 - **AI大模型的行业解决方案和案例库参考**
- https://page.dingtalk.com/wow/dingtalk/default/dingtalk/I0HfYX4QStBIpLgxnZQe
- https://wolai.dingtalk.com/jVUBREtv4JHXRnBSWRaWj6
- https://bigmodel.cn/
#### 高频问题解答
* **问题:大模型是直接调用API吗,就是调用通义千问或者文心一言接口吗?**
- ,LLM大模型只是简单调用API?那如何和后端业务+数据库数据联动?
- 架构也和微服务类似,LLM重试机制、兜底降级机制等等怎么做?敏感数据敢上传外部?
- 比如
- 某一次失败之后应该怎么处理,还有日志生成、管理资源、性能优化、准确性等等
- 这一些都是很关键的,靠普通的API是解决不了的,这个就是大课的部分解决方案,还有更多!!!!
- 通义千问或者文心一言都是一个基层模型底座,这些大模型类似我们的操作系统,不是商业应用程序
- 类似我们会基于操作系统上开发App软件;那AI应用就是基于这些大模型作为底座,开发上层的商业智能化应用
- 比如
- 公司需要做智能知识库、行业智能客服、智慧政务、AI律师、AI客服等,那就没法用这些平台
- 因为你公司不可能把敏感数据上传上去,而且也没法做到;
- 比如律师行业,医疗行业,财税行业等专业领域知识都是。
- 所以直接调用外部的API完全不一样,像通义千问等只是通用大模型,适合个人提升效率啥的,这个很容易。
- 但是达不到商用级别,也难和公司的业务结合一起;
- 像很多公司都是有沉淀很多历史的资料,文档记录,案例等,而且又敏感,不能上传外部的LLM平台
- 所以都需要私有化部署,针对公司本身所处的行业进行深度定制和优化,结合常规的后端和前端项目整合一起
* **问题:学完这个大课,可以开发怎么样的项目和应用呢?**
- AI文档助手
- 你可以给一堆专业文档,包括word文档、PDF等,让AI工具帮你生成 文档总结做周报、季度汇报等
- 给公司培训的的时候,可以从网上寻找很多资料,但是杂乱分散,可以让AI帮你整理和汇总,排版清晰
- 让AI帮你写多类型跳槽简历、毕业论文
- 企业知识库
- 将企业的各类知识资源进行智能化归类、整合,形成一套问题与答案的集合
- 【企业内部知识共享】作为企业内部的知识共享平台,帮助员工快速获取所需知识,提高团队协作效率
- 【客户服务】AI企业问答知识库可以为客户提供快速准确的解答服务 理解客户的问题并给出相应的答案
- 【员工培训】AI企业问答知识库还可以作为员工培训的平台,根据员工的个人需求进行定制化培训
- 私人AI助理
- 聊天与陪伴:私人AI助理可以陪伴用户聊天、讲笑话、玩小游戏等,提供轻松愉快的休闲娱乐体验。
- 个性化推荐:根据用户的喜好和行为习惯,推荐音乐、电影、书籍等娱乐内容。
- 健康管理:监测家庭成员的健康状况,提供运动、饮食建议,甚至可以协助医生进行诊断
- 特定领域智能聊天机器人
- 通过给AI一系列资料,单独训练特定领域,然后让帮我们做出决策
- 比如
- 各个大公司财报和历史股票行情信息,让AI汇总和给出指导建议
- 给出医院检查报告等,AI训练可以给出诊断和建议
- 给出特定领域销售部门的日常话术和专业知识, 充当智能客服
* **问题:什么是AI大模型应用,什么是AI大模型底层原理?课程是重点讲解哪块?**
- AI大模型应用开发
- 就是我们用的很多人工智能工具,比如【智能美颜相机】【智能客服机器人】
- LLM应用层面很多很多:企业问答、智能律师、智慧政务、税务等
- 多数公司都是开发这类应用产品,包括App,网站等,使用人员和市场需求最多,90%占比
- AI大模型底层原理
- 就是为啥他的更加智能,采用什么数学算法,为啥更加智能,刨根问底
- 需要高学历,需要看很多行业英文论文、高等数学知识、算法原理等,岗位和市场需求少 10%占比
- 如果个人喜欢编写代码,实现具体的功能,且想要快速看到应用效果,则AI大模型应用开发
- 如果你对算数学模型、机器学习等有很好的基础,有精力进行深入研究则可以学习AI大模型底层原理
- 我们这个课程对于侧重AI大模型应用开发,如果你是0基础,之前是前端/后端/测试/大数据等背景则推荐
- 建议优先学习AI大模型应用开发,然后在进一步学习LLM算法方面知识提升
* **问题:后端业务+LLM大模型课程对电脑配置有什么要求,常规几千块的电脑能学不?**
- 常规电脑即可学习,虽然后端项目涉及多个中间件,LLM大模型训练和私有化部署等需要用到大量硬件资源
- 课程会教采用云服务器和三方算力平台解决这类问题,几十块就可以搞定,所以不用担心。
- 课程会讲多个LLM大模型,封装成底层,容易切换不同的大模型,包括在线和离线私有化部署的大模型
- LLM大模型参数有几亿和几十亿、几百亿等参数规模,这个是需要比较大的算力资源
- 学习的时候可以使用少点参数进行练习,生产的时候可以根据公司需要选择不同级别的参数规模,结合硬件
- 这些都需要掌握,不同的级别的项目才好根据情况进行选择
#### 技术栈要求和内容安排
* **大课技术栈概览**
* 基础工具环境:AI大模型编码插件+JDK21+IDEA旗舰版+VSCode+Python3.1X+Linux服务器
* 后端高并发技术:新版SpringBoot3.X+MybatisPlus+Lombok+Hutool+Mysql8.X+多个开源工具包
* 中间件+存储技术:Redis7.X+Kafak3.X-Kraft架构|RabbitMQ+分布式文件存储MinIO或OSS存储引擎
* 前后端分离架构下的 Vue3+ AntDesign+ Nginx网关+多个前端开源组件 (提供完整代码)
* 超多AI大模型+模型库应用:新版GPT/ChatGLM/通义千问等+Huggingface/ModelScope等
* AI大模型技术:FastAPI框架+全新LangChain框架+向量数据库Milvus+多个大模型高频类库等
* LLM框架组件:Model+Prompt+Agent+Chains+Memory+Indexes+RAG+ReAct等
* DevOps上线部署:Jenkins CICD + 阿里云Git仓库+ 阿里云ECS 服务器+ Docker容器编排调度
* ....更多精彩
* **内容安排说明**
* 前置必备技术栈:SpringBoot + Mysql +Redis + Kafka|RabbitMQ + Docker +Linux
* 其他新技术栈:Python + LangChain + FastAPI + Milvus +MinIO 等大课里面会讲
### 需求文档和架构图
#### 为什么技术Leader需要掌握产品需求文档
* 核心:有些不懂技术的产品经理没法编写特定领域的项目需求文档
* **技术知识缺乏**:
* 特定领域的项目可能需要特定的技术知识。
* 如果产品经理缺乏相关技术背景,难以理解技术实现的复杂性和可行性,从而难以准确描述技术需求。
* **沟通障碍**
* 产品经理需要与技术团队紧密合作,以确保需求的可实现性。
* 如果产品经理不懂技术,他们可能难以与技术团队有效沟通,导致需求文档中的技术细节不准确或不完整。
* **风险评估不足**:
* 不懂技术的产品经理可能无法准确评估技术实现的风险,这可能导致项目在实施过程中遇到预料之外的问题。
* **需求优先级判断失误**:
* 技术背景可以帮助产品经理判断哪些需求对项目成功最为关键。
* 缺乏技术背景的产品经理可能难以做出正确的优先级排序。
* **一份合格的产品需求文档(多数内容有即可,不同团队要求大体类似)**
```markdown
## 1. 标题页
- **产品名称**:[产品名称]
- **版本/修订号**:[版本号]
- **编制日期**:[编制日期]
- **编制人**:[编制人姓名]
- **审核人**:[审核人姓名]
## 2. 目录
- 根据文档内容创建目录,方便快速跳转到各个部分。
## 3. 引言
### 3.1 目的
- 简要说明编写此文档的目的。
### 3.2 背景
- 描述产品的背景信息,包括市场机会、业务需求等。
### 3.3 定义
- 对文档中使用的专业术语或缩写词进行定义。
## 4. 产品概述
### 4.1 产品愿景
- 描述产品的长远目标和愿景。
### 4.2 产品目标
- 明确产品的短期和长期目标。
### 4.3 用户和市场
- 描述目标用户群体和市场定位。
## 5. 功能需求
### 5.1 功能列表
- 列出产品需要实现的所有功能。
### 5.2 功能描述
- 对每个功能进行详细描述,包括用户故事或用例。
## 6. 非功能需求
### 6.1 性能要求
- 描述产品的性能标准,如响应时间、并发用户数等。
### 6.2 安全要求
- 列出产品必须满足的安全标准。
### 6.3 可用性要求
- 描述产品的易用性和可访问性要求。
### 6.4 法律和标准
- 指出产品需要遵守的法律、法规和行业标准。
## 7. 技术和开发约束
- 列出技术栈、开发平台、第三方服务等技术约束。
## 8. 项目计划
- 提供产品开发的时间线和里程碑。
## 9. 预算和资源
- 概述项目的预算和所需资源。
## 10. 风险评估
- 识别项目可能面临的风险,并提出相应的缓解措施。
## 11. 附件
- 包括市场调研报告、竞品分析、用户访谈记录等支持文档。
```
#### AI智能化云盘需求文档说明
- **AI大模型的行业解决方案和案例库参考**
- https://page.dingtalk.com/wow/dingtalk/default/dingtalk/I0HfYX4QStBIpLgxnZQe
- https://wolai.dingtalk.com/jVUBREtv4JHXRnBSWRaWj6
- https://bigmodel.cn/
#### 高频问题解答
* **问题:大模型是直接调用API吗,就是调用通义千问或者文心一言接口吗?**
- ,LLM大模型只是简单调用API?那如何和后端业务+数据库数据联动?
- 架构也和微服务类似,LLM重试机制、兜底降级机制等等怎么做?敏感数据敢上传外部?
- 比如
- 某一次失败之后应该怎么处理,还有日志生成、管理资源、性能优化、准确性等等
- 这一些都是很关键的,靠普通的API是解决不了的,这个就是大课的部分解决方案,还有更多!!!!
- 通义千问或者文心一言都是一个基层模型底座,这些大模型类似我们的操作系统,不是商业应用程序
- 类似我们会基于操作系统上开发App软件;那AI应用就是基于这些大模型作为底座,开发上层的商业智能化应用
- 比如
- 公司需要做智能知识库、行业智能客服、智慧政务、AI律师、AI客服等,那就没法用这些平台
- 因为你公司不可能把敏感数据上传上去,而且也没法做到;
- 比如律师行业,医疗行业,财税行业等专业领域知识都是。
- 所以直接调用外部的API完全不一样,像通义千问等只是通用大模型,适合个人提升效率啥的,这个很容易。
- 但是达不到商用级别,也难和公司的业务结合一起;
- 像很多公司都是有沉淀很多历史的资料,文档记录,案例等,而且又敏感,不能上传外部的LLM平台
- 所以都需要私有化部署,针对公司本身所处的行业进行深度定制和优化,结合常规的后端和前端项目整合一起
* **问题:学完这个大课,可以开发怎么样的项目和应用呢?**
- AI文档助手
- 你可以给一堆专业文档,包括word文档、PDF等,让AI工具帮你生成 文档总结做周报、季度汇报等
- 给公司培训的的时候,可以从网上寻找很多资料,但是杂乱分散,可以让AI帮你整理和汇总,排版清晰
- 让AI帮你写多类型跳槽简历、毕业论文
- 企业知识库
- 将企业的各类知识资源进行智能化归类、整合,形成一套问题与答案的集合
- 【企业内部知识共享】作为企业内部的知识共享平台,帮助员工快速获取所需知识,提高团队协作效率
- 【客户服务】AI企业问答知识库可以为客户提供快速准确的解答服务 理解客户的问题并给出相应的答案
- 【员工培训】AI企业问答知识库还可以作为员工培训的平台,根据员工的个人需求进行定制化培训
- 私人AI助理
- 聊天与陪伴:私人AI助理可以陪伴用户聊天、讲笑话、玩小游戏等,提供轻松愉快的休闲娱乐体验。
- 个性化推荐:根据用户的喜好和行为习惯,推荐音乐、电影、书籍等娱乐内容。
- 健康管理:监测家庭成员的健康状况,提供运动、饮食建议,甚至可以协助医生进行诊断
- 特定领域智能聊天机器人
- 通过给AI一系列资料,单独训练特定领域,然后让帮我们做出决策
- 比如
- 各个大公司财报和历史股票行情信息,让AI汇总和给出指导建议
- 给出医院检查报告等,AI训练可以给出诊断和建议
- 给出特定领域销售部门的日常话术和专业知识, 充当智能客服
* **问题:什么是AI大模型应用,什么是AI大模型底层原理?课程是重点讲解哪块?**
- AI大模型应用开发
- 就是我们用的很多人工智能工具,比如【智能美颜相机】【智能客服机器人】
- LLM应用层面很多很多:企业问答、智能律师、智慧政务、税务等
- 多数公司都是开发这类应用产品,包括App,网站等,使用人员和市场需求最多,90%占比
- AI大模型底层原理
- 就是为啥他的更加智能,采用什么数学算法,为啥更加智能,刨根问底
- 需要高学历,需要看很多行业英文论文、高等数学知识、算法原理等,岗位和市场需求少 10%占比
- 如果个人喜欢编写代码,实现具体的功能,且想要快速看到应用效果,则AI大模型应用开发
- 如果你对算数学模型、机器学习等有很好的基础,有精力进行深入研究则可以学习AI大模型底层原理
- 我们这个课程对于侧重AI大模型应用开发,如果你是0基础,之前是前端/后端/测试/大数据等背景则推荐
- 建议优先学习AI大模型应用开发,然后在进一步学习LLM算法方面知识提升
* **问题:后端业务+LLM大模型课程对电脑配置有什么要求,常规几千块的电脑能学不?**
- 常规电脑即可学习,虽然后端项目涉及多个中间件,LLM大模型训练和私有化部署等需要用到大量硬件资源
- 课程会教采用云服务器和三方算力平台解决这类问题,几十块就可以搞定,所以不用担心。
- 课程会讲多个LLM大模型,封装成底层,容易切换不同的大模型,包括在线和离线私有化部署的大模型
- LLM大模型参数有几亿和几十亿、几百亿等参数规模,这个是需要比较大的算力资源
- 学习的时候可以使用少点参数进行练习,生产的时候可以根据公司需要选择不同级别的参数规模,结合硬件
- 这些都需要掌握,不同的级别的项目才好根据情况进行选择
#### 技术栈要求和内容安排
* **大课技术栈概览**
* 基础工具环境:AI大模型编码插件+JDK21+IDEA旗舰版+VSCode+Python3.1X+Linux服务器
* 后端高并发技术:新版SpringBoot3.X+MybatisPlus+Lombok+Hutool+Mysql8.X+多个开源工具包
* 中间件+存储技术:Redis7.X+Kafak3.X-Kraft架构|RabbitMQ+分布式文件存储MinIO或OSS存储引擎
* 前后端分离架构下的 Vue3+ AntDesign+ Nginx网关+多个前端开源组件 (提供完整代码)
* 超多AI大模型+模型库应用:新版GPT/ChatGLM/通义千问等+Huggingface/ModelScope等
* AI大模型技术:FastAPI框架+全新LangChain框架+向量数据库Milvus+多个大模型高频类库等
* LLM框架组件:Model+Prompt+Agent+Chains+Memory+Indexes+RAG+ReAct等
* DevOps上线部署:Jenkins CICD + 阿里云Git仓库+ 阿里云ECS 服务器+ Docker容器编排调度
* ....更多精彩
* **内容安排说明**
* 前置必备技术栈:SpringBoot + Mysql +Redis + Kafka|RabbitMQ + Docker +Linux
* 其他新技术栈:Python + LangChain + FastAPI + Milvus +MinIO 等大课里面会讲
### 需求文档和架构图
#### 为什么技术Leader需要掌握产品需求文档
* 核心:有些不懂技术的产品经理没法编写特定领域的项目需求文档
* **技术知识缺乏**:
* 特定领域的项目可能需要特定的技术知识。
* 如果产品经理缺乏相关技术背景,难以理解技术实现的复杂性和可行性,从而难以准确描述技术需求。
* **沟通障碍**
* 产品经理需要与技术团队紧密合作,以确保需求的可实现性。
* 如果产品经理不懂技术,他们可能难以与技术团队有效沟通,导致需求文档中的技术细节不准确或不完整。
* **风险评估不足**:
* 不懂技术的产品经理可能无法准确评估技术实现的风险,这可能导致项目在实施过程中遇到预料之外的问题。
* **需求优先级判断失误**:
* 技术背景可以帮助产品经理判断哪些需求对项目成功最为关键。
* 缺乏技术背景的产品经理可能难以做出正确的优先级排序。
* **一份合格的产品需求文档(多数内容有即可,不同团队要求大体类似)**
```markdown
## 1. 标题页
- **产品名称**:[产品名称]
- **版本/修订号**:[版本号]
- **编制日期**:[编制日期]
- **编制人**:[编制人姓名]
- **审核人**:[审核人姓名]
## 2. 目录
- 根据文档内容创建目录,方便快速跳转到各个部分。
## 3. 引言
### 3.1 目的
- 简要说明编写此文档的目的。
### 3.2 背景
- 描述产品的背景信息,包括市场机会、业务需求等。
### 3.3 定义
- 对文档中使用的专业术语或缩写词进行定义。
## 4. 产品概述
### 4.1 产品愿景
- 描述产品的长远目标和愿景。
### 4.2 产品目标
- 明确产品的短期和长期目标。
### 4.3 用户和市场
- 描述目标用户群体和市场定位。
## 5. 功能需求
### 5.1 功能列表
- 列出产品需要实现的所有功能。
### 5.2 功能描述
- 对每个功能进行详细描述,包括用户故事或用例。
## 6. 非功能需求
### 6.1 性能要求
- 描述产品的性能标准,如响应时间、并发用户数等。
### 6.2 安全要求
- 列出产品必须满足的安全标准。
### 6.3 可用性要求
- 描述产品的易用性和可访问性要求。
### 6.4 法律和标准
- 指出产品需要遵守的法律、法规和行业标准。
## 7. 技术和开发约束
- 列出技术栈、开发平台、第三方服务等技术约束。
## 8. 项目计划
- 提供产品开发的时间线和里程碑。
## 9. 预算和资源
- 概述项目的预算和所需资源。
## 10. 风险评估
- 识别项目可能面临的风险,并提出相应的缓解措施。
## 11. 附件
- 包括市场调研报告、竞品分析、用户访谈记录等支持文档。
```
#### AI智能化云盘需求文档说明
 #### 架构图的作用和绘制技巧
- 什么是架构图
- 架构图 = 架构 + 图
- 用图的形式把系统架构展示出来,配上简单的文案
- 一图胜千言,解决沟通障碍,给不同的【业务方】看懂
- 业务方很多,不同人看到角度不一样,你让【产品经理】看 【物理部署视图】他看得懂?
* 架构图是给人看的,这些人我们习惯称为【业务方、客户】,有哪些人?
- 人员
- 上级:你的公司Leader(晋升汇报)、老板、外部投资人
- 团队内:产品、运营、测试、技术、运维同学
- 外部:最终系统使用的用户
- 好比阿里这边评定绩效,有一项就是业务方评分
- 你做的外部用户的活动系统,测试同学会进行测试,太多bug肯定就不行
- 你做的给运营同学使用的系统,不能提升她运营的效率,业务方是否满意?
* 为什么要搞出这么多个架构图?用一个图不行吗?
- 一开始确实是一个图表示系统架构设计
- 但是业务方很多,不同人看到角度不一样,你让软件用户看物理部署视图?他看得懂?
- 要明确沟通交流面向的客户
- 开发人员、运维人员、项目经理、软件最终用户、客户
- 避免在一张图中展示所有细节,根据受众的需要简化信息,突出关键组件和关系。
- 不同架构视图承载不同的架构设计决策,支持不同的目标和用途
- 架构图也不能太多(过度文档化)维护更新起来成本大
- 不同架构图应该使用哪种方法来画?
- 可以用的表示法和工具很多,没有太多的限制,把握对应的视图关注点才是关键
- Xmind、EdrawMax、PPT、PowerDesigner
- OmniGraffle、Visio、Process On
- 开始阶段不要陷入过度设计中,没那么多需求不一定要那么多图(你是否有那么多客户)
* 常见架构图作用对比
* 产品/应用/产品业务架构
- 表达业务是如何开展的,服务于业务目标,通过描绘业务上下层关系,简单的业务视图降低业务系统的复杂
- 是对整个系统实现的总体架构 , 应用架构和**系统架构**很大类似
- 一方面承接业务架构的落地,一方面影响技术选型
- 注意:一般应用架构图【不加入太多技术框架和实现】
- 下面这个是什么架构图(产品架构图-方便技术和产品沟通,图片阿里云官方网站VOD视频点播)
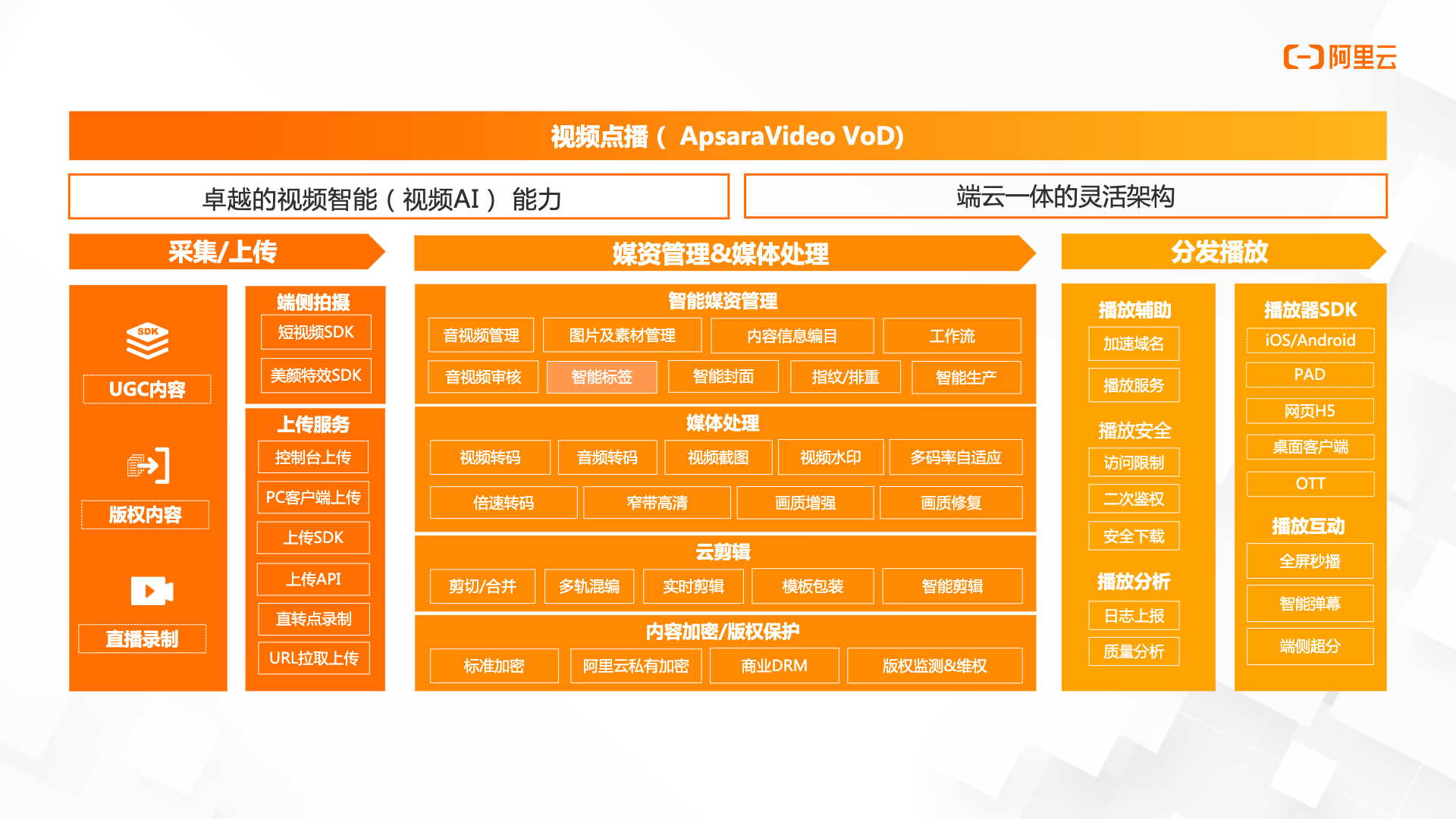
* 技术架构
- 应用架构本身只关心需要哪些应用系统,不关心在整个项目中你需要使用哪些技术
- 技术架构则是实现应用架构的承接方,识别技术需求,进行技术选型,描述技术之间的关系
- 解决的问题包括
- 技术层面的分层、开发语言、框架的选择
- 通信技术、存储技术的选择、非功能性需求的技术选择等
#### 教你画架构图
- 在画架构图之前,想清楚3个问题,架构图想表达什么?有什么用?给谁看?
- 表达是业务系统之间的关系,梳理业务结构
- 将复杂的业务逻辑简单化,降低理解难度,更方便业务方理解
- 给业务方查看,业务相关干系人
- 业务架构图
- 表达业务是如何开展的,服务于业务目标,通过描绘业务上下层关系,简单的业务视图降低业务系统的复杂度,提高客户理解度
- 图中【尽量不出现技术】的字眼,不同架构图的读者是不同的,确保能看懂。
- 架构图中模块的划分粒度,一定要合适,既不能太宽泛,也不能太细粒度
- 无技术背景人员可参与实现的讨论,向技术人员描述解决方案核心要做什么,必须实现的关键是什么
- 明白一个点
- 先有业务,再有系统,微服务/系统/中心 是类似概念
- 系统是来实现业务的,比如电商业务里面A系统、B系统
* 业务架构类型
- 上中下结构:用户展现层-业务平台层-公共能力层-数据存储层-基础资源层
- 案例一(图片来源-阿里云数字政府)
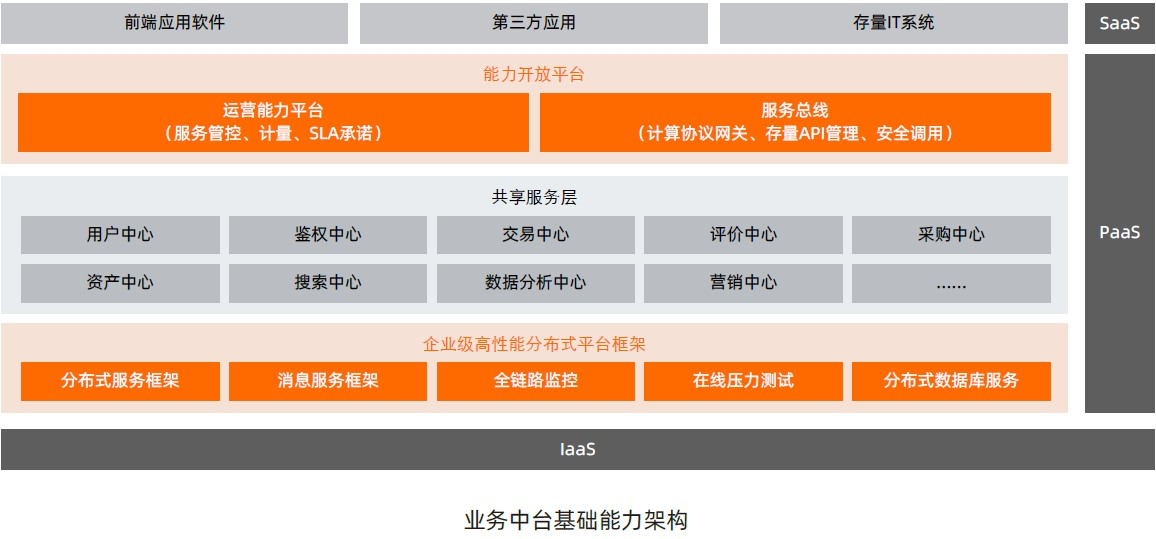
- 左中右结构:上游产业 - 业务平台- 下游产业
- 相对较少用,就是倒置过去
* 画图三步走(**不同架构图通用法则**)
- 分层
- 业务按照层级进行划分,各个层级属于独立的版块
- 下层为上层提供服务能力支撑,比如:laaS / PaaS / SaaS
- 分模块
- 同层级中进行小归类;属于平行关系,可以独立存在
- 理清架构图类型、业务要全面、专业术语一致、图形清晰美观、颜色类型划分合理
- 不同颜色可以表示当下要做的,未来要做的
- 分功能
- 独立功能划分出来,即业务入口
- 业务方重点关注的功能点,可以认为是微服务划分
* 如何判断架构图的好和坏?
- 业务抽象设计的合理性,是否满足高内聚、低耦合的要求,不能太宽泛,也不能太细粒度
- 层级划分目标系统边界,自下而上 或 由上而下,一般包括 基础设施、数据层、应用层、用户层四个层次
- 使用清晰的布局,确保组件之间的连接线不交叉,易于跟踪。
- 使用颜色和样式来区分不同类型的组件,但不要过度使用,以免分散注意力。
- 纵向分层 上层依赖于下层越底层,越是基础服务;横向并列关系,级别相同
- 理清架构图类型、业务要全面、专业术语一致、图形清晰美观、颜色类型划分合理
- 最重要是:**你的业务方能 满意+看懂!!!**
#### AI智能化云盘应用架构图讲解
* 什么是应用架构图
- 是对整个系统实现的总体架构 , 应用架构和**系统架构**很大类似
- 一方面承接业务架构的落地,一方面影响技术选型
* 注意:一般应用架构图【不加入太多技术框架和实现】
- 作用
- 根据业务场景 对系统进分层,指出开发的原则、系统各个层次的应用服务
- 业务方
- **研发人员,各层级架构师,各层级技术管理者**
- 分类
- 多系统应用架构,用来分层次说明不同系统间的业务逻辑关系、系统边界等,比如 分布式、微服务
- 单系统应用架构,用来分层次说明系统的组成模块和功能点之间的业务逻辑关系,比如单体应用
- 常规分层
- 表示-展现层:负责用户体验
- 业务-服务层:负责业务逻辑
- 数据-访问层:负责数据库存取
* 画图三步走
- 分层
- 业务按照层级进行划分,各个层级属于独立的版块
- 下层为上层提供服务能力支撑,比如:laaS / PaaS / SaaS
- 分模块
- 同层级中进行小归类;属于平行关系,可以独立存在
- 理清架构图类型、业务要全面、专业术语一致、图形清晰美观、颜色类型划分合理
- 不同颜色可以表示当下要做的,未来要做的
- 分功能
- 独立功能划分出来,即业务入口
- 业务方重点关注的功能点,可以认为是微服务划分
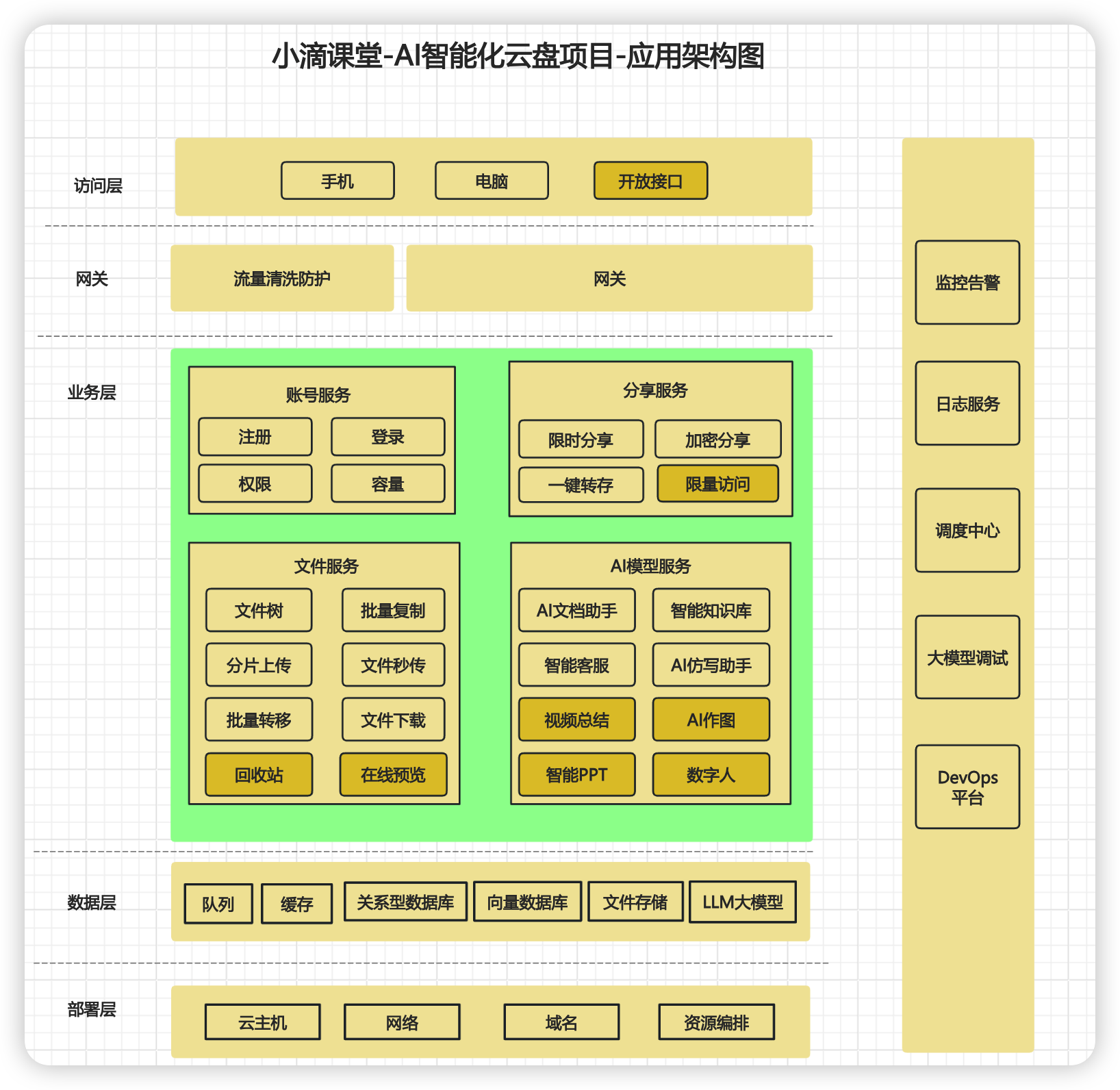
* 新一代AI智能化云盘应用架构图(找bug)
#### 架构图的作用和绘制技巧
- 什么是架构图
- 架构图 = 架构 + 图
- 用图的形式把系统架构展示出来,配上简单的文案
- 一图胜千言,解决沟通障碍,给不同的【业务方】看懂
- 业务方很多,不同人看到角度不一样,你让【产品经理】看 【物理部署视图】他看得懂?
* 架构图是给人看的,这些人我们习惯称为【业务方、客户】,有哪些人?
- 人员
- 上级:你的公司Leader(晋升汇报)、老板、外部投资人
- 团队内:产品、运营、测试、技术、运维同学
- 外部:最终系统使用的用户
- 好比阿里这边评定绩效,有一项就是业务方评分
- 你做的外部用户的活动系统,测试同学会进行测试,太多bug肯定就不行
- 你做的给运营同学使用的系统,不能提升她运营的效率,业务方是否满意?
* 为什么要搞出这么多个架构图?用一个图不行吗?
- 一开始确实是一个图表示系统架构设计
- 但是业务方很多,不同人看到角度不一样,你让软件用户看物理部署视图?他看得懂?
- 要明确沟通交流面向的客户
- 开发人员、运维人员、项目经理、软件最终用户、客户
- 避免在一张图中展示所有细节,根据受众的需要简化信息,突出关键组件和关系。
- 不同架构视图承载不同的架构设计决策,支持不同的目标和用途
- 架构图也不能太多(过度文档化)维护更新起来成本大
- 不同架构图应该使用哪种方法来画?
- 可以用的表示法和工具很多,没有太多的限制,把握对应的视图关注点才是关键
- Xmind、EdrawMax、PPT、PowerDesigner
- OmniGraffle、Visio、Process On
- 开始阶段不要陷入过度设计中,没那么多需求不一定要那么多图(你是否有那么多客户)
* 常见架构图作用对比
* 产品/应用/产品业务架构
- 表达业务是如何开展的,服务于业务目标,通过描绘业务上下层关系,简单的业务视图降低业务系统的复杂
- 是对整个系统实现的总体架构 , 应用架构和**系统架构**很大类似
- 一方面承接业务架构的落地,一方面影响技术选型
- 注意:一般应用架构图【不加入太多技术框架和实现】
- 下面这个是什么架构图(产品架构图-方便技术和产品沟通,图片阿里云官方网站VOD视频点播)

* 技术架构
- 应用架构本身只关心需要哪些应用系统,不关心在整个项目中你需要使用哪些技术
- 技术架构则是实现应用架构的承接方,识别技术需求,进行技术选型,描述技术之间的关系
- 解决的问题包括
- 技术层面的分层、开发语言、框架的选择
- 通信技术、存储技术的选择、非功能性需求的技术选择等
#### 教你画架构图
- 在画架构图之前,想清楚3个问题,架构图想表达什么?有什么用?给谁看?
- 表达是业务系统之间的关系,梳理业务结构
- 将复杂的业务逻辑简单化,降低理解难度,更方便业务方理解
- 给业务方查看,业务相关干系人
- 业务架构图
- 表达业务是如何开展的,服务于业务目标,通过描绘业务上下层关系,简单的业务视图降低业务系统的复杂度,提高客户理解度
- 图中【尽量不出现技术】的字眼,不同架构图的读者是不同的,确保能看懂。
- 架构图中模块的划分粒度,一定要合适,既不能太宽泛,也不能太细粒度
- 无技术背景人员可参与实现的讨论,向技术人员描述解决方案核心要做什么,必须实现的关键是什么
- 明白一个点
- 先有业务,再有系统,微服务/系统/中心 是类似概念
- 系统是来实现业务的,比如电商业务里面A系统、B系统
* 业务架构类型
- 上中下结构:用户展现层-业务平台层-公共能力层-数据存储层-基础资源层
- 案例一(图片来源-阿里云数字政府)

- 左中右结构:上游产业 - 业务平台- 下游产业
- 相对较少用,就是倒置过去
* 画图三步走(**不同架构图通用法则**)
- 分层
- 业务按照层级进行划分,各个层级属于独立的版块
- 下层为上层提供服务能力支撑,比如:laaS / PaaS / SaaS
- 分模块
- 同层级中进行小归类;属于平行关系,可以独立存在
- 理清架构图类型、业务要全面、专业术语一致、图形清晰美观、颜色类型划分合理
- 不同颜色可以表示当下要做的,未来要做的
- 分功能
- 独立功能划分出来,即业务入口
- 业务方重点关注的功能点,可以认为是微服务划分

* 如何判断架构图的好和坏?
- 业务抽象设计的合理性,是否满足高内聚、低耦合的要求,不能太宽泛,也不能太细粒度
- 层级划分目标系统边界,自下而上 或 由上而下,一般包括 基础设施、数据层、应用层、用户层四个层次
- 使用清晰的布局,确保组件之间的连接线不交叉,易于跟踪。
- 使用颜色和样式来区分不同类型的组件,但不要过度使用,以免分散注意力。
- 纵向分层 上层依赖于下层越底层,越是基础服务;横向并列关系,级别相同
- 理清架构图类型、业务要全面、专业术语一致、图形清晰美观、颜色类型划分合理
- 最重要是:**你的业务方能 满意+看懂!!!**
#### AI智能化云盘应用架构图讲解
* 什么是应用架构图
- 是对整个系统实现的总体架构 , 应用架构和**系统架构**很大类似
- 一方面承接业务架构的落地,一方面影响技术选型
* 注意:一般应用架构图【不加入太多技术框架和实现】
- 作用
- 根据业务场景 对系统进分层,指出开发的原则、系统各个层次的应用服务
- 业务方
- **研发人员,各层级架构师,各层级技术管理者**
- 分类
- 多系统应用架构,用来分层次说明不同系统间的业务逻辑关系、系统边界等,比如 分布式、微服务
- 单系统应用架构,用来分层次说明系统的组成模块和功能点之间的业务逻辑关系,比如单体应用
- 常规分层
- 表示-展现层:负责用户体验
- 业务-服务层:负责业务逻辑
- 数据-访问层:负责数据库存取
* 画图三步走
- 分层
- 业务按照层级进行划分,各个层级属于独立的版块
- 下层为上层提供服务能力支撑,比如:laaS / PaaS / SaaS
- 分模块
- 同层级中进行小归类;属于平行关系,可以独立存在
- 理清架构图类型、业务要全面、专业术语一致、图形清晰美观、颜色类型划分合理
- 不同颜色可以表示当下要做的,未来要做的
- 分功能
- 独立功能划分出来,即业务入口
- 业务方重点关注的功能点,可以认为是微服务划分
* 新一代AI智能化云盘应用架构图(找bug)
 #### AI智能化云盘技术架构图和作业提交
* 什么是技术架构
- 应用架构本身只关心需要哪些应用系统,不关心在整个项目中你需要使用哪些技术
- 技术架构则是实现应用架构的承接方,识别技术需求,进行技术选型,描述技术之间的关系
- 解决的问题包括
- 技术层面的分层、开发语言、框架的选择
- 通信技术、存储技术的选择、非功能性需求的技术选择等
- 案例
#### AI智能化云盘技术架构图和作业提交
* 什么是技术架构
- 应用架构本身只关心需要哪些应用系统,不关心在整个项目中你需要使用哪些技术
- 技术架构则是实现应用架构的承接方,识别技术需求,进行技术选型,描述技术之间的关系
- 解决的问题包括
- 技术层面的分层、开发语言、框架的选择
- 通信技术、存储技术的选择、非功能性需求的技术选择等
- 案例
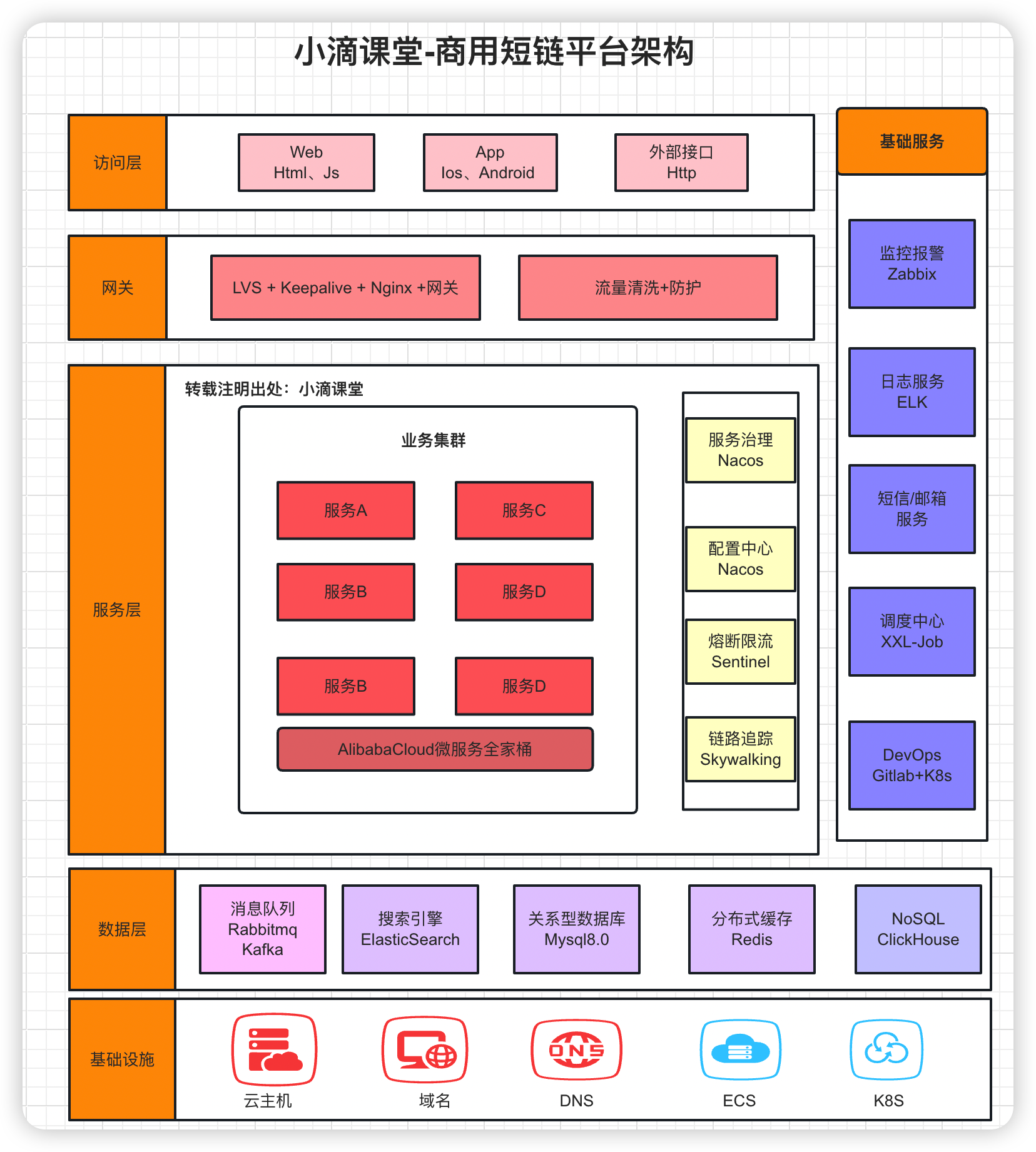 * 新一代AI智能化云盘技术选型(**下面只是部分技术栈**)
* 基础工具环境:AI大模型编码插件+JDK21+IDEA旗舰版+VSCode+Python3.1X+Linux服务器
* 后端高并发技术:新版SpringBoot3.X+MybatisPlus+Lombok+Hutool+Mysql8.X+多个开源工具包
* 中间件+存储技术:Redis7.X+Kafak3.X-Kraft架构+分布式文件存储MinIO或OSS存储引擎
* 前后端分离架构下的 Vue3+ AntDesign+ Nginx网关+多个前端开源组件 (提供完整代码)
* 超多AI大模型+模型库应用:新版GPT/ChatGLM/通义千问等+Huggingface/ModelScope等
* AI大模型技术:FastAPI框架+全新LangChain框架+向量数据库Milvus+多个大模型高频类库等
* LLM框架组件:Model+Prompt+Agent+Chains+Memory+Indexes+RAG+ReAct等
* DevOps上线部署:Jenkins CICD + 阿里云Git仓库+ 阿里云ECS 服务器+ Docker容器编排调度
### 开发环境搭建
#### AI编码插件
AI会淘汰程序员?
* AI技术的发展一定程度上改变我们程序员的工作方式,例如自动化一些重复性任务,辅助程序员进行代码审查和优化等
* 也可以编写包括中等程度的CURD、算法等;但AI很难完全替代程序员,可以很大程度辅助我们工程师
* 程序员在创造力、人际沟通、适应新技术、解决复杂问题以及法律责任等方面具有不可替代的优势,AI背锅?
* 如果程序员不懂技术,你能判断AI写的代码上生产环境?出问题你可以排查?
AI编码插件对比
* CodeGeeX(清华大学+智谱AI)
* 地址:https://codegeex.cn/
* 优点:
* 多语言代码生成模型,支持代码生成与补全、自动添加注释、代码翻译以及智能问答等功能
* 支持多种主流编程语言,并适配多种主流IDE
* 对于个人开发者完全免费,国内开发,无需额外连接VPN
* 缺点
* 对于复杂的场景,AI工具可能提供错误的答案
* 通义灵码(阿里)
* 地址:https://tongyi.aliyun.com/lingma
* 优点:
* 基于通义大模型,提供代码智能生成、研发智能问答能力
* 支持行级/函数级实时续写,自然语言生成代码
* 生成单元测试,支持多种测试框架。
* 支持多种主流编程语言
* 缺点
* 单元测试生成功能表现一般
* 高级功能需要付费
* GitHub Copilot
* 地址:https://github.com/features/copilot/
* 优点:
* 根据提示自动生成代码,提高开发效率
* 学习项目中的代码风格,获取足够多的上下文,并根据其生成代码
* 支持多种编程语言,适用范围广
* 缺点:
* 可能存在隐私问题
* 功能收费,对于个人开发者成本较高
* **其他比较牛的(都需要科学上网):**
* **Cursor、Claude**
* 能够完成复杂的任务,并且可以与其他系统集成,支持多种应用场景,包括独立开发程序
* **一个是目前适配AI最好的代码编辑器,一个是目前AI编程能力最强的大模型。**
#### SpringBoot3.X本地开发环境创建
技术版本
* Maven-3.9以上: `mvn -version`
* JDK-21版本(LTS版本 主流应该是26到28年)
* 新版IDEA-旗舰版
* 框架版本-SpringBoot3.X
项目创建 ycloud-aipan
* 快速创建地址:https://start.spring.io/
```xml
* 新一代AI智能化云盘技术选型(**下面只是部分技术栈**)
* 基础工具环境:AI大模型编码插件+JDK21+IDEA旗舰版+VSCode+Python3.1X+Linux服务器
* 后端高并发技术:新版SpringBoot3.X+MybatisPlus+Lombok+Hutool+Mysql8.X+多个开源工具包
* 中间件+存储技术:Redis7.X+Kafak3.X-Kraft架构+分布式文件存储MinIO或OSS存储引擎
* 前后端分离架构下的 Vue3+ AntDesign+ Nginx网关+多个前端开源组件 (提供完整代码)
* 超多AI大模型+模型库应用:新版GPT/ChatGLM/通义千问等+Huggingface/ModelScope等
* AI大模型技术:FastAPI框架+全新LangChain框架+向量数据库Milvus+多个大模型高频类库等
* LLM框架组件:Model+Prompt+Agent+Chains+Memory+Indexes+RAG+ReAct等
* DevOps上线部署:Jenkins CICD + 阿里云Git仓库+ 阿里云ECS 服务器+ Docker容器编排调度
### 开发环境搭建
#### AI编码插件
AI会淘汰程序员?
* AI技术的发展一定程度上改变我们程序员的工作方式,例如自动化一些重复性任务,辅助程序员进行代码审查和优化等
* 也可以编写包括中等程度的CURD、算法等;但AI很难完全替代程序员,可以很大程度辅助我们工程师
* 程序员在创造力、人际沟通、适应新技术、解决复杂问题以及法律责任等方面具有不可替代的优势,AI背锅?
* 如果程序员不懂技术,你能判断AI写的代码上生产环境?出问题你可以排查?
AI编码插件对比
* CodeGeeX(清华大学+智谱AI)
* 地址:https://codegeex.cn/
* 优点:
* 多语言代码生成模型,支持代码生成与补全、自动添加注释、代码翻译以及智能问答等功能
* 支持多种主流编程语言,并适配多种主流IDE
* 对于个人开发者完全免费,国内开发,无需额外连接VPN
* 缺点
* 对于复杂的场景,AI工具可能提供错误的答案
* 通义灵码(阿里)
* 地址:https://tongyi.aliyun.com/lingma
* 优点:
* 基于通义大模型,提供代码智能生成、研发智能问答能力
* 支持行级/函数级实时续写,自然语言生成代码
* 生成单元测试,支持多种测试框架。
* 支持多种主流编程语言
* 缺点
* 单元测试生成功能表现一般
* 高级功能需要付费
* GitHub Copilot
* 地址:https://github.com/features/copilot/
* 优点:
* 根据提示自动生成代码,提高开发效率
* 学习项目中的代码风格,获取足够多的上下文,并根据其生成代码
* 支持多种编程语言,适用范围广
* 缺点:
* 可能存在隐私问题
* 功能收费,对于个人开发者成本较高
* **其他比较牛的(都需要科学上网):**
* **Cursor、Claude**
* 能够完成复杂的任务,并且可以与其他系统集成,支持多种应用场景,包括独立开发程序
* **一个是目前适配AI最好的代码编辑器,一个是目前AI编程能力最强的大模型。**
#### SpringBoot3.X本地开发环境创建
技术版本
* Maven-3.9以上: `mvn -version`
* JDK-21版本(LTS版本 主流应该是26到28年)
* 新版IDEA-旗舰版
* 框架版本-SpringBoot3.X
项目创建 ycloud-aipan
* 快速创建地址:https://start.spring.io/
```xml
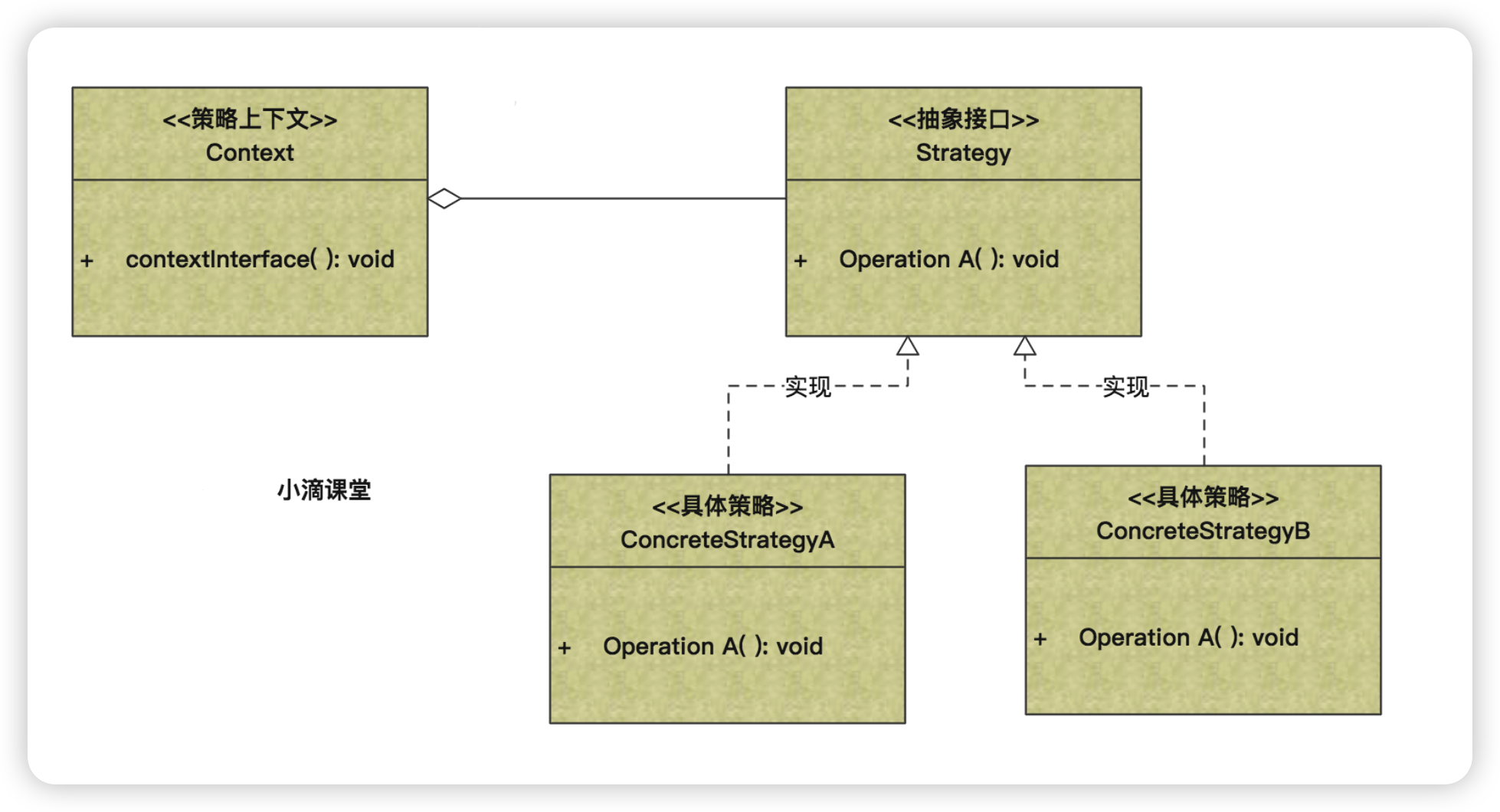 * 应用场景
- 外出旅游,选择骑自行车、坐汽车、飞机等,每一种旅行方式都是一个策略
- 如果在一个系统里面有许多类,它们之间的区别仅在于它们的行为,那么可以使用策略模式
- 不希望暴露复杂的、与算法有关的数据结构,那么可以使用策略模式来封装算法
* 为什么要抽象存储引擎接口
* 将文件存储引擎的接口抽象出来,具体实现可以多种,提高系统的灵活性和可维护性。
* 允许我们根据不同的需求和环境(如开发、测试、生产)灵活切换不同的存储解决方案
* 优点
- **灵活性和可扩展性**:通过定义一个统一的存储接口,我们可以在不修改客户端代码的情况下引入新的存储解决方案。
- **解耦**:将存储逻辑从业务逻辑中解耦,使得存储引擎的变化不影响业务逻辑。
- **易于测试**:可以针对接口编写单元测试,而不必依赖具体的存储实现。
- **代码复用**:多个项目可以共享相同的存储接口,提高代码复用率。
- **简化维护**:统一的接口使得维护和更新存储逻辑变得更加简单。
* 缺点
- **复杂性增加**:需要额外定义接口和可能的抽象类,增加了系统的复杂性。
- **性能考虑**:接口调用可能引入额外的性能开销,尤其是在接口频繁调用的情况下。
- **实现一致性**:确保所有存储策略实现都遵循相同的接口规范,需要严格的代码审查和测试。
* 注意
* **其实aws-java-sdk-s3本身就是封装好了,支持多个存储的,为啥我们又要加一层呢???**
* 假想下
* 万一我以后不用aws-java-sdk-s3,那岂不是四处要修改aws-java-sdk-s3的API方法
* 但如果我加了一层,其他地方使用的话,后续修改换别的SDK,我只需要修改我自己封装的那层即可
#### SpringBoot3.X整合MinIO存储AWS-S3封装
封装存储引擎接口设计【常规版】
* * 定义一个名为StorageEngine的接口,包含多个方法
* 可以跟进需求,实现`StorageEngine`接口的不同存储策略
- **LocalFileStorageEngine**:使用本地文件系统作为存储。
- **S3StorageEngine**:使用Amazon S3作为存储。
- **DatabaseStorageEngine**:使用数据库存储文件元数据和内容。
- **MinIOStorageEngine**:使用MinIO存储文件内容。
- ...
* 使用策略模式的优势
- **客户端代码与存储实现解耦**:客户端代码只需与`StorageEngine`接口交互,不需要关心具体的存储细节。
- **易于切换存储策略**:根据不同的业务需求或环境(开发、测试、生产)灵活切换不同的存储策略。
- **支持A/B测试**:可以同时运行多个存储策略,进行性能和效果比较。
* 抽取文件操作相关接口 StoreEngine
```java
public interface StoreEngine {
/*=====================Bucket相关===========================*/
/**
* 检查指定的存储桶是否存在于当前的存储系统中
*
* @param bucketName 存储桶的名称
* @return 如果存储桶存在,则返回true;否则返回false
*/
boolean bucketExists(String bucketName);
/**
* 删除指定名称的存储桶
*
* @param bucketName 存储桶的名称
* @return 如果存储桶删除成功,则返回true;否则返回false
*/
boolean removeBucket(String bucketName);
/**
* 创建一个新的存储桶
*
* @param bucketName 新存储桶的名称
*/
void createBucket(String bucketName);
/**
* 获取当前存储系统中的所有存储桶列表
*
* @return 包含所有存储桶的列表
*/
List
* 应用场景
- 外出旅游,选择骑自行车、坐汽车、飞机等,每一种旅行方式都是一个策略
- 如果在一个系统里面有许多类,它们之间的区别仅在于它们的行为,那么可以使用策略模式
- 不希望暴露复杂的、与算法有关的数据结构,那么可以使用策略模式来封装算法
* 为什么要抽象存储引擎接口
* 将文件存储引擎的接口抽象出来,具体实现可以多种,提高系统的灵活性和可维护性。
* 允许我们根据不同的需求和环境(如开发、测试、生产)灵活切换不同的存储解决方案
* 优点
- **灵活性和可扩展性**:通过定义一个统一的存储接口,我们可以在不修改客户端代码的情况下引入新的存储解决方案。
- **解耦**:将存储逻辑从业务逻辑中解耦,使得存储引擎的变化不影响业务逻辑。
- **易于测试**:可以针对接口编写单元测试,而不必依赖具体的存储实现。
- **代码复用**:多个项目可以共享相同的存储接口,提高代码复用率。
- **简化维护**:统一的接口使得维护和更新存储逻辑变得更加简单。
* 缺点
- **复杂性增加**:需要额外定义接口和可能的抽象类,增加了系统的复杂性。
- **性能考虑**:接口调用可能引入额外的性能开销,尤其是在接口频繁调用的情况下。
- **实现一致性**:确保所有存储策略实现都遵循相同的接口规范,需要严格的代码审查和测试。
* 注意
* **其实aws-java-sdk-s3本身就是封装好了,支持多个存储的,为啥我们又要加一层呢???**
* 假想下
* 万一我以后不用aws-java-sdk-s3,那岂不是四处要修改aws-java-sdk-s3的API方法
* 但如果我加了一层,其他地方使用的话,后续修改换别的SDK,我只需要修改我自己封装的那层即可
#### SpringBoot3.X整合MinIO存储AWS-S3封装
封装存储引擎接口设计【常规版】
* * 定义一个名为StorageEngine的接口,包含多个方法
* 可以跟进需求,实现`StorageEngine`接口的不同存储策略
- **LocalFileStorageEngine**:使用本地文件系统作为存储。
- **S3StorageEngine**:使用Amazon S3作为存储。
- **DatabaseStorageEngine**:使用数据库存储文件元数据和内容。
- **MinIOStorageEngine**:使用MinIO存储文件内容。
- ...
* 使用策略模式的优势
- **客户端代码与存储实现解耦**:客户端代码只需与`StorageEngine`接口交互,不需要关心具体的存储细节。
- **易于切换存储策略**:根据不同的业务需求或环境(开发、测试、生产)灵活切换不同的存储策略。
- **支持A/B测试**:可以同时运行多个存储策略,进行性能和效果比较。
* 抽取文件操作相关接口 StoreEngine
```java
public interface StoreEngine {
/*=====================Bucket相关===========================*/
/**
* 检查指定的存储桶是否存在于当前的存储系统中
*
* @param bucketName 存储桶的名称
* @return 如果存储桶存在,则返回true;否则返回false
*/
boolean bucketExists(String bucketName);
/**
* 删除指定名称的存储桶
*
* @param bucketName 存储桶的名称
* @return 如果存储桶删除成功,则返回true;否则返回false
*/
boolean removeBucket(String bucketName);
/**
* 创建一个新的存储桶
*
* @param bucketName 新存储桶的名称
*/
void createBucket(String bucketName);
/**
* 获取当前存储系统中的所有存储桶列表
*
* @return 包含所有存储桶的列表
*/
List * 智能云盘
* 智能云盘
 * 云盘存储相关设计说明
* 任何文件都有一个唯一标识,我们统一命名为 **identifier**,同个文件产生的标识是不变的
* 唯一标识(identifier)可以采用多个方案,也有对应的类库
* 哈希函数(如MD5、SHA-256)
* 优点:
* 唯一性:理论上 不同的文件内容会产生不同的哈希值,保证了标识的唯一性。
* 快速计算:哈希函数可以快速计算出文件的哈希值。
* 安全性:对于SHA-256等哈希算法,抗碰撞性较强,不易被篡改。
* 缺点:
* 安全性问题:对于MD5,由于其抗碰撞性较弱,已经不推荐用于安全敏感的应用。
* 存储和比较:哈希值需要存储和比较,对于非常大的文件系统,这可能会增加存储和计算开销。
* 基于内容的指纹(如SimHash、Locality-Sensitive Hashing)
* 优点:
* 相似性检测:适用于检测相似或重复的文件,可以容忍文件内容的微小变化。
* 减少存储:通过减少哈希值的位数来减少存储需求。
* 缺点:
* 计算复杂性:相比于简单的哈希函数,这些算法可能需要更复杂的计算。
* 误判率:在某些情况下可能会有误判,即不同的文件产生相同的指纹。
* 文件元数据组合
* 优点:
* 简单易实现:通过文件的大小、创建时间、修改时间等元数据生成标识。
* 快速检索:基于元数据的检索通常很快。
* 缺点:
* 非唯一性:不同的文件可能具有相同的元数据,特别是在文件被复制或修改的情况下。
* 不稳定性:文件的元数据(如修改时间)可能会改变,导致标识失效
* 方案:采用MD5, 相关标识可以前端和后端保持一定规则,前端上传的时候生成标识传递给后端
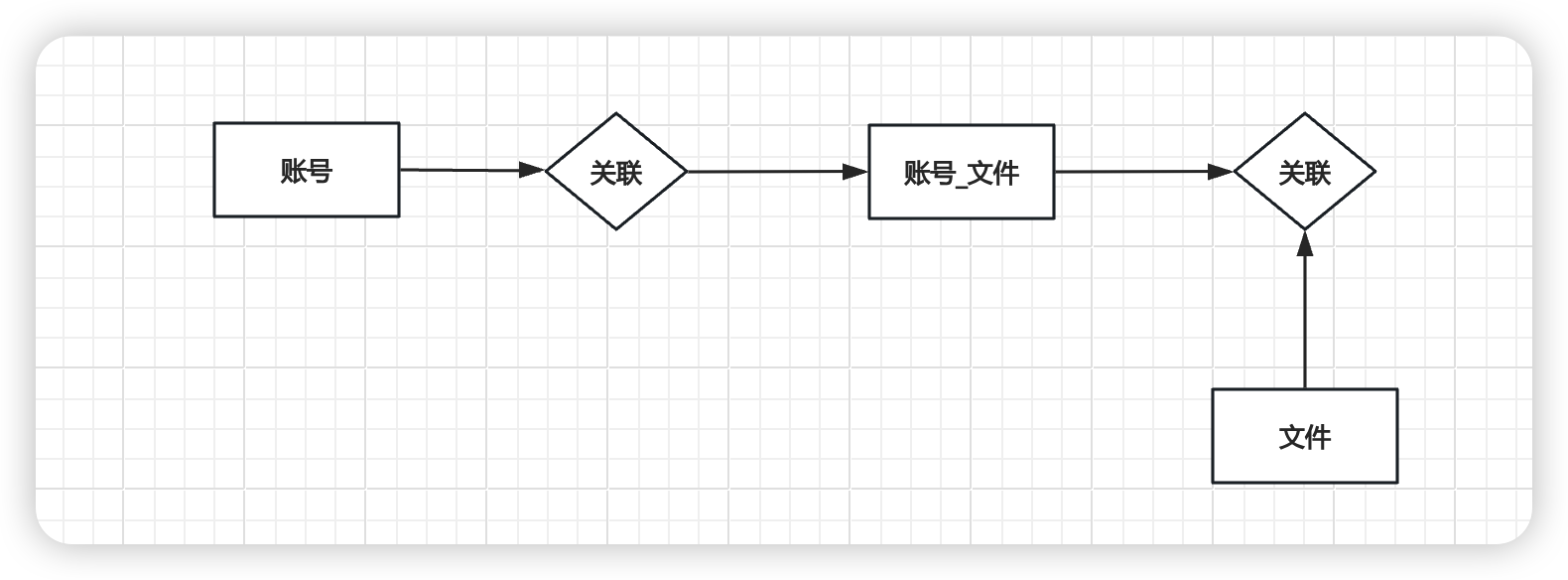
#### 账号表-文件表和关联关系表设计说明
* 三个关键表说明
* **account表**:存储用户的基本信息,如用户名、密码、头像等。这是用户身份验证和个性化设置的基础。
* **file表**:存储文件的元数据,包括文件名、大小、后缀、唯一标识符(MD5)等。主要用于跟踪文件的属性和文件的唯一性
* **account_file表**:
* 存储用户与文件之间的关系,包括文件的层级结构(文件夹和子文件),以及文件的类型和大小等信息。
* 这个表允许一个用户有多个子文件和文件夹,并且可以表示文件的层级关系
* 如果没有`account_file`表,
* 每个用户都重复上传,随着文件数量的增加,没有`account_file`表来组织文件结构,`file`表会变得非常大,性能问题
* 无法有效地表示文件和文件夹的层级结构
* 实现文件的移动、复制、删除等操作会变得复杂,因为没有一个明确的结构来跟踪文件的层级和用户关系
* 权限管理也会变得更加复杂,因为没有一个清晰的结构来定义哪些文件可以被哪些用户访问。
* 智能化云盘设计的3个表理解清楚
* 账号表
* 记录账号相关基础信息
* 关键字段
```
id 即后续用的 account_id
username
password
role 用户角色 COMMON, ADMIN
```
* 账号文件关系表
* 记录对应账号下的文件和文件夹、关系等
* 关键字段
```
id
account_id 账号ID
is_dir 是否是目录,0不是文件夹,1是文件夹
parent_id 上层文件夹ID,顶层文件夹为0
file_id 文件ID,真正存储的文件
file_name 文件名和实际存储的文件名区分开来,可能重命名
```
* 文件表
* 记录文件相关的物理存储信息
```
id 即file_id
account_id 哪个账号上传的
file_name 文件名
object_key 文件的key, 格式 日期/md5.拓展名,比如 2024/11/13/921674fd-cdaf-459a-be7b-109469e7050d.png
identifier 唯一标识,文件MD5
```
#### AI智能化云盘数据库设计和字段说明
* 数据库ER图设计(**后续还有调整相关表结构**)
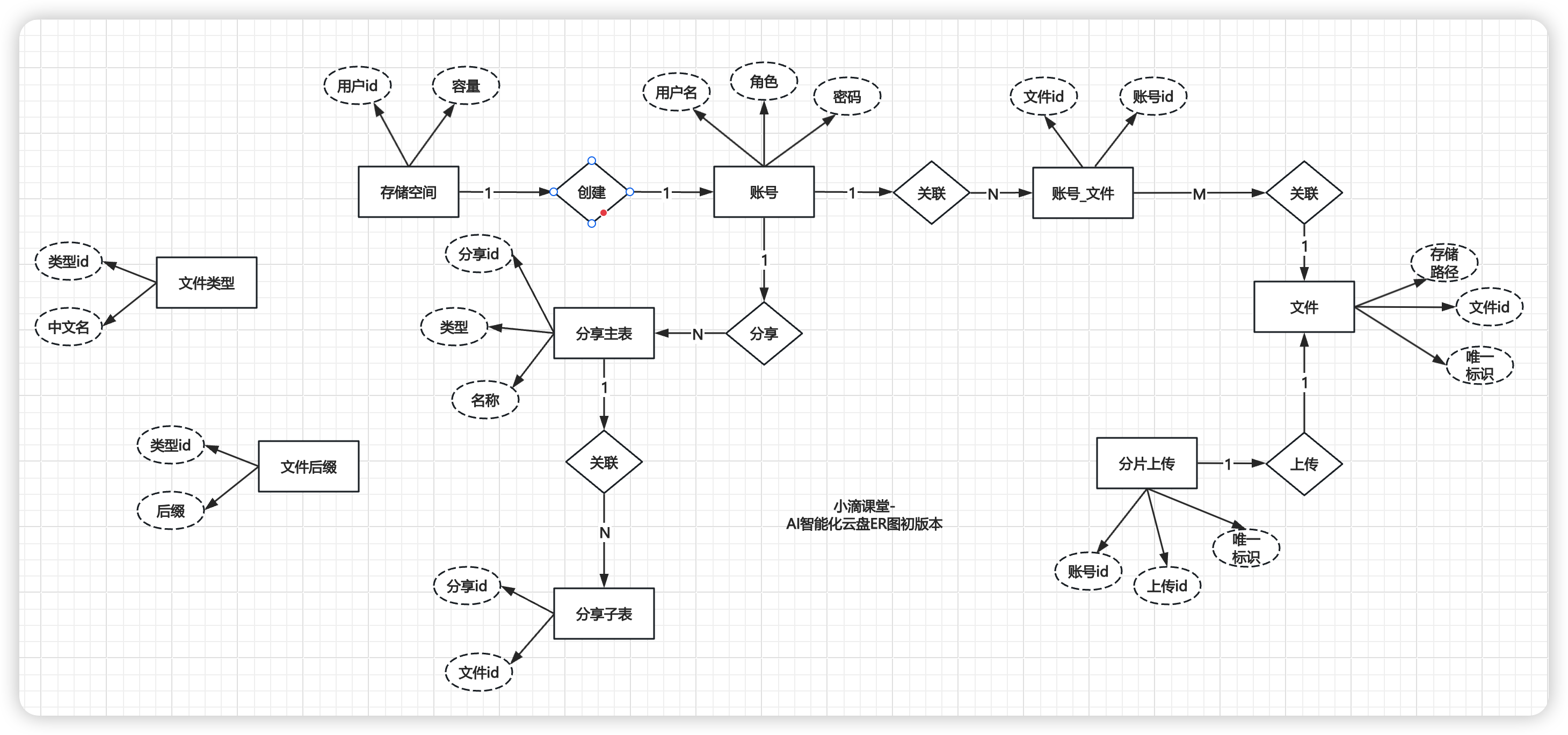
* 导入建表语句
#### 智能化云盘数据库逆向工程配置生成
* 配置数据库
```java
public class MyBatisPlusGenerator {
public static void main(String[] args) {
String userName = "root";
String password = "xx";
String serverInfo = "127.0.0.1:3306";
String targetModuleNamePath = "/";
String dbName = "ycloud-aipan";
String[] tables = {
"account", "file","account_file","file_chunk", "file_suffix","file_type", "share", "share_file", "storage"
};
// 使用 FastAutoGenerator 快速配置代码生成器
FastAutoGenerator.create("jdbc:mysql://"+serverInfo+"/"+dbName+"?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&tinyInt1isBit=true", userName, password)
.globalConfig(builder -> {
builder.author("everyone") // 设置作者
.commentDate("yyyy-MM-dd")
.enableSpringdoc()
.disableOpenDir() //禁止打开输出目录
.dateType(DateType.ONLY_DATE) //定义生成的实体类中日期类型 DateType.ONLY_DATE 默认值: DateType.TIME_PACK
.outputDir(System.getProperty("user.dir") + targetModuleNamePath + "/src/main/java"); // 指定输出目录
})
.packageConfig(builder -> {
builder.parent("org.ycloud.aipan") // 父包模块名
.entity("model") //Entity 包名 默认值:entity
.mapper("mapper") //Mapper 包名 默认值:mapper
.pathInfo(Collections.singletonMap(OutputFile.xml, System.getProperty("user.dir") + targetModuleNamePath + "/src/main/resources/mapper")); // 设置mapperXml生成路,默认存放在mapper的xml下
})
.dataSourceConfig(builder -> {//Mysql下tinyint字段转换
builder.typeConvertHandler((globalConfig, typeRegistry, metaInfo) -> {
if (JdbcType.TINYINT == metaInfo.getJdbcType()) {
return DbColumnType.BOOLEAN;
}
return typeRegistry.getColumnType(metaInfo);
});
})
.strategyConfig(builder -> {
builder.addInclude(tables) // 设置需要生成的表名 可变参数
.entityBuilder()// Entity策略配置
.enableFileOverride() // 开启生成Entity层文件覆盖
.idType(IdType.ASSIGN_ID)//主键策略 雪花算法自动生成的id
.enableLombok() //开启lombok
.logicDeleteColumnName("del")// 说明逻辑删除是哪个字段
.enableTableFieldAnnotation()// 属性加上注解说明
.formatFileName("%sDO") //格式化生成的文件名称
.controllerBuilder().disable()// Controller策略配置,这里不生成Controller层
.serviceBuilder().disable()// Service策略配置,这里不生成Service层
.mapperBuilder()// Mapper策略配置
.enableFileOverride() // 开启生成Mapper层文件覆盖
.formatMapperFileName("%sMapper")// 格式化Mapper文件名称
.superClass(BaseMapper.class) //继承的父类
.enableBaseResultMap() // 开启生成resultMap,
.enableBaseColumnList() // 开启生成Sql片段
.formatXmlFileName("%sMapper"); // 格式化xml文件名称
})
.templateConfig(builder -> {
// 不生成Controller
builder.disable(TemplateType.CONTROLLER,TemplateType.SERVICE,TemplateType.SERVICE_IMPL);
})
.execute(); // 执行生成
}
}
```
### 账号模块开发和Knife4j接口文档配置
#### Knife4j接口文档工具
* 什么是Knife4j
* 一个为Java MVC框架集成Swagger生成Api文档的增强解决方案,前身是swagger-bootstrap-ui。
* 提供了新的Web页面,更符合使用习惯和审美;补充了一些注解,扩展了原生Swagger的功能;
* 是一个更小巧、轻量且功能强悍的接口文档管理工具
* 核心功能
* **文档说明**:详细列出接口文档的说明,包括接口地址、类型、请求示例、请求参数、响应示例、响应参数、响应码等信息。
* **在线调试**:提供在线接口联调功能,自动解析当前接口参数,返回接口响应内容、headers、响应时间、响应状态码等信息。
* **接口搜索**:提供强大的接口搜索功能,支持按接口地址、请求方法、接口描述等关键字进行搜索。
* **接口过滤**:提供接口过滤功能,可以根据接口分组、接口标签、接口地址等条件进行过滤。
* **自定义主题**:支持自定义主题,定制个性化的API文档界面。
* **丰富的扩展功能**:如接口排序、接口分组、接口标签等,进一步丰富了API文档管理的功能。
* 配置实战
* 添加依赖
```xml
* 云盘存储相关设计说明
* 任何文件都有一个唯一标识,我们统一命名为 **identifier**,同个文件产生的标识是不变的
* 唯一标识(identifier)可以采用多个方案,也有对应的类库
* 哈希函数(如MD5、SHA-256)
* 优点:
* 唯一性:理论上 不同的文件内容会产生不同的哈希值,保证了标识的唯一性。
* 快速计算:哈希函数可以快速计算出文件的哈希值。
* 安全性:对于SHA-256等哈希算法,抗碰撞性较强,不易被篡改。
* 缺点:
* 安全性问题:对于MD5,由于其抗碰撞性较弱,已经不推荐用于安全敏感的应用。
* 存储和比较:哈希值需要存储和比较,对于非常大的文件系统,这可能会增加存储和计算开销。
* 基于内容的指纹(如SimHash、Locality-Sensitive Hashing)
* 优点:
* 相似性检测:适用于检测相似或重复的文件,可以容忍文件内容的微小变化。
* 减少存储:通过减少哈希值的位数来减少存储需求。
* 缺点:
* 计算复杂性:相比于简单的哈希函数,这些算法可能需要更复杂的计算。
* 误判率:在某些情况下可能会有误判,即不同的文件产生相同的指纹。
* 文件元数据组合
* 优点:
* 简单易实现:通过文件的大小、创建时间、修改时间等元数据生成标识。
* 快速检索:基于元数据的检索通常很快。
* 缺点:
* 非唯一性:不同的文件可能具有相同的元数据,特别是在文件被复制或修改的情况下。
* 不稳定性:文件的元数据(如修改时间)可能会改变,导致标识失效
* 方案:采用MD5, 相关标识可以前端和后端保持一定规则,前端上传的时候生成标识传递给后端
#### 账号表-文件表和关联关系表设计说明
* 三个关键表说明
* **account表**:存储用户的基本信息,如用户名、密码、头像等。这是用户身份验证和个性化设置的基础。
* **file表**:存储文件的元数据,包括文件名、大小、后缀、唯一标识符(MD5)等。主要用于跟踪文件的属性和文件的唯一性
* **account_file表**:
* 存储用户与文件之间的关系,包括文件的层级结构(文件夹和子文件),以及文件的类型和大小等信息。
* 这个表允许一个用户有多个子文件和文件夹,并且可以表示文件的层级关系
* 如果没有`account_file`表,
* 每个用户都重复上传,随着文件数量的增加,没有`account_file`表来组织文件结构,`file`表会变得非常大,性能问题
* 无法有效地表示文件和文件夹的层级结构
* 实现文件的移动、复制、删除等操作会变得复杂,因为没有一个明确的结构来跟踪文件的层级和用户关系
* 权限管理也会变得更加复杂,因为没有一个清晰的结构来定义哪些文件可以被哪些用户访问。

* 智能化云盘设计的3个表理解清楚
* 账号表
* 记录账号相关基础信息
* 关键字段
```
id 即后续用的 account_id
username
password
role 用户角色 COMMON, ADMIN
```
* 账号文件关系表
* 记录对应账号下的文件和文件夹、关系等
* 关键字段
```
id
account_id 账号ID
is_dir 是否是目录,0不是文件夹,1是文件夹
parent_id 上层文件夹ID,顶层文件夹为0
file_id 文件ID,真正存储的文件
file_name 文件名和实际存储的文件名区分开来,可能重命名
```
* 文件表
* 记录文件相关的物理存储信息
```
id 即file_id
account_id 哪个账号上传的
file_name 文件名
object_key 文件的key, 格式 日期/md5.拓展名,比如 2024/11/13/921674fd-cdaf-459a-be7b-109469e7050d.png
identifier 唯一标识,文件MD5
```
#### AI智能化云盘数据库设计和字段说明
* 数据库ER图设计(**后续还有调整相关表结构**)

* 导入建表语句
#### 智能化云盘数据库逆向工程配置生成
* 配置数据库
```java
public class MyBatisPlusGenerator {
public static void main(String[] args) {
String userName = "root";
String password = "xx";
String serverInfo = "127.0.0.1:3306";
String targetModuleNamePath = "/";
String dbName = "ycloud-aipan";
String[] tables = {
"account", "file","account_file","file_chunk", "file_suffix","file_type", "share", "share_file", "storage"
};
// 使用 FastAutoGenerator 快速配置代码生成器
FastAutoGenerator.create("jdbc:mysql://"+serverInfo+"/"+dbName+"?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai&tinyInt1isBit=true", userName, password)
.globalConfig(builder -> {
builder.author("everyone") // 设置作者
.commentDate("yyyy-MM-dd")
.enableSpringdoc()
.disableOpenDir() //禁止打开输出目录
.dateType(DateType.ONLY_DATE) //定义生成的实体类中日期类型 DateType.ONLY_DATE 默认值: DateType.TIME_PACK
.outputDir(System.getProperty("user.dir") + targetModuleNamePath + "/src/main/java"); // 指定输出目录
})
.packageConfig(builder -> {
builder.parent("org.ycloud.aipan") // 父包模块名
.entity("model") //Entity 包名 默认值:entity
.mapper("mapper") //Mapper 包名 默认值:mapper
.pathInfo(Collections.singletonMap(OutputFile.xml, System.getProperty("user.dir") + targetModuleNamePath + "/src/main/resources/mapper")); // 设置mapperXml生成路,默认存放在mapper的xml下
})
.dataSourceConfig(builder -> {//Mysql下tinyint字段转换
builder.typeConvertHandler((globalConfig, typeRegistry, metaInfo) -> {
if (JdbcType.TINYINT == metaInfo.getJdbcType()) {
return DbColumnType.BOOLEAN;
}
return typeRegistry.getColumnType(metaInfo);
});
})
.strategyConfig(builder -> {
builder.addInclude(tables) // 设置需要生成的表名 可变参数
.entityBuilder()// Entity策略配置
.enableFileOverride() // 开启生成Entity层文件覆盖
.idType(IdType.ASSIGN_ID)//主键策略 雪花算法自动生成的id
.enableLombok() //开启lombok
.logicDeleteColumnName("del")// 说明逻辑删除是哪个字段
.enableTableFieldAnnotation()// 属性加上注解说明
.formatFileName("%sDO") //格式化生成的文件名称
.controllerBuilder().disable()// Controller策略配置,这里不生成Controller层
.serviceBuilder().disable()// Service策略配置,这里不生成Service层
.mapperBuilder()// Mapper策略配置
.enableFileOverride() // 开启生成Mapper层文件覆盖
.formatMapperFileName("%sMapper")// 格式化Mapper文件名称
.superClass(BaseMapper.class) //继承的父类
.enableBaseResultMap() // 开启生成resultMap,
.enableBaseColumnList() // 开启生成Sql片段
.formatXmlFileName("%sMapper"); // 格式化xml文件名称
})
.templateConfig(builder -> {
// 不生成Controller
builder.disable(TemplateType.CONTROLLER,TemplateType.SERVICE,TemplateType.SERVICE_IMPL);
})
.execute(); // 执行生成
}
}
```
### 账号模块开发和Knife4j接口文档配置
#### Knife4j接口文档工具
* 什么是Knife4j
* 一个为Java MVC框架集成Swagger生成Api文档的增强解决方案,前身是swagger-bootstrap-ui。
* 提供了新的Web页面,更符合使用习惯和审美;补充了一些注解,扩展了原生Swagger的功能;
* 是一个更小巧、轻量且功能强悍的接口文档管理工具
* 核心功能
* **文档说明**:详细列出接口文档的说明,包括接口地址、类型、请求示例、请求参数、响应示例、响应参数、响应码等信息。
* **在线调试**:提供在线接口联调功能,自动解析当前接口参数,返回接口响应内容、headers、响应时间、响应状态码等信息。
* **接口搜索**:提供强大的接口搜索功能,支持按接口地址、请求方法、接口描述等关键字进行搜索。
* **接口过滤**:提供接口过滤功能,可以根据接口分组、接口标签、接口地址等条件进行过滤。
* **自定义主题**:支持自定义主题,定制个性化的API文档界面。
* **丰富的扩展功能**:如接口排序、接口分组、接口标签等,进一步丰富了API文档管理的功能。
* 配置实战
* 添加依赖
```xml
* knife4j 访问地址:http://localhost:8080/doc.html
* Swagger2.0访问地址:http://localhost:8080/swagger-ui.html
* Swagger3.0访问地址:http://localhost:8080/swagger-ui/index.html
*/
@Slf4j
@Configuration
public class Knife4jConfig {
@Bean
public OpenAPI customOpenAPI() {
return new OpenAPI()
.info(new Info()
.title("AI智能云盘系统 API")
.version("1.0-SNAPSHOT")
.description("AI智能云盘系统")
.termsOfService("https://www.xxx.net")
.license(new License().name("Apache 2.0").url("https://www.xxx.net"))
// 添加作者信息
.contact(new Contact()
.name("anonymity") // 替换为作者的名字
.email("anonymity@qq.com") // 替换为作者的电子邮件
.url("https://www.xxx.net") // 替换为作者的网站或个人资料链接
)
);
}
}
```
* 配置Spring Boot控制台打印
```java
@Slf4j
@SpringBootApplication
public class CloudApplication {
public static void main(String[] args) throws Exception {
ConfigurableApplicationContext application = SpringApplication.run(CloudApplication.class, args);
Environment env = application.getEnvironment();
log.info("\n----------------------------------------------------------\n\t" +
"Application '{}' is running! Access URLs:\n\t" +
"Local: \t\thttp://localhost:{}\n\t" +
"External: \thttp://{}:{}\n\t" +
"API文档: \thttp://{}:{}/doc.html\n" +
"----------------------------------------------------------",
env.getProperty("spring.application.name"),
env.getProperty("server.port"),
InetAddress.getLocalHost().getHostAddress(),
env.getProperty("server.port"),
InetAddress.getLocalHost().getHostAddress(),
env.getProperty("server.port"));
}
}
```
#### 账号注册相关模块接口开发实战
* 需求
* 开发用户注册相关接口,手机号注册
* 内部使用, 不加验证码,如果需要对外则可以加入验证码逻辑
* 用户板块不做复杂权限或者多重校验处理等
* 逻辑说明
* 根据手机号查询是否重复(或者唯一索引)
* 密码加密处理
* 保存用户注册逻辑
* 其他逻辑(创建默认的存储空间,初始化根目录)
* 编码实战:
> 编写`AccountController,AccountRegisterReq,AccountService,AccountConfig`...
```sql
CREATE TABLE `account` (
`id` bigint NOT NULL COMMENT 'ID',
`username` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '用户名',
`password` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL COMMENT '密码',
`avatar_url` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '用户头像',
`phone` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '手机号',
`role` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT 'COMMON' COMMENT '用户角色 COMMON, ADMIN',
`del` tinyint DEFAULT '0' COMMENT '逻辑删除(1删除 0未删除)',
`gmt_create` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`gmt_modified` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `idx_phone_uni` (`phone`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci ROW_FORMAT=DYNAMIC COMMENT='用户信息表';
```
#### 头像上传接口开发和MinIO权限配置
* 需求
* 开发头像上传接口,用户注册时候需要把头像url进行上传
* **存储到minio需要可以公开访问,和文件存储分开bucket**
* 逻辑说明
* 文件上传接口
* 返回文件访问路径
* **配置minio的头像存储bucket存储权限为public**
#### 网盘存储容量设计和根目录初始化配置
* 需求
* **问题一:新用户注册,有默认网盘存储容量,什么时候进行初始化?**
* 答案
* 用户注册的时候一并配置相关的初始化内容
* 如果是简单场景:直接调用; 复杂场景:结合消息队列
* 类似场景大家可以思考下还有哪些,各大公司拉新活动折扣
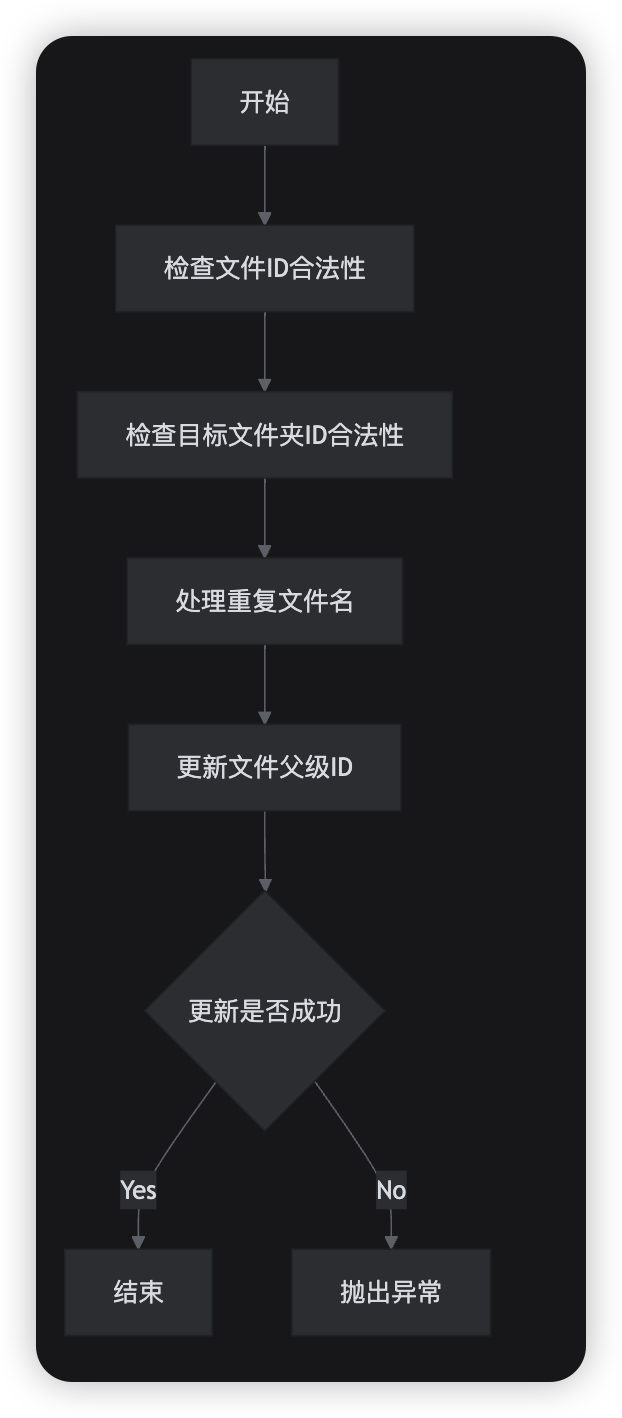
* 1、检查父文件ID是否存在,避免越权
* 2、检查文件名是否重复
* 3、保存文件信息
*
* @return
*/
private Long saveAccountFile(AccountFileDTO accountFileDTO) {
//检查父文件ID是否存在
checkParentFileId(accountFileDTO);
//存储文件信息
AccountFileDO accountFileDO = SpringBeanUtil.copyProperties(accountFileDTO, AccountFileDO.class);
//检查文件名是否重复
processFileNameDuplicate(accountFileDO);
accountFileMapper.insert(accountFileDO);
return accountFileDO.getId();
}
```
#### 网盘文件重命名相关接口
* 需求
* 开发网盘文件重命名接口,包括文件夹和文件一样适用
 * **问题二:网盘文件存储有个根目录,这个如何进行设计?**
* 上传文件的到根目录,这个相关的parent_id是怎么填写?
* 答案:参考Linux操作系统,根目录也是一个目录

* 开发编码实战:创建文件夹
```java
//3.创建默认的存储空间
StorageDO storageDO = new StorageDO();
storageDO.setAccountId(accountDO.getId());
storageDO.setUsedSize(0L);
storageDO.setTotalSize(AccountConfig.DEFAULT_STORAGE_SIZE);
storageMapper.insert(storageDO);
//4.初始化根目录
FolderCreateReq createRootFolderReq = FolderCreateReq.builder()
.accountId(accountDO.getId())
.parentId(AccountConfig.ROOT_PARENT_ID)
.folderName(AccountConfig.ROOT_FOLDER_NAME)
.build();
accountFileService.createFolder(createRootFolderReq);
```
#### 账号登录相关模块设计和开发实战
* 需求
* 开发用户登录模块
* 配置生成JWT
* 编码实战
```java
//业务逻辑
public AccountDTO login(AccountLoginReq req) {
String encryptPassword = DigestUtils.md5DigestAsHex(( AccountConfig.ACCOUNT_SALT+ req.getPassword()).getBytes());
QueryWrapper
* 逻辑说明
* 步骤一
* 进入首页需要先获取用户的根目录文件夹ID
* 通过根目录文件夹ID去获取对应的文件列表
* 步骤二
* 首页需要显示用户的存储空间
* 编码实战
```java
public AccountDTO queryDetail(Long accountId) {
//账号详情
AccountDO accountDO = accountMapper.selectById(accountId);
AccountDTO accountDTO = SpringBeanUtil.copyProperties(accountDO, AccountDTO.class);
//存储信息
StorageDO storageDO = storageMapper.selectOne(new QueryWrapper
* **问题二:网盘文件存储有个根目录,这个如何进行设计?**
* 上传文件的到根目录,这个相关的parent_id是怎么填写?
* 答案:参考Linux操作系统,根目录也是一个目录

* 开发编码实战:创建文件夹
```java
//3.创建默认的存储空间
StorageDO storageDO = new StorageDO();
storageDO.setAccountId(accountDO.getId());
storageDO.setUsedSize(0L);
storageDO.setTotalSize(AccountConfig.DEFAULT_STORAGE_SIZE);
storageMapper.insert(storageDO);
//4.初始化根目录
FolderCreateReq createRootFolderReq = FolderCreateReq.builder()
.accountId(accountDO.getId())
.parentId(AccountConfig.ROOT_PARENT_ID)
.folderName(AccountConfig.ROOT_FOLDER_NAME)
.build();
accountFileService.createFolder(createRootFolderReq);
```
#### 账号登录相关模块设计和开发实战
* 需求
* 开发用户登录模块
* 配置生成JWT
* 编码实战
```java
//业务逻辑
public AccountDTO login(AccountLoginReq req) {
String encryptPassword = DigestUtils.md5DigestAsHex(( AccountConfig.ACCOUNT_SALT+ req.getPassword()).getBytes());
QueryWrapper
* 逻辑说明
* 步骤一
* 进入首页需要先获取用户的根目录文件夹ID
* 通过根目录文件夹ID去获取对应的文件列表
* 步骤二
* 首页需要显示用户的存储空间
* 编码实战
```java
public AccountDTO queryDetail(Long accountId) {
//账号详情
AccountDO accountDO = accountMapper.selectById(accountId);
AccountDTO accountDTO = SpringBeanUtil.copyProperties(accountDO, AccountDTO.class);
//存储信息
StorageDO storageDO = storageMapper.selectOne(new QueryWrapper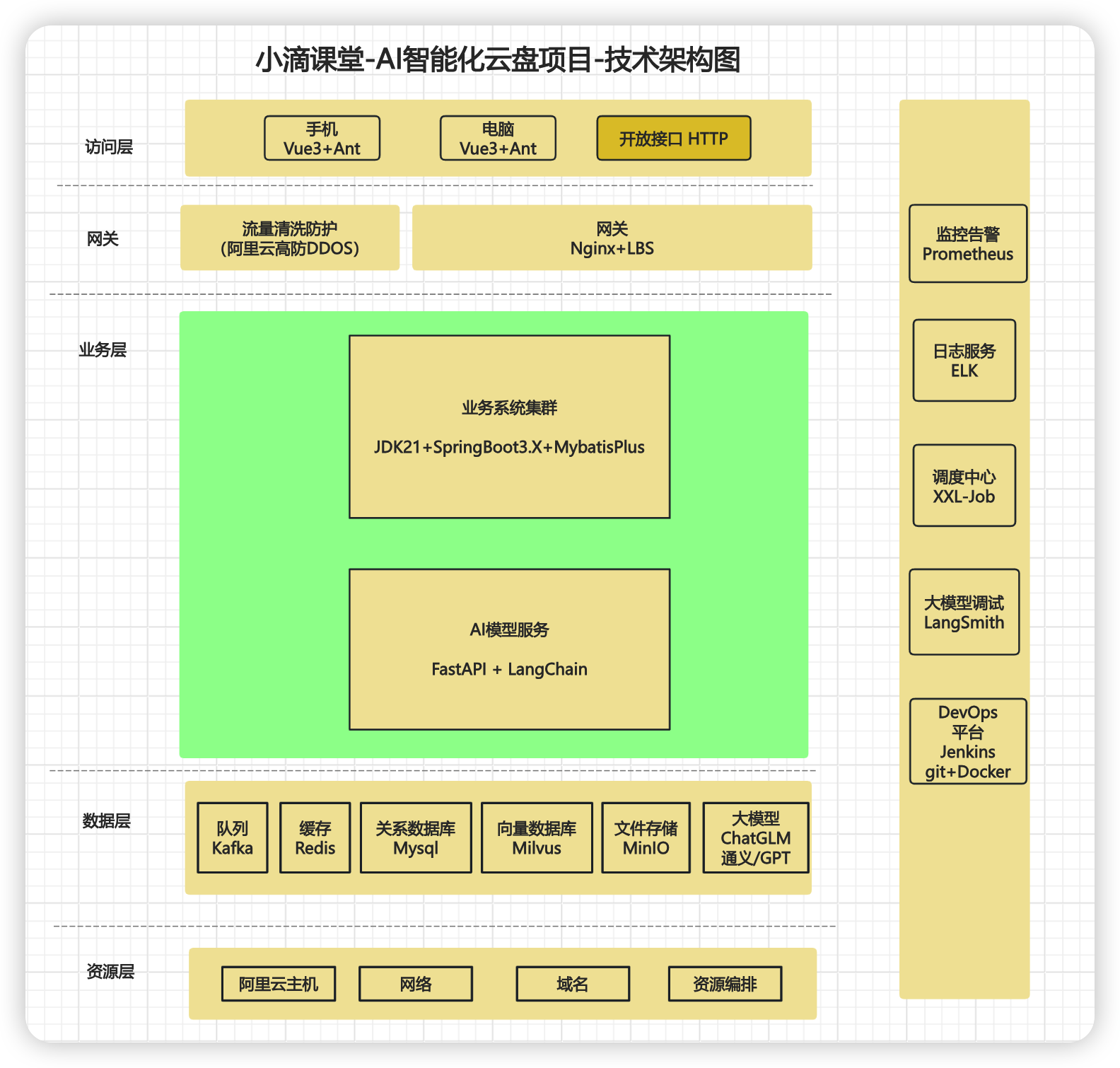 AI补充接口文档和注释字段操作
* AI补充API接口文档
* `补充knife4j的接口文档配置内容,@Tag @Operation等注解,使用v3`
* AI补充字段解释说明
* `补充knife4j接口文档信息,使用@Schema,使用v3,添加参数举例`
### 网盘文件模块基础设计和开发
#### 资源访问安全之web常见越权攻击和防范
* **越权攻击介绍**
* 是Web应用程序中一种常见的漏洞,由于其存在范围广、危害 大, 列为Web应用十大安全隐患的第二名
* 指应用在检查授权时存在纰漏,使得攻击者在获得低权限用户账户后,利用一些方式绕过权限检查,访问或者操作其他用户
* 产生原因:主要是因为开发人员在对数据进行增、删、改、查询时对客户端请求的数据过分相信,而遗漏了权限的判定
* 比如网盘里面:分享、转存、查看文件的时候都容易触发
* **水平越权攻击**
- 指的是攻击者通过某种手段获取了与自己权限相同的其他账户的访问权限。
- 用户A能够访问用户B的账户信息,尽管他们都是普通用户,但A不应该能够访问B的数据。
- 技术实现方式
- **参数篡改**:
- 攻击者通过修改请求中的用户ID参数,尝试访问其他同级别用户的资源。
- 在电商系统中,用户A通过修改订单ID参数,尝试查看或修改用户B的订单信息。
- **会话劫持**:
- 攻击者通过某种方式获取了其他用户的会话信息,从而冒充该用户进行操作,这可能导致水平越权问题。
- **利用前端安全漏洞**:
- 如果前端安全措施不当,攻击者可能会通过修改前端显示的界面元素,如隐藏的URL或参数,来访问其他用户的数据。
* **水平越权攻击的防范**:
- **权限验证**:确保每次数据访问都进行严格的权限验证。
- **数据隔离**:不同用户的数据应该在数据库层面进行隔离。
- **会话管理**:使用安全的会话管理机制,如HTTPS、Token等。
* **垂直越权攻击**
- 指的是攻击者通过某种手段获取了更高权限的账户的访问权限。
- 普通用户获取了管理员账户或者更高的权限。
- 技术实现方式
- **权限配置错误**:
- 由于系统配置不当,普通用户能够执行管理员级别的操作,例如通过修改请求中的权限参数来提升权限。
- **利用系统漏洞**:
- 攻击者利用系统或应用程序的漏洞提升权限,例如通过SQL注入攻击来执行管理员级别的数据库操作。
- **多阶段功能滥用**:
- 在多阶段功能实现中,如果后续阶段不再验证用户身份,攻击者可能通过抓包修改参数值,实现越权操作,如修改任意用户密码
- **垂直越权攻击的防范**:
- **最小权限原则**:用户和系统组件应该只拥有完成其任务所必需的最小权限。
- **权限审查**:定期审查权限设置,确保没有不必要的权限提升。
- **安全编码**:遵循安全编码实践,避免常见的安全漏洞,如SQL注入、跨站脚本(XSS)等。
- **安全审计**:实施安全审计,监控和记录关键操作,以便在发生安全事件时进行追踪。
* 智能化网盘项目里面的避免越权处理方案
* 相关文件数据处理,加入account_id确认
* 角色权限通过role进行确认操作
#### 文件模块开发之查询文件列表接口开发
* 需求
* 网盘存储首页进入,会触发哪些请求?**获取当前用户根目录文件夹**
* 根据根目录文件夹查询对应的文件列表
* 进入相关的指定文件夹,查询对应的子文件
* 注意事项
* 查询的时候都需要加入账号相关进行确认
**前面代码相对会简单点,逐步代码封装和抽取就会上升难度,**
* 编码实战
```java
@GetMapping("list")
public JsonData list(@RequestParam(value = "parent_id")Long parentId){
Long accountId = LoginInterceptor.threadLocal.get().getId();
List
AI补充接口文档和注释字段操作
* AI补充API接口文档
* `补充knife4j的接口文档配置内容,@Tag @Operation等注解,使用v3`
* AI补充字段解释说明
* `补充knife4j接口文档信息,使用@Schema,使用v3,添加参数举例`
### 网盘文件模块基础设计和开发
#### 资源访问安全之web常见越权攻击和防范
* **越权攻击介绍**
* 是Web应用程序中一种常见的漏洞,由于其存在范围广、危害 大, 列为Web应用十大安全隐患的第二名
* 指应用在检查授权时存在纰漏,使得攻击者在获得低权限用户账户后,利用一些方式绕过权限检查,访问或者操作其他用户
* 产生原因:主要是因为开发人员在对数据进行增、删、改、查询时对客户端请求的数据过分相信,而遗漏了权限的判定
* 比如网盘里面:分享、转存、查看文件的时候都容易触发
* **水平越权攻击**
- 指的是攻击者通过某种手段获取了与自己权限相同的其他账户的访问权限。
- 用户A能够访问用户B的账户信息,尽管他们都是普通用户,但A不应该能够访问B的数据。
- 技术实现方式
- **参数篡改**:
- 攻击者通过修改请求中的用户ID参数,尝试访问其他同级别用户的资源。
- 在电商系统中,用户A通过修改订单ID参数,尝试查看或修改用户B的订单信息。
- **会话劫持**:
- 攻击者通过某种方式获取了其他用户的会话信息,从而冒充该用户进行操作,这可能导致水平越权问题。
- **利用前端安全漏洞**:
- 如果前端安全措施不当,攻击者可能会通过修改前端显示的界面元素,如隐藏的URL或参数,来访问其他用户的数据。
* **水平越权攻击的防范**:
- **权限验证**:确保每次数据访问都进行严格的权限验证。
- **数据隔离**:不同用户的数据应该在数据库层面进行隔离。
- **会话管理**:使用安全的会话管理机制,如HTTPS、Token等。
* **垂直越权攻击**
- 指的是攻击者通过某种手段获取了更高权限的账户的访问权限。
- 普通用户获取了管理员账户或者更高的权限。
- 技术实现方式
- **权限配置错误**:
- 由于系统配置不当,普通用户能够执行管理员级别的操作,例如通过修改请求中的权限参数来提升权限。
- **利用系统漏洞**:
- 攻击者利用系统或应用程序的漏洞提升权限,例如通过SQL注入攻击来执行管理员级别的数据库操作。
- **多阶段功能滥用**:
- 在多阶段功能实现中,如果后续阶段不再验证用户身份,攻击者可能通过抓包修改参数值,实现越权操作,如修改任意用户密码
- **垂直越权攻击的防范**:
- **最小权限原则**:用户和系统组件应该只拥有完成其任务所必需的最小权限。
- **权限审查**:定期审查权限设置,确保没有不必要的权限提升。
- **安全编码**:遵循安全编码实践,避免常见的安全漏洞,如SQL注入、跨站脚本(XSS)等。
- **安全审计**:实施安全审计,监控和记录关键操作,以便在发生安全事件时进行追踪。
* 智能化网盘项目里面的避免越权处理方案
* 相关文件数据处理,加入account_id确认
* 角色权限通过role进行确认操作
#### 文件模块开发之查询文件列表接口开发
* 需求
* 网盘存储首页进入,会触发哪些请求?**获取当前用户根目录文件夹**
* 根据根目录文件夹查询对应的文件列表
* 进入相关的指定文件夹,查询对应的子文件
* 注意事项
* 查询的时候都需要加入账号相关进行确认
**前面代码相对会简单点,逐步代码封装和抽取就会上升难度,**
* 编码实战
```java
@GetMapping("list")
public JsonData list(@RequestParam(value = "parent_id")Long parentId){
Long accountId = LoginInterceptor.threadLocal.get().getId();
List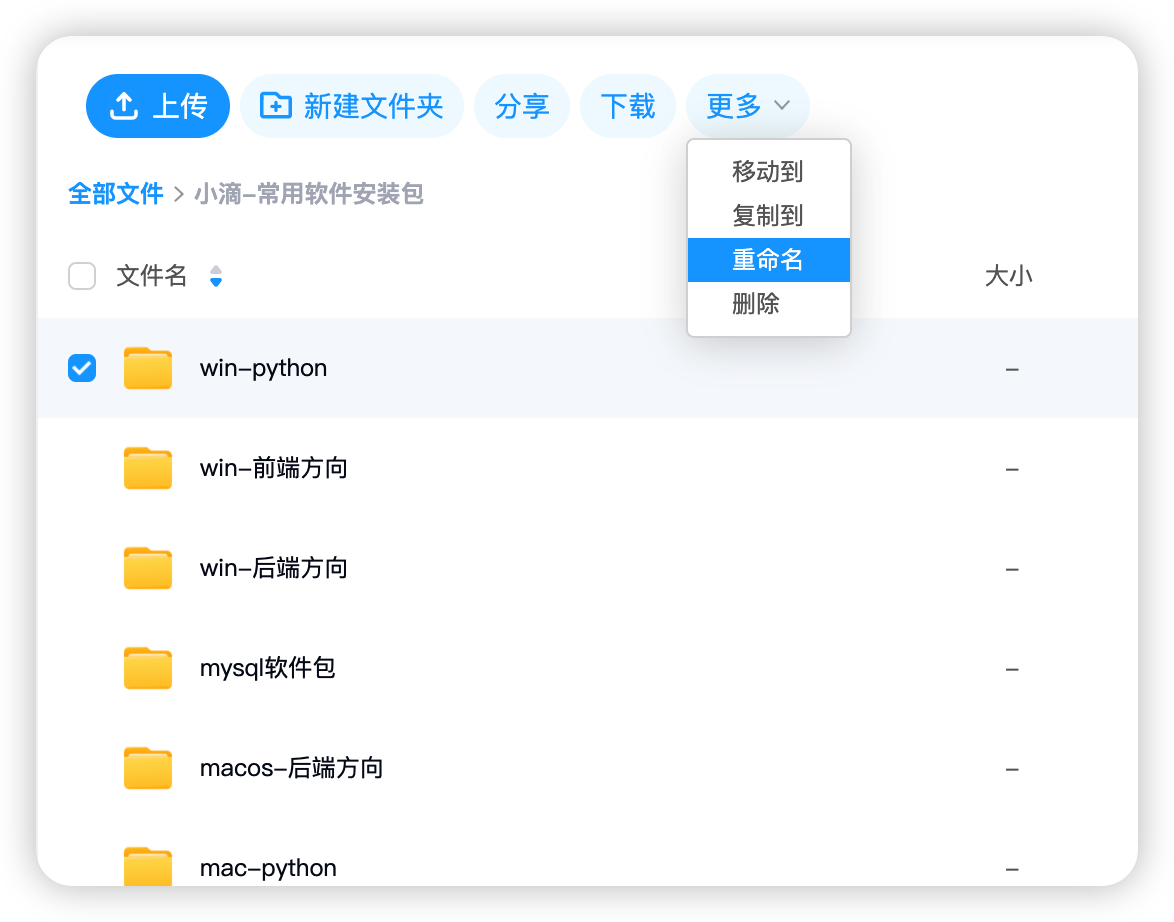 * 业务逻辑方法梳理
* 文件ID是否存在,避免越权
* 新旧文件名称不能一样
* 也不能用同层文件夹的名称,通过parent_id进行查询
* 编码实战
```java
@Override
public void renameFile(FileUpdateReq req) {
//文件ID是否存在,避免越权
AccountFileDO accountFileDO = accountFileMapper.selectOne(new QueryWrapper
* 业务逻辑方法梳理
* 文件ID是否存在,避免越权
* 新旧文件名称不能一样
* 也不能用同层文件夹的名称,通过parent_id进行查询
* 编码实战
```java
@Override
public void renameFile(FileUpdateReq req) {
//文件ID是否存在,避免越权
AccountFileDO accountFileDO = accountFileMapper.selectOne(new QueryWrapper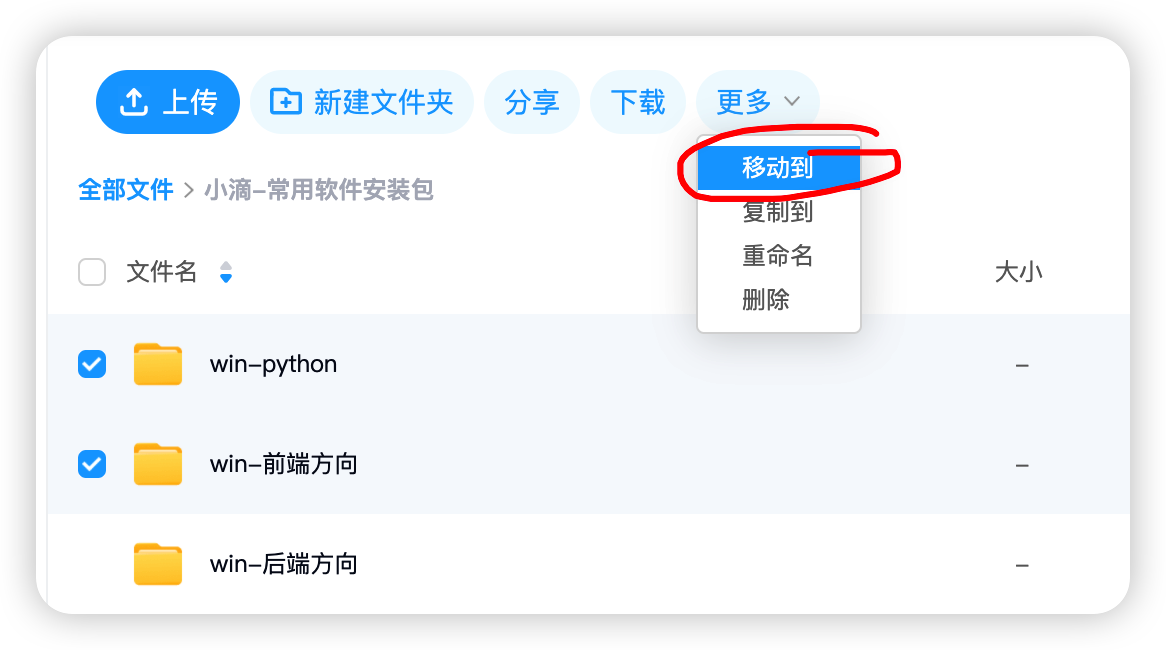 * 业务逻辑设计(哪些方法会复用)
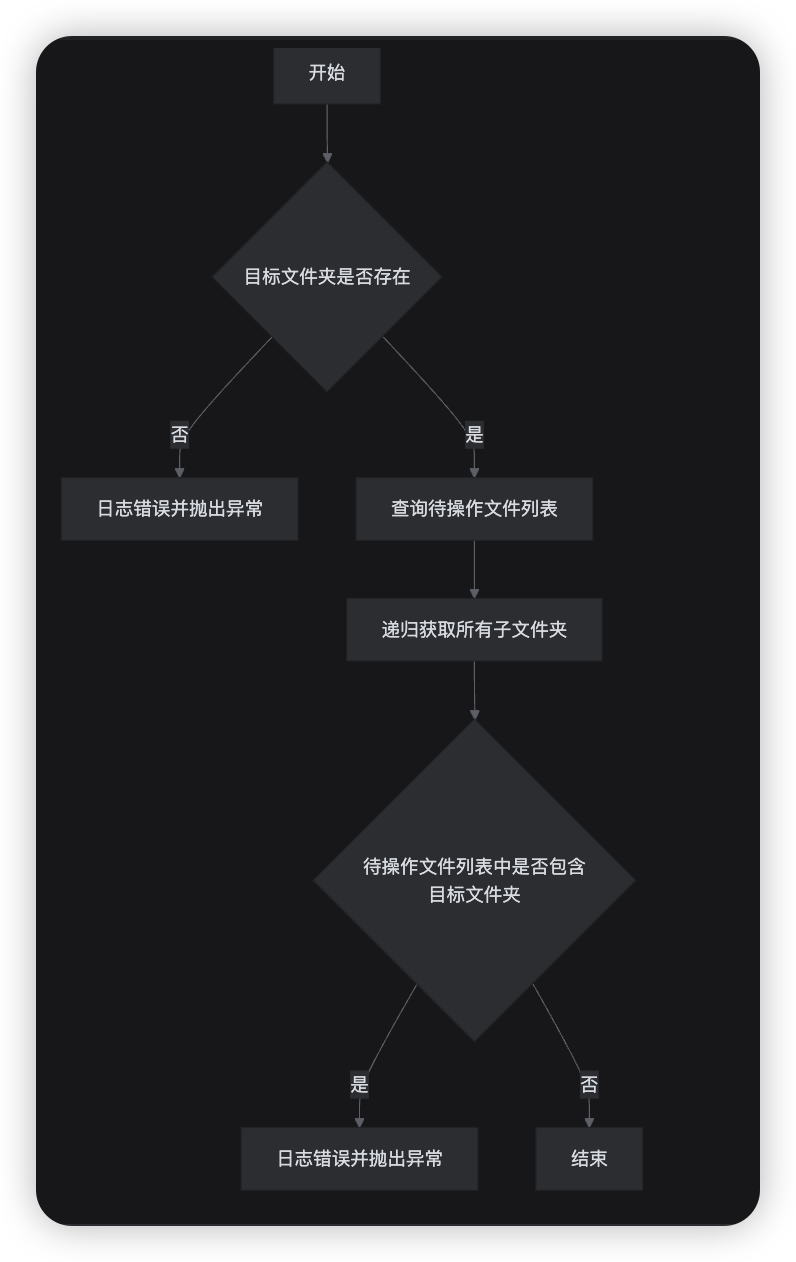
* 检查被转移的文件ID是否合法(复用)
* 检查目标文件夹ID是否合法(复用)
* 目标文件夹ID必须是当前用户的文件夹,不能是文件
* 要操作(移动、复制)的文件列表不能包含是目标文件夹的子文件夹,递归处理
* 批量转移文件到目标文件夹
* 处理重复文件名
* 更新文件或文件夹的parentId为目标文件夹ID
* 编码实战
* 业务逻辑设计(哪些方法会复用)
* 检查被转移的文件ID是否合法(复用)
* 检查目标文件夹ID是否合法(复用)
* 目标文件夹ID必须是当前用户的文件夹,不能是文件
* 要操作(移动、复制)的文件列表不能包含是目标文件夹的子文件夹,递归处理
* 批量转移文件到目标文件夹
* 处理重复文件名
* 更新文件或文件夹的parentId为目标文件夹ID
* 编码实战
 ```java
@Transactional(rollbackFor = Exception.class)
public void moveBatch(FileBatchReq req) {
//检查被转移的文件ID是否合法
List
* 编码实现
```java
@Transactional(rollbackFor = Exception.class)
public void moveBatch(FileBatchReq req) {
//检查被转移的文件ID是否合法
List
* 编码实现
 * 检查父ID是否合法
```java
private void checkTargetParentIdLegal(FileBatchReq req) {
//1、目标文件夹ID 必须是当前用户的文件夹,不能是文件
AccountFileDO targetParentFolder = accountFileMapper.selectOne(new QueryWrapper
* 检查父ID是否合法
```java
private void checkTargetParentIdLegal(FileBatchReq req) {
//1、目标文件夹ID 必须是当前用户的文件夹,不能是文件
AccountFileDO targetParentFolder = accountFileMapper.selectOne(new QueryWrapper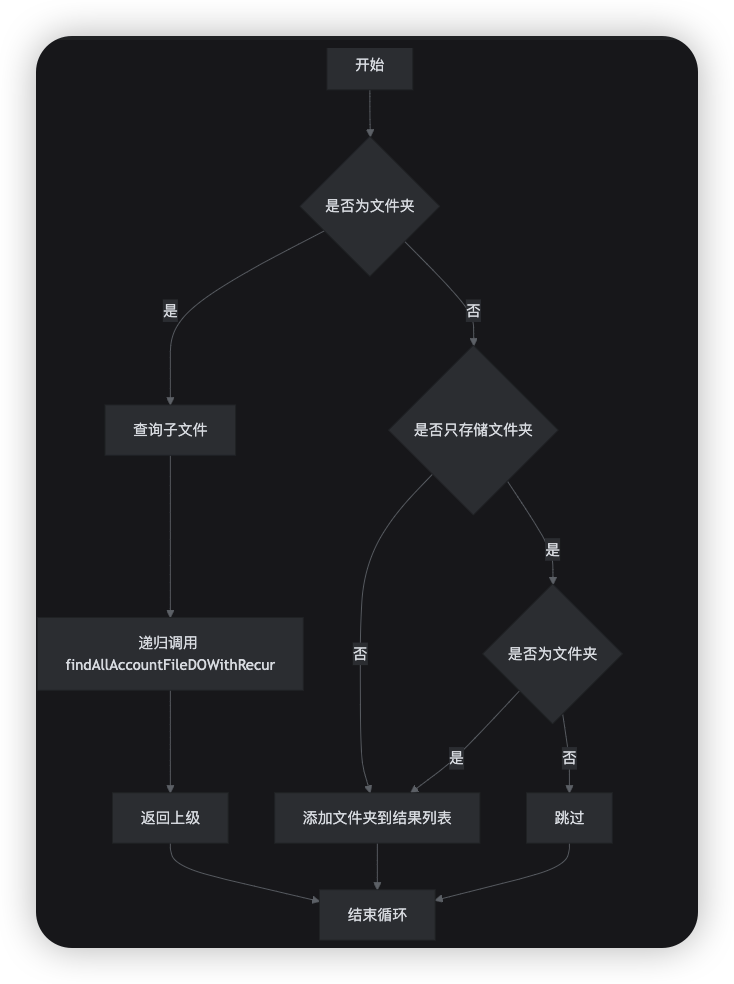 * `findAllAccountFileDOWithRecur` 递归逻辑处理(多个地方会使用,封装方法)
```java
@Override
public void findAllAccountFileDOWithRecur(List
* `findAllAccountFileDOWithRecur` 递归逻辑处理(多个地方会使用,封装方法)
```java
@Override
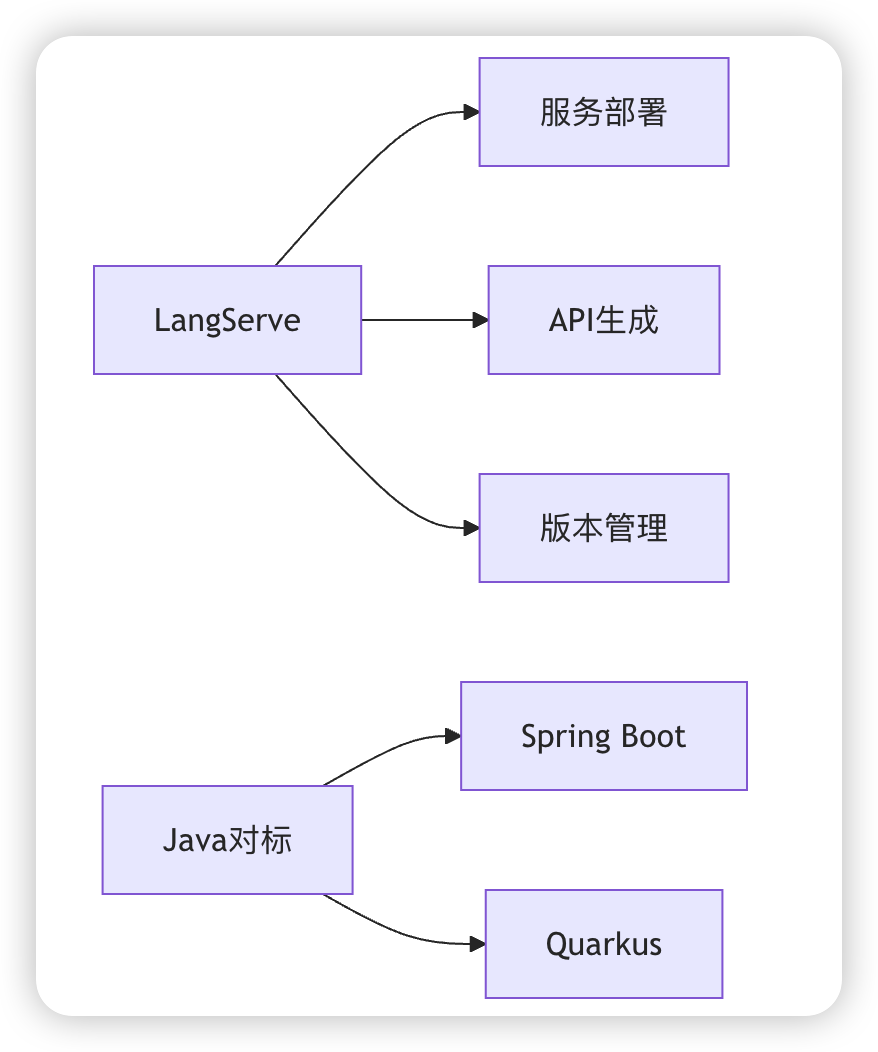
public void findAllAccountFileDOWithRecur(List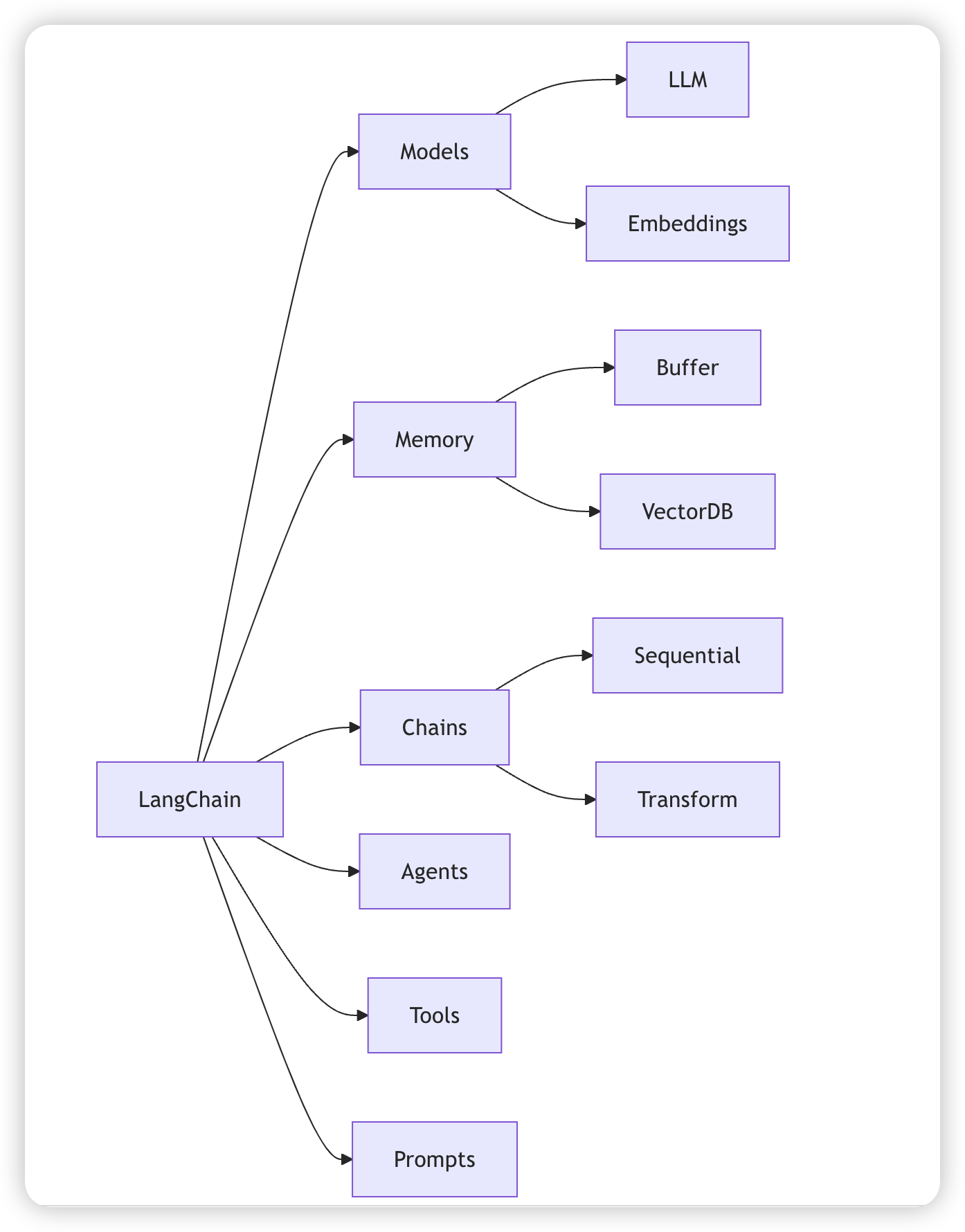 * LangServer
* 部署工具,可将LangChain应用快速转换为REST API,支持并行处理、流式传输和异步调用
* 自动生成OpenAPI文档, 滚动更新支持, 内置Prometheus指标, 适用于企业级生产环境
* LangServer
* 部署工具,可将LangChain应用快速转换为REST API,支持并行处理、流式传输和异步调用
* 自动生成OpenAPI文档, 滚动更新支持, 内置Prometheus指标, 适用于企业级生产环境
 * LangSmith
* 开发者调试与监控平台,支持对LLM应用的性能分析、测试和部署优化
* 提供可视化调试界面和自动化评估工具,提升开发效率与可靠性
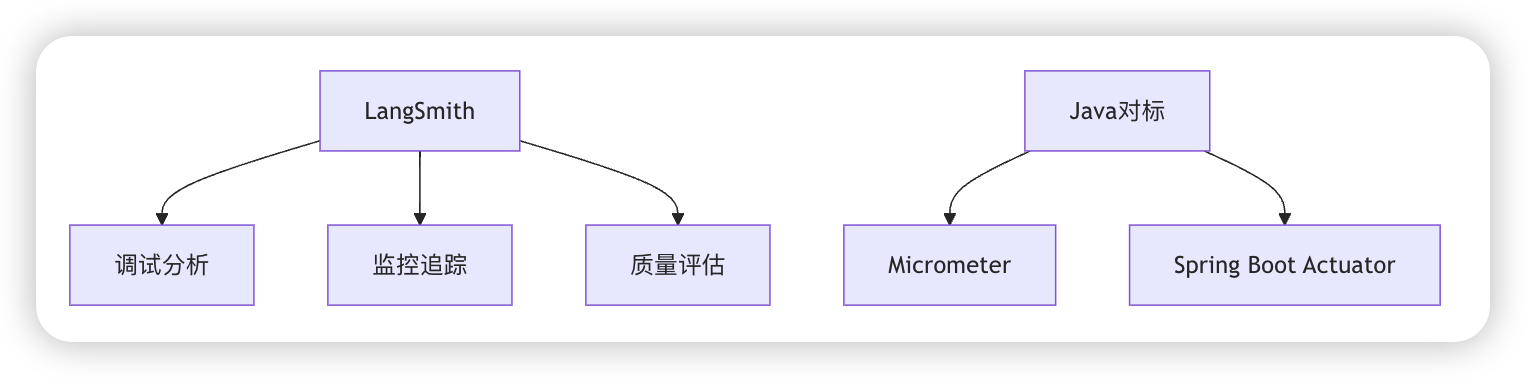
* LangGraph
* 状态管理工具,用于构建多代理系统,支持流式处理和复杂任务分解
* 可视化流程设计器, 循环/条件分支支持,分布式状态持久化, 自动断点续跑
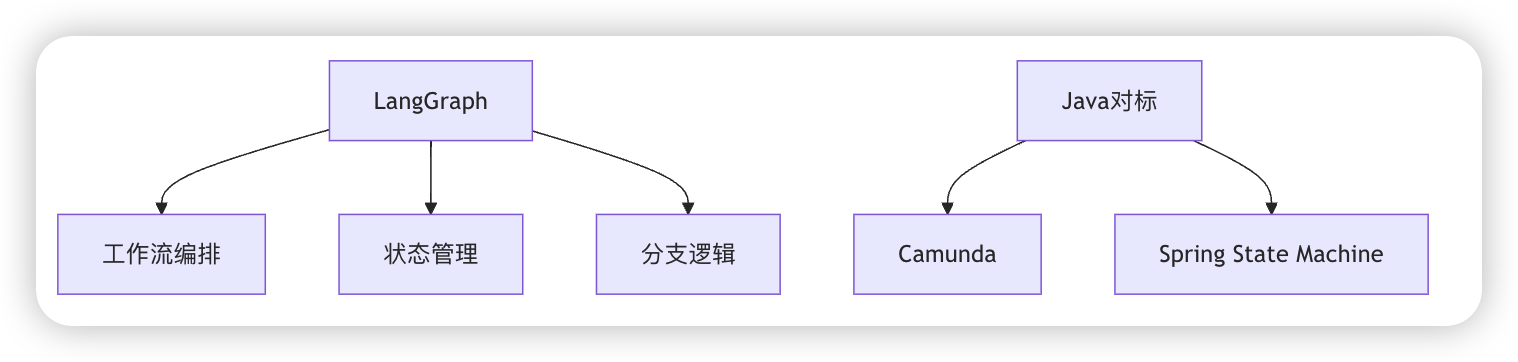
* 产品矩阵对比
| **产品** | **核心价值** | **Java生态对标** | **适用场景** |
| :------------: | :----------------: | :------------------: | :----------------------: |
| LangSmith | 全生命周期可观测性 | Prometheus + Grafana | 生产环境监控、效果评估 |
| LangServe | 快速服务化 | Spring Boot | 模型API部署、快速原型 |
| LangGraph | 复杂流程编排 | Activiti BPMN | 业务工作流设计、状态管理 |
| LangChain Core | 基础组件库 | Spring AI | 基础AI功能开发 |

#### Python虚拟环境evn应用讲解和实战
* 什么是Python的虚拟环境
* 类似虚拟机、沙箱机制一样,隔离不同的项目依赖的环境
* 核心作用
* **隔离项目依赖**:不同项目可能依赖同一库的不同版本。
* **避免全局污染**:防止安装过多全局包导致冲突。
* **便于协作**:通过依赖清单(如`requirements.txt`)复现环境
* 虚拟环境 vs 全局环境
| **特性** | **虚拟环境** | **全局环境** |
| :----------: | :--------------------------: | :------------------------: |
| **依赖隔离** | 项目独立,互不影响 | 所有项目共享 |
| **安全性** | 避免权限问题(无需sudo安装) | 需谨慎操作(可能影响系统) |
| **适用场景** | 开发、测试、多版本项目 | 系统级工具或少量通用库 |
* 镜像源配置
* 查看系统配置的镜像源操作
```shell
pip config list
pip config get global.index-url
```
* 配置国内镜像源
```shell
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
```
* 虚拟环境基础操作
* 创建虚拟环境
```shell
# 语法:python -m venv <环境目录名>
python -m venv myenv # 创建名为myenv的虚拟环境
```
* 激活虚拟环境
* Windows(CMD/PowerShell)
```shell
myenv\Scripts\activate.bat # CMD
myenv\Scripts\Activate.ps1 # PowerShell(需管理员权限解除限制)
```
* Linux/macOS:
```shell
source myenv/bin/activate
```
* 激活后提示符变化
```shell
source myenv/bin/activate
```
* 退出虚拟环境
```shell
deactivate
```
* 依赖管理
* 安装库到虚拟环境
```shell
# 激活环境后操作
(myenv) pip install requests # 安装最新版本
(myenv) pip install django==3.2 # 安装指定版本
```
* 导出依赖清单
```shell
(myenv) pip freeze > requirements.txt
```
* 从清单恢复依赖
```shell
# 在新环境中执行
(myenv) pip install -r requirements.txt
```
* 最佳实践与案例
* 典型项目流程(区分Linux、Mac和Window)
```shell
# 创建项目目录并进入
mkdir myproject && cd myproject
# 创建虚拟环境
python -m venv .venv
# 激活环境(Windows: .venv\Scripts\activate)
source .venv/bin/activate
# 安装依赖
pip install django pandas
# 导出依赖
pip freeze > requirements.txt
# 开发完成后退出
deactivate
```
* 协作复现环境
```shell
# 克隆项目后操作
git clone https://github.com/user/project.git
cd project
# 创建并激活虚拟环境
python -m venv .venv
source .venv/bin/activate
# 安装依赖
pip install -r requirements.txt
```
* 常见问题与解决
* 虚拟环境激活失败
* 现象:source: command not found
* 原因:在Windows使用Linux命令或在Linux未使用source。
* 解决:根据操作系统选择正确激活命令。
* 跨平台路径问题
* 问题:Windows与Linux路径格式差异导致脚本无法运行。
* 方案:使用/统一路径分隔符,或在代码中处理路径
* 依赖版本冲突
* 场景:项目A需要`numpy==1.18`,项目B需要`numpy==1.20`。
* 解决:为每个项目创建独立虚拟环境。
* 案例实战:
* LangChain框架环境搭建
#### VSCode编辑器LangChain环境安装和验证
* Python虚拟环境和项目创建
* 创建虚拟环境(Windows/macOS/Linux通用)
```python
# 创建环境目录
python -m venv langchain_env
```
* 激活虚拟环境
* **Windows**
```python
.\langchain_env\Scripts\activate
```
* **macOS/Linux**
```python
source langchain_env/bin/activate
```
* 验证环境
```python
# 查看Python路径(应显示虚拟环境路径)
which python # macOS/Linux
where python # Windows
```
* LangChain环境安装
* 安装核心依赖包 (**版本和课程保持一致,不然很多不兼容!!!**)
* 下载相关资料 ,使用**【wget】或者【浏览器】远程下载相关依赖包(需要替换群里最新的)**
```python
原生资料下载方式(账号 - 密码 - ip地址 - 端口 需要替换群里最新的,【其他路径不变】)
wget --http-user=用户名 --http-password=密码 http://ip:端口/dcloud_pan/aipan_install_1.zip
#比如 命令行下
wget --http-user=admin --http-password=xdclass.net888 http://47.115.31.28:9088/dcloud_pan/aipan_install_1.zip
# 比如 浏览器直接访问
http://47.115.31.28:9088/dcloud_pan/aipan_install_1.zip
```
* 解压后执行【**依赖很多,版本差异大,务必按照下面执行,否则课程无法进行下去,加我微信 xdclass6**】
```python
# 安装依赖
pip install -r requirements.txt
```
* 验证安装【很多模块后续使用会验证】
```python
# 执行简单测试
from langchain_core.prompts import ChatPromptTemplate
print(ChatPromptTemplate.from_template("Hello 欢迎来到小滴课堂-AI大模型开发课程 {title}!").format(title=",干就完了"))
# 应输出: Human: Hello 欢迎来到小滴课堂-AI大模型开发课程 ,干就完了!
```
#### LangChain框架模块和大模型IO交互链路讲解
**简介: LangChain框架模块和大模型IO交互链路讲解**
* 大模型IO交互链路概览
* LangChain模块对比大家熟知的Java Spring生态
| LangChain模块 | Spring对应技术 | 交互方式差异 |
| :-----------: | :-------------: | :----------------: |
| Models | Spring AI | 多模型热切换支持 |
| Memory | Redis/Hazelcast | 内置对话上下文管理 |
| Chains | Activity工作流 | 动态流程重组能力 |
| Agents | Drools规则引擎 | 基于LLM的决策机制 |
* LangChain架构六大模块(后续围绕模块逐步深入)
* **Models(模型层)**
- 相当于`interface LLM`,支持多种大模型(OpenAI/Gemini等)
- 示例:就像Java中的JDBC接口,可以对接不同数据库
* **Prompts(提示工程)**
- 相当于模板引擎(类似Thymeleaf)
```python
from langchain.prompts import PromptTemplate
template = """
你是一个Java专家,请用比喻解释{concept}:
要求:
1. 用{framework}框架做类比
2. 不超过2句话
"""
prompt = PromptTemplate.from_template(template)
print(prompt.format(concept="机器学习", framework="Spring"))
```
* **Chains(任务链)**
- 类似Java的工作流引擎,将多个组件组合在一起,创建一个单一、连贯的任务
- 包括不同的链之间组合
```python
from langchain.chains import LLMChain
# 创建任务链(类似Java的链式调用)
chain = LLMChain(llm=model, prompt=prompt)
result = chain.run(concept="多线程", framework="Spring Batch")
```
* **Memory(记忆)**
- 类似HTTP Session的会话管理
```python
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.save_context({"input": "你好"}, {"output": "您好!"})
```
* **Indexes(索引)**
- 类似数据库索引+JDBC连接
- 对不通的文档进行结构化的方法,包括提取、切割、向量存储等,方便 LLM 能够更好的与之交互
```python
from langchain.document_loaders import WebBaseLoader
# 加载外部数据(类似JDBC读取数据库)
loader = WebBaseLoader("https://docs.spring.io/spring-boot/docs/current/reference/html/")
docs = loader.load()
```
* **Agents(智能体)**
- 类似策略模式+工厂模式,比chain更高级,可以自己选择调用链路
- 比如下一步有多个选择, 包括不同工具、流程链路等,由程序自己选择
```python
from langchain.agents import Tool, initialize_agent
tools = [
Tool(name="Calculator",
func=lambda x: eval(x),
description="计算数学表达式")
]
agent = initialize_agent(tools, llm, agent="zero-shot-react-description")
```
* 常见分层设计和交互如下
```python
+----------------+
| 应用层 (Agents) |
+----------------+
| 编排层 (Chains) |
+----------------+
| 能力层 (Tools) |
+----------------+
| 模型层 (Models) |
+----------------+
| 数据层 (Memory) |
+----------------+
```
#### 大模型Model-IO链路抽象和Chat模型开发
**简介: 大模型Model-IO链路抽象和Chat模型实战**
* 大模型使用开发的Model IO链路核心三要素

| 组件 | 作用 | 典型类/方法 |
| :---------: | :------------------------: | :-------------------------------------------: |
| **Prompts** | 构建模型输入的结构化模板 | `ChatPromptTemplate`, `FewShotPromptTemplate` |
| **Models** | 对接不同LLM服务的统一接口 | `ChatOpenAI` |
| **Parsers** | 将模型输出转换为结构化数据 | `StrOutputParser`, `JsonOutputParser` |

* LangChain支持的模型类型说明
* 文本生成模型(Text Generation Models-逐渐少用了,Chat更强大)
* 功能:生成连贯文本,主要用于处理文本相关的任务,如自然语言理解、文本生成、情感分析、翻译
* 典型模型:GPT-3、Claude、PaLM
* 对话模型(Chat Models,多数采用这个)
* 功能:处理多轮对话,人机交互中的对话能力,能够进行自然流畅的对话交流,适用于客户服务、智能助手
* 典型模型:GPT-4、Claude-2
* 嵌入模型(Embedding Models)
* 功能:生成文本向量表示,将文本转换为固定长度的向量表示,向量保留了数据的语义信息,便于后续的相似度计算、分类等任务。
* 典型模型:text-embedding-ada-002
* 多模态模型(Multimodal Models)
* 功能:处理文本+图像,例如文本、图像、音频等,更全面的信息理解和处理能力。
* 典型模型:GPT-4V、Qwen-omni-turbo
* 其他更多....
* LangChain开发LLM聊天模型快速编码实战
```python
from langchain_openai import ChatOpenAI
# 调用Chat Completion API
llm = ChatOpenAI(
model_name='qwen-plus',
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-0903038424424850a88ed161845d7d4c")
response = llm.invoke('你是谁?')
print(response)
```
#### 类型增强模块Typing应用和案例》
* Python的动态类型痛点
```python
# 传统动态类型代码示例
def calculate(a, b):
return a + b # 无法直观看出参数类型和返回值类型
result1 = calculate(3, 5) # ✅ 正确用法
result2 = calculate("3", 5) # ❌ 运行时才报错
```
* 什么是Typing模块
* 自python3.5开始,PEP484为python引入了类型注解(type hints), 为Python带来了类型提示和类型检查的能力。
* 允许开发者在代码中添加类型注解,提高代码的可读性和可维护性。
* 尽管Python是一种动态类型语言,但类型注解能让开发者更清晰地了解函数和变量的预期类型
* 核心
* **提升代码可读性**:明确参数和返回类型
* **增强IDE支持**:智能提示与自动补全
* **静态类型检查**:开发阶段发现潜在错误
* **完善文档生成**:自动生成类型化API文档
* 核心语法快速入门
* 简单类型(Primitive Types)
* Python内置的基本数据类型注解
* 适用场景:变量、函数参数、返回值的简单类型声明
* 类型注解不影响运行时行为
* 兼容子类型(如int注解可接受bool值)
```
age: int = 25 # 整数类型
name: str = "Alice" # 字符串类型
price: float = 9.99 # 浮点数类型
is_valid: bool = True # 布尔类型
data: bytes = b"binary" # 字节类型
```
* 容器类型
* 有多种内置的类型别名,比如`List`、`Tuple`、`Dict`等,可用于注解变量和函数的预期类型
* 例如
* `Dict[str, int]`表示键是字符串类型,值是整数类型的字典
* `Set[int]`表示整数类型的集合
* `List`同质元素的序列容器
* 适用场景:列表类型数据,元素类型相同
```python
from typing import List
scores: List[int] = [90, 85, 95] # 整型列表
matrix: List[List[float]] = [[1.1, 2.2], [3.3]] # 嵌套列表
```
* `Dict` 键值对映射容器
* 适用场景:字典类型数据,需指定键值类型
```python
from typing import Dict
person: Dict[str, str] = {"name": "Bob", "job": "dev"} # 字符串字典
config: Dict[str, Union[int, str]] = {"timeout": 30} # 混合值类型
```
* `Tuple`固定长度、类型的不可变序列
- 适用场景:坐标、数据库记录等固定结构
- 变长声明:`Tuple[T, ...]`:元素类型相同但长度不限 , ():空元组
```python
from typing import Tuple
point: Tuple[float, float] = (3.14, 2.71) # 二元坐标
rgb: Tuple[int, int, int] = (255, 0, 128) # 颜色值
flexible: Tuple[str, ...] = ("a", "b", "c") # 任意长度元组
```
* `Set` 无序不重复元素的集合
- 适用场景:去重数据、集合运算
```python
from typing import Set
unique_ids: Set[int] = {1, 2, 3} # 整型集合
tags: Set[Union[str, int]] = {"urgent", 1001} # 混合类型集合
```
* 任意类型 `Any`
- 动态类型占位符,放弃类型检查, 应尽量避免过度使用
- 适用场景:兼容无类型代码或动态行为
```python
from typing import Any
def debug_log(obj: Any) -> None:
print(repr(obj))
```
* 函数类型注解
* 为函数添加typing模块的注解后,函数使用者就能清晰的了解函数的参数以及返回值类型
```python
def greet(name: str) -> str: # 参数类型 -> 返回值类型
return f"Hello, {name}"
def calculate(a: int, b: int) -> int:
return a * b
# 无返回值使用None
def show_info(info: str) -> None:
print(info)
```
* `Literal` 字面量类型
* 精确值类型约束, 替代简单字符串枚举
* 适用场景:枚举值的类型安全
```python
from typing import Literal
# 限定特定值
HttpMethod = Literal["GET", "POST", "PUT", "DELETE"]
def send_request(method: HttpMethod, url: str) -> None:
print(f"Sending {method} request to {url}")
send_request("POST", "/api") # ✅
send_request("PATCH", "/api") # ❌ mypy报错
```
* `Union`联合类型
* Union允许参数接受多种不同类型的数据。
* 例如 `Union[int, float]`表示变量可以是int类型或float类型
```python
from typing import Union
def process_input(value: Union[int, str]) -> None:
if isinstance(value, int):
print(f"Number: {value}")
else:
print(f"String: {value}")
process_input(42) # Number: 42
process_input("test") # String: test
```
* `Optional`可选类型
* `Optional`表示参数可以是指定类型或者`None`
* 让编译器识别到该参数有一个类型提示,可以使指定类型,也可以是None,且参数是可选非必传的。
* `Optional[int]` 等价于 `Union[int, None]`,表示:既可以传指定的类型 int,也可以传 None, `Optional[ ]` 里面只能写一个数据类型
* 适用场景:可能返回空值的操作
* 在下面函数定义中,Optional[str] = None表示参数name的类型可以是str或None。
* 注意
* `= None`可省略,它表示默认参数。
* 从 Python 3.10 开始,Optional[Type] 可以直接用 `Type | None` 替代,写法更清晰
```python
from typing import Optional
def greet1(name: Optional[str] = None) -> str:
if name:
return f"Hello, {name}!"
else:
return "Hello, world!"
def greet2(name: Optional[str]) -> str:
if name:
return f"Hello, {name}!"
else:
return "Hello, world!"
print(greet1())
# print(greet2()) # 报错,必须要有参数
print(greet1("老王"))
print(greet2("冰冰"))
```
* 类型别名
* 自定义类型别名提高代码可读性。
```python
from typing import Tuple
# 基本别名
UserId = int
Point = Tuple[float, float]
def get_user(id: UserId) -> str:
return f"User{id}"
def plot(points: List[Point]) -> None:
for x, y in points:
print(f"({x}, {y})")
```
* `NewType`新类型创建
* 创建具有类型检查的语义化新类型
* 适合 区分相同基础类型的不同用途
```python
from typing import NewType
# 创建强类型
UserId = NewType('UserId', int)
admin_id = UserId(1001)
def print_id(user_id: UserId) -> None:
print(user_id)
# 正确调用
print_id(admin_id) # ✅
print_id(1001) # ❌ mypy报错
```
* `TypeVar`(类型变量)
* 创建通用类型参数
* 适用场景:泛型函数/类的类型参数化;比如创建一个函数,无论是处理整数、字符串还是自定义对象
```python
from typing import TypeVar, Sequence
T = TypeVar('T') # 无约束类型
Num = TypeVar('Num', int, float) # 受限类型
def first(items: Sequence[T]) -> T:
return items[0]
def sum(values: Sequence[Num]) -> Num:
return sum(values)
```
```python
from typing import TypeVar
# 定义一个泛型变量T
T = TypeVar('T')
# 创建一个泛型函数
def get_first_item(items: list[T]) -> T:
"""获取列表的第一个元素"""
if items:
return items[0]
raise ValueError("列表为空")
# 使用示例
numbers = [1, 2, 3, 4, 5]
words = ['apple', 'banana', 'cherry', 'fruit']
print(get_first_item(numbers)) # 输出: 1
print(get_first_item(words)) # 输出: apple
```
### Prompt提示词工程和案例最佳实践
#### 大模型必备Prompt提示词工程
* 什么是Prompt Engineering提示词工程
* 通过特定格式的文本输入引导AI模型生成期望输出的技术,明确地告诉模型你想要解决的问题或完成的任务
* 也是大语言模型理解用户需求并生成相关、准确回答或内容的基础
* **类比:给Java程序员的任务需求文档(越清晰明确,结果越符合预期)**
* 为什么需要学习?
* 大模型就是你的员工,你可以有多个助手,OpenAI、DeepSeek、千问等
* 作为老板的你,需要正确的下达任务,描述合理和交付目标等
```python
传统编程:写代码→计算机执行
Prompt工程:写自然语言指令→大模型生成结果
```

* Prompt设计四要素
* 角色设定(Role Prompting)
* 作用:限定模型回答视角
```python
[差] 写一首关于春天的诗
[优] 你是一位擅长写现代诗的诗人,请用比喻手法创作一首8行的春天主题短诗
```
* 任务描述
* STAR原则:Situation 场景、Task 任务、Action 行动、Result 结果
```python
(场景)用户提交了一个技术问题
(任务)需要给出准确且易懂的解答
(行动)分步骤说明解决方案
(结果)最后用一句话总结要点
```
* 格式规范
* 常用格式指令:分点列表、指定段落数、表格呈现、代码格式
```python
用JSON格式输出包含以下字段:
{
"summary": "不超过50字的摘要",
"keywords": ["关键词1", "关键词2", "关键词3"]
}
```
* 约束条件
* 常见约束类型:
| 类型 | 示例 |
| :--: | :--------------------: |
| 长度 | "答案控制在200字内" |
| 风格 | "用初中生能理解的语言" |
| 内容 | "不包含专业术语" |
| 逻辑 | "先解释概念再举例说明" |
* 汇总
| 要素 | 说明 | 反面案例 | 优化案例 |
| :----------: | :------------: | :----------: | :-------------------------: |
| **角色设定** | 明确模型身份 | "帮我写代码" | "你是一个资深Java架构师..." |
| **任务说明** | 具体执行要求 | "分析数据" | "使用Markdown表格对比..." |
| **输出格式** | 结构化结果定义 | 自由文本 | JSON/XML/YAML格式 |
| **约束条件** | 限制输出范围 | 无限制 | "不超过200字,不用专业术语" |
* 模板结构设计(黄金公式)
```python
# 标准三段式结构
prompt_template = """
[角色设定]
你是一个具有10年经验的{领域}专家,擅长{特定技能}
[任务说明]
需要完成以下任务:
1. {步骤1}
2. {步骤2}
3. {步骤3}
[输出要求]
请按照以下格式响应:
{示例格式}
"""
```
* 常见问题和排查原因
| 现象 | 可能原因 | 解决方案 |
| :--------------: | :----------------: | :----------------------: |
| 输出内容偏离主题 | 角色设定不明确 | 添加"忽略无关信息"约束 |
| 生成结果过于笼统 | 缺少具体步骤要求 | 添加"分步骤详细说明"指令 |
| 格式不符合要求 | 未提供明确格式示例 | 添加XML/JSON标记示例 |
#### Prompt提示词工程多案例最佳实践
* 需求
* 利用在线大模型或者本地大模型
* 测试不同的提示词效果,分析优化前、后的Prompt工程
* **案例实战:通用回答助手、代码生成助手、技术问答、AI数据分析 等案例实战**
* 案例实战一:通用回答
* 差Prompt:
```
告诉我关于人工智能的信息
```
* 问题分析:过于宽泛,缺乏焦点、没有指定回答的深度和范围、未明确期望的格式
* 输出结果:可能得到从历史发展到技术原理的冗长概述,缺乏针对性
* 好prompt
```python
你是一位科技专栏作家,请用通俗易懂的方式向高中生解释:
1. 什么是人工智能(用1个生活化比喻说明)
2. 列举3个当前主流应用场景
3. 字数控制在300字以内
要求使用「首先」、「其次」、「最后」的结构
```
* 优化后
* 设定回答视角(科技专栏作家)
* 明确目标受众(高中生)
* 结构化输出要求
* 添加格式约束
* 案例实战二:代码生成
* 差Prompt:
```python
写个Python程序
```
* 问题分析:没有具体功能描述、未指定输入输出格式、忽略异常处理需求
* 输出结果:可能生成简单的"Hello World"程序,与真实需求不符
* 好Prompt:
```python
编写一个Python函数,实现以下功能:
- 输入:字符串形式的日期(格式:YYYY-MM-DD)
- 输出:该日期对应的季度(1-4)
- 要求:
- 包含参数校验(不符合格式时抛出ValueError)
- 使用datetime模块
- 编写对应的单元测试用例
示例:
输入 "2024-03-15" → 返回 1
```
* 优化后
* 明确定义输入输出
* 指定实现方式
* 包含测试要求
* 提供示例验证
* 案例实战三:技术问答
* 差Prompt
```python
如何优化网站性能?
```
* 问题分析:问题范围过大、未说明技术栈、缺少评估标准
* 输出结果:可能得到泛泛而谈的通用建议
* 好Prompt
```python
针对使用SpringBoot+Vue3的技术栈,请给出5项可量化的性能优化方案:
要求:
1. 每项方案包含:
- 实施步骤
- 预期性能提升指标(如LCP减少20%)
- 复杂度评估(低/中/高)
2. 优先前端和后端优化方案
3. 引用Web Vitals评估标准
限制条件:
- 不涉及服务器扩容等硬件方案
- 排除已广泛采用的方案(如代码压缩)
```
* 优化点
* 限定技术范围
* 结构化响应要求
* 设定评估标准
* 排除已知方案
* 案例实战四:数据分析
* 差Prompt
```python
分析这份销售数据
```
* 问题分析:未说明数据特征、没有指定分析方法、缺少可视化要求
* 输出结果:可能得到无重点的描述性统计,缺乏洞察
* 好Prompt
```python
你是一位资深数据分析师,请完成以下任务:
数据集特征:
- 时间范围:2027年1-12月
- 字段:日期/产品类别/销售额/利润率
要求:
1. 找出销售额top3的月份,分析增长原因
2. 识别利润率低于5%的产品类别
3. 生成包含趋势图的Markdown报告
输出格式:
## 分析报告
### 关键发现
- 要点1(数据支撑)
- 要点2(对比分析)
### 可视化
趋势图描述,生成base64编码的折线图
```
* 优化点:
* 明确分析者角色
* 描述数据集特征
* 指定分析方法论
* 规范输出格式
#### LangChain 提示模板PromptTemplate介绍
* 需求
* 掌握LangChain 提示模板PromptTemplate常见用法
* 掌握提示词里面的占位符使用和预置变量
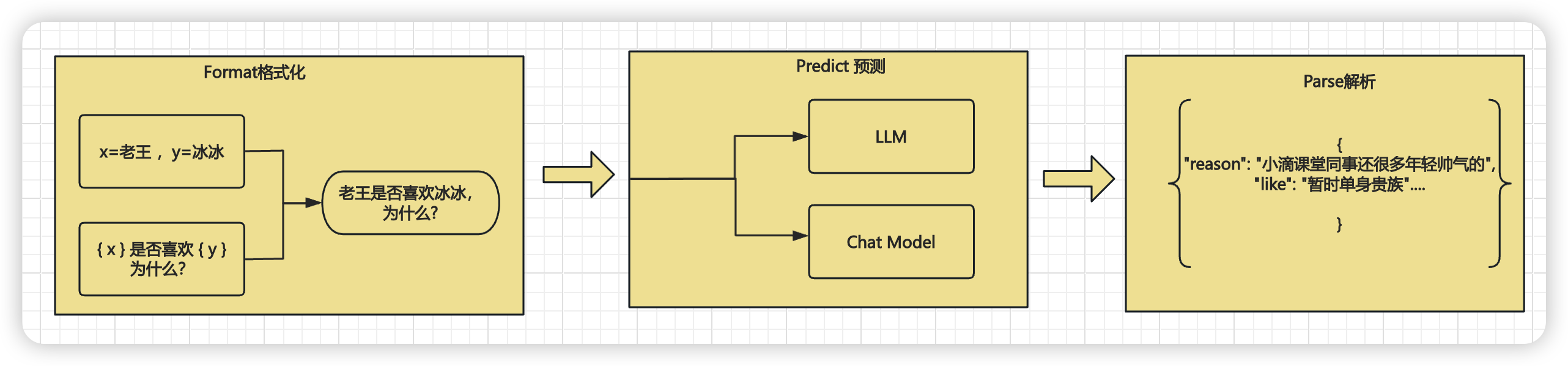
* PromptTemplate介绍
* 是LangChain中用于构建结构化提示词的组件,负责将用户输入/动态数据转换为LLM可理解的格式
* 它是一种单纯的字符模板,后续还有进阶的ChatPromptTemplate
* 主要解决
* 动态内容组装
* 避免Prompt硬编码

* PromptTemplate核心变量和方法
* template 定义具体的模板格式,其中 `{变量名}` 是占位符
* input_variables 定义模板中可以使用的变量。
* partial_variables:前置变量,可以提前定义部分变量的值,预填充进去
* format 使用 `format` 方法填充模板中的占位符,形成最终的文本
* 案例实战
* 创建PromptTemplate对象简单模版
```python
from langchain.prompts import PromptTemplate
# 定义模板
template = """
你是一位专业的{domain}顾问,请用{language}回答:
问题:{question}
回答:
"""
# 创建实例
prompt = PromptTemplate(
input_variables=["domain", "language", "question"],
template=template
)
print(prompt)
# 格式化输出
print(prompt.format(
domain="网络安全",
language="中文",
question="如何防范钓鱼攻击?"
))
```
* 自动推断变量
```python
from langchain.prompts import PromptTemplate
# 当不显式声明 input_variables 时
template = "请将以下文本翻译成{target_language}:{text}"
prompt = PromptTemplate.from_template(template)
print(prompt.input_variables) # 输出: ['target_language', 'text']
```
* 默认值设置
```python
from langchain.prompts import PromptTemplate
template = """分析用户情绪(默认分析类型:{analysis_type}):
用户输入:{user_input}
分析结果:"""
prompt_template = PromptTemplate(
input_variables=["user_input"],
template=template,
template_format="f-string", # 新增参数
partial_variables={"analysis_type": "情感极性分析"} # 固定值
)
print(prompt_template.format(user_input="这个产品太难用了"))
#====打印内部的变量======
print(prompt_template.template)
print(prompt_template.input_variables)
print(prompt_template.template_format)
print(prompt_template.input_types)
print(prompt_template.partial_variables)
```
#### PromptTemplate结合LLM案例实战
* 案例实战
```python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
#创建prompt AIGC
prompt_template = PromptTemplate(
input_variables=["product"],
template="为{product}写3个吸引人的广告语,需要面向年轻人",
)
prompt = prompt_template.invoke({"product":"小滴课堂"})
#创建模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
#调用大模型
response = model.invoke(prompt)
#print(response.content)
#创建输出解析器
out_parser = StrOutputParser()
answer = out_parser.invoke(response)
print(answer)
```
#### 大模型ChatModel聊天模型和Token计算
* 什么是**ChatModel**
* 是专为**多轮对话场景**设计的大语言模型(LLM),通过理解上下文和对话逻辑,生成连贯、符合人类交互习惯的回复。
* 不仅是简单的文本生成工具,更是能处理复杂对话流程的智能系统
* 核心特点
| 特性 | 说明 | 示例场景 |
| :--------------: | :----------------------------------------------: | :----------------------------------------------------------: |
| **上下文感知** | 追踪多轮对话历史,理解指代关系(如“它”、“这个”) | 用户:“什么是量子计算?” → AI 解释 → 用户:“它有什么应用?” → AI 能正确关联“它”指量子计算 |
| **角色扮演能力** | 可设定特定角色(如客服、教师)并保持一致性 | 设定AI为“医疗助手”时,拒绝提供诊断建议,仅提供健康信息 |
| **意图识别** | 解析用户深层需求(如咨询、投诉、闲聊) | 用户:“我的订单没收到!” → AI 识别为物流投诉,优先转接人工客服 |
| **情感分析** | 识别用户情绪(积极/消极),调整回复语气 | 用户表达不满时,AI 回复:“非常抱歉给您带来不便,我们会立刻处理...” |
| **安全过滤** | 避免生成有害、偏见或敏感内容 | 用户请求生成暴力内容时,AI 拒绝并提示:“我无法协助这个请求” |
* ChatModel vs. 传统 Text Model
| **对比维度** | **ChatModel** | **传统 Text Model(如 text-davinci-003)** |
| :------------: | :------------------------------------: | :----------------------------------------: |
| **核心目标** | 多轮交互式对话 | 单次文本生成(文章、代码等) |
| **输入格式** | 结构化消息序列(System/Human/AI 角色) | 纯文本提示 |
| **上下文处理** | 自动管理对话历史 | 需手动拼接历史文本 |
| **输出控制** | 内置安全审查和格式约束 | 依赖提示词工程控制 |
| **典型应用** | 客服机器人、虚拟助手 | 内容创作、数据清洗 |
* 聊天模型(如 GPT-3.5-turbo、GPT-4)通过 **角色化消息** 实现对话控制,核心角色包括:
| 角色类型 | 标识符 | 功能定位 | 使用场景示例 |
| :-----------: | :---------: | :------------------------: | :----------------------------------------------------------: |
| **System** | `system` | 定义AI的行为准则和角色设定 | 设定AI身份、回答规则、知识范围
* LangSmith
* 开发者调试与监控平台,支持对LLM应用的性能分析、测试和部署优化
* 提供可视化调试界面和自动化评估工具,提升开发效率与可靠性

* LangGraph
* 状态管理工具,用于构建多代理系统,支持流式处理和复杂任务分解
* 可视化流程设计器, 循环/条件分支支持,分布式状态持久化, 自动断点续跑

* 产品矩阵对比
| **产品** | **核心价值** | **Java生态对标** | **适用场景** |
| :------------: | :----------------: | :------------------: | :----------------------: |
| LangSmith | 全生命周期可观测性 | Prometheus + Grafana | 生产环境监控、效果评估 |
| LangServe | 快速服务化 | Spring Boot | 模型API部署、快速原型 |
| LangGraph | 复杂流程编排 | Activiti BPMN | 业务工作流设计、状态管理 |
| LangChain Core | 基础组件库 | Spring AI | 基础AI功能开发 |

#### Python虚拟环境evn应用讲解和实战
* 什么是Python的虚拟环境
* 类似虚拟机、沙箱机制一样,隔离不同的项目依赖的环境
* 核心作用
* **隔离项目依赖**:不同项目可能依赖同一库的不同版本。
* **避免全局污染**:防止安装过多全局包导致冲突。
* **便于协作**:通过依赖清单(如`requirements.txt`)复现环境
* 虚拟环境 vs 全局环境
| **特性** | **虚拟环境** | **全局环境** |
| :----------: | :--------------------------: | :------------------------: |
| **依赖隔离** | 项目独立,互不影响 | 所有项目共享 |
| **安全性** | 避免权限问题(无需sudo安装) | 需谨慎操作(可能影响系统) |
| **适用场景** | 开发、测试、多版本项目 | 系统级工具或少量通用库 |
* 镜像源配置
* 查看系统配置的镜像源操作
```shell
pip config list
pip config get global.index-url
```
* 配置国内镜像源
```shell
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
```
* 虚拟环境基础操作
* 创建虚拟环境
```shell
# 语法:python -m venv <环境目录名>
python -m venv myenv # 创建名为myenv的虚拟环境
```
* 激活虚拟环境
* Windows(CMD/PowerShell)
```shell
myenv\Scripts\activate.bat # CMD
myenv\Scripts\Activate.ps1 # PowerShell(需管理员权限解除限制)
```
* Linux/macOS:
```shell
source myenv/bin/activate
```
* 激活后提示符变化
```shell
source myenv/bin/activate
```
* 退出虚拟环境
```shell
deactivate
```
* 依赖管理
* 安装库到虚拟环境
```shell
# 激活环境后操作
(myenv) pip install requests # 安装最新版本
(myenv) pip install django==3.2 # 安装指定版本
```
* 导出依赖清单
```shell
(myenv) pip freeze > requirements.txt
```
* 从清单恢复依赖
```shell
# 在新环境中执行
(myenv) pip install -r requirements.txt
```
* 最佳实践与案例
* 典型项目流程(区分Linux、Mac和Window)
```shell
# 创建项目目录并进入
mkdir myproject && cd myproject
# 创建虚拟环境
python -m venv .venv
# 激活环境(Windows: .venv\Scripts\activate)
source .venv/bin/activate
# 安装依赖
pip install django pandas
# 导出依赖
pip freeze > requirements.txt
# 开发完成后退出
deactivate
```
* 协作复现环境
```shell
# 克隆项目后操作
git clone https://github.com/user/project.git
cd project
# 创建并激活虚拟环境
python -m venv .venv
source .venv/bin/activate
# 安装依赖
pip install -r requirements.txt
```
* 常见问题与解决
* 虚拟环境激活失败
* 现象:source: command not found
* 原因:在Windows使用Linux命令或在Linux未使用source。
* 解决:根据操作系统选择正确激活命令。
* 跨平台路径问题
* 问题:Windows与Linux路径格式差异导致脚本无法运行。
* 方案:使用/统一路径分隔符,或在代码中处理路径
* 依赖版本冲突
* 场景:项目A需要`numpy==1.18`,项目B需要`numpy==1.20`。
* 解决:为每个项目创建独立虚拟环境。
* 案例实战:
* LangChain框架环境搭建
#### VSCode编辑器LangChain环境安装和验证
* Python虚拟环境和项目创建
* 创建虚拟环境(Windows/macOS/Linux通用)
```python
# 创建环境目录
python -m venv langchain_env
```
* 激活虚拟环境
* **Windows**
```python
.\langchain_env\Scripts\activate
```
* **macOS/Linux**
```python
source langchain_env/bin/activate
```
* 验证环境
```python
# 查看Python路径(应显示虚拟环境路径)
which python # macOS/Linux
where python # Windows
```
* LangChain环境安装
* 安装核心依赖包 (**版本和课程保持一致,不然很多不兼容!!!**)
* 下载相关资料 ,使用**【wget】或者【浏览器】远程下载相关依赖包(需要替换群里最新的)**
```python
原生资料下载方式(账号 - 密码 - ip地址 - 端口 需要替换群里最新的,【其他路径不变】)
wget --http-user=用户名 --http-password=密码 http://ip:端口/dcloud_pan/aipan_install_1.zip
#比如 命令行下
wget --http-user=admin --http-password=xdclass.net888 http://47.115.31.28:9088/dcloud_pan/aipan_install_1.zip
# 比如 浏览器直接访问
http://47.115.31.28:9088/dcloud_pan/aipan_install_1.zip
```
* 解压后执行【**依赖很多,版本差异大,务必按照下面执行,否则课程无法进行下去,加我微信 xdclass6**】
```python
# 安装依赖
pip install -r requirements.txt
```
* 验证安装【很多模块后续使用会验证】
```python
# 执行简单测试
from langchain_core.prompts import ChatPromptTemplate
print(ChatPromptTemplate.from_template("Hello 欢迎来到小滴课堂-AI大模型开发课程 {title}!").format(title=",干就完了"))
# 应输出: Human: Hello 欢迎来到小滴课堂-AI大模型开发课程 ,干就完了!
```
#### LangChain框架模块和大模型IO交互链路讲解
**简介: LangChain框架模块和大模型IO交互链路讲解**
* 大模型IO交互链路概览

* LangChain模块对比大家熟知的Java Spring生态
| LangChain模块 | Spring对应技术 | 交互方式差异 |
| :-----------: | :-------------: | :----------------: |
| Models | Spring AI | 多模型热切换支持 |
| Memory | Redis/Hazelcast | 内置对话上下文管理 |
| Chains | Activity工作流 | 动态流程重组能力 |
| Agents | Drools规则引擎 | 基于LLM的决策机制 |
* LangChain架构六大模块(后续围绕模块逐步深入)
* **Models(模型层)**
- 相当于`interface LLM`,支持多种大模型(OpenAI/Gemini等)
- 示例:就像Java中的JDBC接口,可以对接不同数据库
* **Prompts(提示工程)**
- 相当于模板引擎(类似Thymeleaf)
```python
from langchain.prompts import PromptTemplate
template = """
你是一个Java专家,请用比喻解释{concept}:
要求:
1. 用{framework}框架做类比
2. 不超过2句话
"""
prompt = PromptTemplate.from_template(template)
print(prompt.format(concept="机器学习", framework="Spring"))
```
* **Chains(任务链)**
- 类似Java的工作流引擎,将多个组件组合在一起,创建一个单一、连贯的任务
- 包括不同的链之间组合
```python
from langchain.chains import LLMChain
# 创建任务链(类似Java的链式调用)
chain = LLMChain(llm=model, prompt=prompt)
result = chain.run(concept="多线程", framework="Spring Batch")
```
* **Memory(记忆)**
- 类似HTTP Session的会话管理
```python
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.save_context({"input": "你好"}, {"output": "您好!"})
```
* **Indexes(索引)**
- 类似数据库索引+JDBC连接
- 对不通的文档进行结构化的方法,包括提取、切割、向量存储等,方便 LLM 能够更好的与之交互
```python
from langchain.document_loaders import WebBaseLoader
# 加载外部数据(类似JDBC读取数据库)
loader = WebBaseLoader("https://docs.spring.io/spring-boot/docs/current/reference/html/")
docs = loader.load()
```
* **Agents(智能体)**
- 类似策略模式+工厂模式,比chain更高级,可以自己选择调用链路
- 比如下一步有多个选择, 包括不同工具、流程链路等,由程序自己选择
```python
from langchain.agents import Tool, initialize_agent
tools = [
Tool(name="Calculator",
func=lambda x: eval(x),
description="计算数学表达式")
]
agent = initialize_agent(tools, llm, agent="zero-shot-react-description")
```
* 常见分层设计和交互如下
```python
+----------------+
| 应用层 (Agents) |
+----------------+
| 编排层 (Chains) |
+----------------+
| 能力层 (Tools) |
+----------------+
| 模型层 (Models) |
+----------------+
| 数据层 (Memory) |
+----------------+
```
#### 大模型Model-IO链路抽象和Chat模型开发
**简介: 大模型Model-IO链路抽象和Chat模型实战**
* 大模型使用开发的Model IO链路核心三要素

| 组件 | 作用 | 典型类/方法 |
| :---------: | :------------------------: | :-------------------------------------------: |
| **Prompts** | 构建模型输入的结构化模板 | `ChatPromptTemplate`, `FewShotPromptTemplate` |
| **Models** | 对接不同LLM服务的统一接口 | `ChatOpenAI` |
| **Parsers** | 将模型输出转换为结构化数据 | `StrOutputParser`, `JsonOutputParser` |

* LangChain支持的模型类型说明
* 文本生成模型(Text Generation Models-逐渐少用了,Chat更强大)
* 功能:生成连贯文本,主要用于处理文本相关的任务,如自然语言理解、文本生成、情感分析、翻译
* 典型模型:GPT-3、Claude、PaLM
* 对话模型(Chat Models,多数采用这个)
* 功能:处理多轮对话,人机交互中的对话能力,能够进行自然流畅的对话交流,适用于客户服务、智能助手
* 典型模型:GPT-4、Claude-2
* 嵌入模型(Embedding Models)
* 功能:生成文本向量表示,将文本转换为固定长度的向量表示,向量保留了数据的语义信息,便于后续的相似度计算、分类等任务。
* 典型模型:text-embedding-ada-002
* 多模态模型(Multimodal Models)
* 功能:处理文本+图像,例如文本、图像、音频等,更全面的信息理解和处理能力。
* 典型模型:GPT-4V、Qwen-omni-turbo
* 其他更多....
* LangChain开发LLM聊天模型快速编码实战
```python
from langchain_openai import ChatOpenAI
# 调用Chat Completion API
llm = ChatOpenAI(
model_name='qwen-plus',
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-0903038424424850a88ed161845d7d4c")
response = llm.invoke('你是谁?')
print(response)
```
#### 类型增强模块Typing应用和案例》
* Python的动态类型痛点
```python
# 传统动态类型代码示例
def calculate(a, b):
return a + b # 无法直观看出参数类型和返回值类型
result1 = calculate(3, 5) # ✅ 正确用法
result2 = calculate("3", 5) # ❌ 运行时才报错
```
* 什么是Typing模块
* 自python3.5开始,PEP484为python引入了类型注解(type hints), 为Python带来了类型提示和类型检查的能力。
* 允许开发者在代码中添加类型注解,提高代码的可读性和可维护性。
* 尽管Python是一种动态类型语言,但类型注解能让开发者更清晰地了解函数和变量的预期类型
* 核心
* **提升代码可读性**:明确参数和返回类型
* **增强IDE支持**:智能提示与自动补全
* **静态类型检查**:开发阶段发现潜在错误
* **完善文档生成**:自动生成类型化API文档
* 核心语法快速入门
* 简单类型(Primitive Types)
* Python内置的基本数据类型注解
* 适用场景:变量、函数参数、返回值的简单类型声明
* 类型注解不影响运行时行为
* 兼容子类型(如int注解可接受bool值)
```
age: int = 25 # 整数类型
name: str = "Alice" # 字符串类型
price: float = 9.99 # 浮点数类型
is_valid: bool = True # 布尔类型
data: bytes = b"binary" # 字节类型
```
* 容器类型
* 有多种内置的类型别名,比如`List`、`Tuple`、`Dict`等,可用于注解变量和函数的预期类型
* 例如
* `Dict[str, int]`表示键是字符串类型,值是整数类型的字典
* `Set[int]`表示整数类型的集合
* `List`同质元素的序列容器
* 适用场景:列表类型数据,元素类型相同
```python
from typing import List
scores: List[int] = [90, 85, 95] # 整型列表
matrix: List[List[float]] = [[1.1, 2.2], [3.3]] # 嵌套列表
```
* `Dict` 键值对映射容器
* 适用场景:字典类型数据,需指定键值类型
```python
from typing import Dict
person: Dict[str, str] = {"name": "Bob", "job": "dev"} # 字符串字典
config: Dict[str, Union[int, str]] = {"timeout": 30} # 混合值类型
```
* `Tuple`固定长度、类型的不可变序列
- 适用场景:坐标、数据库记录等固定结构
- 变长声明:`Tuple[T, ...]`:元素类型相同但长度不限 , ():空元组
```python
from typing import Tuple
point: Tuple[float, float] = (3.14, 2.71) # 二元坐标
rgb: Tuple[int, int, int] = (255, 0, 128) # 颜色值
flexible: Tuple[str, ...] = ("a", "b", "c") # 任意长度元组
```
* `Set` 无序不重复元素的集合
- 适用场景:去重数据、集合运算
```python
from typing import Set
unique_ids: Set[int] = {1, 2, 3} # 整型集合
tags: Set[Union[str, int]] = {"urgent", 1001} # 混合类型集合
```
* 任意类型 `Any`
- 动态类型占位符,放弃类型检查, 应尽量避免过度使用
- 适用场景:兼容无类型代码或动态行为
```python
from typing import Any
def debug_log(obj: Any) -> None:
print(repr(obj))
```
* 函数类型注解
* 为函数添加typing模块的注解后,函数使用者就能清晰的了解函数的参数以及返回值类型
```python
def greet(name: str) -> str: # 参数类型 -> 返回值类型
return f"Hello, {name}"
def calculate(a: int, b: int) -> int:
return a * b
# 无返回值使用None
def show_info(info: str) -> None:
print(info)
```
* `Literal` 字面量类型
* 精确值类型约束, 替代简单字符串枚举
* 适用场景:枚举值的类型安全
```python
from typing import Literal
# 限定特定值
HttpMethod = Literal["GET", "POST", "PUT", "DELETE"]
def send_request(method: HttpMethod, url: str) -> None:
print(f"Sending {method} request to {url}")
send_request("POST", "/api") # ✅
send_request("PATCH", "/api") # ❌ mypy报错
```
* `Union`联合类型
* Union允许参数接受多种不同类型的数据。
* 例如 `Union[int, float]`表示变量可以是int类型或float类型
```python
from typing import Union
def process_input(value: Union[int, str]) -> None:
if isinstance(value, int):
print(f"Number: {value}")
else:
print(f"String: {value}")
process_input(42) # Number: 42
process_input("test") # String: test
```
* `Optional`可选类型
* `Optional`表示参数可以是指定类型或者`None`
* 让编译器识别到该参数有一个类型提示,可以使指定类型,也可以是None,且参数是可选非必传的。
* `Optional[int]` 等价于 `Union[int, None]`,表示:既可以传指定的类型 int,也可以传 None, `Optional[ ]` 里面只能写一个数据类型
* 适用场景:可能返回空值的操作
* 在下面函数定义中,Optional[str] = None表示参数name的类型可以是str或None。
* 注意
* `= None`可省略,它表示默认参数。
* 从 Python 3.10 开始,Optional[Type] 可以直接用 `Type | None` 替代,写法更清晰
```python
from typing import Optional
def greet1(name: Optional[str] = None) -> str:
if name:
return f"Hello, {name}!"
else:
return "Hello, world!"
def greet2(name: Optional[str]) -> str:
if name:
return f"Hello, {name}!"
else:
return "Hello, world!"
print(greet1())
# print(greet2()) # 报错,必须要有参数
print(greet1("老王"))
print(greet2("冰冰"))
```
* 类型别名
* 自定义类型别名提高代码可读性。
```python
from typing import Tuple
# 基本别名
UserId = int
Point = Tuple[float, float]
def get_user(id: UserId) -> str:
return f"User{id}"
def plot(points: List[Point]) -> None:
for x, y in points:
print(f"({x}, {y})")
```
* `NewType`新类型创建
* 创建具有类型检查的语义化新类型
* 适合 区分相同基础类型的不同用途
```python
from typing import NewType
# 创建强类型
UserId = NewType('UserId', int)
admin_id = UserId(1001)
def print_id(user_id: UserId) -> None:
print(user_id)
# 正确调用
print_id(admin_id) # ✅
print_id(1001) # ❌ mypy报错
```
* `TypeVar`(类型变量)
* 创建通用类型参数
* 适用场景:泛型函数/类的类型参数化;比如创建一个函数,无论是处理整数、字符串还是自定义对象
```python
from typing import TypeVar, Sequence
T = TypeVar('T') # 无约束类型
Num = TypeVar('Num', int, float) # 受限类型
def first(items: Sequence[T]) -> T:
return items[0]
def sum(values: Sequence[Num]) -> Num:
return sum(values)
```
```python
from typing import TypeVar
# 定义一个泛型变量T
T = TypeVar('T')
# 创建一个泛型函数
def get_first_item(items: list[T]) -> T:
"""获取列表的第一个元素"""
if items:
return items[0]
raise ValueError("列表为空")
# 使用示例
numbers = [1, 2, 3, 4, 5]
words = ['apple', 'banana', 'cherry', 'fruit']
print(get_first_item(numbers)) # 输出: 1
print(get_first_item(words)) # 输出: apple
```
### Prompt提示词工程和案例最佳实践
#### 大模型必备Prompt提示词工程
* 什么是Prompt Engineering提示词工程
* 通过特定格式的文本输入引导AI模型生成期望输出的技术,明确地告诉模型你想要解决的问题或完成的任务
* 也是大语言模型理解用户需求并生成相关、准确回答或内容的基础
* **类比:给Java程序员的任务需求文档(越清晰明确,结果越符合预期)**
* 为什么需要学习?
* 大模型就是你的员工,你可以有多个助手,OpenAI、DeepSeek、千问等
* 作为老板的你,需要正确的下达任务,描述合理和交付目标等
```python
传统编程:写代码→计算机执行
Prompt工程:写自然语言指令→大模型生成结果
```

* Prompt设计四要素
* 角色设定(Role Prompting)
* 作用:限定模型回答视角
```python
[差] 写一首关于春天的诗
[优] 你是一位擅长写现代诗的诗人,请用比喻手法创作一首8行的春天主题短诗
```
* 任务描述
* STAR原则:Situation 场景、Task 任务、Action 行动、Result 结果
```python
(场景)用户提交了一个技术问题
(任务)需要给出准确且易懂的解答
(行动)分步骤说明解决方案
(结果)最后用一句话总结要点
```
* 格式规范
* 常用格式指令:分点列表、指定段落数、表格呈现、代码格式
```python
用JSON格式输出包含以下字段:
{
"summary": "不超过50字的摘要",
"keywords": ["关键词1", "关键词2", "关键词3"]
}
```
* 约束条件
* 常见约束类型:
| 类型 | 示例 |
| :--: | :--------------------: |
| 长度 | "答案控制在200字内" |
| 风格 | "用初中生能理解的语言" |
| 内容 | "不包含专业术语" |
| 逻辑 | "先解释概念再举例说明" |
* 汇总
| 要素 | 说明 | 反面案例 | 优化案例 |
| :----------: | :------------: | :----------: | :-------------------------: |
| **角色设定** | 明确模型身份 | "帮我写代码" | "你是一个资深Java架构师..." |
| **任务说明** | 具体执行要求 | "分析数据" | "使用Markdown表格对比..." |
| **输出格式** | 结构化结果定义 | 自由文本 | JSON/XML/YAML格式 |
| **约束条件** | 限制输出范围 | 无限制 | "不超过200字,不用专业术语" |
* 模板结构设计(黄金公式)
```python
# 标准三段式结构
prompt_template = """
[角色设定]
你是一个具有10年经验的{领域}专家,擅长{特定技能}
[任务说明]
需要完成以下任务:
1. {步骤1}
2. {步骤2}
3. {步骤3}
[输出要求]
请按照以下格式响应:
{示例格式}
"""
```
* 常见问题和排查原因
| 现象 | 可能原因 | 解决方案 |
| :--------------: | :----------------: | :----------------------: |
| 输出内容偏离主题 | 角色设定不明确 | 添加"忽略无关信息"约束 |
| 生成结果过于笼统 | 缺少具体步骤要求 | 添加"分步骤详细说明"指令 |
| 格式不符合要求 | 未提供明确格式示例 | 添加XML/JSON标记示例 |
#### Prompt提示词工程多案例最佳实践
* 需求
* 利用在线大模型或者本地大模型
* 测试不同的提示词效果,分析优化前、后的Prompt工程
* **案例实战:通用回答助手、代码生成助手、技术问答、AI数据分析 等案例实战**
* 案例实战一:通用回答
* 差Prompt:
```
告诉我关于人工智能的信息
```
* 问题分析:过于宽泛,缺乏焦点、没有指定回答的深度和范围、未明确期望的格式
* 输出结果:可能得到从历史发展到技术原理的冗长概述,缺乏针对性
* 好prompt
```python
你是一位科技专栏作家,请用通俗易懂的方式向高中生解释:
1. 什么是人工智能(用1个生活化比喻说明)
2. 列举3个当前主流应用场景
3. 字数控制在300字以内
要求使用「首先」、「其次」、「最后」的结构
```
* 优化后
* 设定回答视角(科技专栏作家)
* 明确目标受众(高中生)
* 结构化输出要求
* 添加格式约束
* 案例实战二:代码生成
* 差Prompt:
```python
写个Python程序
```
* 问题分析:没有具体功能描述、未指定输入输出格式、忽略异常处理需求
* 输出结果:可能生成简单的"Hello World"程序,与真实需求不符
* 好Prompt:
```python
编写一个Python函数,实现以下功能:
- 输入:字符串形式的日期(格式:YYYY-MM-DD)
- 输出:该日期对应的季度(1-4)
- 要求:
- 包含参数校验(不符合格式时抛出ValueError)
- 使用datetime模块
- 编写对应的单元测试用例
示例:
输入 "2024-03-15" → 返回 1
```
* 优化后
* 明确定义输入输出
* 指定实现方式
* 包含测试要求
* 提供示例验证
* 案例实战三:技术问答
* 差Prompt
```python
如何优化网站性能?
```
* 问题分析:问题范围过大、未说明技术栈、缺少评估标准
* 输出结果:可能得到泛泛而谈的通用建议
* 好Prompt
```python
针对使用SpringBoot+Vue3的技术栈,请给出5项可量化的性能优化方案:
要求:
1. 每项方案包含:
- 实施步骤
- 预期性能提升指标(如LCP减少20%)
- 复杂度评估(低/中/高)
2. 优先前端和后端优化方案
3. 引用Web Vitals评估标准
限制条件:
- 不涉及服务器扩容等硬件方案
- 排除已广泛采用的方案(如代码压缩)
```
* 优化点
* 限定技术范围
* 结构化响应要求
* 设定评估标准
* 排除已知方案
* 案例实战四:数据分析
* 差Prompt
```python
分析这份销售数据
```
* 问题分析:未说明数据特征、没有指定分析方法、缺少可视化要求
* 输出结果:可能得到无重点的描述性统计,缺乏洞察
* 好Prompt
```python
你是一位资深数据分析师,请完成以下任务:
数据集特征:
- 时间范围:2027年1-12月
- 字段:日期/产品类别/销售额/利润率
要求:
1. 找出销售额top3的月份,分析增长原因
2. 识别利润率低于5%的产品类别
3. 生成包含趋势图的Markdown报告
输出格式:
## 分析报告
### 关键发现
- 要点1(数据支撑)
- 要点2(对比分析)
### 可视化
趋势图描述,生成base64编码的折线图
```
* 优化点:
* 明确分析者角色
* 描述数据集特征
* 指定分析方法论
* 规范输出格式
#### LangChain 提示模板PromptTemplate介绍
* 需求
* 掌握LangChain 提示模板PromptTemplate常见用法
* 掌握提示词里面的占位符使用和预置变量
* PromptTemplate介绍
* 是LangChain中用于构建结构化提示词的组件,负责将用户输入/动态数据转换为LLM可理解的格式
* 它是一种单纯的字符模板,后续还有进阶的ChatPromptTemplate
* 主要解决
* 动态内容组装
* 避免Prompt硬编码

* PromptTemplate核心变量和方法
* template 定义具体的模板格式,其中 `{变量名}` 是占位符
* input_variables 定义模板中可以使用的变量。
* partial_variables:前置变量,可以提前定义部分变量的值,预填充进去
* format 使用 `format` 方法填充模板中的占位符,形成最终的文本
* 案例实战
* 创建PromptTemplate对象简单模版
```python
from langchain.prompts import PromptTemplate
# 定义模板
template = """
你是一位专业的{domain}顾问,请用{language}回答:
问题:{question}
回答:
"""
# 创建实例
prompt = PromptTemplate(
input_variables=["domain", "language", "question"],
template=template
)
print(prompt)
# 格式化输出
print(prompt.format(
domain="网络安全",
language="中文",
question="如何防范钓鱼攻击?"
))
```
* 自动推断变量
```python
from langchain.prompts import PromptTemplate
# 当不显式声明 input_variables 时
template = "请将以下文本翻译成{target_language}:{text}"
prompt = PromptTemplate.from_template(template)
print(prompt.input_variables) # 输出: ['target_language', 'text']
```
* 默认值设置
```python
from langchain.prompts import PromptTemplate
template = """分析用户情绪(默认分析类型:{analysis_type}):
用户输入:{user_input}
分析结果:"""
prompt_template = PromptTemplate(
input_variables=["user_input"],
template=template,
template_format="f-string", # 新增参数
partial_variables={"analysis_type": "情感极性分析"} # 固定值
)
print(prompt_template.format(user_input="这个产品太难用了"))
#====打印内部的变量======
print(prompt_template.template)
print(prompt_template.input_variables)
print(prompt_template.template_format)
print(prompt_template.input_types)
print(prompt_template.partial_variables)
```
#### PromptTemplate结合LLM案例实战
* 案例实战
```python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
#创建prompt AIGC
prompt_template = PromptTemplate(
input_variables=["product"],
template="为{product}写3个吸引人的广告语,需要面向年轻人",
)
prompt = prompt_template.invoke({"product":"小滴课堂"})
#创建模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
#调用大模型
response = model.invoke(prompt)
#print(response.content)
#创建输出解析器
out_parser = StrOutputParser()
answer = out_parser.invoke(response)
print(answer)
```
#### 大模型ChatModel聊天模型和Token计算
* 什么是**ChatModel**
* 是专为**多轮对话场景**设计的大语言模型(LLM),通过理解上下文和对话逻辑,生成连贯、符合人类交互习惯的回复。
* 不仅是简单的文本生成工具,更是能处理复杂对话流程的智能系统
* 核心特点
| 特性 | 说明 | 示例场景 |
| :--------------: | :----------------------------------------------: | :----------------------------------------------------------: |
| **上下文感知** | 追踪多轮对话历史,理解指代关系(如“它”、“这个”) | 用户:“什么是量子计算?” → AI 解释 → 用户:“它有什么应用?” → AI 能正确关联“它”指量子计算 |
| **角色扮演能力** | 可设定特定角色(如客服、教师)并保持一致性 | 设定AI为“医疗助手”时,拒绝提供诊断建议,仅提供健康信息 |
| **意图识别** | 解析用户深层需求(如咨询、投诉、闲聊) | 用户:“我的订单没收到!” → AI 识别为物流投诉,优先转接人工客服 |
| **情感分析** | 识别用户情绪(积极/消极),调整回复语气 | 用户表达不满时,AI 回复:“非常抱歉给您带来不便,我们会立刻处理...” |
| **安全过滤** | 避免生成有害、偏见或敏感内容 | 用户请求生成暴力内容时,AI 拒绝并提示:“我无法协助这个请求” |
* ChatModel vs. 传统 Text Model
| **对比维度** | **ChatModel** | **传统 Text Model(如 text-davinci-003)** |
| :------------: | :------------------------------------: | :----------------------------------------: |
| **核心目标** | 多轮交互式对话 | 单次文本生成(文章、代码等) |
| **输入格式** | 结构化消息序列(System/Human/AI 角色) | 纯文本提示 |
| **上下文处理** | 自动管理对话历史 | 需手动拼接历史文本 |
| **输出控制** | 内置安全审查和格式约束 | 依赖提示词工程控制 |
| **典型应用** | 客服机器人、虚拟助手 | 内容创作、数据清洗 |
* 聊天模型(如 GPT-3.5-turbo、GPT-4)通过 **角色化消息** 实现对话控制,核心角色包括:
| 角色类型 | 标识符 | 功能定位 | 使用场景示例 |
| :-----------: | :---------: | :------------------------: | :----------------------------------------------------------: |
| **System** | `system` | 定义AI的行为准则和角色设定 | 设定AI身份、回答规则、知识范围
`("system", "你是一位医疗助手...")` |
| **User** | `user` | 代表用户的输入信息 | 用户提问、指令、反馈
`("human", "如何缓解头痛?")` |
| **Assistant** | `assistant` | 存储AI的历史回复 | 维护对话上下文、保持回答连贯性
`("ai", "建议服用布洛芬...")` |
* 参考案例OpenAI代码
```python
# 多轮对话示例
messages = [
{"role": "system", "content": "你是一个电影推荐助手"},
{"role": "user", "content": "我喜欢科幻片,推荐三部经典"},
{"role": "assistant", "content": "1.《银翼杀手2049》... 2.《星际穿越》... 3.《黑客帝国》"},
{"role": "user", "content": "第二部的主演是谁?"} # 基于上下文追问
]
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages
)
print(response.choices[0].message.content)
# 输出:《星际穿越》的主演是马修·麦康纳和安妮·海瑟薇...
```
* Chat聊天多轮对话中的Token如何计算
* 在多轮对话场景下,上下文通常涵盖以下几部分:
* **用户的历史输入** :之前用户说过的话,这些内容会作为上下文的一部分,帮助模型理解当前对话的背景和意图。
* **模型的历史回复** :模型之前给出的回应,这样能让模型保持对话的连贯性和一致性。
* **系统提示** :用于设定聊天机器人的角色、目标等,引导对话的方向和风格。
* 随着上下文内容的增加,Token 数量也会相应增多。
* 多轮对话的上下文 Token 累积
* 假设每轮对话中,用户的输入和模型的输出分别对应一定数量的 Token
* 我们以每轮对话输入 50 Token、输出 100 Token 为例来计算:
* **第 1 轮** :用户的输入为 50 Token,模型的输出为 100 Token,此时上下文中的 Token 总数为 50 + 100 = 150 Token。
* **第 2 轮** :新的用户输入为 50 Token,模型新的输出为 100 Token,加上之前的历史上下文 150 Token,此时上下文中的 Token 总数为 50 + 100 + 150 = 300 Token。
* **第 3 轮** :再次新增用户输入 50 Token 和模型输出 100 Token,加上之前的历史上下文 300 Token,上下文中的 Token 总数变为 50 + 100 + 300 = 450 Token
* 上下文窗口的限制
* 每个大语言模型都有一个 “上下文窗口大小”(Context Window)的限制,
* 它决定了模型能够处理的上下文的最大 Token 数量。
* 常见的上下文窗口大小有:
* 4k Tokens :例如 OpenAI GPT - 3.5,其上下文窗口大小为 4096 个 Token。
* 8k、32k Tokens :支持长上下文的模型,如 GPT-4 等,有更大的上下文窗口,分别为 8192 个和 32768 个 Token。
#### 聊天模型ChatPromptTemplate讲解
* ChatPromptTemplate 核心概念
* 核心差异
* 支持**消息角色**(system/user/assistant)
* 天然适配聊天模型(如GPT-3.5/4)
* 可维护对话上下文

* 消息类型体系
| 消息模板类 | 对应角色 | 典型用途 |
| :-------------------------: | :--------: | :--------------: |
| SystemMessagePromptTemplate | 系统消息 | 设定AI行为规则 |
| HumanMessagePromptTemplate | 用户消息 | 接收用户输入 |
| AIMessagePromptTemplate | AI回复消息 | 记录历史响应 |
| ChatPromptTemplate | 容器模板 | 组合多个消息模板 |
* 掌握两个常见类方法
* `ChatPromptTemplate.from_template()`
* 用于创建单条消息模板,通常结合其他方法构建更复杂的对话流程。
* 适用于单一角色的消息定义(如仅系统指令或用户输入)。
* 需与其他模板组合使用,例如通过`from_messages`整合多个单模板
* `ChatPromptTemplate.from_messages()`
* 用于构建多轮对话模板,支持定义不同角色(如系统、用户、AI)的消息,并允许动态插入变量。
* 支持消息列表,每个消息可以是元组或`MessagePromptTemplate`对象。
* 角色类型包括:`system(系统指令)、human(用户输入)、ai(模型回复)`
* 可通过占位符(如`{variable}`)动态替换内容。
* 汇总对比
| 方法 | 适用场景 | 灵活性 | 代码复杂度 |
| :-------------: | :------------------------------: | :----: | :----------------: |
| `from_messages` | 多角色、多轮对话(如聊天机器人) | 高 | 较高(需定义列表) |
| `from_template` | 单角色消息模板(需组合使用) | 低 | 简单 |
* 案例实战
* 使用from_messages构建多轮对话模板
```python
from langchain_core.prompts import ChatPromptTemplate
# 定义消息列表,包含系统指令、用户输入和AI回复模板, 通过元组列表定义角色和模板,动态插入name和user_input变量
chat_template = ChatPromptTemplate.from_messages([
("system", "你是一个助手AI,名字是{name}。"),
("human", "你好,最近怎么样?"),
("ai", "我很好,谢谢!"),
("human", "{user_input}")
])
# 格式化模板并传入变量
messages = chat_template.format_messages(
name="Bob",
user_input="你最喜欢的编程语言是什么?"
)
print(messages)
# 输出结果示例:
# SystemMessage(content='你是一个助手AI,名字是Bob。')
# HumanMessage(content='你好,最近怎么样?')
# AIMessage(content='我很好,谢谢!')
# HumanMessage(content='你最喜欢的编程语言是什么?')
```
* 结合`from_template`与`from_messages`
```python
from langchain_core.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate
)
# 创建单条消息模板,通过细分模板类(如SystemMessagePromptTemplate)定义单条消息,再通过from_messages组合
system_template = SystemMessagePromptTemplate.from_template(
"你是一个{role},请用{language}回答。"
)
user_template = HumanMessagePromptTemplate.from_template("{question}")
# 组合成多轮对话模板
chat_template = ChatPromptTemplate.from_messages([
system_template,
user_template
])
# 使用示例
messages = chat_template.format_messages(
role="翻译助手",
language="中文",
question="将'I love Python'翻译成中文。"
)
print(messages)
# 输出结果示例:
# SystemMessage(content='你是一个翻译助手,请用中文回答。')
# HumanMessage(content='将'I love Python'翻译成中文。'
```
#### LangChain聊天模型多案例实战
* 需求
* 聊天模型案例实战,需要结合LLM大模型进行调用
* 简单记执行顺序 ` from_template->from_messages->format_messages`
* 最终传递给大模型是完整构建消息列表对象
* 领域专家案例实战
```python
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 构建消息列表(类似Java的ListMessage>)
messages = [
SystemMessage(content="你是一个Java专家,用中文回答"),
HumanMessage(content="解释volatile关键字的作用")
]
# 同步调用(类似Java的execute())
response = model.invoke(messages)
print(response.content)
"""
volatile关键字主要用于:
1. 保证变量可见性...
2. 禁止指令重排序...
"""
```
* 带参数的领域专家
```python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain.prompts import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate
)
# 定义系统消息模板
system_template = SystemMessagePromptTemplate.from_template(
"你是一位专业的{domain}专家,回答需满足:{style_guide}"
)
# 定义用户消息模板
human_template = HumanMessagePromptTemplate.from_template(
"请解释:{concept}"
)
# 组合聊天提示
chat_prompt = ChatPromptTemplate.from_messages([
system_template,
human_template
])
# 格式化输出
messages = chat_prompt.format_messages(
domain="机器学习",
style_guide="使用比喻和示例说明",
concept="过拟合"
)
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
response = model.invoke(messages)
print(response)
```
* 合规客服系统
```python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
compliance_template = ChatPromptTemplate.from_messages([
("system", """您是{company}客服助手,遵守:
1. 不透露内部系统名称
2. 不提供医疗/金融建议
3. 遇到{transfer_cond}转人工"""),
("human", "[{user_level}用户]:{query}")
])
messages = compliance_template.format_messages(company="小滴课堂老王医生", transfer_cond="病情咨询、支付问题", user_level="VIP", query="感冒应该吃什么药?")
response = model.invoke(messages)
print(response)
```
### LCEL表达式和输出解析器多案例实战
#### LangChain链和LLMChain链案例实战
* 什么是Chain链
* 是构建语言模型应用的核心组件,用于将多个模块(如模型调用、提示模板、记忆系统等)组合成可复用的工作流程。
* 本质:将多个处理单元(模型/工具/逻辑)按特定顺序连接起来,形成完整的任务处理流程
* 想象Java中的责任链模式或工作流引擎中的步骤串联。
```java
// 传统Java责任链模式(对比理解)
public interface Handler {
void handle(Request request);
}
class ValidationHandler implements Handler { /* 验证逻辑 */ }
class LLMProcessingHandler implements Handler { /* 大模型处理 */ }
class DatabaseSaveHandler implements Handler { /* 存储结果 */ }
// 构建处理链
List * 对比Java开发的模型验证
* 典型Java方式(需手写校验逻辑)
```java
public class User {
private String name;
private int age;
// 需要手写校验方法
public void validate() throws IllegalArgumentException {
if (name == null || name.isEmpty()) {
throw new IllegalArgumentException("姓名不能为空");
}
if (age > 150) {
throw new IllegalArgumentException("年龄不合法");
}
}
}
```
* 传统Python方式(样板代码)
```python
class User:
def __init__(self, name: str, age: int):
if not isinstance(name, str):
raise TypeError("name必须是字符串")
if not isinstance(age, int):
raise TypeError("age必须是整数")
if age > 150:
raise ValueError("年龄必须在0-150之间")
self.name = name
self.age = age
```
* pydantic方式(声明式验证)
```python
# 只需3行代码即可实现完整验证!
from pydantic import BaseModel, Field
class User(BaseModel):
name: str = Field(min_length=1, max_length=50) # 内置字符串长度验证
age: int = Field(ge=0, le=150) # 数值范围验证(类似Java的@Min/@Max)
```
* 案例实战
* 模块安装 Pydantic V2(需要Python 3.10+)
```shell
pip install pydantic==2.7.4
```
* 使用
* Pydantic 的主要方法是创建继承自 BaseModel 的自定义类
```python
from pydantic import BaseModel
# 类似Java中的POJO,但更强大
class UserProfile(BaseModel):
username: str # 必须字段
age: int = 18 # 默认值
email: str | None = None # 可选字段
# 实例化验证
user1 = UserProfile(username="Alice")
print(user1) # username='Alice' age=18 email=None
user2 = UserProfile(username="Bob", age="20") # 自动类型转换
print(user2.age) # 20(int类型)
```
* 创建实例与校验
```python
try:
UserProfile(username=123) # 触发验证错误
except ValueError as e:
print(e.errors())
# [{
# 'type': 'string_type',
# 'loc': ('username',),
# 'msg': 'Input should be a valid string',
# 'input': 123
# }]
```
* 字段类型验证
```python
from pydantic import BaseModel,HttpUrl,ValidationError
class WebSite(BaseModel):
url: HttpUrl #URL格式验证
visits: int = 0 #默认值
tags: list[str] = [] #字符串列表
valid_data = {
"url": "https://www.baidu.com",
"visits": 100,
"tags": ["python", "fastapi"]
}
# try:
# website = WebSite(**valid_data)
# print(website)
# except ValidationError as e:
# print(e.errors())
try:
website = WebSite(url="xdclass.net",visits=100)
print(website)
except ValidationError as e:
print(e.errors())
```
* 数据解析/序列化
```python
from pydantic import BaseModel
class Item(BaseModel):
name: str
price: float
# 从JSON自动解析(类似Jackson)
data = '{"name": "Widget", "price": "9.99"}' # 字符串数字自动转换
item = Item.model_validate_json(data)
# 导出为字典(类似Java的POJO转Map)
print(item.model_dump()) # {'name': 'Widget', 'price': 9.99}
```
* 调试技巧:打印模型结构
```python
print(Website.model_json_schema())
# 输出完整的JSON Schem
```
#### Pydantic字段校验Field函数多案例实战
* Filed函数讲解
* Field函数通常用于给模型字段添加额外的元数据或者验证条件。
* 例如,title参数用来设置字段的标题,min_length用来限制最小长度。
* 核心
* **`...` 的本质**:表示“无默认值”,强制字段必填。
* **`Field` 的常用参数**:
- `title`:字段标题(用于文档)
- `description`:详细描述
- `min_length`/`max_length`(字符串、列表)
- `gt`/`ge`/`lt`/`le`(数值范围)
- `regex`(正则表达式)
- `example`(示例值,常用于 API 文档)
* 案例实战
* 必填字段(无默认值)
* 必填字段:
* ... 表示该字段必须显式提供值。若创建模型实例时未传入此字段,Pydantic 会抛出验证错误(ValidationError)。
* 默认值占位
* Field 的第一个参数是 default,而 ... 在此处的语义等价于“无默认值”。
* 若省略 default 参数(如 Field(title="用户名")),Pydantic 会隐式使用 ...,但显式写出更明确
```python
from pydantic import BaseModel, Field
class User(BaseModel):
name: str = Field(..., title="用户名", min_length=2)
# 正确用法
user = User(name="Alice")
# 错误用法:缺少 name 字段
user = User() # 触发 ValidationError
```
* 可选字段(有默认值)
```python
from pydantic import BaseModel, Field
class UserOptional(BaseModel):
name: str = Field("Guest", title="用户名") # 默认值为 "Guest"
# 可不传 name,自动使用默认值
user = UserOptional()
print(user.name) # 输出 "Guest"
```
* 以下两种写法完全等价, 使用 `Field` 的优势在于可以附加额外参数(如 `title`、`min_length`、`description` 等)。
```python
# 写法 1:省略 Field,直接类型注解
name: str
# 写法 2:显式使用 Field(...)
name: str = Field(...)
```
* 数值类型必填
```python
from pydantic import BaseModel, Field, ValidationError
class Product(BaseModel):
price: float = Field(..., title="价格", gt=0) # 必须 > 0
stock: int = Field(..., ge=0) # 必须 >= 0
# 正确
product = Product(price=99.9, stock=10)
# 错误:price <= 0
try:
Product(price=-5, stock=10)
except ValidationError as e:
print(e.json()) # 提示 "price" 必须大于 0
```
* 嵌套模型必填
```python
from pydantic import BaseModel, Field
class Address(BaseModel):
city: str = Field(..., min_length=1)
street: str
class User(BaseModel):
name: str = Field(...)
address: Address # 等效于 address: Address = Field(...)
# 正确
user = User(name="Alice", address={"city": "Shanghai", "street": "Main St"})
# 错误:缺少 address
user = User(name="Bob") # 触发 ValidationError
```
* 明确可选字段
```python
from pydantic import BaseModel, Field
from typing import Optional
class User(BaseModel):
name: str = Field(...)
email: Optional[str] = Field(None, title="邮箱") # 可选,默认值为 None
# 正确:不传 email
user = User(name="Alice")
```
* 混合使用默认值和必填
```python
from pydantic import BaseModel, Field
class Config(BaseModel):
api_key: str = Field(...) # 必填
timeout: int = Field(10, ge=1) # 可选,默认 10,但必须 >=1
# 正确
config = Config(api_key="secret")
assert config.timeout == 10
# 错误:未传 api_key
Config(timeout=5) # 触发 ValidationError
```
#### Pydantic自定义验证器多案例实战
* `@field_validator`介绍
* 是 Pydantic 中用于为**单个字段**添加自定义验证逻辑的装饰器
* **适用场景**:当默认验证规则(如 `min_length`、`gt`)无法满足需求时,通过编写代码实现复杂校验。
* **触发时机**:默认在字段通过基础类型和规则校验后执行(可通过 `mode` 参数调整)
* 基础语法
```python
from pydantic import BaseModel, ValidationError, field_validator
class User(BaseModel):
username: str
# 带默认值的可选字段
# int | None表示 age 变量的类型可以是整数 (int) 或 None,旧版本的写法:age: Union[int, None]
# Python 3.10 开始引入,替代了早期通过 Union[int, None] 的形式(仍兼容)
age: int | None = Field(
default=None,
ge=18,
description="用户年龄必须≥18岁"
)
@field_validator("username")
def validate_username(cls, value: str) -> str:
# cls: 模型类(可访问其他字段)
# value: 当前字段的值
if len(value) < 3:
raise ValueError("用户名至少 3 个字符")
return value # 可修改返回值(如格式化)
```
* 案例实战
* 字符串格式校验
```python
from pydantic import BaseModel, Field,field_validator
class User(BaseModel):
email: str
@field_validator("email")
def validate_email(cls, v):
if "@" not in v:
raise ValueError("邮箱格式无效")
return v.lower() # 返回格式化后的值
# 正确
User(email="ALICE@example.com") # 自动转为小写:alice@example.com
# 错误
#User(email="invalid") # 触发 ValueError
```
* 验证用户名和长度
```python
from pydantic import BaseModel, Field,field_validator
class User(BaseModel):
username: str = Field(..., min_length=3)
@field_validator("username")
def validate_username(cls, v):
if "admin" in v:
raise ValueError("用户名不能包含 'admin'")
return v
# 正确
User(username="alice123")
# 错误
#User(username="admin") # 触发自定义验证错误
```
* 密码复杂性验证
```python
from pydantic import BaseModel, Field,field_validator
class Account(BaseModel):
password: str
@field_validator("password")
def validate_password(cls, v):
errors = []
if len(v) < 8:
errors.append("至少 8 个字符")
if not any(c.isupper() for c in v):
errors.append("至少一个大写字母")
if errors:
raise ValueError("; ".join(errors))
return v
# 错误:密码不符合规则
Account(password="weak") # 提示:至少 8 个字符; 至少一个大写字母
```
* 多个字段共享验证器
```python
from pydantic import BaseModel, Field,field_validator
class Product(BaseModel):
price: float
cost: float
@field_validator("price", "cost")
def check_positive(cls, v):
if v <= 0:
raise ValueError("必须大于 0")
return v
# 同时验证 price 和 cost 是否为正数
Product(price=1, cost=-2)
```
* 注意事项
* 忘记返回值:验证器必须返回字段的值(除非明确要修改)。
```python
@field_validator("email")
def validate_email(cls, v):
if "@" not in v:
raise ValueError("Invalid email")
# ❌ 错误:未返回 v
```
* **Pydantic V2 现为 Pydantic 的当前生产发布版本**
* 网上不少是V1版本的教程,需要注意
* Pydantic V1和Pydantic V2的API差异
| Pydantic V1 | Pydantic V2 |
| :----------------------- | :----------------------- |
| `__fields__` | `model_fields` |
| `__private_attributes__` | `__pydantic_private__` |
| `__validators__` | `__pydantic_validator__` |
| `construct()` | `model_construct()` |
| `copy()` | `model_copy()` |
| `dict()` | `model_dump()` |
| `json_schema()` | `model_json_schema()` |
| `json()` | `model_dump_json()` |
| `parse_obj()` | `model_validate()` |
| `update_forward_refs()` | `model_rebuild()` |
#### 重点-解析器PydanticOutputParser实战
* 为啥要用为什么需要Pydantic解析?
* 结构化输出:将非结构化文本转为可编程对象
* 数据验证:自动验证字段类型和约束条件,单纯json解析器则不会校验
* 开发效率:减少手动解析代码
* 错误处理:内置异常捕获与修复机制
* **案例实战一:大模型信息输出提取( `PydanticOutputParser` 结合Pydantic模型验证输出)**
```python
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from langchain_core.output_parsers import PydanticOutputParser
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# Step1: 定义Pydantic模型
class UserInfo(BaseModel):
name: str = Field(description="用户姓名")
age: int = Field(description="用户年龄", gt=0)
hobbies: list[str] = Field(description="兴趣爱好列表")
# Step2: 创建解析器
parser = PydanticOutputParser(pydantic_object=UserInfo)
# Step3: 构建提示模板
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("""
提取用户信息,严格按格式输出:
{format_instructions}
输入内容:
{input}
""")
# 注入格式指令
prompt = prompt.partial(
format_instructions=parser.get_format_instructions()
)
# Step4: 组合处理链
chain = prompt | model | parser
# 执行解析
result = chain.invoke({
"input": """
我的名称是张三,年龄是18岁,兴趣爱好有打篮球、看电影。
"""
})
print(type(result))
print(result)
```
* **案例实战二:电商评论情感分析系统(JsonOutputParser和pydantic结合)**
* `JsonOutputParser`与`PydanticOutputParser`类似
* 新版才支持从pydantic获取约束模型,该参数并非强制要求,而是可选的增强功能
* `JsonOutputParser`可以处理流式返回的部分JSON对象。
```python
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 定义JSON结构
class SentimentResult(BaseModel):
sentiment: str
confidence: float
keywords: list[str]
# 构建处理链
parser = JsonOutputParser(pydantic_object=SentimentResult)
prompt = ChatPromptTemplate.from_template("""
分析评论情感:
{input}
按以下JSON格式返回:
{format_instructions}
""").partial(format_instructions=parser.get_format_instructions())
chain = prompt | model | parser
# 执行分析
result = chain.invoke({"input": "物流很慢,包装破损严重"})
print(result)
# 输出:
# {
# "sentiment": "negative",
# "confidence": 0.85,
# "keywords": ["物流快", "包装破损"]
# }
# 2. 执行流式调用
#for chunk in chain.stream({"input": "物流很慢,包装破损严重"}):
# print(chunk) # 逐词输出
```
#### 重点-大模型修复机制OutputFixingParser
* `OutputFixingParser`
* 是LangChain中用于修复语言模型(LLM)输出格式错误的工具,通常与`PydanticOutputParser`配合使用。
* 当原始解析器因格式问题(如JSON语法错误、字段缺失等)失败时,它能自动调用LLM修正输出,提升解析的鲁棒性。
* 核心功能:
* 自动纠错:修复不规范的输出格式(如单引号JSON、字段顺序错误等)。
* 兼容性:与Pydantic数据模型无缝集成,支持结构化输出验证。
* 容错机制:避免因模型输出不稳定导致程序中断
* 对比Java开发的模型验证
* 典型Java方式(需手写校验逻辑)
```java
public class User {
private String name;
private int age;
// 需要手写校验方法
public void validate() throws IllegalArgumentException {
if (name == null || name.isEmpty()) {
throw new IllegalArgumentException("姓名不能为空");
}
if (age > 150) {
throw new IllegalArgumentException("年龄不合法");
}
}
}
```
* 传统Python方式(样板代码)
```python
class User:
def __init__(self, name: str, age: int):
if not isinstance(name, str):
raise TypeError("name必须是字符串")
if not isinstance(age, int):
raise TypeError("age必须是整数")
if age > 150:
raise ValueError("年龄必须在0-150之间")
self.name = name
self.age = age
```
* pydantic方式(声明式验证)
```python
# 只需3行代码即可实现完整验证!
from pydantic import BaseModel, Field
class User(BaseModel):
name: str = Field(min_length=1, max_length=50) # 内置字符串长度验证
age: int = Field(ge=0, le=150) # 数值范围验证(类似Java的@Min/@Max)
```
* 案例实战
* 模块安装 Pydantic V2(需要Python 3.10+)
```shell
pip install pydantic==2.7.4
```
* 使用
* Pydantic 的主要方法是创建继承自 BaseModel 的自定义类
```python
from pydantic import BaseModel
# 类似Java中的POJO,但更强大
class UserProfile(BaseModel):
username: str # 必须字段
age: int = 18 # 默认值
email: str | None = None # 可选字段
# 实例化验证
user1 = UserProfile(username="Alice")
print(user1) # username='Alice' age=18 email=None
user2 = UserProfile(username="Bob", age="20") # 自动类型转换
print(user2.age) # 20(int类型)
```
* 创建实例与校验
```python
try:
UserProfile(username=123) # 触发验证错误
except ValueError as e:
print(e.errors())
# [{
# 'type': 'string_type',
# 'loc': ('username',),
# 'msg': 'Input should be a valid string',
# 'input': 123
# }]
```
* 字段类型验证
```python
from pydantic import BaseModel,HttpUrl,ValidationError
class WebSite(BaseModel):
url: HttpUrl #URL格式验证
visits: int = 0 #默认值
tags: list[str] = [] #字符串列表
valid_data = {
"url": "https://www.baidu.com",
"visits": 100,
"tags": ["python", "fastapi"]
}
# try:
# website = WebSite(**valid_data)
# print(website)
# except ValidationError as e:
# print(e.errors())
try:
website = WebSite(url="xdclass.net",visits=100)
print(website)
except ValidationError as e:
print(e.errors())
```
* 数据解析/序列化
```python
from pydantic import BaseModel
class Item(BaseModel):
name: str
price: float
# 从JSON自动解析(类似Jackson)
data = '{"name": "Widget", "price": "9.99"}' # 字符串数字自动转换
item = Item.model_validate_json(data)
# 导出为字典(类似Java的POJO转Map)
print(item.model_dump()) # {'name': 'Widget', 'price': 9.99}
```
* 调试技巧:打印模型结构
```python
print(Website.model_json_schema())
# 输出完整的JSON Schem
```
#### Pydantic字段校验Field函数多案例实战
* Filed函数讲解
* Field函数通常用于给模型字段添加额外的元数据或者验证条件。
* 例如,title参数用来设置字段的标题,min_length用来限制最小长度。
* 核心
* **`...` 的本质**:表示“无默认值”,强制字段必填。
* **`Field` 的常用参数**:
- `title`:字段标题(用于文档)
- `description`:详细描述
- `min_length`/`max_length`(字符串、列表)
- `gt`/`ge`/`lt`/`le`(数值范围)
- `regex`(正则表达式)
- `example`(示例值,常用于 API 文档)
* 案例实战
* 必填字段(无默认值)
* 必填字段:
* ... 表示该字段必须显式提供值。若创建模型实例时未传入此字段,Pydantic 会抛出验证错误(ValidationError)。
* 默认值占位
* Field 的第一个参数是 default,而 ... 在此处的语义等价于“无默认值”。
* 若省略 default 参数(如 Field(title="用户名")),Pydantic 会隐式使用 ...,但显式写出更明确
```python
from pydantic import BaseModel, Field
class User(BaseModel):
name: str = Field(..., title="用户名", min_length=2)
# 正确用法
user = User(name="Alice")
# 错误用法:缺少 name 字段
user = User() # 触发 ValidationError
```
* 可选字段(有默认值)
```python
from pydantic import BaseModel, Field
class UserOptional(BaseModel):
name: str = Field("Guest", title="用户名") # 默认值为 "Guest"
# 可不传 name,自动使用默认值
user = UserOptional()
print(user.name) # 输出 "Guest"
```
* 以下两种写法完全等价, 使用 `Field` 的优势在于可以附加额外参数(如 `title`、`min_length`、`description` 等)。
```python
# 写法 1:省略 Field,直接类型注解
name: str
# 写法 2:显式使用 Field(...)
name: str = Field(...)
```
* 数值类型必填
```python
from pydantic import BaseModel, Field, ValidationError
class Product(BaseModel):
price: float = Field(..., title="价格", gt=0) # 必须 > 0
stock: int = Field(..., ge=0) # 必须 >= 0
# 正确
product = Product(price=99.9, stock=10)
# 错误:price <= 0
try:
Product(price=-5, stock=10)
except ValidationError as e:
print(e.json()) # 提示 "price" 必须大于 0
```
* 嵌套模型必填
```python
from pydantic import BaseModel, Field
class Address(BaseModel):
city: str = Field(..., min_length=1)
street: str
class User(BaseModel):
name: str = Field(...)
address: Address # 等效于 address: Address = Field(...)
# 正确
user = User(name="Alice", address={"city": "Shanghai", "street": "Main St"})
# 错误:缺少 address
user = User(name="Bob") # 触发 ValidationError
```
* 明确可选字段
```python
from pydantic import BaseModel, Field
from typing import Optional
class User(BaseModel):
name: str = Field(...)
email: Optional[str] = Field(None, title="邮箱") # 可选,默认值为 None
# 正确:不传 email
user = User(name="Alice")
```
* 混合使用默认值和必填
```python
from pydantic import BaseModel, Field
class Config(BaseModel):
api_key: str = Field(...) # 必填
timeout: int = Field(10, ge=1) # 可选,默认 10,但必须 >=1
# 正确
config = Config(api_key="secret")
assert config.timeout == 10
# 错误:未传 api_key
Config(timeout=5) # 触发 ValidationError
```
#### Pydantic自定义验证器多案例实战
* `@field_validator`介绍
* 是 Pydantic 中用于为**单个字段**添加自定义验证逻辑的装饰器
* **适用场景**:当默认验证规则(如 `min_length`、`gt`)无法满足需求时,通过编写代码实现复杂校验。
* **触发时机**:默认在字段通过基础类型和规则校验后执行(可通过 `mode` 参数调整)
* 基础语法
```python
from pydantic import BaseModel, ValidationError, field_validator
class User(BaseModel):
username: str
# 带默认值的可选字段
# int | None表示 age 变量的类型可以是整数 (int) 或 None,旧版本的写法:age: Union[int, None]
# Python 3.10 开始引入,替代了早期通过 Union[int, None] 的形式(仍兼容)
age: int | None = Field(
default=None,
ge=18,
description="用户年龄必须≥18岁"
)
@field_validator("username")
def validate_username(cls, value: str) -> str:
# cls: 模型类(可访问其他字段)
# value: 当前字段的值
if len(value) < 3:
raise ValueError("用户名至少 3 个字符")
return value # 可修改返回值(如格式化)
```
* 案例实战
* 字符串格式校验
```python
from pydantic import BaseModel, Field,field_validator
class User(BaseModel):
email: str
@field_validator("email")
def validate_email(cls, v):
if "@" not in v:
raise ValueError("邮箱格式无效")
return v.lower() # 返回格式化后的值
# 正确
User(email="ALICE@example.com") # 自动转为小写:alice@example.com
# 错误
#User(email="invalid") # 触发 ValueError
```
* 验证用户名和长度
```python
from pydantic import BaseModel, Field,field_validator
class User(BaseModel):
username: str = Field(..., min_length=3)
@field_validator("username")
def validate_username(cls, v):
if "admin" in v:
raise ValueError("用户名不能包含 'admin'")
return v
# 正确
User(username="alice123")
# 错误
#User(username="admin") # 触发自定义验证错误
```
* 密码复杂性验证
```python
from pydantic import BaseModel, Field,field_validator
class Account(BaseModel):
password: str
@field_validator("password")
def validate_password(cls, v):
errors = []
if len(v) < 8:
errors.append("至少 8 个字符")
if not any(c.isupper() for c in v):
errors.append("至少一个大写字母")
if errors:
raise ValueError("; ".join(errors))
return v
# 错误:密码不符合规则
Account(password="weak") # 提示:至少 8 个字符; 至少一个大写字母
```
* 多个字段共享验证器
```python
from pydantic import BaseModel, Field,field_validator
class Product(BaseModel):
price: float
cost: float
@field_validator("price", "cost")
def check_positive(cls, v):
if v <= 0:
raise ValueError("必须大于 0")
return v
# 同时验证 price 和 cost 是否为正数
Product(price=1, cost=-2)
```
* 注意事项
* 忘记返回值:验证器必须返回字段的值(除非明确要修改)。
```python
@field_validator("email")
def validate_email(cls, v):
if "@" not in v:
raise ValueError("Invalid email")
# ❌ 错误:未返回 v
```
* **Pydantic V2 现为 Pydantic 的当前生产发布版本**
* 网上不少是V1版本的教程,需要注意
* Pydantic V1和Pydantic V2的API差异
| Pydantic V1 | Pydantic V2 |
| :----------------------- | :----------------------- |
| `__fields__` | `model_fields` |
| `__private_attributes__` | `__pydantic_private__` |
| `__validators__` | `__pydantic_validator__` |
| `construct()` | `model_construct()` |
| `copy()` | `model_copy()` |
| `dict()` | `model_dump()` |
| `json_schema()` | `model_json_schema()` |
| `json()` | `model_dump_json()` |
| `parse_obj()` | `model_validate()` |
| `update_forward_refs()` | `model_rebuild()` |
#### 重点-解析器PydanticOutputParser实战
* 为啥要用为什么需要Pydantic解析?
* 结构化输出:将非结构化文本转为可编程对象
* 数据验证:自动验证字段类型和约束条件,单纯json解析器则不会校验
* 开发效率:减少手动解析代码
* 错误处理:内置异常捕获与修复机制
* **案例实战一:大模型信息输出提取( `PydanticOutputParser` 结合Pydantic模型验证输出)**
```python
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from langchain_core.output_parsers import PydanticOutputParser
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# Step1: 定义Pydantic模型
class UserInfo(BaseModel):
name: str = Field(description="用户姓名")
age: int = Field(description="用户年龄", gt=0)
hobbies: list[str] = Field(description="兴趣爱好列表")
# Step2: 创建解析器
parser = PydanticOutputParser(pydantic_object=UserInfo)
# Step3: 构建提示模板
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("""
提取用户信息,严格按格式输出:
{format_instructions}
输入内容:
{input}
""")
# 注入格式指令
prompt = prompt.partial(
format_instructions=parser.get_format_instructions()
)
# Step4: 组合处理链
chain = prompt | model | parser
# 执行解析
result = chain.invoke({
"input": """
我的名称是张三,年龄是18岁,兴趣爱好有打篮球、看电影。
"""
})
print(type(result))
print(result)
```
* **案例实战二:电商评论情感分析系统(JsonOutputParser和pydantic结合)**
* `JsonOutputParser`与`PydanticOutputParser`类似
* 新版才支持从pydantic获取约束模型,该参数并非强制要求,而是可选的增强功能
* `JsonOutputParser`可以处理流式返回的部分JSON对象。
```python
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 定义JSON结构
class SentimentResult(BaseModel):
sentiment: str
confidence: float
keywords: list[str]
# 构建处理链
parser = JsonOutputParser(pydantic_object=SentimentResult)
prompt = ChatPromptTemplate.from_template("""
分析评论情感:
{input}
按以下JSON格式返回:
{format_instructions}
""").partial(format_instructions=parser.get_format_instructions())
chain = prompt | model | parser
# 执行分析
result = chain.invoke({"input": "物流很慢,包装破损严重"})
print(result)
# 输出:
# {
# "sentiment": "negative",
# "confidence": 0.85,
# "keywords": ["物流快", "包装破损"]
# }
# 2. 执行流式调用
#for chunk in chain.stream({"input": "物流很慢,包装破损严重"}):
# print(chunk) # 逐词输出
```
#### 重点-大模型修复机制OutputFixingParser
* `OutputFixingParser`
* 是LangChain中用于修复语言模型(LLM)输出格式错误的工具,通常与`PydanticOutputParser`配合使用。
* 当原始解析器因格式问题(如JSON语法错误、字段缺失等)失败时,它能自动调用LLM修正输出,提升解析的鲁棒性。
* 核心功能:
* 自动纠错:修复不规范的输出格式(如单引号JSON、字段顺序错误等)。
* 兼容性:与Pydantic数据模型无缝集成,支持结构化输出验证。
* 容错机制:避免因模型输出不稳定导致程序中断
 * 核心语法与使用步骤
* 基础语法
```python
from langchain.output_parsers import OutputFixingParser, PydanticOutputParser
from langchain_openai import ChatOpenAI
# 步骤1:定义Pydantic数据模型
class MyModel(BaseModel):
field1: str = Field(description="字段描述")
field2: int
# 步骤2:创建原始解析器
parser = PydanticOutputParser(pydantic_object=MyModel)
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 步骤3:包装为OutputFixingParser
fixing_parser = OutputFixingParser.from_llm(parser=parser, llm=model)
```
* 参数说明:
* parser: 原始解析器对象(如PydanticOutputParser)。
* llm: 用于修复错误的语言模型实例。
* max_retries(可选): 最大重试次数(默认1)
* 案例实战
* 修复机制
* 检测到错误后,将错误信息与原始输入传递给LLM。
* LLM根据提示生成符合Pydantic模型的修正结果。
```python
from langchain.output_parsers import OutputFixingParser
from langchain_core.output_parsers import PydanticOutputParser
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from typing import List
class Actor(BaseModel):
name: str = Field(description="演员姓名")
film_names: List[str] = Field(description="参演电影列表")
parser = PydanticOutputParser(pydantic_object=Actor)
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 包装原始解析器
fixing_parser = OutputFixingParser.from_llm(parser=parser, llm=model)
# 模拟模型输出的错误格式(使用单引号)
misformatted_output = "{'name': '小滴课堂老王', 'film_names': ['A计划','架构大课','一路向西']}"
#在LLM 链中,chain.invoke会将 LLM 返回的文本字符串传入output_parser.invoke
#而`output_parser.invoke`最终会调用到`output_parser.parse`。
# try:
# parsed_data = parser.parse(misformatted_output) # 直接解析会失败
# except Exception as e:
# print(f"解析失败:{e}") # 抛出JSONDecodeError
# 使用OutputFixingParser修复并解析
fixed_data = fixing_parser.parse(misformatted_output)
print(type(fixed_data))
print(fixed_data.model_dump())
# 输出:{'name': '小滴课堂老王', 'film_names': ['A计划','架构大课','一路向西']}
```
* 完整正常案例
```python
from langchain.output_parsers import OutputFixingParser
from langchain_core.output_parsers import PydanticOutputParser
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from langchain_core.prompts import PromptTemplate
from typing import List
class Actor(BaseModel):
name: str = Field(description="演员姓名")
film_names: List[str] = Field(description="参演电影列表")
parser = PydanticOutputParser(pydantic_object=Actor)
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
prompt = PromptTemplate(
template="{format_instructions}\n{query}",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# 包装原始解析器
fixing_parser = OutputFixingParser.from_llm(parser=parser, llm=model)
chain = prompt | model | fixing_parser
response = chain.invoke({"query": "说下成龙出演过的5部动作电影? "})
print(response)
print(type(response))
print(response.model_dump())
```
* 常见问题与解决方案
* 修复失败的可能原因
* 模型能力不足:升级LLM版本(如使用更高级的模型和参数量)。
* 提示词不清晰:在提示模板中明确格式要求。
* 网络问题:通过代理服务优化API访问
### AI大模型必备之RAG和智能医生实战
#### 什么是大模型的幻觉输出
* “幻觉输出”(Hallucination)
* 是大语言模型(如GPT、Llama、DeepSeek等)生成内容时的一种常见问题
* 指模型输出看似合理但实际错误、虚构或脱离事实的信息。
* 这种现象类似于人类的“臆想”——模型基于不完整或错误的知识,生成逻辑通顺但内容失实的回答
* 表现形式
* 虚构事实
* 例1:生成不存在的书籍(如称《时间简史》是鲁迅所写)。
* 例2:编造错误的历史事件(如“秦始皇于公元前200年统一六国”)。
* 错误推理
* 例:回答数学问题时,步骤正确但结果错误(如“2+3=6”)。
* 过度泛化
* 例:将特定领域的知识错误迁移到其他领域(如用医学术语解释物理现象)。
* 矛盾内容
* 例:同一段回答中前后逻辑冲突(如先说“地球是平的”,后又说“地球绕太阳公转”)
* 幻觉产生的根本原因
* **训练数据的局限性**
- **数据噪声**:模型训练数据可能包含错误、过时或偏见信息(如互联网上的谣言)。
- **知识截止**:模型训练后无法获取新知识(如GPT-3的数据截止到2021年)。
* **模型生成机制**
- **概率驱动**:模型通过预测“最可能的下一词”生成文本,而非验证事实。
- **缺乏常识判断**:无法区分“合理表达”与“真实事实”。
* **模型策略的副作用**
- **创造性模式**:模型在开放生成任务中更易“放飞自我”(如写小说时虚构细节)
* 典型案例分析
- **案例1:医疗问答**
- **问题**:用户问“新冠疫苗会导致自闭症吗?”
- **幻觉输出**:模型可能生成“有研究表明两者存在相关性”(错误)。
- **解决方案**:RAG检索WHO官方声明,生成“无科学证据支持此说法”。
- **案例2:金融咨询**
- **问题**:“2024年比特币会涨到10万美元吗?”
- **幻觉输出**:模型虚构专家预测或历史数据。
- **解决方案**:限定回答范围(如“截至2023年,比特币最高价格为…”)
* 产生的影响
* **误导用户**:在医疗、法律等专业领域可能引发严重后果。
* **信任危机**:用户对模型输出的可靠性产生质疑。
* **技术瓶颈**:暴露大模型在事实性、可解释性上的不足。
* 如何缓解幻觉输出(注意:不是解决)
* **技术改进方案**
- **检索增强生成(RAG)**:通过实时检索外部知识库(如维基百科、专业数据库),为生成提供事实依据。
- **微调对齐**:用高质量数据(如标注正确的问答对)调整模型输出偏好。
- **强化学习(RLHF)**:通过人类反馈惩罚错误生成,奖励准确回答。
* **生成策略优化**
- **温度参数调整**:降低随机性(`temperature=0`),减少“胡编乱造”。
- **后处理校验**:添加事实核查模块(如调用知识图谱API验证答案)。
* **用户侧应对**
- **提示词设计**:明确要求模型标注不确定性(如“回答需基于2023年数据”)。
- **多源验证**:对关键信息人工交叉核对(如学术论文、权威网站)。
#### 带你走进RAG检索增强生成和应用场景
**简介: 带你走进RAG检索增强生成和应用场景**
* 什么是RAG技术
* RAG(Retrieval-Augmented Generation)检索增强生成,是结合信息检索与文本生成的AI技术架构。
* 核心思想:
* 先通过检索系统找到与问题相关的知识片段
* 再将检索结果与问题共同输入生成模型得到最终答案
* 类比人类解答问题的过程:遇到问题时先查资料(检索),再结合资料组织回答(生成)
* 用Java伪代码描述RAG工作流程:
```java
public class JavaRAG {
public static void main(String[] args) {
// 1. 加载文档
List
* 核心语法与使用步骤
* 基础语法
```python
from langchain.output_parsers import OutputFixingParser, PydanticOutputParser
from langchain_openai import ChatOpenAI
# 步骤1:定义Pydantic数据模型
class MyModel(BaseModel):
field1: str = Field(description="字段描述")
field2: int
# 步骤2:创建原始解析器
parser = PydanticOutputParser(pydantic_object=MyModel)
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 步骤3:包装为OutputFixingParser
fixing_parser = OutputFixingParser.from_llm(parser=parser, llm=model)
```
* 参数说明:
* parser: 原始解析器对象(如PydanticOutputParser)。
* llm: 用于修复错误的语言模型实例。
* max_retries(可选): 最大重试次数(默认1)
* 案例实战
* 修复机制
* 检测到错误后,将错误信息与原始输入传递给LLM。
* LLM根据提示生成符合Pydantic模型的修正结果。
```python
from langchain.output_parsers import OutputFixingParser
from langchain_core.output_parsers import PydanticOutputParser
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from typing import List
class Actor(BaseModel):
name: str = Field(description="演员姓名")
film_names: List[str] = Field(description="参演电影列表")
parser = PydanticOutputParser(pydantic_object=Actor)
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 包装原始解析器
fixing_parser = OutputFixingParser.from_llm(parser=parser, llm=model)
# 模拟模型输出的错误格式(使用单引号)
misformatted_output = "{'name': '小滴课堂老王', 'film_names': ['A计划','架构大课','一路向西']}"
#在LLM 链中,chain.invoke会将 LLM 返回的文本字符串传入output_parser.invoke
#而`output_parser.invoke`最终会调用到`output_parser.parse`。
# try:
# parsed_data = parser.parse(misformatted_output) # 直接解析会失败
# except Exception as e:
# print(f"解析失败:{e}") # 抛出JSONDecodeError
# 使用OutputFixingParser修复并解析
fixed_data = fixing_parser.parse(misformatted_output)
print(type(fixed_data))
print(fixed_data.model_dump())
# 输出:{'name': '小滴课堂老王', 'film_names': ['A计划','架构大课','一路向西']}
```
* 完整正常案例
```python
from langchain.output_parsers import OutputFixingParser
from langchain_core.output_parsers import PydanticOutputParser
from langchain_openai import ChatOpenAI
from pydantic import BaseModel, Field
from langchain_core.prompts import PromptTemplate
from typing import List
class Actor(BaseModel):
name: str = Field(description="演员姓名")
film_names: List[str] = Field(description="参演电影列表")
parser = PydanticOutputParser(pydantic_object=Actor)
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
prompt = PromptTemplate(
template="{format_instructions}\n{query}",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# 包装原始解析器
fixing_parser = OutputFixingParser.from_llm(parser=parser, llm=model)
chain = prompt | model | fixing_parser
response = chain.invoke({"query": "说下成龙出演过的5部动作电影? "})
print(response)
print(type(response))
print(response.model_dump())
```
* 常见问题与解决方案
* 修复失败的可能原因
* 模型能力不足:升级LLM版本(如使用更高级的模型和参数量)。
* 提示词不清晰:在提示模板中明确格式要求。
* 网络问题:通过代理服务优化API访问
### AI大模型必备之RAG和智能医生实战
#### 什么是大模型的幻觉输出
* “幻觉输出”(Hallucination)
* 是大语言模型(如GPT、Llama、DeepSeek等)生成内容时的一种常见问题
* 指模型输出看似合理但实际错误、虚构或脱离事实的信息。
* 这种现象类似于人类的“臆想”——模型基于不完整或错误的知识,生成逻辑通顺但内容失实的回答
* 表现形式
* 虚构事实
* 例1:生成不存在的书籍(如称《时间简史》是鲁迅所写)。
* 例2:编造错误的历史事件(如“秦始皇于公元前200年统一六国”)。
* 错误推理
* 例:回答数学问题时,步骤正确但结果错误(如“2+3=6”)。
* 过度泛化
* 例:将特定领域的知识错误迁移到其他领域(如用医学术语解释物理现象)。
* 矛盾内容
* 例:同一段回答中前后逻辑冲突(如先说“地球是平的”,后又说“地球绕太阳公转”)
* 幻觉产生的根本原因
* **训练数据的局限性**
- **数据噪声**:模型训练数据可能包含错误、过时或偏见信息(如互联网上的谣言)。
- **知识截止**:模型训练后无法获取新知识(如GPT-3的数据截止到2021年)。
* **模型生成机制**
- **概率驱动**:模型通过预测“最可能的下一词”生成文本,而非验证事实。
- **缺乏常识判断**:无法区分“合理表达”与“真实事实”。
* **模型策略的副作用**
- **创造性模式**:模型在开放生成任务中更易“放飞自我”(如写小说时虚构细节)
* 典型案例分析
- **案例1:医疗问答**
- **问题**:用户问“新冠疫苗会导致自闭症吗?”
- **幻觉输出**:模型可能生成“有研究表明两者存在相关性”(错误)。
- **解决方案**:RAG检索WHO官方声明,生成“无科学证据支持此说法”。
- **案例2:金融咨询**
- **问题**:“2024年比特币会涨到10万美元吗?”
- **幻觉输出**:模型虚构专家预测或历史数据。
- **解决方案**:限定回答范围(如“截至2023年,比特币最高价格为…”)
* 产生的影响
* **误导用户**:在医疗、法律等专业领域可能引发严重后果。
* **信任危机**:用户对模型输出的可靠性产生质疑。
* **技术瓶颈**:暴露大模型在事实性、可解释性上的不足。
* 如何缓解幻觉输出(注意:不是解决)
* **技术改进方案**
- **检索增强生成(RAG)**:通过实时检索外部知识库(如维基百科、专业数据库),为生成提供事实依据。
- **微调对齐**:用高质量数据(如标注正确的问答对)调整模型输出偏好。
- **强化学习(RLHF)**:通过人类反馈惩罚错误生成,奖励准确回答。
* **生成策略优化**
- **温度参数调整**:降低随机性(`temperature=0`),减少“胡编乱造”。
- **后处理校验**:添加事实核查模块(如调用知识图谱API验证答案)。
* **用户侧应对**
- **提示词设计**:明确要求模型标注不确定性(如“回答需基于2023年数据”)。
- **多源验证**:对关键信息人工交叉核对(如学术论文、权威网站)。
#### 带你走进RAG检索增强生成和应用场景
**简介: 带你走进RAG检索增强生成和应用场景**
* 什么是RAG技术
* RAG(Retrieval-Augmented Generation)检索增强生成,是结合信息检索与文本生成的AI技术架构。
* 核心思想:
* 先通过检索系统找到与问题相关的知识片段
* 再将检索结果与问题共同输入生成模型得到最终答案
* 类比人类解答问题的过程:遇到问题时先查资料(检索),再结合资料组织回答(生成)

* 用Java伪代码描述RAG工作流程:
```java
public class JavaRAG {
public static void main(String[] args) {
// 1. 加载文档
List * **涉及的技术链路环节: 文档加载器->文档转换器->文本嵌入模型->向量存储->检索器**
* 关键技术组件
| 组件 | 常用工具 | Java类比 |
| :--------: | :-----------------------: | :------------------: |
| 文档加载器 | PyPDFLoader, Unstructured | FileInputStream |
| 文本分块器 | RecursiveTextSplitter | String.split()增强版 |
| 元数据处理 | LangChain Document类 | DTO对象封装 |
| 向量存储 | FAISS, Pinecone | 数据库索引 |
* 典型应用场景
* 案例1:智能客服系统
* 传统问题:客服知识库更新频繁,模型无法实时同步。
* RAG方案:
* 实时检索最新的产品文档、FAQ。
* 生成个性化回答(如退货政策、故障排查)。
```python
用户问:"这个小滴手机支持老人家使用不?"
系统检索:产品适合人群相关词条
生成回答:"我们这个产品适合18岁以上的成人使用,包括中老年人等"
```
* 效果:减少人工干预,回答准确率提升30%+。
* 案例2:医疗问答助手
* 传统问题:通用模型缺乏专业医学知识,可能给出危险建议。
* RAG方案:
* 检索权威医学数据库(如PubMed、临床指南)。
* 生成基于循证医学的答案,标注参考文献来源。
```python
用户问:"二甲双胍的禁忌症有哪些?"
系统检索:最新《临床用药指南》第5.3节
生成回答:"根据2023版用药指南,二甲双胍禁用于以下情况:1)严重肾功能不全..."
```
* 效果:合规性提升,避免法律风险。
* 案例3:金融研究报告生成
* 传统问题:市场数据动态变化,模型无法实时分析。
* RAG方案:
* 检索实时财报、新闻、行业数据 → 输入生成模型。
* 自动生成带有数据支撑的投资建议。
```python
用户问:"XXX公司财报如何"
系统检索:某某公司财报
生成回答:"根据公司的财报和解读,利润和负债..."
```
* 效果:析师效率提升,报告更新频率加快
#### LLM智能AI医生+RAG系统案例实战
* 需求
* 快速搭建智能医生客服案例,基于LLM大模型+RAG技术
* 方便大家可以直观的看相关效果,并方便后续拆解每个步骤
* 效果:可以根据用户的提问,检索相关私有数据,整合大模型,最终生成返回给用户
* 案例实战【本集不提供课程代码,请从下面地址下载】
* 创建项目和安装相关环境
```python
# 创建并激活虚拟环境
python -m venv .venv
source .venv/bin/activate
# 安装依赖
pip install -r requirements.txt
```
* 查看训练的文档数据
* 项目部署运行 (**版本和课程保持一致,不然很多不兼容!!!**)
* 下载相关资料 ,使用**【wget】或者【浏览器】远程下载相关依赖包(需要替换群里最新的)**
```python
原生资料下载方式(账号 - 密码 - ip地址 - 端口 需要替换群里最新的,【其他路径不变】)
wget --http-user=用户名 --http-password=密码 http://ip:端口/dcloud_pan/aipan_xd-rag.zip
#比如 命令行下
wget --http-user=admin --http-password=xdclass.net888 http://47.115.31.28:9088/dcloud_pan/aipan_xd-rag.zip
# 比如 浏览器直接访问
http://47.115.31.28:9088/dcloud_pan/aipan_xd-rag.zip
```
* 解压后执行【**依赖很多,版本差异大,务必按照下面执行,否则课程无法进行下去,加我微信 xdclass6**】
```
# 安装依赖
pip install -r requirements.txt
```
* 效果测试
* 多数同学的问题
* **为啥可以根据我们的提问,进行检索到对应的词条?而且还可以正确检索?**
* **为啥要加载文件?然后切割?什么是向量数据库?**
* **为啥检索到词条后,还可以用调整输出内容,更加友好?**
* **什么是嵌入大模型?和前面学的LLM大模型有啥区别?**
### RAG 检索增强生成之Loader实战
#### RAG系统链路和数据加载Loaders技术
* RAG系统与LLM交互架构图
* 注意
* 万丈高楼平地起,基础需要打牢固,一步步进行,然后学会举一反三使用
* 如果直接讲Agent智能体项目,那项目涉及到的很多技术就懵逼了,要学会思路

* **涉及的技术链路环节: 文档加载器->文档转换器->文本嵌入模型->向量存储->检索器**
* RAG数据流水线示意图
```
原始数据 → 数据加载 → 预处理 → 向量化 → 存储 → 检索增强生成
↗ ↗ ↗
PDF 文本清洗 嵌入模型
数据库 分块
网页
```
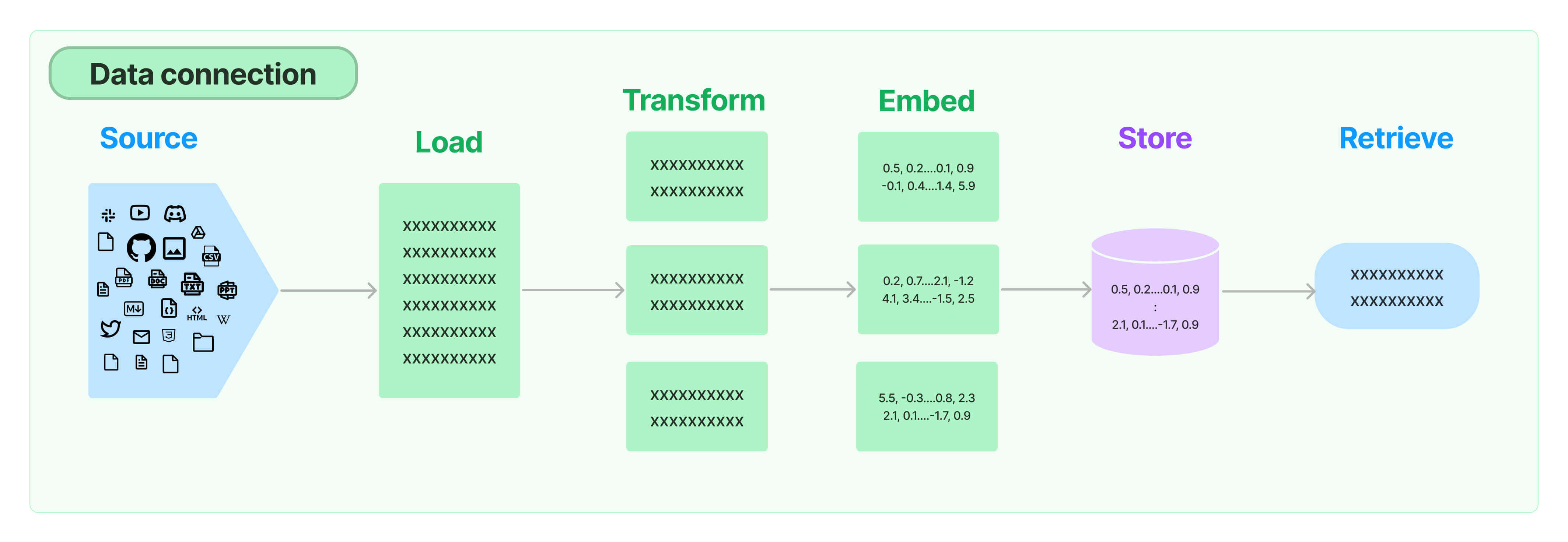
* 文档加载器 (Document Loaders)
* 外部数据多样性,包括在线,本地 或者数据库等来源
* 将不同来源的原始数据(如PDF、网页、JSON、、HTML、数据库等)转换为统一格式的文档对象,便于后续处理。
* **核心任务**:数据源适配与初步结构化
* LangChain里面的Loader
* 接口文档地址【如果失效就忽略):https://python.langchain.com/docs/integrations/document_loaders/
```
from langchain_community.document_loaders import (
TextLoader, #文本加载
PyPDFLoader, # PDF
Docx2txtLoader, # Word
UnstructuredHTMLLoader, # HTML
CSVLoader, # CSV
JSONLoader, # JSON
SeleniumURLLoader, # 动态网页
WebBaseLoader #网页加载
)
```
* LangChain 设计了一个统一的接口`BaseLoader`来加载和解析文档,
```python
class BaseLoader(ABC): # noqa: B024
"""Interface for Document Loader.
Implementations should implement the lazy-loading method using generators
to avoid loading all Documents into memory at once.
`load` is provided just for user convenience and should not be overridden.
"""
# Sub-classes should not implement this method directly. Instead, they
# should implement the lazy load method.
def load(self) -> list[Document]:
"""Load data into Document objects."""
return list(self.lazy_load())
```
* 将原始数据(如文件、API 响应、文本文件、网页、数据库等)转换为 LangChain 的 `Document` 对象
* `load`方法返回一个`Document`数组, 每个 `Document` 包含
* **`page_content`**: 文本内容
* **`metadata`**: 元数据(如来源、创建时间、作者等)
```python
class Document(BaseMedia):
"""Class for storing a piece of text and associated metadata.
Example:
.. code-block:: python
from langchain_core.documents import Document
document = Document(
page_content="Hello, world!",
metadata={"source": "https://example.com"}
)
"""
page_content: str
"""String text."""
type: Literal["Document"] = "Document"
```
* Loader 的分类与常见类型
* 文件加载器(File Loaders)
| Loader 类型 | 功能描述 |
| :----------------------: | :----------------------------------: |
| `TextLoader` | 加载纯文本文件(.txt) |
| `CSVLoader` | 解析 CSV 文件,按行生成 Document |
| `PyPDFLoader` | 提取 PDF 文本及元数据(基于 PyPDF2) |
| `Docx2txtLoader` | 读取 Word 文档(.docx) |
| `UnstructuredFileLoader` | 通用文件解析(支持多种格式) |
* 网页加载器(Web Loaders)
| Loader 类型 | 功能描述 |
| :--------------: | :----------------------------: |
| `WebBaseLoader` | 抓取网页文本内容 |
| `SeleniumLoader` | 处理需要 JavaScript 渲染的页面 |
* 数据库加载器(Database Loaders)
| Loader 类型 | 功能描述 |
| :-----------------: | :---------------------: |
| `SQLDatabaseLoader` | 执行 SQL 查询并加载结果 |
| `MongoDBLoader` | 从 MongoDB 中读取数据 |
* 其他加载器 (自定义) ...
#### 文档加载器Loaders技术多案例实战
* TextLoader - 加载纯文本文件
* ##### **通用参数**
- **`encoding`**: 文件编码(默认 `utf-8`)
- **`autodetect_encoding`**: 自动检测编码(如处理中文乱码)
```python
from langchain_community.document_loaders import TextLoader
# 文本加载
loader = TextLoader("data/test.txt")
documents = loader.load()
print(documents)
print(len(documents)) #长度
print(documents[0].page_content[:100]) # 打印前100个字符
print(documents[0].metadata) # 输出: {'source': 'data/test.txt'}
```
* CSVLoader - 加载 CSV 文件
* 基础案例代码
```python
from langchain_community.document_loaders import CSVLoader
loader = CSVLoader("data/test.csv", csv_args={"delimiter": ","})
documents = loader.load()
# 每行转换为一个 Document,metadata 包含行号
print(len(documents))
print(documents[0].metadata) # 输出: {'source': 'data.csv', 'row': 0}
print(documents[0].page_content)
```
* 可指定列名,按行生成文档
```python
from langchain_community.document_loaders import CSVLoader
#loader = CSVLoader("data/test.csv", csv_args={"delimiter": ","})
loader = CSVLoader("data/test.csv", csv_args={"fieldnames": ["产品名称", "销售数量", "客户名称"]})
documents = loader.load()
# 每行转换为一个 Document,metadata 包含行号
print(len(documents))
print(documents[1].metadata) # 输出: {'source': 'data.csv', 'row': 0}
print(documents[1].page_content)
```
* JSONLoader - 加载 JSON 文件
* 核心参数详解
| 参数 | 类型 | 必填 | 说明 |
| :-------------- | :------- | :--- | :----------------------------------------------- |
| `file_path` | str | ✅ | JSON 文件路径 |
| `jq_schema` | str | ✅ | jq 查询语法,定义数据提取逻辑 |
| `content_key` | str | ❌ | 指定作为文本内容的字段(默认直接使用提取到的值) |
| `metadata_func` | Callable | ❌ | 自定义元数据处理函数 |
| `text_content` | bool | ❌ | 是否将提取内容强制转为字符串(默认 True) |
* 必选参数 `jq_schema`
* 必须使用 `jq_schema` 语法指定数据提取路径
* 支持更复杂的 JSON 结构解析
* jq 语法常用模式
| 场景 | jq_schema 示例 | 说明 |
| :----------- | :----------------------------------- | :--------------------------- |
| 提取根级数组 | `.[]` | 适用于 JSON 文件本身是数组 |
| 嵌套对象提取 | `.data.posts[].content` | 提取 data.posts 下的 content |
| 条件过滤 | `.users[] | select(.age > 18)` | 筛选年龄大于18的用户 |
| 多字段合并 | `{name: .username, email: .contact}` | 组合多个字段为对象 |
* 案例实战
* 安装依赖包
```
pip install jq
```
* 编码实战
```python
from langchain_community.document_loaders import JSONLoader
loader = JSONLoader(
file_path="data/test.json",
jq_schema=".articles[]", # 提取 articles 数组中的每个元素
content_key="content" # 指定 content 字段作为文本内容
)
docs = loader.load()
print(len(docs))
print(docs[0]
```
#### PDF文档加载器实战和常见问题处理
* `PyPDFLoader` 加载PDF文件
* `PyPDFLoader` 是 LangChain 中专门用于加载和解析 **PDF 文件** 的文档加载器。
* 它能将 PDF 按页拆分为多个 `Document` 对象,每个对象包含页面文本和元数据(如页码、来源路径等)。
* 适用于处理多页PDF文档的文本提取任务。
* 使用步骤
* 安装依赖库
```python
pip install pypdf
```
* 案例代码实战
```python
from langchain_community.document_loaders import PyPDFLoader
# PDF加载
loader = PyPDFLoader("data/test.pdf")
# 加载文档并按页分割
pages = loader.load() # 返回 Document 对象列表
# 查看页数
print(f"总页数: {len(pages)}")
# 访问第一页内容
page_content = pages[0].page_content
metadata = pages[0].metadata
print(f"第一页内容:\n{page_content[:200]}...") # 预览前200字符
print(f"元数据: {metadata}")
```
* 按需加载, 通过 `load()` 方法的参数控制加载范围:
```python
# 加载指定页码范围(例如第2页到第4页)
pages = loader.load([1, 2, 3]) # 注意页码从0开始(第1页对应索引0)
```
* 提取所有文本合并为单个文档, 若需将全部页面内容合并为一个字符串:
```python
full_text = "\n\n".join([page.page_content for page in pages])
print(f"合并后的全文长度: {len(full_text)} 字符")
```
* 常见问题与解决方案
* PDF无法加载或内容为空
* 原因:PDF为扫描版图片或加密。
* 解决:
* 使用OCR工具(如pytesseract+pdf2image)提取图片文本。
* 解密PDF后加载(需密码时,PyPDFLoader暂不支持直接解密)
* 文本分块不理想
* 调整分块策略:选择合适的分隔符或分块大小
```python
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "."], # 按段落、句子分割
chunk_size=500,
chunk_overlap=100
)
```
* 高级技巧
* **批量处理PDF**:遍历文件夹内所有PDF文件。
```python
import os
pdf_folder = "docs/"
all_pages = []
for filename in os.listdir(pdf_folder):
if filename.endswith(".pdf"):
loader = PyPDFLoader(os.path.join(pdf_folder, filename))
all_pages.extend(loader.load())
```
#### Loader进阶-PDF文档里面的图片提取解析
* 如何提取PDF里面的图片文案?
* `PyPDFLoader` 仅提取文本,如果没配置第三方类库则会提取不了对应的图片文案
* 需结合其他库(如`camelot`、`pdfplumber`、`rapidocr-onnxruntime`)提取表格或图像。
* 如果需要提取,安装好依赖库后,设置`extract_images`参数为`True`。
* `RapidOCR-ONNXRuntime `介绍
* 是一个基于 ONNX Runtime 推理引擎的轻量级 OCR(光学字符识别)工具库,专注于高效、跨平台部署。
* 它是 [RapidOCR](https://github.com/RapidAI/RapidOCR) 项目的一个分支,实现了更高的推理速度和更低的资源占用
* 特点:
* 跨平台支持:支持 Windows、Linux、macOS,以及移动端(Android/iOS)和嵌入式设备。
* 多语言识别:支持中文、英文、日文、韩文等多种语言,尤其擅长中英混合文本。
* 轻量级:模型体积小(约几 MB),适合资源受限的环境。
* 预处理与后处理集成:内置图像预处理(如二值化、方向校正)和文本后处理(如去除冗余字符)。
* RapidOCR-ONNXRuntime 与其他主流 OCR 工具的对比:
| 工具 | 引擎 | 速度 | 准确率 | 语言支持 | 依赖项 | 适用场景 |
| :----------------------- | :----------- | :--- | :----- | :------- | :----- | :--------------------- |
| **RapidOCR-ONNXRuntime** | ONNX Runtime | ⭐⭐⭐⭐ | ⭐⭐⭐ | 多语言 | 少 | 跨平台、轻量级部署 |
| **Tesseract** | 自研引擎 | ⭐⭐ | ⭐⭐ | 多语言 | 多 | 历史项目、简单场景 |
| **EasyOCR** | PyTorch | ⭐⭐ | ⭐⭐⭐ | 多语言 | 多 | 快速原型开发 |
| **Microsoft Read API** | 云端服务 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 多语言 | 无 | 企业级、高并发云端需求 |
* 案例实战
* 安装依赖包 (**耗时会有点久**)
```
pip install rapidocr-onnxruntime
```
* 代码实战
```python
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("data/pdf-img.pdf", extract_images=True)
pages = loader.load()
print(pages[0].page_content)
```
#### 网页加载器WebBaseLoader案例实战
**简介: Web网页加载器WebBaseLoader案例实战**
* 什么是WebBaseLoader
* `WebBaseLoader` 是 LangChain 中用于抓取 **静态网页内容** 的文档加载器。
* 通过 HTTP 请求直接获取网页 HTML,并提取其中的文本内容(自动清理标签、脚本等非文本元素)
* 生成包含网页文本和元数据的 `Document` 对象
* 适用于新闻文章、博客、文档页面等静态内容的快速提取。
* 场景
* 知识库构建(知识问答、企业知识库)、舆情监控(新闻/社交媒体分析)
* 竞品分析(产品功能/价格监控)、SEO 内容聚合
* 使用步骤
* 安装依赖库
```python
pip install beautifulsoup4 # HTML 解析依赖(默认已包含)
pip install requests # 网络请求依赖(默认已包含)
```
* 目标网页要求
* 无需 JavaScript 渲染(动态内容需改用 `SeleniumURLLoader` ,但是很鸡肋,少用)
* 未被反爬虫机制拦截(如需要,需配置代理或请求头)
* 如果动态网页,且内容提取好,还是需要单独针对不同的网站写代码进行提取内容
* 案例实战
* 基础用法:加载单个网页
```python
import os
#代码中设置USER_AGENT, 设置USER_AGENT的代码一定要放在WebBaseLoader 这个包前面,不然还是会报错
os.environ['USER_AGENT'] = 'Mozilla/5.0 (Windows NT 14.0; Win64; x64) AppleWebKit/567.36 (KHTML, like Gecko) Chrome/58.0.444.11 Safari/337.3'
from langchain_community.document_loaders import WebBaseLoader
#警告日志信息:USER_AGENT environment variable not set, consider setting it to identify your requests.
# 初始化加载器,传入目标URL列表(可多个)
urls = ["https://www.cnblogs.com"]
loader = WebBaseLoader(urls)
# 加载文档(返回Document对象列表)
docs = loader.load()
# 查看结果
print(f"提取的文本长度: {len(docs[0].page_content)} 字符")
print(f"前200字符预览:\n{docs[0].page_content[:200]}...")
print(f"元数据: {docs[0].metadata}")
```
* 批量加载多个网页
```python
import os
#代码中设置USER_AGENT, 注意设置USER_AGENT的代码一定要放在WebBaseLoader 这个包前面,不然还是会报错
os.environ['USER_AGENT'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
from langchain_community.document_loaders import WebBaseLoader
#警告日志信息:USER_AGENT environment variable not set, consider setting it to identify your requests.
# 初始化加载器,传入目标URL列表(可多个)
urls = [
"https://news.baidu.com/", # 新闻
"https://tieba.baidu.com/index.html" # 贴吧
]
loader = WebBaseLoader(urls)
docs = loader.load()
print(f"共加载 {len(docs)} 个文档")
print("各文档来源:")
for doc in docs:
print(f"- {doc.metadata['source']}")
```
* 更多详细API和参数 https://python.langchain.com/docs/integrations/document_loaders/web_base/
#### Word文档加载器实战和常见问题处理
* `Docx2txtLoader`介绍
* 是 LangChain 中专门用于加载 **Microsoft Word 文档(.docx)** 的文档加载器。
* 提取文档中的纯文本内容(包括段落、列表、表格文字等),忽略复杂格式(如字体、颜色),生成统一的 `Document` 对象。
* 适用于从 Word 报告中快速提取结构化文本
* 使用步骤
* 安装依赖库
```python
pip install docx2txt # 核心文本提取库
```
* 准备.docx文件:确保目标文件为 .docx 格式(旧版 .doc 需转换),且未被加密
* 案例代码实战
* 基础用法:加载单个Word文档
```python
from langchain_community.document_loaders import Docx2txtLoader
# 初始化加载器,传入文件路径
loader = Docx2txtLoader("data/test1.docx")
# 加载文档(返回单个Document对象)
documents = loader.load()
# 查看内容
print(f"文本长度: {len(documents[0].page_content)} 字符")
print(f"前200字符预览:\n{documents[0].page_content[:200]}...")
print(f"元数据: {documents[0].metadata}")
```
* 批量加载文档
```python
from langchain_community.document_loaders import Docx2txtLoader
import os
folder_path = "data/"
all_docs = []
# 遍历文件夹内所有.docx文件
for filename in os.listdir(folder_path):
if filename.endswith(".docx"):
file_path = os.path.join(folder_path, filename)
loader = Docx2txtLoader(file_path)
all_docs.extend(loader.load()) # 合并所有文档
print(f"加载文件: {filename}")
print(all_docs)
```
* 常见问题与解决方案
* 加载 .doc 文件报错
* 原因:docx2txt 仅支持 .docx 格式。
* 解决:使用 Word 将 .doc 另存为 .docx。
* 文档中的图片/图表未被提取
* 原因:Docx2txtLoader 仅提取文本,忽略图片。
* 解决:使用 python-docx 单独提取图片,也可以使用其他组件,类似OCR
### RAG检索增强生成之文档切割
#### RAG系统链路构建之文档切割转换
* 构建RAG系统:**涉及的技术链路环节: 文档加载器->文档转换器->文本嵌入模型->向量存储->检索器**
* RAG数据流水线示意图
```python
原始数据 → 数据加载 → 预处理 → 向量化 → 存储 → 检索增强生成
↗ ↗ ↗
PDF 文本清洗 嵌入模型
数据库 分块
网页
```

* 需求背景,为啥要用?
* 模型输入限制:GPT-4最大上下文32k tokens,Claude 3最高200k
* 信息密度不均:关键信息可能分布在长文本的不同位置
* 格式兼容性问题:PDF/HTML/代码等不同格式的结构差异
* 文档转换器(Document Transformers)
* 文档转换器是 LangChain 处理文档流水线的核心组件,负责对原始文档进行结构化和语义化处理,
* 为后续的向量化存储、检索增强生成(RAG)等场景提供标准化输入。
* 核心任务:文本清洗、分块、元数据增强
* 关键操作
* **文本分块**:按固定长度或语义分割(防止截断完整句子)
* **去噪处理**:移除特殊字符、乱码、广告内容
* **元数据注入**:添加来源、时间戳等上下文信息
* 效果
* **保留语义完整性**:避免因分割导致上下文断裂或信息丢失
* **适配模型输入限制**:确保分割后的文本块长度符合大语言模型(LLM)的token限制
* **优化向量化效果**:通过合理分块提升向量表示的语义精度,从而提高检索匹配率
| 问题类型 | 原始文档示例 | 转换前问题 | 转换后效果 |
| :--------: | :-----------: | :-----------------------: | :--------------------: |
| 长文本溢出 | 500页法律合同 | 直接输入导致API报错 | 分割为上下文合规的段落 |
| 信息碎片化 | 产品手册PDF | 技术参数分散在不同页面 | 按功能模块重组内容 |
| 噪音污染 | 网页抓取内容 | 包含广告/导航栏等干扰信息 | 提取纯净正文内容 |
| 格式混乱 | 代码仓库文档 | Markdown/代码片段混合 | 分离代码与说明文本 |
* 基础类和核心参数说明
```python
from langchain_text_splitters import TextSplitter
#源码
class TextSplitter(BaseDocumentTransformer, ABC):
"""Interface for splitting text into chunks."""
def __init__(
self,
chunk_size: int = 4000,
chunk_overlap: int = 200,
length_function: Callable[[str], int] = len,
keep_separator: Union[bool, Literal["start", "end"]] = False,
add_start_index: bool = False,
strip_whitespace: bool = True,
) -> None:
```
* 方法说明
* `TextSplitter`本身没有实现`split_text`,要文档分割器按自己的分割策略实现分割
* 关键方法调用 `split_documents()->create_documents->()->split_text()`
* `split_text()`是基础文本分割方法
* `create_documents()`在`split_text()`基础上封装了元数据绑定逻辑
* `split_documents()`内部调用`create_documents()`并自动处理元数据传递
| 方法 | 输入类型 | 输出类型 | 元数据处理 | 典型使用场景 |
| :----------------------- | :------------------- | :--------------- | :------------------------- | :------------------------------------ |
| **`split_text()`** | **单个字符串** | `List[str]` | ❌ 不保留元数据 | 仅需分割纯文本内容时使用 |
| **`create_documents()`** | **字符串列表** | `List[Document]` | ✅ 需手动传递元数据 | 从原始文本构建带元数据的文档对象 |
| **`split_documents()`** | **Document对象列表** | `List[Document]` | ✅ 自动继承输入文档的元数据 | 分割已加载的文档对象(如PDF解析结果) |
* `chunk_size`
* 定义:每个文本块的最大长度(字符数或token数),用于控制分割后的文本块大小。
* 作用
* 防止文本过长超出模型处理限制,影响检索精度。
* 较小的chunk_size能提高检索细粒度,会导致上下文缺失。
* 例子
```python
# 设置chunk_size=100,分割文本为不超过100字符的块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
#输入文本:"Python是一种解释型语言,适合快速开发。它支持面向对象编程,语法简洁。"
#分割结果:["Python是一种解释型语言,适合快速开发。", "开发。它支持面向对象编程,语法简洁。"](假设每个块接近100字符)
```
* `chunk_overlap`
* 定义:相邻文本块之间的重叠字符数,用于保留上下文连贯性。
* 作用:避免因分割导致关键信息被切断(如句子中间被截断)
* 案例一
```python
如果chunk_size设为1024,chunk_overlap设为128, 对一个长度为2560的文本序列,会切分成3个chunk:
chunk 1: 第1-1024个token
chunk 2: 第897-1920个token (与chunk 1重叠128个)
chunk 3: 第1793-2560个token (与chunk 2重叠128个)
```
* 案例二
```python
# 设置chunk_size=50,chunk_overlap=10
text = "深度学习需要大量数据和计算资源。卷积神经网络(CNN)在图像处理中表现优异。"
text_splitter = CharacterTextSplitter(chunk_size=50, chunk_overlap=10)
#分割结果:["深度学习需要大量数据和计算资源。卷积神经", "计算资源。卷积神经网络(CNN)在图像处理中表现优异。"]
# 重叠部分"计算资源。"确保第二块包含前一块的结尾
```
* `separators`
* 定义:分隔符优先级列表,用于递归分割文本。
* 作用:优先按自然语义边界(如段落、句子)分割,减少语义断裂。
* 例子
```python
# 默认分隔符:["\n\n", "\n", " ", ""]
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "。", ",", " "]
)
#输入文本:"第一段\n\n第二段。第三段,第四段"
#分割流程:先按\n\n分割为两段,若仍超长则按。继续分割
```
#### 字符文档转换器TextSplitter案例实战
* `CharacterTextSplitter` 字符分割器
* 核心特点
* 是 LangChain 中最基础的文本分割器,采用**固定长度字符切割**策略。
* 适用于结构规整、格式统一的文本处理场景,强调**精确控制块长度**
* 适用于结构清晰的文本(如段落分隔明确的文档)。
* 核心参数详解
| 参数 | 类型 | 默认值 | 说明 |
| :------------------: | :--: | :------: | :----------------------: |
| `separator` | str | `"\n\n"` | 切割文本的分隔符 |
| `chunk_size` | int | `4000` | 每个块的最大字符数 |
| `chunk_overlap` | int | `200` | 相邻块的重叠字符数 |
| `strip_whitespace` | bool | `True` | 是否清除块首尾空格 |
| `is_separator_regex` | bool | `False` | 是否启用正则表达式分隔符 |
* 案例代码
* 长文本处理
```python
from langchain.text_splitter import CharacterTextSplitter
text = "是一段 需要被分割的 长文本示例....,每个文本块的最大长度(字符数或token数)Document loaders are designed to load document objects. LangChain has hundreds of integrations with various data sources to load data from: Slack, Notion, Google Drive"
splitter = CharacterTextSplitter(
separator=" ",
chunk_size=50,
chunk_overlap=10
)
chunks = splitter.split_text(text)
print(len(chunks))
for chunk in chunks:
print(chunk)
```
* 日志文件处理
```python
from langchain.text_splitter import CharacterTextSplitter
log_data = """
[ERROR] 2026-03-15 14:22:35 - Database connection failed
[INFO] 2026-03-15 14:23:10 - Retrying connection...
[WARNING] 2026-03-15 14:23:45 - High memory usage detected
"""
splitter = CharacterTextSplitter(
separator="\n",
chunk_size=60,
chunk_overlap=20
)
log_chunks = splitter.split_text(log_data)
for chunk in log_chunks:
print(chunk)
```
* 优缺点说明
| 特性 | 优势 | 局限性 |
| :--------: | :----------------------: | :----------------------------------------: |
| 分割速度 | ⚡️ 极快(O(n)复杂度) | 不考虑语义结构 |
| 内存消耗 | 🟢 极低 | 可能切断完整语义单元, 对语义关联性保持较弱 |
| 配置灵活性 | 🛠️ 支持自定义分隔符和重叠 | 需要预定义有效分隔符 |
| 多语言支持 | 🌍 支持任意字符集文本 | 对表意文字计算可能不准确 |
* 适合场景
* 推荐使用:
- 结构化日志处理
- 代码文件解析
- 已知明确分隔符的文本(如Markdown)
- 需要精确控制块大小的场景
* 不推荐使用:
- 自然语言段落(建议用RecursiveCharacterSplitter)
- 需要保持语义完整性的场景
- 包含复杂嵌套结构的文本
#### 递归字符文档转换器TextSplitter案例实战
* `RecursiveCharacterTextSplitter` 递归字符分割器
* 核心特点
* **递归字符分割器**采用**多级分隔符优先级切割**机制,是 LangChain 中使用最广泛的通用分割器。
* 递归尝试多种分隔符(默认顺序:`["\n\n", "\n", " ", ""]`),优先按大粒度分割
* 若块过大则继续尝试更细粒度分隔符,适合处理结构复杂或嵌套的文本。
* 核心参数说明
```python
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 目标块大小(字符)每个块最多包含 1000 个字符
chunk_overlap=200, # 块间重叠量,最多有200个字符重叠
separators=["\n\n", "\n", "。", "?", "!", " ", ""], # 优先级递减的分割符
length_function=len, # 长度计算函数
keep_separator=True, # 是否保留分隔符
)
```
* 案例实战
* 基础案例测试, 处理后chunk之间也有overlap
```python
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
#separators=["\n\n", "\n", " ", ""], #首先按段落分割,然后按行分割,最后按空格分割,如果都不行则按字符分割
chunk_size=20, #每个块的最大大小,不超过即可,如果超过则继续调用_split_text分隔(以字符数为单位)
chunk_overlap=4 #块与块之间的重叠部分的大小
)
text = "I Love English hello world, how about you? If you're looking to get started with chat models, vector stores, or other LangChain components from a specific provider, check out our supported integrations"
chunks = splitter.split_text(text)
print(len(chunks))
for chunk in chunks:
print(chunk)
```
* 学术论文处理
```python
from langchain.text_splitter import RecursiveCharacterTextSplitter
paper_text = """
引言机器学习近年来取得突破性进展...(长文本)若块过大则继续尝试更细粒度分隔符,适合处理结构复杂或嵌套的文本
方法我们提出新型网络架构...(技术细节)按优先级(如段落、句子、单词)递归分割文本,优先保留自然边界,如换行符、句号
实验在ImageNet数据集上...处理技术文档时,使用chunk_size=800和chunk_overlap=100,数据表格
"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=20,
chunk_overlap=4
)
paper_chunks = splitter.split_text(paper_text)
print(len(paper_chunks))
for chunk in paper_chunks:
print(chunk)
```
* 避坑指南
```python
# 错误示范:不合理的separators顺序
bad_splitter = RecursiveCharacterTextSplitter(
separators=[" ", "\n"], # 空格优先会导致过早分割
chunk_size=500
)
# 正确写法:从大结构到小结构
good_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "。", " ", ""]
)
```
* 核心优势对比
| 特性 | CharacterTextSplitter | RecursiveCharacterTextSplitter |
| :------------: | :-------------------: | :----------------------------: |
| 分隔符策略 | 单级固定分隔符 | 多级优先级递归分隔符 |
| 语义保持能力 | ★★☆☆☆ | ★★★★☆ |
| 复杂文本适应性 | 简单结构化文本 | 混合格式/长文本/多语言 |
| 典型应用场景 | 日志/CSV | 论文/邮件/网页/混合代码文 |
* 推荐场景
* 学术论文/技术文档解析
* 多语言混合内容处理
* 包含嵌套结构的文本(如Markdown)
* 需要保持段落完整性的问答系统
#### 分割器常见问题和优化最佳实践
* 其他常见分割器
* 递归字符分割(RecursiveCharacterTextSplitter)
* 原理:按优先级(如段落、句子、单词)递归分割文本,优先保留自然边界(如换行符、句号)
* 适用场景:通用文本处理,尤其适合逻辑紧密的长文档(如论文、技术手册)
* 固定大小分割(CharacterTextSplitter)
* 原理:按固定字符数分割,简单但可能打断句子结构。
* 优化:通过重叠(chunk_overlap)和智能截断(如优先在标点处分隔)减少语义断裂
* 适用场景:结构松散或句子独立性强的文本(如产品说明书)
* Token分割(TokenTextSplitter)
* 原理:基于LLM的token限制分割,避免超出模型输入长度。
* 优势:更贴近模型处理逻辑(如GPT系列)
* 结构化文档分割
* HTML/Markdown分割器:按标题层级分割,保留元数据(如`HTMLHeaderTextSplitter`)
* 适用场景:网页、技术文档等结构化内容
* 还有很多,可以查看官方文档拓展(如果不可访问,百度搜索)
* https://python.langchain.com/docs/how_to/
* 关键参数`chunk_size、chunk_overlap`
| 参数 | 作用 | 默认值 | 关键限制条件 |
| :------------------ | :----------------------------------------------------------- | :----- | :------------------------ |
| **`chunk_size`** | 定义每个文本块的最大长度(根据`length_function`计算,默认按字符数) | 1000 | 必须为正整数 |
| **`chunk_overlap`** | 定义相邻块之间的重叠长度 | 20 | 必须小于`chunk_size`的50% |
* 重叠内容未出现的常见原因
* 文本总长度不足:当输入文本长度 ≤ chunk_size时,不会触发分割。
```python
#解释:文本长度远小于chunk_size,不触发分割,无重叠。
from langchain_text_splitters import CharacterTextSplitter
text = "这是一个非常短的测试文本。"
text_splitter = CharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
separator="。", # 按句号分割
length_function=len
)
chunks = text_splitter.split_text(text)
print(chunks)
# 输出:['这是一个非常短的测试文本。']
```
* 递归分割策略:RecursiveCharacterTextSplitter优先保证块大小,可能牺牲重叠。
```python
# 解释:当无法找到分隔符时,按字符数硬分割,强制保留重叠。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text = "这是一段没有标点的超长文本需要被分割成多个块但是因为没有分隔符所以分割器会尝试按字符递归分割直到满足块大小要求"
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=30,
chunk_overlap=10,
separators=["", " "], # 无有效分隔符时按字符分割
length_function=len
)
chunks = text_splitter.split_text(text)
for i, chunk in enumerate(chunks):
print(f"块{i+1}(长度{len(chunk)}): {chunk}")
# 输出示例:
# 块1(长度30): 这是一段没有标点的超长文本需要被分割成多个块但是因为没有分隔
# 块2(长度30): 个块但是因为没有分隔符所以分割器会尝试按字符递归分割直到满足
# 块3(长度15): 字符递归分割直到满足块大小要求
# 重叠部分:"个块但是因为没有分隔"(10字符)
```
* `enumerate()`
* 函数是一个内置函数,用于在迭代过程中同时获取元素的索引和值。
* 它返回一个枚举对象,包含了索引和对应的元素
```python
# enumerate(iterable, start=0)
#参数:iterable:必需,一个可迭代对象,如列表、元组、字符串等。
#参数:start:可选,指定索引的起始值,默认为 0。
fruits = ['apple', 'banana', 'orange']
for index, fruit in enumerate(fruits):
print(index, fruit)
```
* 分隔符强制分割:在分隔符处切割时,剩余文本不足以形成重叠。
```python
#解释:分隔符优先切割,每个块正好为7个字符,无法形成重叠。
from langchain_text_splitters import CharacterTextSplitter
text = "abcdefg.hijkllm.nopqrst.uvwxyz"
text_splitter = CharacterTextSplitter(
chunk_size=7,
chunk_overlap=3,
separator=".", # 按句号分割
is_separator_regex=False
)
chunks = text_splitter.split_text(text)
print("分割块数:", len(chunks))
for i, chunk in enumerate(chunks):
print(f"块{i+1}: {chunk}")
```
* 参数调优最佳实践
* 通用文本处理
* 参数建议:`chunk_size=500-1000字符,chunk_overlap=10-20%`
* 案例:
* 处理技术文档时,使用`chunk_size=800和chunk_overlap=100`
* 确保每个块包含完整段落,同时通过重叠保留跨段落的关键术语
* 代码分割
* 参数建议:根据编程语言特性调整分隔符。
* 案例:
* 分割Python代码时,`RecursiveCharacterTextSplitter.from_language(Language.PYTHON)`
* 会自动识别函数、类等结构,避免打断代码逻辑
```python
from langchain_text_splitters import Language, RecursiveCharacterTextSplitter
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=200, chunk_overlap=50
)
```
* 结构化文档(如Markdown)
* 参数建议:结合标题层级分割。
* 案例:
* 使用MarkdownHeaderTextSplitter按标题分割,保留元数据
* 输入Markdown内容将按标题层级生成带元数据的块
```python
headers_to_split_on = [("#", "Header 1"), ("##", "Header 2")]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on)
```
* 常见问题与解决方案
* 过长导致语义模糊
* 表现:检索时匹配不精准。
* 解决:缩小chunk_size,增加chunk_overlap
* 块过短丢失上下文
* 表现:回答缺乏连贯性。
* 解决:合并相邻块或使用ParentDocumentRetriever,将细粒度块与父文档关联
* 参数选择原则:
* 密集文本(如论文):chunk_size较大(如1000),chunk_overlap约15%。
* 松散文本(如对话记录):chunk_size较小(如200),chunk_overlap约20%。
* **实验验证:通过AB测试对比不同参数的检索准确率与生成质量**
### 人工智能和高等数学核心基础扫盲
#### 扫盲-AI大模型必备之向量-张量和应用场景
* 什么是向量
* 向量就是一串有序的数字,像一条带方向的“箭头”, 在机器学习里面尤其重要
* **涉及的技术链路环节: 文档加载器->文档转换器->文本嵌入模型->向量存储->检索器**
* 关键技术组件
| 组件 | 常用工具 | Java类比 |
| :--------: | :-----------------------: | :------------------: |
| 文档加载器 | PyPDFLoader, Unstructured | FileInputStream |
| 文本分块器 | RecursiveTextSplitter | String.split()增强版 |
| 元数据处理 | LangChain Document类 | DTO对象封装 |
| 向量存储 | FAISS, Pinecone | 数据库索引 |
* 典型应用场景
* 案例1:智能客服系统
* 传统问题:客服知识库更新频繁,模型无法实时同步。
* RAG方案:
* 实时检索最新的产品文档、FAQ。
* 生成个性化回答(如退货政策、故障排查)。
```python
用户问:"这个小滴手机支持老人家使用不?"
系统检索:产品适合人群相关词条
生成回答:"我们这个产品适合18岁以上的成人使用,包括中老年人等"
```
* 效果:减少人工干预,回答准确率提升30%+。
* 案例2:医疗问答助手
* 传统问题:通用模型缺乏专业医学知识,可能给出危险建议。
* RAG方案:
* 检索权威医学数据库(如PubMed、临床指南)。
* 生成基于循证医学的答案,标注参考文献来源。
```python
用户问:"二甲双胍的禁忌症有哪些?"
系统检索:最新《临床用药指南》第5.3节
生成回答:"根据2023版用药指南,二甲双胍禁用于以下情况:1)严重肾功能不全..."
```
* 效果:合规性提升,避免法律风险。
* 案例3:金融研究报告生成
* 传统问题:市场数据动态变化,模型无法实时分析。
* RAG方案:
* 检索实时财报、新闻、行业数据 → 输入生成模型。
* 自动生成带有数据支撑的投资建议。
```python
用户问:"XXX公司财报如何"
系统检索:某某公司财报
生成回答:"根据公司的财报和解读,利润和负债..."
```
* 效果:析师效率提升,报告更新频率加快
#### LLM智能AI医生+RAG系统案例实战
* 需求
* 快速搭建智能医生客服案例,基于LLM大模型+RAG技术
* 方便大家可以直观的看相关效果,并方便后续拆解每个步骤
* 效果:可以根据用户的提问,检索相关私有数据,整合大模型,最终生成返回给用户
* 案例实战【本集不提供课程代码,请从下面地址下载】
* 创建项目和安装相关环境
```python
# 创建并激活虚拟环境
python -m venv .venv
source .venv/bin/activate
# 安装依赖
pip install -r requirements.txt
```
* 查看训练的文档数据
* 项目部署运行 (**版本和课程保持一致,不然很多不兼容!!!**)
* 下载相关资料 ,使用**【wget】或者【浏览器】远程下载相关依赖包(需要替换群里最新的)**
```python
原生资料下载方式(账号 - 密码 - ip地址 - 端口 需要替换群里最新的,【其他路径不变】)
wget --http-user=用户名 --http-password=密码 http://ip:端口/dcloud_pan/aipan_xd-rag.zip
#比如 命令行下
wget --http-user=admin --http-password=xdclass.net888 http://47.115.31.28:9088/dcloud_pan/aipan_xd-rag.zip
# 比如 浏览器直接访问
http://47.115.31.28:9088/dcloud_pan/aipan_xd-rag.zip
```
* 解压后执行【**依赖很多,版本差异大,务必按照下面执行,否则课程无法进行下去,加我微信 xdclass6**】
```
# 安装依赖
pip install -r requirements.txt
```
* 效果测试

* 多数同学的问题
* **为啥可以根据我们的提问,进行检索到对应的词条?而且还可以正确检索?**
* **为啥要加载文件?然后切割?什么是向量数据库?**
* **为啥检索到词条后,还可以用调整输出内容,更加友好?**
* **什么是嵌入大模型?和前面学的LLM大模型有啥区别?**
### RAG 检索增强生成之Loader实战
#### RAG系统链路和数据加载Loaders技术
* RAG系统与LLM交互架构图
* 注意
* 万丈高楼平地起,基础需要打牢固,一步步进行,然后学会举一反三使用
* 如果直接讲Agent智能体项目,那项目涉及到的很多技术就懵逼了,要学会思路

* **涉及的技术链路环节: 文档加载器->文档转换器->文本嵌入模型->向量存储->检索器**
* RAG数据流水线示意图
```
原始数据 → 数据加载 → 预处理 → 向量化 → 存储 → 检索增强生成
↗ ↗ ↗
PDF 文本清洗 嵌入模型
数据库 分块
网页
```

* 文档加载器 (Document Loaders)
* 外部数据多样性,包括在线,本地 或者数据库等来源
* 将不同来源的原始数据(如PDF、网页、JSON、、HTML、数据库等)转换为统一格式的文档对象,便于后续处理。
* **核心任务**:数据源适配与初步结构化
* LangChain里面的Loader
* 接口文档地址【如果失效就忽略):https://python.langchain.com/docs/integrations/document_loaders/
```
from langchain_community.document_loaders import (
TextLoader, #文本加载
PyPDFLoader, # PDF
Docx2txtLoader, # Word
UnstructuredHTMLLoader, # HTML
CSVLoader, # CSV
JSONLoader, # JSON
SeleniumURLLoader, # 动态网页
WebBaseLoader #网页加载
)
```
* LangChain 设计了一个统一的接口`BaseLoader`来加载和解析文档,
```python
class BaseLoader(ABC): # noqa: B024
"""Interface for Document Loader.
Implementations should implement the lazy-loading method using generators
to avoid loading all Documents into memory at once.
`load` is provided just for user convenience and should not be overridden.
"""
# Sub-classes should not implement this method directly. Instead, they
# should implement the lazy load method.
def load(self) -> list[Document]:
"""Load data into Document objects."""
return list(self.lazy_load())
```
* 将原始数据(如文件、API 响应、文本文件、网页、数据库等)转换为 LangChain 的 `Document` 对象
* `load`方法返回一个`Document`数组, 每个 `Document` 包含
* **`page_content`**: 文本内容
* **`metadata`**: 元数据(如来源、创建时间、作者等)
```python
class Document(BaseMedia):
"""Class for storing a piece of text and associated metadata.
Example:
.. code-block:: python
from langchain_core.documents import Document
document = Document(
page_content="Hello, world!",
metadata={"source": "https://example.com"}
)
"""
page_content: str
"""String text."""
type: Literal["Document"] = "Document"
```
* Loader 的分类与常见类型
* 文件加载器(File Loaders)
| Loader 类型 | 功能描述 |
| :----------------------: | :----------------------------------: |
| `TextLoader` | 加载纯文本文件(.txt) |
| `CSVLoader` | 解析 CSV 文件,按行生成 Document |
| `PyPDFLoader` | 提取 PDF 文本及元数据(基于 PyPDF2) |
| `Docx2txtLoader` | 读取 Word 文档(.docx) |
| `UnstructuredFileLoader` | 通用文件解析(支持多种格式) |
* 网页加载器(Web Loaders)
| Loader 类型 | 功能描述 |
| :--------------: | :----------------------------: |
| `WebBaseLoader` | 抓取网页文本内容 |
| `SeleniumLoader` | 处理需要 JavaScript 渲染的页面 |
* 数据库加载器(Database Loaders)
| Loader 类型 | 功能描述 |
| :-----------------: | :---------------------: |
| `SQLDatabaseLoader` | 执行 SQL 查询并加载结果 |
| `MongoDBLoader` | 从 MongoDB 中读取数据 |
* 其他加载器 (自定义) ...
#### 文档加载器Loaders技术多案例实战
* TextLoader - 加载纯文本文件
* ##### **通用参数**
- **`encoding`**: 文件编码(默认 `utf-8`)
- **`autodetect_encoding`**: 自动检测编码(如处理中文乱码)
```python
from langchain_community.document_loaders import TextLoader
# 文本加载
loader = TextLoader("data/test.txt")
documents = loader.load()
print(documents)
print(len(documents)) #长度
print(documents[0].page_content[:100]) # 打印前100个字符
print(documents[0].metadata) # 输出: {'source': 'data/test.txt'}
```
* CSVLoader - 加载 CSV 文件
* 基础案例代码
```python
from langchain_community.document_loaders import CSVLoader
loader = CSVLoader("data/test.csv", csv_args={"delimiter": ","})
documents = loader.load()
# 每行转换为一个 Document,metadata 包含行号
print(len(documents))
print(documents[0].metadata) # 输出: {'source': 'data.csv', 'row': 0}
print(documents[0].page_content)
```
* 可指定列名,按行生成文档
```python
from langchain_community.document_loaders import CSVLoader
#loader = CSVLoader("data/test.csv", csv_args={"delimiter": ","})
loader = CSVLoader("data/test.csv", csv_args={"fieldnames": ["产品名称", "销售数量", "客户名称"]})
documents = loader.load()
# 每行转换为一个 Document,metadata 包含行号
print(len(documents))
print(documents[1].metadata) # 输出: {'source': 'data.csv', 'row': 0}
print(documents[1].page_content)
```
* JSONLoader - 加载 JSON 文件
* 核心参数详解
| 参数 | 类型 | 必填 | 说明 |
| :-------------- | :------- | :--- | :----------------------------------------------- |
| `file_path` | str | ✅ | JSON 文件路径 |
| `jq_schema` | str | ✅ | jq 查询语法,定义数据提取逻辑 |
| `content_key` | str | ❌ | 指定作为文本内容的字段(默认直接使用提取到的值) |
| `metadata_func` | Callable | ❌ | 自定义元数据处理函数 |
| `text_content` | bool | ❌ | 是否将提取内容强制转为字符串(默认 True) |
* 必选参数 `jq_schema`
* 必须使用 `jq_schema` 语法指定数据提取路径
* 支持更复杂的 JSON 结构解析
* jq 语法常用模式
| 场景 | jq_schema 示例 | 说明 |
| :----------- | :----------------------------------- | :--------------------------- |
| 提取根级数组 | `.[]` | 适用于 JSON 文件本身是数组 |
| 嵌套对象提取 | `.data.posts[].content` | 提取 data.posts 下的 content |
| 条件过滤 | `.users[] | select(.age > 18)` | 筛选年龄大于18的用户 |
| 多字段合并 | `{name: .username, email: .contact}` | 组合多个字段为对象 |
* 案例实战
* 安装依赖包
```
pip install jq
```
* 编码实战
```python
from langchain_community.document_loaders import JSONLoader
loader = JSONLoader(
file_path="data/test.json",
jq_schema=".articles[]", # 提取 articles 数组中的每个元素
content_key="content" # 指定 content 字段作为文本内容
)
docs = loader.load()
print(len(docs))
print(docs[0]
```
#### PDF文档加载器实战和常见问题处理
* `PyPDFLoader` 加载PDF文件
* `PyPDFLoader` 是 LangChain 中专门用于加载和解析 **PDF 文件** 的文档加载器。
* 它能将 PDF 按页拆分为多个 `Document` 对象,每个对象包含页面文本和元数据(如页码、来源路径等)。
* 适用于处理多页PDF文档的文本提取任务。
* 使用步骤
* 安装依赖库
```python
pip install pypdf
```
* 案例代码实战
```python
from langchain_community.document_loaders import PyPDFLoader
# PDF加载
loader = PyPDFLoader("data/test.pdf")
# 加载文档并按页分割
pages = loader.load() # 返回 Document 对象列表
# 查看页数
print(f"总页数: {len(pages)}")
# 访问第一页内容
page_content = pages[0].page_content
metadata = pages[0].metadata
print(f"第一页内容:\n{page_content[:200]}...") # 预览前200字符
print(f"元数据: {metadata}")
```
* 按需加载, 通过 `load()` 方法的参数控制加载范围:
```python
# 加载指定页码范围(例如第2页到第4页)
pages = loader.load([1, 2, 3]) # 注意页码从0开始(第1页对应索引0)
```
* 提取所有文本合并为单个文档, 若需将全部页面内容合并为一个字符串:
```python
full_text = "\n\n".join([page.page_content for page in pages])
print(f"合并后的全文长度: {len(full_text)} 字符")
```
* 常见问题与解决方案
* PDF无法加载或内容为空
* 原因:PDF为扫描版图片或加密。
* 解决:
* 使用OCR工具(如pytesseract+pdf2image)提取图片文本。
* 解密PDF后加载(需密码时,PyPDFLoader暂不支持直接解密)
* 文本分块不理想
* 调整分块策略:选择合适的分隔符或分块大小
```python
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "."], # 按段落、句子分割
chunk_size=500,
chunk_overlap=100
)
```
* 高级技巧
* **批量处理PDF**:遍历文件夹内所有PDF文件。
```python
import os
pdf_folder = "docs/"
all_pages = []
for filename in os.listdir(pdf_folder):
if filename.endswith(".pdf"):
loader = PyPDFLoader(os.path.join(pdf_folder, filename))
all_pages.extend(loader.load())
```
#### Loader进阶-PDF文档里面的图片提取解析
* 如何提取PDF里面的图片文案?
* `PyPDFLoader` 仅提取文本,如果没配置第三方类库则会提取不了对应的图片文案
* 需结合其他库(如`camelot`、`pdfplumber`、`rapidocr-onnxruntime`)提取表格或图像。
* 如果需要提取,安装好依赖库后,设置`extract_images`参数为`True`。
* `RapidOCR-ONNXRuntime `介绍
* 是一个基于 ONNX Runtime 推理引擎的轻量级 OCR(光学字符识别)工具库,专注于高效、跨平台部署。
* 它是 [RapidOCR](https://github.com/RapidAI/RapidOCR) 项目的一个分支,实现了更高的推理速度和更低的资源占用
* 特点:
* 跨平台支持:支持 Windows、Linux、macOS,以及移动端(Android/iOS)和嵌入式设备。
* 多语言识别:支持中文、英文、日文、韩文等多种语言,尤其擅长中英混合文本。
* 轻量级:模型体积小(约几 MB),适合资源受限的环境。
* 预处理与后处理集成:内置图像预处理(如二值化、方向校正)和文本后处理(如去除冗余字符)。
* RapidOCR-ONNXRuntime 与其他主流 OCR 工具的对比:
| 工具 | 引擎 | 速度 | 准确率 | 语言支持 | 依赖项 | 适用场景 |
| :----------------------- | :----------- | :--- | :----- | :------- | :----- | :--------------------- |
| **RapidOCR-ONNXRuntime** | ONNX Runtime | ⭐⭐⭐⭐ | ⭐⭐⭐ | 多语言 | 少 | 跨平台、轻量级部署 |
| **Tesseract** | 自研引擎 | ⭐⭐ | ⭐⭐ | 多语言 | 多 | 历史项目、简单场景 |
| **EasyOCR** | PyTorch | ⭐⭐ | ⭐⭐⭐ | 多语言 | 多 | 快速原型开发 |
| **Microsoft Read API** | 云端服务 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 多语言 | 无 | 企业级、高并发云端需求 |
* 案例实战
* 安装依赖包 (**耗时会有点久**)
```
pip install rapidocr-onnxruntime
```
* 代码实战
```python
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("data/pdf-img.pdf", extract_images=True)
pages = loader.load()
print(pages[0].page_content)
```
#### 网页加载器WebBaseLoader案例实战
**简介: Web网页加载器WebBaseLoader案例实战**
* 什么是WebBaseLoader
* `WebBaseLoader` 是 LangChain 中用于抓取 **静态网页内容** 的文档加载器。
* 通过 HTTP 请求直接获取网页 HTML,并提取其中的文本内容(自动清理标签、脚本等非文本元素)
* 生成包含网页文本和元数据的 `Document` 对象
* 适用于新闻文章、博客、文档页面等静态内容的快速提取。
* 场景
* 知识库构建(知识问答、企业知识库)、舆情监控(新闻/社交媒体分析)
* 竞品分析(产品功能/价格监控)、SEO 内容聚合
* 使用步骤
* 安装依赖库
```python
pip install beautifulsoup4 # HTML 解析依赖(默认已包含)
pip install requests # 网络请求依赖(默认已包含)
```
* 目标网页要求
* 无需 JavaScript 渲染(动态内容需改用 `SeleniumURLLoader` ,但是很鸡肋,少用)
* 未被反爬虫机制拦截(如需要,需配置代理或请求头)
* 如果动态网页,且内容提取好,还是需要单独针对不同的网站写代码进行提取内容
* 案例实战
* 基础用法:加载单个网页
```python
import os
#代码中设置USER_AGENT, 设置USER_AGENT的代码一定要放在WebBaseLoader 这个包前面,不然还是会报错
os.environ['USER_AGENT'] = 'Mozilla/5.0 (Windows NT 14.0; Win64; x64) AppleWebKit/567.36 (KHTML, like Gecko) Chrome/58.0.444.11 Safari/337.3'
from langchain_community.document_loaders import WebBaseLoader
#警告日志信息:USER_AGENT environment variable not set, consider setting it to identify your requests.
# 初始化加载器,传入目标URL列表(可多个)
urls = ["https://www.cnblogs.com"]
loader = WebBaseLoader(urls)
# 加载文档(返回Document对象列表)
docs = loader.load()
# 查看结果
print(f"提取的文本长度: {len(docs[0].page_content)} 字符")
print(f"前200字符预览:\n{docs[0].page_content[:200]}...")
print(f"元数据: {docs[0].metadata}")
```
* 批量加载多个网页
```python
import os
#代码中设置USER_AGENT, 注意设置USER_AGENT的代码一定要放在WebBaseLoader 这个包前面,不然还是会报错
os.environ['USER_AGENT'] = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
from langchain_community.document_loaders import WebBaseLoader
#警告日志信息:USER_AGENT environment variable not set, consider setting it to identify your requests.
# 初始化加载器,传入目标URL列表(可多个)
urls = [
"https://news.baidu.com/", # 新闻
"https://tieba.baidu.com/index.html" # 贴吧
]
loader = WebBaseLoader(urls)
docs = loader.load()
print(f"共加载 {len(docs)} 个文档")
print("各文档来源:")
for doc in docs:
print(f"- {doc.metadata['source']}")
```
* 更多详细API和参数 https://python.langchain.com/docs/integrations/document_loaders/web_base/
#### Word文档加载器实战和常见问题处理
* `Docx2txtLoader`介绍
* 是 LangChain 中专门用于加载 **Microsoft Word 文档(.docx)** 的文档加载器。
* 提取文档中的纯文本内容(包括段落、列表、表格文字等),忽略复杂格式(如字体、颜色),生成统一的 `Document` 对象。
* 适用于从 Word 报告中快速提取结构化文本
* 使用步骤
* 安装依赖库
```python
pip install docx2txt # 核心文本提取库
```
* 准备.docx文件:确保目标文件为 .docx 格式(旧版 .doc 需转换),且未被加密
* 案例代码实战
* 基础用法:加载单个Word文档
```python
from langchain_community.document_loaders import Docx2txtLoader
# 初始化加载器,传入文件路径
loader = Docx2txtLoader("data/test1.docx")
# 加载文档(返回单个Document对象)
documents = loader.load()
# 查看内容
print(f"文本长度: {len(documents[0].page_content)} 字符")
print(f"前200字符预览:\n{documents[0].page_content[:200]}...")
print(f"元数据: {documents[0].metadata}")
```
* 批量加载文档
```python
from langchain_community.document_loaders import Docx2txtLoader
import os
folder_path = "data/"
all_docs = []
# 遍历文件夹内所有.docx文件
for filename in os.listdir(folder_path):
if filename.endswith(".docx"):
file_path = os.path.join(folder_path, filename)
loader = Docx2txtLoader(file_path)
all_docs.extend(loader.load()) # 合并所有文档
print(f"加载文件: {filename}")
print(all_docs)
```
* 常见问题与解决方案
* 加载 .doc 文件报错
* 原因:docx2txt 仅支持 .docx 格式。
* 解决:使用 Word 将 .doc 另存为 .docx。
* 文档中的图片/图表未被提取
* 原因:Docx2txtLoader 仅提取文本,忽略图片。
* 解决:使用 python-docx 单独提取图片,也可以使用其他组件,类似OCR
### RAG检索增强生成之文档切割
#### RAG系统链路构建之文档切割转换
* 构建RAG系统:**涉及的技术链路环节: 文档加载器->文档转换器->文本嵌入模型->向量存储->检索器**
* RAG数据流水线示意图
```python
原始数据 → 数据加载 → 预处理 → 向量化 → 存储 → 检索增强生成
↗ ↗ ↗
PDF 文本清洗 嵌入模型
数据库 分块
网页
```

* 需求背景,为啥要用?
* 模型输入限制:GPT-4最大上下文32k tokens,Claude 3最高200k
* 信息密度不均:关键信息可能分布在长文本的不同位置
* 格式兼容性问题:PDF/HTML/代码等不同格式的结构差异
* 文档转换器(Document Transformers)
* 文档转换器是 LangChain 处理文档流水线的核心组件,负责对原始文档进行结构化和语义化处理,
* 为后续的向量化存储、检索增强生成(RAG)等场景提供标准化输入。
* 核心任务:文本清洗、分块、元数据增强
* 关键操作
* **文本分块**:按固定长度或语义分割(防止截断完整句子)
* **去噪处理**:移除特殊字符、乱码、广告内容
* **元数据注入**:添加来源、时间戳等上下文信息
* 效果
* **保留语义完整性**:避免因分割导致上下文断裂或信息丢失
* **适配模型输入限制**:确保分割后的文本块长度符合大语言模型(LLM)的token限制
* **优化向量化效果**:通过合理分块提升向量表示的语义精度,从而提高检索匹配率
| 问题类型 | 原始文档示例 | 转换前问题 | 转换后效果 |
| :--------: | :-----------: | :-----------------------: | :--------------------: |
| 长文本溢出 | 500页法律合同 | 直接输入导致API报错 | 分割为上下文合规的段落 |
| 信息碎片化 | 产品手册PDF | 技术参数分散在不同页面 | 按功能模块重组内容 |
| 噪音污染 | 网页抓取内容 | 包含广告/导航栏等干扰信息 | 提取纯净正文内容 |
| 格式混乱 | 代码仓库文档 | Markdown/代码片段混合 | 分离代码与说明文本 |
* 基础类和核心参数说明
```python
from langchain_text_splitters import TextSplitter
#源码
class TextSplitter(BaseDocumentTransformer, ABC):
"""Interface for splitting text into chunks."""
def __init__(
self,
chunk_size: int = 4000,
chunk_overlap: int = 200,
length_function: Callable[[str], int] = len,
keep_separator: Union[bool, Literal["start", "end"]] = False,
add_start_index: bool = False,
strip_whitespace: bool = True,
) -> None:
```
* 方法说明
* `TextSplitter`本身没有实现`split_text`,要文档分割器按自己的分割策略实现分割
* 关键方法调用 `split_documents()->create_documents->()->split_text()`
* `split_text()`是基础文本分割方法
* `create_documents()`在`split_text()`基础上封装了元数据绑定逻辑
* `split_documents()`内部调用`create_documents()`并自动处理元数据传递
| 方法 | 输入类型 | 输出类型 | 元数据处理 | 典型使用场景 |
| :----------------------- | :------------------- | :--------------- | :------------------------- | :------------------------------------ |
| **`split_text()`** | **单个字符串** | `List[str]` | ❌ 不保留元数据 | 仅需分割纯文本内容时使用 |
| **`create_documents()`** | **字符串列表** | `List[Document]` | ✅ 需手动传递元数据 | 从原始文本构建带元数据的文档对象 |
| **`split_documents()`** | **Document对象列表** | `List[Document]` | ✅ 自动继承输入文档的元数据 | 分割已加载的文档对象(如PDF解析结果) |
* `chunk_size`
* 定义:每个文本块的最大长度(字符数或token数),用于控制分割后的文本块大小。
* 作用
* 防止文本过长超出模型处理限制,影响检索精度。
* 较小的chunk_size能提高检索细粒度,会导致上下文缺失。
* 例子
```python
# 设置chunk_size=100,分割文本为不超过100字符的块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
#输入文本:"Python是一种解释型语言,适合快速开发。它支持面向对象编程,语法简洁。"
#分割结果:["Python是一种解释型语言,适合快速开发。", "开发。它支持面向对象编程,语法简洁。"](假设每个块接近100字符)
```
* `chunk_overlap`
* 定义:相邻文本块之间的重叠字符数,用于保留上下文连贯性。
* 作用:避免因分割导致关键信息被切断(如句子中间被截断)
* 案例一
```python
如果chunk_size设为1024,chunk_overlap设为128, 对一个长度为2560的文本序列,会切分成3个chunk:
chunk 1: 第1-1024个token
chunk 2: 第897-1920个token (与chunk 1重叠128个)
chunk 3: 第1793-2560个token (与chunk 2重叠128个)
```
* 案例二
```python
# 设置chunk_size=50,chunk_overlap=10
text = "深度学习需要大量数据和计算资源。卷积神经网络(CNN)在图像处理中表现优异。"
text_splitter = CharacterTextSplitter(chunk_size=50, chunk_overlap=10)
#分割结果:["深度学习需要大量数据和计算资源。卷积神经", "计算资源。卷积神经网络(CNN)在图像处理中表现优异。"]
# 重叠部分"计算资源。"确保第二块包含前一块的结尾
```
* `separators`
* 定义:分隔符优先级列表,用于递归分割文本。
* 作用:优先按自然语义边界(如段落、句子)分割,减少语义断裂。
* 例子
```python
# 默认分隔符:["\n\n", "\n", " ", ""]
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "。", ",", " "]
)
#输入文本:"第一段\n\n第二段。第三段,第四段"
#分割流程:先按\n\n分割为两段,若仍超长则按。继续分割
```
#### 字符文档转换器TextSplitter案例实战
* `CharacterTextSplitter` 字符分割器
* 核心特点
* 是 LangChain 中最基础的文本分割器,采用**固定长度字符切割**策略。
* 适用于结构规整、格式统一的文本处理场景,强调**精确控制块长度**
* 适用于结构清晰的文本(如段落分隔明确的文档)。
* 核心参数详解
| 参数 | 类型 | 默认值 | 说明 |
| :------------------: | :--: | :------: | :----------------------: |
| `separator` | str | `"\n\n"` | 切割文本的分隔符 |
| `chunk_size` | int | `4000` | 每个块的最大字符数 |
| `chunk_overlap` | int | `200` | 相邻块的重叠字符数 |
| `strip_whitespace` | bool | `True` | 是否清除块首尾空格 |
| `is_separator_regex` | bool | `False` | 是否启用正则表达式分隔符 |
* 案例代码
* 长文本处理
```python
from langchain.text_splitter import CharacterTextSplitter
text = "是一段 需要被分割的 长文本示例....,每个文本块的最大长度(字符数或token数)Document loaders are designed to load document objects. LangChain has hundreds of integrations with various data sources to load data from: Slack, Notion, Google Drive"
splitter = CharacterTextSplitter(
separator=" ",
chunk_size=50,
chunk_overlap=10
)
chunks = splitter.split_text(text)
print(len(chunks))
for chunk in chunks:
print(chunk)
```
* 日志文件处理
```python
from langchain.text_splitter import CharacterTextSplitter
log_data = """
[ERROR] 2026-03-15 14:22:35 - Database connection failed
[INFO] 2026-03-15 14:23:10 - Retrying connection...
[WARNING] 2026-03-15 14:23:45 - High memory usage detected
"""
splitter = CharacterTextSplitter(
separator="\n",
chunk_size=60,
chunk_overlap=20
)
log_chunks = splitter.split_text(log_data)
for chunk in log_chunks:
print(chunk)
```
* 优缺点说明
| 特性 | 优势 | 局限性 |
| :--------: | :----------------------: | :----------------------------------------: |
| 分割速度 | ⚡️ 极快(O(n)复杂度) | 不考虑语义结构 |
| 内存消耗 | 🟢 极低 | 可能切断完整语义单元, 对语义关联性保持较弱 |
| 配置灵活性 | 🛠️ 支持自定义分隔符和重叠 | 需要预定义有效分隔符 |
| 多语言支持 | 🌍 支持任意字符集文本 | 对表意文字计算可能不准确 |
* 适合场景
* 推荐使用:
- 结构化日志处理
- 代码文件解析
- 已知明确分隔符的文本(如Markdown)
- 需要精确控制块大小的场景
* 不推荐使用:
- 自然语言段落(建议用RecursiveCharacterSplitter)
- 需要保持语义完整性的场景
- 包含复杂嵌套结构的文本
#### 递归字符文档转换器TextSplitter案例实战
* `RecursiveCharacterTextSplitter` 递归字符分割器
* 核心特点
* **递归字符分割器**采用**多级分隔符优先级切割**机制,是 LangChain 中使用最广泛的通用分割器。
* 递归尝试多种分隔符(默认顺序:`["\n\n", "\n", " ", ""]`),优先按大粒度分割
* 若块过大则继续尝试更细粒度分隔符,适合处理结构复杂或嵌套的文本。
* 核心参数说明
```python
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 目标块大小(字符)每个块最多包含 1000 个字符
chunk_overlap=200, # 块间重叠量,最多有200个字符重叠
separators=["\n\n", "\n", "。", "?", "!", " ", ""], # 优先级递减的分割符
length_function=len, # 长度计算函数
keep_separator=True, # 是否保留分隔符
)
```
* 案例实战
* 基础案例测试, 处理后chunk之间也有overlap
```python
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
#separators=["\n\n", "\n", " ", ""], #首先按段落分割,然后按行分割,最后按空格分割,如果都不行则按字符分割
chunk_size=20, #每个块的最大大小,不超过即可,如果超过则继续调用_split_text分隔(以字符数为单位)
chunk_overlap=4 #块与块之间的重叠部分的大小
)
text = "I Love English hello world, how about you? If you're looking to get started with chat models, vector stores, or other LangChain components from a specific provider, check out our supported integrations"
chunks = splitter.split_text(text)
print(len(chunks))
for chunk in chunks:
print(chunk)
```
* 学术论文处理
```python
from langchain.text_splitter import RecursiveCharacterTextSplitter
paper_text = """
引言机器学习近年来取得突破性进展...(长文本)若块过大则继续尝试更细粒度分隔符,适合处理结构复杂或嵌套的文本
方法我们提出新型网络架构...(技术细节)按优先级(如段落、句子、单词)递归分割文本,优先保留自然边界,如换行符、句号
实验在ImageNet数据集上...处理技术文档时,使用chunk_size=800和chunk_overlap=100,数据表格
"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=20,
chunk_overlap=4
)
paper_chunks = splitter.split_text(paper_text)
print(len(paper_chunks))
for chunk in paper_chunks:
print(chunk)
```
* 避坑指南
```python
# 错误示范:不合理的separators顺序
bad_splitter = RecursiveCharacterTextSplitter(
separators=[" ", "\n"], # 空格优先会导致过早分割
chunk_size=500
)
# 正确写法:从大结构到小结构
good_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", "。", " ", ""]
)
```
* 核心优势对比
| 特性 | CharacterTextSplitter | RecursiveCharacterTextSplitter |
| :------------: | :-------------------: | :----------------------------: |
| 分隔符策略 | 单级固定分隔符 | 多级优先级递归分隔符 |
| 语义保持能力 | ★★☆☆☆ | ★★★★☆ |
| 复杂文本适应性 | 简单结构化文本 | 混合格式/长文本/多语言 |
| 典型应用场景 | 日志/CSV | 论文/邮件/网页/混合代码文 |
* 推荐场景
* 学术论文/技术文档解析
* 多语言混合内容处理
* 包含嵌套结构的文本(如Markdown)
* 需要保持段落完整性的问答系统
#### 分割器常见问题和优化最佳实践
* 其他常见分割器
* 递归字符分割(RecursiveCharacterTextSplitter)
* 原理:按优先级(如段落、句子、单词)递归分割文本,优先保留自然边界(如换行符、句号)
* 适用场景:通用文本处理,尤其适合逻辑紧密的长文档(如论文、技术手册)
* 固定大小分割(CharacterTextSplitter)
* 原理:按固定字符数分割,简单但可能打断句子结构。
* 优化:通过重叠(chunk_overlap)和智能截断(如优先在标点处分隔)减少语义断裂
* 适用场景:结构松散或句子独立性强的文本(如产品说明书)
* Token分割(TokenTextSplitter)
* 原理:基于LLM的token限制分割,避免超出模型输入长度。
* 优势:更贴近模型处理逻辑(如GPT系列)
* 结构化文档分割
* HTML/Markdown分割器:按标题层级分割,保留元数据(如`HTMLHeaderTextSplitter`)
* 适用场景:网页、技术文档等结构化内容
* 还有很多,可以查看官方文档拓展(如果不可访问,百度搜索)
* https://python.langchain.com/docs/how_to/
* 关键参数`chunk_size、chunk_overlap`
| 参数 | 作用 | 默认值 | 关键限制条件 |
| :------------------ | :----------------------------------------------------------- | :----- | :------------------------ |
| **`chunk_size`** | 定义每个文本块的最大长度(根据`length_function`计算,默认按字符数) | 1000 | 必须为正整数 |
| **`chunk_overlap`** | 定义相邻块之间的重叠长度 | 20 | 必须小于`chunk_size`的50% |
* 重叠内容未出现的常见原因
* 文本总长度不足:当输入文本长度 ≤ chunk_size时,不会触发分割。
```python
#解释:文本长度远小于chunk_size,不触发分割,无重叠。
from langchain_text_splitters import CharacterTextSplitter
text = "这是一个非常短的测试文本。"
text_splitter = CharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
separator="。", # 按句号分割
length_function=len
)
chunks = text_splitter.split_text(text)
print(chunks)
# 输出:['这是一个非常短的测试文本。']
```
* 递归分割策略:RecursiveCharacterTextSplitter优先保证块大小,可能牺牲重叠。
```python
# 解释:当无法找到分隔符时,按字符数硬分割,强制保留重叠。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text = "这是一段没有标点的超长文本需要被分割成多个块但是因为没有分隔符所以分割器会尝试按字符递归分割直到满足块大小要求"
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=30,
chunk_overlap=10,
separators=["", " "], # 无有效分隔符时按字符分割
length_function=len
)
chunks = text_splitter.split_text(text)
for i, chunk in enumerate(chunks):
print(f"块{i+1}(长度{len(chunk)}): {chunk}")
# 输出示例:
# 块1(长度30): 这是一段没有标点的超长文本需要被分割成多个块但是因为没有分隔
# 块2(长度30): 个块但是因为没有分隔符所以分割器会尝试按字符递归分割直到满足
# 块3(长度15): 字符递归分割直到满足块大小要求
# 重叠部分:"个块但是因为没有分隔"(10字符)
```
* `enumerate()`
* 函数是一个内置函数,用于在迭代过程中同时获取元素的索引和值。
* 它返回一个枚举对象,包含了索引和对应的元素
```python
# enumerate(iterable, start=0)
#参数:iterable:必需,一个可迭代对象,如列表、元组、字符串等。
#参数:start:可选,指定索引的起始值,默认为 0。
fruits = ['apple', 'banana', 'orange']
for index, fruit in enumerate(fruits):
print(index, fruit)
```
* 分隔符强制分割:在分隔符处切割时,剩余文本不足以形成重叠。
```python
#解释:分隔符优先切割,每个块正好为7个字符,无法形成重叠。
from langchain_text_splitters import CharacterTextSplitter
text = "abcdefg.hijkllm.nopqrst.uvwxyz"
text_splitter = CharacterTextSplitter(
chunk_size=7,
chunk_overlap=3,
separator=".", # 按句号分割
is_separator_regex=False
)
chunks = text_splitter.split_text(text)
print("分割块数:", len(chunks))
for i, chunk in enumerate(chunks):
print(f"块{i+1}: {chunk}")
```
* 参数调优最佳实践
* 通用文本处理
* 参数建议:`chunk_size=500-1000字符,chunk_overlap=10-20%`
* 案例:
* 处理技术文档时,使用`chunk_size=800和chunk_overlap=100`
* 确保每个块包含完整段落,同时通过重叠保留跨段落的关键术语
* 代码分割
* 参数建议:根据编程语言特性调整分隔符。
* 案例:
* 分割Python代码时,`RecursiveCharacterTextSplitter.from_language(Language.PYTHON)`
* 会自动识别函数、类等结构,避免打断代码逻辑
```python
from langchain_text_splitters import Language, RecursiveCharacterTextSplitter
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=200, chunk_overlap=50
)
```
* 结构化文档(如Markdown)
* 参数建议:结合标题层级分割。
* 案例:
* 使用MarkdownHeaderTextSplitter按标题分割,保留元数据
* 输入Markdown内容将按标题层级生成带元数据的块
```python
headers_to_split_on = [("#", "Header 1"), ("##", "Header 2")]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on)
```
* 常见问题与解决方案
* 过长导致语义模糊
* 表现:检索时匹配不精准。
* 解决:缩小chunk_size,增加chunk_overlap
* 块过短丢失上下文
* 表现:回答缺乏连贯性。
* 解决:合并相邻块或使用ParentDocumentRetriever,将细粒度块与父文档关联
* 参数选择原则:
* 密集文本(如论文):chunk_size较大(如1000),chunk_overlap约15%。
* 松散文本(如对话记录):chunk_size较小(如200),chunk_overlap约20%。
* **实验验证:通过AB测试对比不同参数的检索准确率与生成质量**
### 人工智能和高等数学核心基础扫盲
#### 扫盲-AI大模型必备之向量-张量和应用场景
* 什么是向量
* 向量就是一串有序的数字,像一条带方向的“箭头”, 在机器学习里面尤其重要
 * 世间万物使用计算机表示,用的数字化语言,让计算机能理解复杂事物, 每个数据都包含多种属性
* 比如气象数据(包含温度,湿度,风向等等)
* 金融数据(开盘价,收盘价,交易量等等)
* 销售数据(价格,库存量,卖出数量等等)
* 为了表示多属性的数据,或者称为多维度的数据,向量最为合适。
* 向量就是有几个数字横向或者纵向排列而成,每个数字代表一个属性。
```python
// 传统Java数据存储
String[] names = {"小明", "身高", "体重"};
Object[] person = {"张三", 175, 68.5};
// 向量化表示(特征向量)
float[] vector = {0.83f, 175.0f, 68.5f}; // [性别编码, 身高, 体重]
# Python列表表示
vector = [1.2, 3.5, 4.0, 0.8]
```
* 向量能做什么?
* 计算相似度:比如比较两个人的喜好是否接近、物品是否类似
* 用户画像:`[年龄=25, 身高=175, 消费=5000]` → 用数字描述一个人
* 案例:有两个水果的向量(也可以抽取更多属性)
- 苹果:[红色: 0.91, 甜度: 0.83, 圆形: 0.79]
- 草莓:[红色: 0.85, 甜度: 0.75, 圆形: 0.69]
* 多维向量
* 就是维度更多的向量(比如100个数字组成的列表)。
* 例子:
- 词向量:`“猫” = [0.2, -0.3, 0.7, ..., 0.1]`(300个数字表示词义,抽取多点属性,形状、毛发、行为、食物...)。
- 图片特征:一张猫的图片转换为 `[0.8, 0.1, 0.05, ...]`(1000个数字描述图片内容)
- 高维向量表示用户画像
```python
public class UserVector {
// 每个维度代表一个特征
float[] features = new float[256];
// 可能包含:
// [0-49]: 兴趣标签权重
// [50-99]: 行为频率
// [100-255]: 深度模型提取特征
}
```
* 为什么维度越多越好?
- 细节更丰富 , 就像简历写得越详细,越能区分不同的人。
- 低维:`[年龄=25, 性别=1]` → 只能简单分类。
- 高维:`[年龄、性别、职业、兴趣1、兴趣2...]` → 精准推荐商品。
* 多维向量应用场景
- 推荐系统:用用户向量和商品向量计算匹配度。
- 人脸识别:把照片变成向量,对比找到最相似的人。
- 数据表示:用户画像(年龄、性别、兴趣等N个特征)
- 几何计算:三维游戏中物体的位置和移动
* 通俗理解高维空间
- 假设你在三维空间找不到两片不同的树叶,但在100维空间里,每片树叶的位置都会独一无二
* 张量
* 张量是多维数组的统称,涵盖标量、向量、矩阵及更高维结构 ,
* 阶(Rank)表示维度数:
* **标量(0阶张量)**:单个数字(如温度25℃)。
* **向量(1阶张量)**:一维数组(如 `[1, 2, 3]`)。
* **矩阵(2阶张量)**:二维表格(如Excel表格)。
* **高阶张量**:三维及以上(如视频数据:时间×宽×高×颜色通道)
| 阶数 | 数学名称 | 典型应用 | Java存储结构 |
| :--: | :------: | :-------: | :----------: |
| 0 | 标量 | 温度值 | float |
| 1 | 向量 | 用户画像 | float[] |
| 2 | 矩阵 | Excel表格 | float[][] |
| 3 | 张量 | 彩色图片 | float[][][] |
| **数据** | **张量形状** | **解释** |
| :----------: | :------------------: | :-------------------------: |
| 一张黑白图片 | `(28, 28)` | 28行×28列的像素矩阵 |
| 一个视频片段 | `(100, 128, 128, 3)` | 100帧,每帧128x128的RGB图片 |
| 一批用户数据 | `(500, 10)` | 500个用户,每人10个特征 |
* 常见问题
* 为什么要用张量而不是数组?
- 张量是AI框架(如PyTorch)的“通用语言”,能自动支持GPU加速和梯度计算。
* 维度太多会不会算不过来?
- 会!所以需要GPU和优化算法(比如深度学习)。
* 我该用几维向量
* 看任务需求:简单任务用几十维,复杂任务(如ChatGPT)可能用上千维!
* 总结:一句话记住它们!
* 向量 → 一串数字(像GPS坐标)。
* 多维向量 → 更长的数字串(像详细简历)。
* 张量 → 数字的“集装箱”(像Excel表格、图片集、视频流)。
#### 扫盲-高等数学里面的求和-点积公式讲解
* **什么是求和符号?**
* 求和符号Σ(希腊字母sigma)表示**连续加法运算**,用于简化多个数的累加书写。
* 英文意思为Sum,Summation,汉语意思为“和”“总和”。
* 基本形式
* 世间万物使用计算机表示,用的数字化语言,让计算机能理解复杂事物, 每个数据都包含多种属性
* 比如气象数据(包含温度,湿度,风向等等)
* 金融数据(开盘价,收盘价,交易量等等)
* 销售数据(价格,库存量,卖出数量等等)
* 为了表示多属性的数据,或者称为多维度的数据,向量最为合适。
* 向量就是有几个数字横向或者纵向排列而成,每个数字代表一个属性。
```python
// 传统Java数据存储
String[] names = {"小明", "身高", "体重"};
Object[] person = {"张三", 175, 68.5};
// 向量化表示(特征向量)
float[] vector = {0.83f, 175.0f, 68.5f}; // [性别编码, 身高, 体重]
# Python列表表示
vector = [1.2, 3.5, 4.0, 0.8]
```
* 向量能做什么?
* 计算相似度:比如比较两个人的喜好是否接近、物品是否类似
* 用户画像:`[年龄=25, 身高=175, 消费=5000]` → 用数字描述一个人
* 案例:有两个水果的向量(也可以抽取更多属性)
- 苹果:[红色: 0.91, 甜度: 0.83, 圆形: 0.79]
- 草莓:[红色: 0.85, 甜度: 0.75, 圆形: 0.69]
* 多维向量
* 就是维度更多的向量(比如100个数字组成的列表)。
* 例子:
- 词向量:`“猫” = [0.2, -0.3, 0.7, ..., 0.1]`(300个数字表示词义,抽取多点属性,形状、毛发、行为、食物...)。
- 图片特征:一张猫的图片转换为 `[0.8, 0.1, 0.05, ...]`(1000个数字描述图片内容)
- 高维向量表示用户画像
```python
public class UserVector {
// 每个维度代表一个特征
float[] features = new float[256];
// 可能包含:
// [0-49]: 兴趣标签权重
// [50-99]: 行为频率
// [100-255]: 深度模型提取特征
}
```
* 为什么维度越多越好?
- 细节更丰富 , 就像简历写得越详细,越能区分不同的人。
- 低维:`[年龄=25, 性别=1]` → 只能简单分类。
- 高维:`[年龄、性别、职业、兴趣1、兴趣2...]` → 精准推荐商品。
* 多维向量应用场景
- 推荐系统:用用户向量和商品向量计算匹配度。
- 人脸识别:把照片变成向量,对比找到最相似的人。
- 数据表示:用户画像(年龄、性别、兴趣等N个特征)
- 几何计算:三维游戏中物体的位置和移动
* 通俗理解高维空间
- 假设你在三维空间找不到两片不同的树叶,但在100维空间里,每片树叶的位置都会独一无二
* 张量
* 张量是多维数组的统称,涵盖标量、向量、矩阵及更高维结构 ,
* 阶(Rank)表示维度数:
* **标量(0阶张量)**:单个数字(如温度25℃)。
* **向量(1阶张量)**:一维数组(如 `[1, 2, 3]`)。
* **矩阵(2阶张量)**:二维表格(如Excel表格)。
* **高阶张量**:三维及以上(如视频数据:时间×宽×高×颜色通道)
| 阶数 | 数学名称 | 典型应用 | Java存储结构 |
| :--: | :------: | :-------: | :----------: |
| 0 | 标量 | 温度值 | float |
| 1 | 向量 | 用户画像 | float[] |
| 2 | 矩阵 | Excel表格 | float[][] |
| 3 | 张量 | 彩色图片 | float[][][] |
| **数据** | **张量形状** | **解释** |
| :----------: | :------------------: | :-------------------------: |
| 一张黑白图片 | `(28, 28)` | 28行×28列的像素矩阵 |
| 一个视频片段 | `(100, 128, 128, 3)` | 100帧,每帧128x128的RGB图片 |
| 一批用户数据 | `(500, 10)` | 500个用户,每人10个特征 |
* 常见问题
* 为什么要用张量而不是数组?
- 张量是AI框架(如PyTorch)的“通用语言”,能自动支持GPU加速和梯度计算。
* 维度太多会不会算不过来?
- 会!所以需要GPU和优化算法(比如深度学习)。
* 我该用几维向量
* 看任务需求:简单任务用几十维,复杂任务(如ChatGPT)可能用上千维!
* 总结:一句话记住它们!
* 向量 → 一串数字(像GPS坐标)。
* 多维向量 → 更长的数字串(像详细简历)。
* 张量 → 数字的“集装箱”(像Excel表格、图片集、视频流)。
#### 扫盲-高等数学里面的求和-点积公式讲解
* **什么是求和符号?**
* 求和符号Σ(希腊字母sigma)表示**连续加法运算**,用于简化多个数的累加书写。
* 英文意思为Sum,Summation,汉语意思为“和”“总和”。
* 基本形式
 
* **单变量求和示例**
* 计算1到5的整数和:

* **单变量求和示例**
* 计算1到5的整数和:
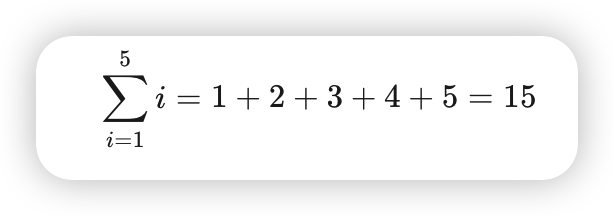 * 计算前3个偶数的平方和:
* 计算前3个偶数的平方和:
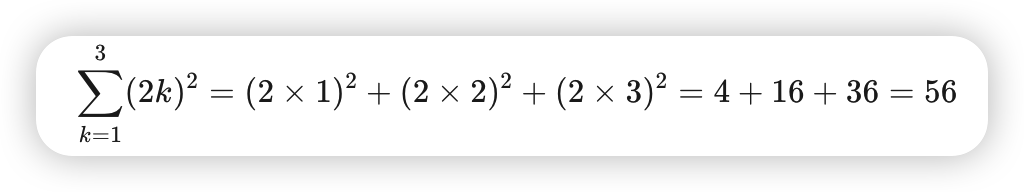 * 点积(内积)的定义与计算
* 点积是什么
* 点积是**两个向量对应分量相乘后求和**的运算,结果是一个标量(数值)。
* 点积(内积)的定义与计算
* 点积是什么
* 点积是**两个向量对应分量相乘后求和**的运算,结果是一个标量(数值)。
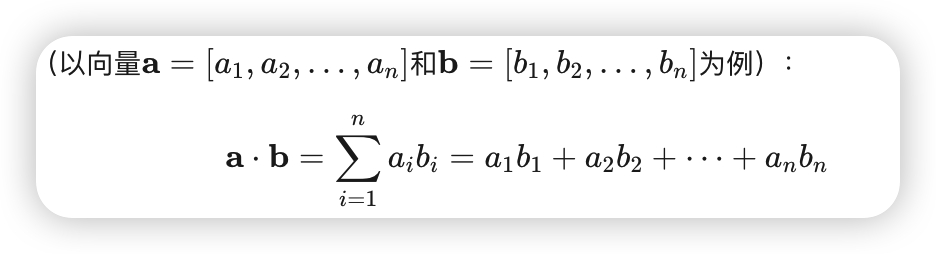 * 几何意义
* 点积反映两个向量的夹角关系
* 通过在空间中引入笛卡尔坐标系,向量之间的点积既可以由向量坐标的代数运算得出
* 几何意义
* 点积反映两个向量的夹角关系
* 通过在空间中引入笛卡尔坐标系,向量之间的点积既可以由向量坐标的代数运算得出
 * 点积计算示例
* 点积计算示例
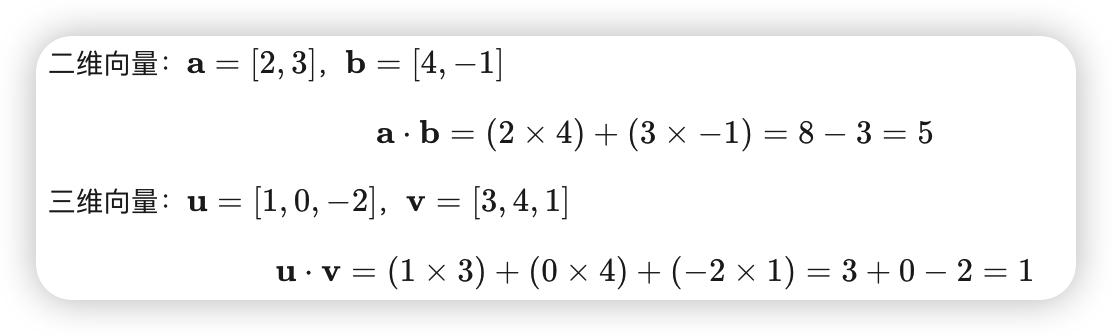 #### 扫盲-向量的相似度计算之余弦相似度
* 补充:三角函数
* **正弦(sinθ)**:对边长度与斜边长度的比值。
* **余弦(cosθ)**:邻边长度与斜边长度的比值(即夹角的两边)
#### 扫盲-向量的相似度计算之余弦相似度
* 补充:三角函数
* **正弦(sinθ)**:对边长度与斜边长度的比值。
* **余弦(cosθ)**:邻边长度与斜边长度的比值(即夹角的两边)
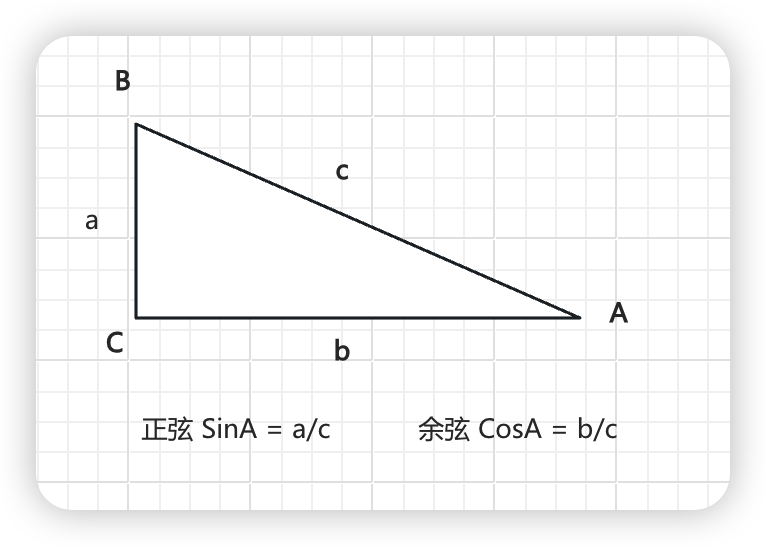 * 为啥要学余弦相似度?
* 生活中的相似度问题,假设你需要完成以下任务:
* 网购时:找出和你刚买的衣服最搭配的裤子
* 听歌时:发现与当前播放歌曲风格相似的曲目
* 点外卖时:找到和你常点菜品口味接近的新店铺
* **LLM大模型的RAG原理:用户输入自然语言query,找到最相关的文档**
* 这些场景的共同点:需要量化两个事物的相似程度,向量空间中的"方向感"
* 什么是余弦相似度?
* 基础定义:余弦相似度(Cosine Similarity)用于衡量两个向量在方向上的相似程度,忽略其绝对长度
* **值的范围为[-1,1],-1为完全不相似,1为完全相似。**
* 公式(向量的模长等于其各分量平方和的平方根)
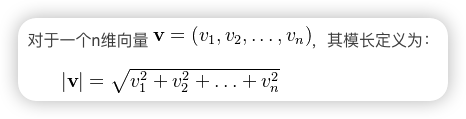
* 为啥要学余弦相似度?
* 生活中的相似度问题,假设你需要完成以下任务:
* 网购时:找出和你刚买的衣服最搭配的裤子
* 听歌时:发现与当前播放歌曲风格相似的曲目
* 点外卖时:找到和你常点菜品口味接近的新店铺
* **LLM大模型的RAG原理:用户输入自然语言query,找到最相关的文档**
* 这些场景的共同点:需要量化两个事物的相似程度,向量空间中的"方向感"
* 什么是余弦相似度?
* 基础定义:余弦相似度(Cosine Similarity)用于衡量两个向量在方向上的相似程度,忽略其绝对长度
* **值的范围为[-1,1],-1为完全不相似,1为完全相似。**
* 公式(向量的模长等于其各分量平方和的平方根)
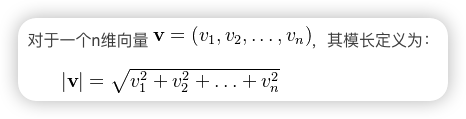
 * **直观理解**
- 几何意义:两个向量的夹角越小,方向越一致,余弦值越接近1。
- 1 → 完全相同方向
- 0 → 完全无关(正交)
- -1 → 完全相反方向
- 两条线段之间形成一个夹角,
- 如果夹角为0度,意味着方向相同、线段重合,这是表示两个向量代表的文本完全相等;
- 如果夹角为90度,意味着形成直角,方向完全不相似;
- 如果夹角为180度,意味着方向正好相反。
- **因此可以通过夹角的大小,来判断向量的相似程度,夹角越小,就代表越相似。**
* **为何选择余弦相似度?**
- **高维数据友好**:适用于文本、图像等高维稀疏数据。
- **长度不变性**:只关注方向,忽略向量长度差异(如文档长短)。
- **计算高效**:适合大规模向量检索
* 案例
* 以二维向量为例:向量A = [3, 4],向量B = [1, 2]
* 结论:两个向量方向高度相似!
* **直观理解**
- 几何意义:两个向量的夹角越小,方向越一致,余弦值越接近1。
- 1 → 完全相同方向
- 0 → 完全无关(正交)
- -1 → 完全相反方向
- 两条线段之间形成一个夹角,
- 如果夹角为0度,意味着方向相同、线段重合,这是表示两个向量代表的文本完全相等;
- 如果夹角为90度,意味着形成直角,方向完全不相似;
- 如果夹角为180度,意味着方向正好相反。
- **因此可以通过夹角的大小,来判断向量的相似程度,夹角越小,就代表越相似。**
* **为何选择余弦相似度?**
- **高维数据友好**:适用于文本、图像等高维稀疏数据。
- **长度不变性**:只关注方向,忽略向量长度差异(如文档长短)。
- **计算高效**:适合大规模向量检索
* 案例
* 以二维向量为例:向量A = [3, 4],向量B = [1, 2]
* 结论:两个向量方向高度相似!
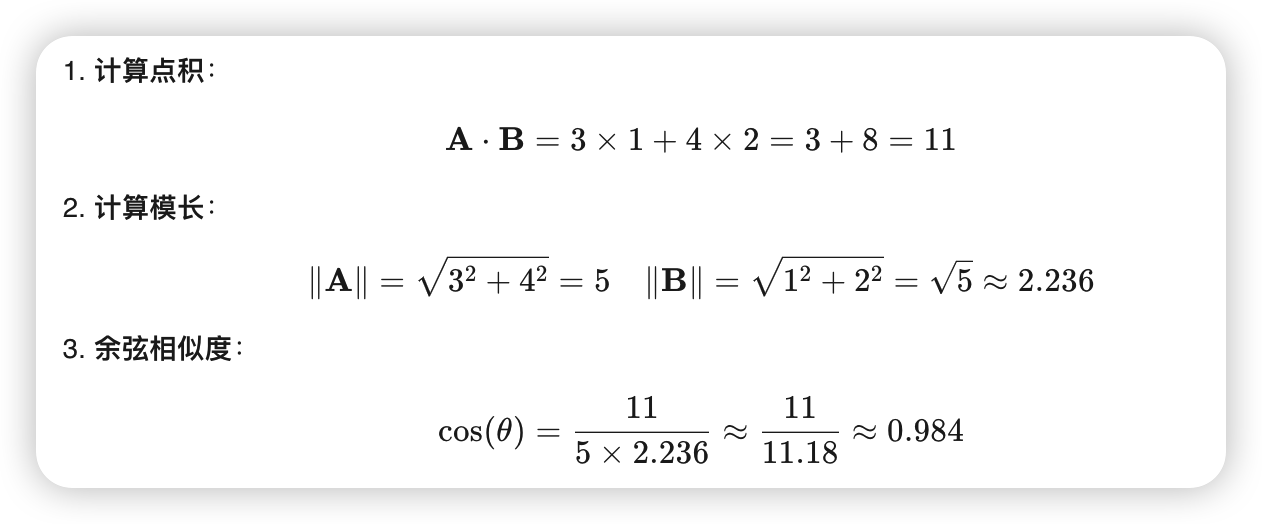 * 大模型中的核心应用场景
* 语义搜索(Semantic Search)
* 问题:用户输入自然语言query,找到最相关的文档。
* 实现步骤:
* 将query和所有文档编码为向量。
* 计算query向量与文档向量的余弦相似度。
* 返回Top-K相似度最高的文档。
* 推荐系统(User-Item Matching)
* 原理:用户向量和物品向量的余弦相似度 → 推荐得分。
* 示例:
* 用户向量:[0.3, 0.5, -0.2](表示对科技、体育、艺术的兴趣)
* 物品向量:[0.4, 0.1, 0.0](科技类文章)
* 相似度 ≈ 0.3×0.4 + 0.5×0.1 = 0.17 → 推荐该文章。
* 为什么重要:掌握余弦相似度,就是掌握了**连接数据与智能的钥匙**!

#### 科学计算核心库NumPy和推荐系统案例
* 什么是 NumPy?
* NumPy(Numerical Python)是 Python 的科学计算核心库,专门处理多维数组(矩阵)的高效运算。
* 核心功能:提供高性能的数组对象 ndarray,支持向量化操作(无需循环直接计算)。
* 江湖地位:几乎所有 Python 科学计算库(如 Pandas、SciPy、TensorFlow)都依赖 NumPy。
* 设计目标:用简洁的语法替代传统循环,提升大规模数据计算效率。
* 为什么需要 NumPy?对比原生 Python
* 原生 Python 列表的痛点
```python
# 计算两个列表元素相加
a = [1, 2, 3]
b = [4, 5, 6]
result = [a[i] + b[i] for i in range(len(a))] # 需要循环逐个计算
```
* NumPy 的解决方案
```python
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
result = a + b # 直接向量化运算 → 输出 [5,7,9]
```
* 性能对比(关键优势)
| 操作类型 | Python 列表耗时 | NumPy 耗时 | 速度提升倍数 |
| :------------ | :--------------- | :--------- | :----------- |
| 100万元素求和 | 15 ms | 0.5 ms | **30倍** |
| 矩阵乘法 | 手动循环实现复杂 | 单行代码 | **100倍+** |
* 基础安装
```python
# 常规安装
pip install numpy
# 验证安装, 应输出版本号
python -c "import numpy as np; print(np.__version__)"
# 升级版本
pip install numpy --upgrade
```
* 余弦相似度案例实战
* 案例1:基础向量计算
```python
import numpy as np
def cos_sim(v1, v2):
"""
计算两个向量的余弦相似度
余弦相似度用于衡量两个向量方向的相似性,结果范围从-1到1
-1表示完全相反,1表示完全相同,0表示两者正交(即无相似性)
参数:
v1: numpy数组,第一个向量
v2: numpy数组,第二个向量
返回:
两个向量的余弦相似度
"""
# 计算向量点积
dot = np.dot(v1, v2)
# 计算向量的模的乘积
norm = np.linalg.norm(v1) * np.linalg.norm(v2)
# 返回余弦相似度
return dot / norm
# 测试向量(支持任意维度)
vec_a = np.array([0.2, 0.5, 0.8]) # 文本A的嵌入向量
vec_b = np.array([0.3, 0.6, 0.7]) # 文本B的嵌入向量
# 输出两向量的余弦相似度
print(f"相似度:{cos_sim(vec_a, vec_b):.4f}") # 输出:0.9943
```
* 案例2:推荐系统
```python
import numpy as np
def cosine_similarity(a, b):
# 将列表转换为NumPy数组
a = np.array(a)
b = np.array(b)
# 计算点积
dot_product = np.dot(a, b)
# 计算模长
norm_a = np.linalg.norm(a)
norm_b = np.linalg.norm(b)
# 计算余弦相似度
return dot_product / (norm_a * norm_b) if norm_a * norm_b != 0 else 0
# 用户嵌入向量(根据浏览行为生成)
user_embedding = [0.7, -0.2, 0.5, 0.1]
# 商品嵌入库
products = {
"item1": [0.6, -0.3, 0.5, 0.2],
"item2": [0.8, 0.1, 0.4, -0.1],
"item3": [-0.5, 0.7, 0.2, 0.3]
}
# 计算相似度并推荐
recommendations = []
for item_id, vec in products.items():
sim = cosine_similarity(user_embedding, vec)
recommendations.append((item_id, round(sim, 3))) # 保留3位小数
# 按相似度降序排序
recommendations.sort(key=lambda x: x[1], reverse=True)
print("推荐排序:", recommendations)
```
### RAG系统必备之嵌入大模型Embedding
#### 嵌入大模型Embedding和LLM大模型对比
* 什么是文本嵌入Text Embedding
* 文本嵌入(Text Embedding)是将文本(单词、短语、句子或文档)映射到高维向量空间的技术。
* 类比
* 假设你是一个Java工程师,现在需要将一段文字(比如用户评论)存入数据库。
* 传统方式可能是存字符串,但计算机无法直接“理解”语义。
* Embedding的作用
* 把文字转换成一个固定长度的数字数组(向量),比如 `[0.2, -0.5, 0.8, ...]`,这个数组能“编码”文字的含义。
* 想象每个词或句子是一个点,而Embedding就是给这些点在地图上标坐标。
* 语义相近的词(如“猫”和“狗”)坐标距离近,无关的词(如“猫”和“汽车”)坐标距离远。
* **通俗来说**
* 将不可计算、非结构化 的词 转化为 可计算,结构化的 向量,把文字变成一串有含义的数字密码
* 就像给每个句子/词语颁发"数字身份证"。这个身份证号码能表达文字的**核心含义**
* 例:"猫" → [0.2, -0.5, 0.8,...](300个数字组成的向量)
* 核心特点
* **语义感知**:相似的文字数字也相似
```python
# "狗"和"犬"的嵌入向量距离近
# "苹果"(水果)和"苹果"(手机)的嵌入距离远
```
* 降维表示:将离散的文本转化为连续的向量
* 维度固定:无论输入多长,同个嵌入大模型 输出数字个数相同(如384/768维)
* 案例【采用二维方式,正常的向量化后都是上千个维度】
* 句子
* 句子1:老王喜欢吃香蕉
* 句子2:冰冰喜欢吃苹果
* 句子3:老帆在打篮球
* 向量化后续图形表示【二维】
* 句子1和2相近,因为维度大体相同
* 大模型中的核心应用场景
* 语义搜索(Semantic Search)
* 问题:用户输入自然语言query,找到最相关的文档。
* 实现步骤:
* 将query和所有文档编码为向量。
* 计算query向量与文档向量的余弦相似度。
* 返回Top-K相似度最高的文档。
* 推荐系统(User-Item Matching)
* 原理:用户向量和物品向量的余弦相似度 → 推荐得分。
* 示例:
* 用户向量:[0.3, 0.5, -0.2](表示对科技、体育、艺术的兴趣)
* 物品向量:[0.4, 0.1, 0.0](科技类文章)
* 相似度 ≈ 0.3×0.4 + 0.5×0.1 = 0.17 → 推荐该文章。
* 为什么重要:掌握余弦相似度,就是掌握了**连接数据与智能的钥匙**!

#### 科学计算核心库NumPy和推荐系统案例
* 什么是 NumPy?
* NumPy(Numerical Python)是 Python 的科学计算核心库,专门处理多维数组(矩阵)的高效运算。
* 核心功能:提供高性能的数组对象 ndarray,支持向量化操作(无需循环直接计算)。
* 江湖地位:几乎所有 Python 科学计算库(如 Pandas、SciPy、TensorFlow)都依赖 NumPy。
* 设计目标:用简洁的语法替代传统循环,提升大规模数据计算效率。
* 为什么需要 NumPy?对比原生 Python
* 原生 Python 列表的痛点
```python
# 计算两个列表元素相加
a = [1, 2, 3]
b = [4, 5, 6]
result = [a[i] + b[i] for i in range(len(a))] # 需要循环逐个计算
```
* NumPy 的解决方案
```python
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
result = a + b # 直接向量化运算 → 输出 [5,7,9]
```
* 性能对比(关键优势)
| 操作类型 | Python 列表耗时 | NumPy 耗时 | 速度提升倍数 |
| :------------ | :--------------- | :--------- | :----------- |
| 100万元素求和 | 15 ms | 0.5 ms | **30倍** |
| 矩阵乘法 | 手动循环实现复杂 | 单行代码 | **100倍+** |
* 基础安装
```python
# 常规安装
pip install numpy
# 验证安装, 应输出版本号
python -c "import numpy as np; print(np.__version__)"
# 升级版本
pip install numpy --upgrade
```
* 余弦相似度案例实战
* 案例1:基础向量计算
```python
import numpy as np
def cos_sim(v1, v2):
"""
计算两个向量的余弦相似度
余弦相似度用于衡量两个向量方向的相似性,结果范围从-1到1
-1表示完全相反,1表示完全相同,0表示两者正交(即无相似性)
参数:
v1: numpy数组,第一个向量
v2: numpy数组,第二个向量
返回:
两个向量的余弦相似度
"""
# 计算向量点积
dot = np.dot(v1, v2)
# 计算向量的模的乘积
norm = np.linalg.norm(v1) * np.linalg.norm(v2)
# 返回余弦相似度
return dot / norm
# 测试向量(支持任意维度)
vec_a = np.array([0.2, 0.5, 0.8]) # 文本A的嵌入向量
vec_b = np.array([0.3, 0.6, 0.7]) # 文本B的嵌入向量
# 输出两向量的余弦相似度
print(f"相似度:{cos_sim(vec_a, vec_b):.4f}") # 输出:0.9943
```
* 案例2:推荐系统
```python
import numpy as np
def cosine_similarity(a, b):
# 将列表转换为NumPy数组
a = np.array(a)
b = np.array(b)
# 计算点积
dot_product = np.dot(a, b)
# 计算模长
norm_a = np.linalg.norm(a)
norm_b = np.linalg.norm(b)
# 计算余弦相似度
return dot_product / (norm_a * norm_b) if norm_a * norm_b != 0 else 0
# 用户嵌入向量(根据浏览行为生成)
user_embedding = [0.7, -0.2, 0.5, 0.1]
# 商品嵌入库
products = {
"item1": [0.6, -0.3, 0.5, 0.2],
"item2": [0.8, 0.1, 0.4, -0.1],
"item3": [-0.5, 0.7, 0.2, 0.3]
}
# 计算相似度并推荐
recommendations = []
for item_id, vec in products.items():
sim = cosine_similarity(user_embedding, vec)
recommendations.append((item_id, round(sim, 3))) # 保留3位小数
# 按相似度降序排序
recommendations.sort(key=lambda x: x[1], reverse=True)
print("推荐排序:", recommendations)
```
### RAG系统必备之嵌入大模型Embedding
#### 嵌入大模型Embedding和LLM大模型对比
* 什么是文本嵌入Text Embedding
* 文本嵌入(Text Embedding)是将文本(单词、短语、句子或文档)映射到高维向量空间的技术。
* 类比
* 假设你是一个Java工程师,现在需要将一段文字(比如用户评论)存入数据库。
* 传统方式可能是存字符串,但计算机无法直接“理解”语义。
* Embedding的作用
* 把文字转换成一个固定长度的数字数组(向量),比如 `[0.2, -0.5, 0.8, ...]`,这个数组能“编码”文字的含义。
* 想象每个词或句子是一个点,而Embedding就是给这些点在地图上标坐标。
* 语义相近的词(如“猫”和“狗”)坐标距离近,无关的词(如“猫”和“汽车”)坐标距离远。
* **通俗来说**
* 将不可计算、非结构化 的词 转化为 可计算,结构化的 向量,把文字变成一串有含义的数字密码
* 就像给每个句子/词语颁发"数字身份证"。这个身份证号码能表达文字的**核心含义**
* 例:"猫" → [0.2, -0.5, 0.8,...](300个数字组成的向量)
* 核心特点
* **语义感知**:相似的文字数字也相似
```python
# "狗"和"犬"的嵌入向量距离近
# "苹果"(水果)和"苹果"(手机)的嵌入距离远
```
* 降维表示:将离散的文本转化为连续的向量
* 维度固定:无论输入多长,同个嵌入大模型 输出数字个数相同(如384/768维)
* 案例【采用二维方式,正常的向量化后都是上千个维度】
* 句子
* 句子1:老王喜欢吃香蕉
* 句子2:冰冰喜欢吃苹果
* 句子3:老帆在打篮球
* 向量化后续图形表示【二维】
* 句子1和2相近,因为维度大体相同
 * 应用场景
* 语义搜索: 找含义相近的内容,不依赖关键词匹配
```
# 搜索"如何养小猫咪" → 匹配到"幼猫护理指南"
```
* 智能分类:自动识别用户评论的情绪/类型
* 问答系统:快速找到与问题最相关的答案段落
* 什么是嵌入Embedding大模型
* Embedding 模型的主要任务是将文本转换为数值向量表示
* 这些向量可以用于计算文本之间的相似度、进行信息检索和聚类分析
* 文本嵌入的整体链路 `原始文本 → Embedding模型 → 数值向量 → 存储/比较`
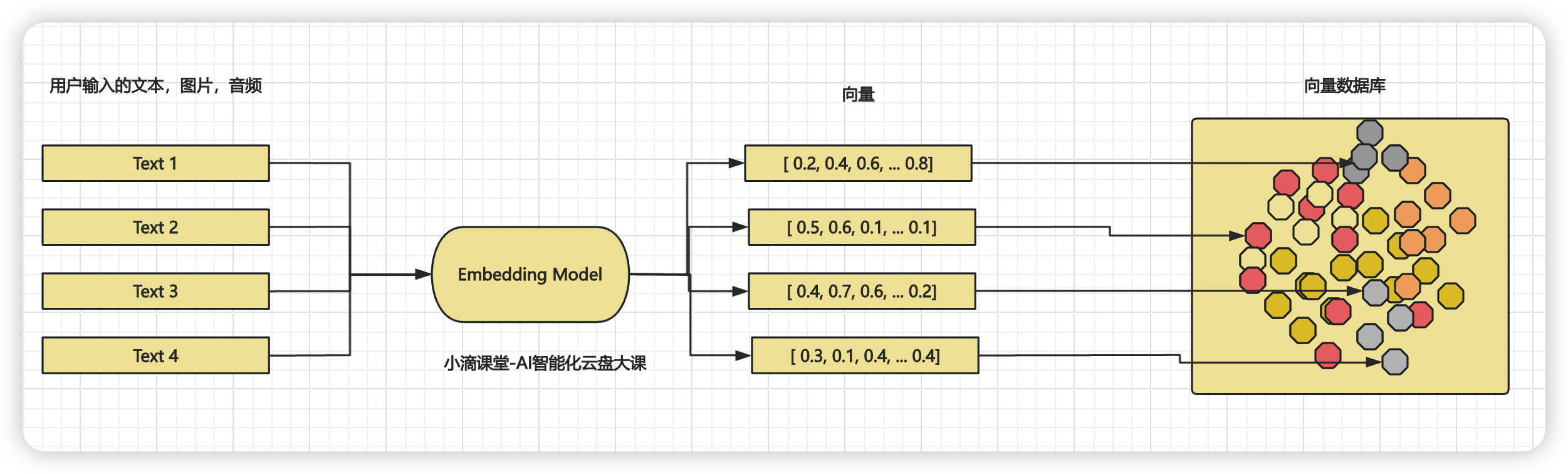
* LLM 大模型 vs Embedding 大模型
| 维度 | LLM (如GPT-4、Claude) | Embedding 模型 (如BERT、text-embedding-3) |
| :----------: | :------------------------: | :---------------------------------------: |
| **核心能力** | 理解并生成人类语言 | 将文本转化为数学向量 |
| **输出形式** | 自然文本(对话/文章/代码) | 数值向量(如1536维浮点数) |
| **典型交互** | 多轮对话、持续创作 | 单次转换、批量处理 |
* 关键联系
* 数据基础相同:
* 都通过海量文本训练,理解语言规律
* 就像作家和图书管理员都读过很多书
* 协作关系
* 常组合使用,Embedding快速筛选相关信息,LLM精细加工生成最终结果
* 就像先让图书管理员找到资料,再让作家整理成报告
* 常见误区
* ❌ 误区1:"Embedding是简化版LLM"→ 其实它们是不同工种,就像厨师和营养师的关系
* ❌ 误区2:"LLM可以直接做Embedding的事"→ 虽然理论上可以,但就像用跑车送外卖——又贵又慢
* ❌ 误区3:"Embedding模型不需要训练"→ 好的Embedding也需要大量训练,就像图书管理员需要学习分类方法
* 一句话总结
* LLM是内容生产者,Embedding是内容组织者
* 它们就像餐厅里的厨师和配菜员,一个负责烹饪(生成内容),一个负责准备食材(组织信息)
* 组合应用场景
* 场景1:智能客服系统
* Embedding:把用户问题"我的订单怎么还没到?"转换成向量,快速匹配知识库中相似问题
* LLM:根据匹配到的问题模板,生成具体回答:"您的订单已发货,预计明天送达"
* 场景2:论文查重
* Embedding:把论文段落转为向量,计算与数据库的相似度
* LLM:若发现高相似度,自动改写重复段落并给出修改建议
#### LangChain框架文本嵌入Embedding实战
* LangChain框架中的Embedding
* 通过标准化接口集成了多种嵌入模型,支持开发者灵活调用
* **功能**:对接各类文本嵌入模型的标准化接口
* **作用**:将文本转换为向量,供后续检索/比较使用
* **类比**:不同品牌手机充电器 → LangChain是万能充电头
* 源码查看
```python
from langchain.embeddings import OpenAIEmbeddings
from abc import ABC, abstractmethod
from langchain_core.runnables.config import run_in_executor
class Embeddings(ABC):
@abstractmethod
def embed_documents(self, texts: list[str]) -> list[list[float]]:
"""Embed search docs.
Args:
texts: List of text to embed.
Returns:
List of embeddings.
"""
@abstractmethod
def embed_query(self, text: str) -> list[float]:
"""Embed query text.
Args:
text: Text to embed.
Returns:
Embedding.
"""
```
* 支持的嵌入模型类型【不同嵌入模型维度和精度不一样】
| 类型 | 代表模型 | 特点 |
| :------------: | :-----------------------------: | :--------------------: |
| 云端API | OpenAI, Cohere, HuggingFace Hub | 无需本地资源,按量付费 |
| 本地开源模型 | Sentence-Transformers, FastText | 数据隐私高,可离线运行 |
| 自定义微调模型 | 用户自行训练的模型 | 领域适配性强 |
* 核心API与属性
| 方法 | 作用 | 示例场景 |
| :----------------------: | :----------------------------: | :----------------: |
| `embed_query(text)` | 对单个文本生成向量 | 用户提问的实时嵌入 |
| `embed_documents(texts)` | 批量处理多个文本,返回向量列表 | 处理数据库文档 |
| `max_retries` | 失败请求重试次数 | 应对API不稳定 |
| `request_timeout` | 单次请求超时时间(秒) | 控制长文本处理时间 |
* 案例实战
* 在线嵌入模型使用,也可以使用其他的厂商
* 地址:https://bailian.console.aliyun.com/
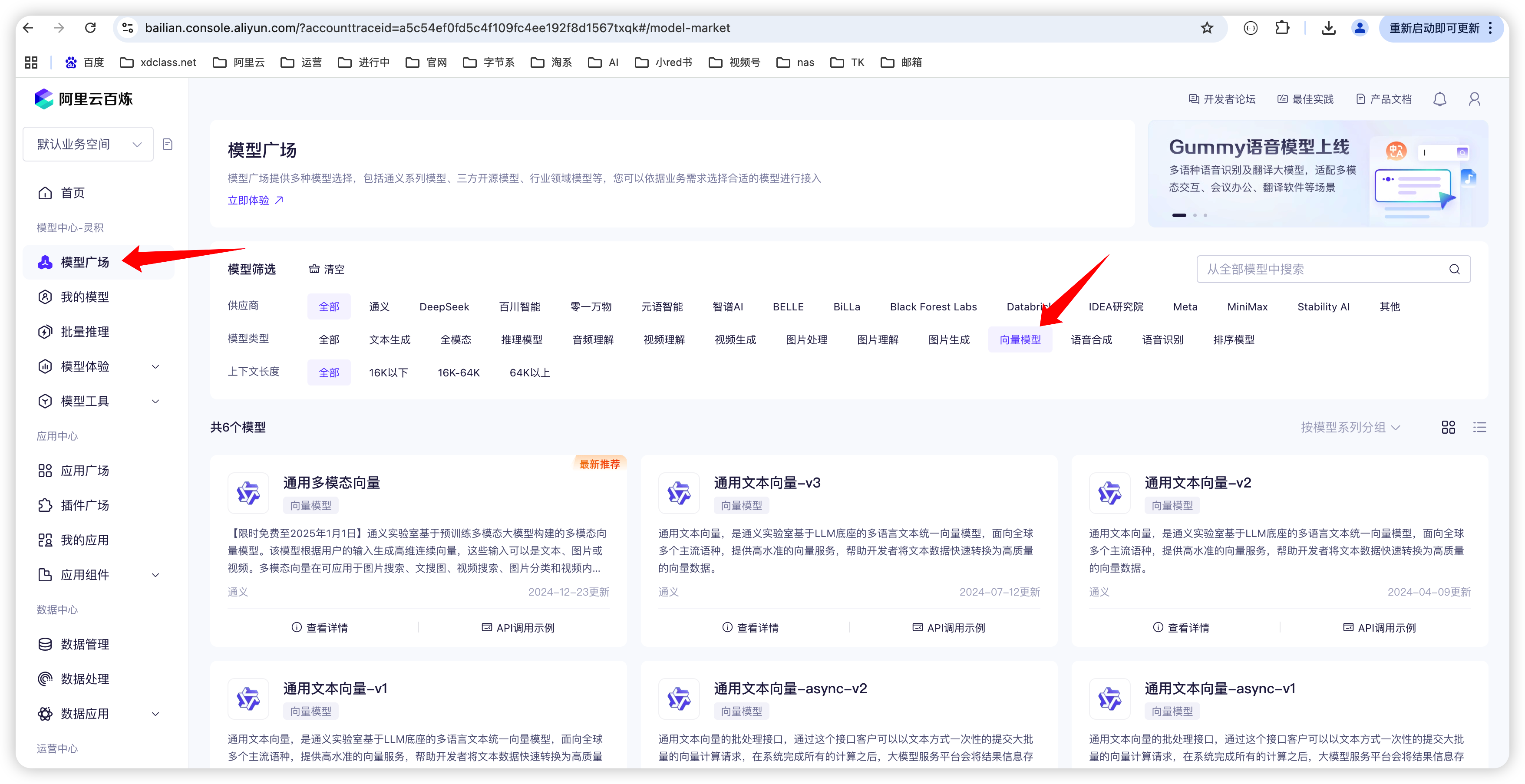
```python
from langchain_community.embeddings import DashScopeEmbeddings
# 初始化模型
ali_embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
# 分析商品评论情感倾向
comments = [
"衣服质量很好,但是物流太慢了",
"性价比超高,会回购!",
"尺寸偏小,建议买大一号"
]
# 生成嵌入向量
embeddings = ali_embeddings.embed_documents(comments)
print(embeddings)
print(len(embeddings)) # 5
print(len(embeddings[0])) # 1536
```
#### 本地私有化部署嵌入大模型Embedding实战
* 为什么要本地部署嵌入大模型
* **对比云端风险**:第三方API可能造成数据泄露(如某云服务商API密钥泄露事件)
| 需求类型 | 典型场景 | 案例说明 |
| :------------: | :----------------: | :------------------------------: |
| **数据安全** | 政府/金融/医疗行业 | 医院病历分析需符合《数据安全法》 |
| **定制化需求** | 垂直领域术语适配 | 法律文书嵌入需理解专业法条词汇 |
| **成本控制** | 长期高频使用场景 | 电商评论分析每日百万次调用 |
| **网络限制** | 内网隔离环境 | 军工企业研发内部知识库 |
* 本地部署嵌入大模型数据闭环
```
用户数据 → 企业内网服务器 → 本地模型处理 → 结果存于本地数据库
```

* 部署实战
* 使用ollama下载嵌入大模型
* 地址:https://ollama.com/search?c=embed
```python
#下载嵌入模型
ollama run mofanke/acge_text_embedding
# 后台启动服务(默认端口11434)
ollama serve &
#查看运行的模型
ollama ps
```
* 嵌入模型请求测试
```
curl http://localhost:11434/api/embeddings -d '{"model": "mofanke/acge_text_embedding", "prompt": "小滴课堂AI大模型课程"}'
```
* 编码实战
* 由于 LangChain 0.3.x 尚未原生支持 Ollama 嵌入模型,需自定义接口类
* `pip install requests`
```python
from typing import List, Optional
from langchain.embeddings.base import Embeddings
import requests
class OllamaEmbeddings(Embeddings):
def __init__(self, model: str = "llama2", base_url: str = "http://localhost:11434"):
self.model = model
self.base_url = base_url
def _embed(self, text: str) -> List[float]:
try:
response = requests.post(
f"{self.base_url}/api/embeddings",
json={
"model": self.model,
"prompt": text # 注意:某些模型可能需要调整参数名(如"prompt"或"text")
}
)
response.raise_for_status()
return response.json().get("embedding", [])
except Exception as e:
raise ValueError(f"Ollama embedding error: {str(e)}")
def embed_query(self, text: str) -> List[float]:
return self._embed(text)
def embed_documents(self, texts: List[str]) -> List[List[float]]:
return [self._embed(text) for text in texts]
```
* 使用自定义嵌入模型处理文档
```python
embeddings = OllamaEmbeddings(
model="mofanke/acge_text_embedding",
base_url="http://localhost:11434"
)
# 分析商品评论情感倾向
comments = [
"衣服质量很好,但是物流太慢了",
"性价比超高,会回购!",
"尺寸偏小,建议买大一号"
]
# 生成嵌入向量
embeddings = embeddings.embed_documents(comments)
print(embeddings)
print(len(embeddings)) # 3
print(len(embeddings[0])) # 1024
```
#### 【面试题】RAG系统构建之嵌入模型性能优化
* 需求背景(面试高频题目)
* 嵌入计算的痛点
* 嵌入生成成本高:每次调用模型API都需要计算资源
* 重复计算浪费:相同文本多次生成嵌入浪费资源
* API调用限制:商业API有调用次数限制和成本
* 响应速度瓶颈:实时场景需要快速响应
* 解决方案:缓存
* 降低计算成本:相同文本只需计算一次
* 提升响应速度:缓存读取比模型计算快10-100倍
* 突破API限制:本地缓存不受远程API配额限制
* 支持离线场景:网络不可用时仍能获取历史嵌入
* `CacheBackedEmbeddings` 介绍
* 技术架构图
```python
[应用程序] → 检查缓存 → 命中 → 返回缓存嵌入
↓
未命中 → 调用模型 → 存储结果 → 返回新嵌入
```
* 是LangChain提供的缓存装饰器,支持 本地文件系统、Redis、数据库等存储方式,自动哈希文本生成唯一缓存键
```
from langchain.embeddings import CacheBackedEmbeddings
```
* 核心语法与参数
```python
from langchain.storage import LocalFileStore
from langchain.embeddings import CacheBackedEmbeddings
# 初始化
cache = CacheBackedEmbeddings(
underlying_embeddings=embedding_model, # 原始嵌入模型
document_embedding_store=storage, # 缓存存储对象
namespace="custom_namespace" # 可选命名空间(隔离不同项目)
)
```
| 参数 | 类型 | 作用 |
| :------------------------: | :--------: | :--------------------------------: |
| `underlying_embeddings` | Embeddings | 原始嵌入模型(如OpenAIEmbeddings) |
| `document_embedding_store` | BaseStore | 缓存存储实现类(如LocalFileStore) |
| `namespace` | str | 缓存命名空间(避免键冲突) |
* 存储支持多类型
```python
#这个包里面
from langchain.storage
__all__ = [
"create_kv_docstore",
"create_lc_store",
"EncoderBackedStore",
"InMemoryByteStore",
"InMemoryStore",
"InvalidKeyException",
"LocalFileStore",
"RedisStore",
"UpstashRedisByteStore",
"UpstashRedisStore",
]
```
* 应用案例:智能客服知识库加速
* 场景需求
* 知识库包含10万条QA对
* 每次用户提问需要检索最相关答案
* 传统方式每次请求都要计算所有问题嵌入
* 缓存方案
* 首次加载时全量预计算并缓存
* 后续请求直接读取缓存
* 新增问题时动态更新缓存
* 代码案例
* 基础版本(无缓存)
```python
from langchain.embeddings import OpenAIEmbeddings
# 初始化模型
embedder = OpenAIEmbeddings(openai_api_key="sk-xxx")
# 生成嵌入
vector = embedder.embed_documents("如何重置密码?")
print(f"向量维度:{len(vector)}")
```
* 带缓存版本
```python
from langchain.storage import LocalFileStore
from langchain.embeddings import CacheBackedEmbeddings
# 创建文件缓存
fs = LocalFileStore("./embedding_cache/")
# 组合缓存与模型(Java的装饰器模式模式类似)
cached_embedder = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings=embedder,
document_embedding_store=fs,
namespace="openai-embeddings" # 区分不同模型版本
)
# 首次调用(写入缓存)
vector1 = cached_embedder.embed_documents("如何重置密码?")
# 二次调用(读取缓存)
vector2 = cached_embedder.embed_documents("如何重置密码?")
print(f"结果一致性:{vector1 == vector2}") # 输出True
```
* 高级配置示例(分布式案例-存储Redis)
```python
# 带TTL的Redis缓存
from redis import Redis
from langchain.storage import RedisStore
redis_client = Redis(host="localhost", port=6379)
redis_store = RedisStore(redis_client, ttl=86400) # 24小时过期
cached_embedder = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings=embedder,
document_embedding_store=redis_store,
namespace="openai-v3"
)
```
#### 嵌入大模型CacheBackedEmbeddings案例实战
* **案例实战:对比嵌入大模型使用缓存前后性能区别**
* 注意:API设计区别
* `embed_documents`:面向批量文档预处理(适合缓存)
* `embed_query`:面向实时查询处理(默认不缓存)
* 设计考量因素
| 维度 | `embed_documents` | `embed_query` |
| :------: | :--------------------------------: | :------------------------------: |
| 使用场景 | 预处理大量重复文档(如知识库构建) | 实时响应用户查询 |
| 数据特征 | 高重复率(法律条款、产品描述) | 低重复率(用户提问多样化) |
| 性能损耗 | 批量处理可分摊缓存读写开销 | 单次查询增加延迟(缓存命中率低) |
| 存储效率 | 缓存大量重复文本收益显著 | 缓存大量唯一查询浪费资源 |
* 编码实战
```python
from langchain.embeddings import CacheBackedEmbeddings
# 已被弃用,需改为从 langchain_community.embeddings 导入
# from langchain.embeddings import DashScopeEmbeddings
from langchain_community.embeddings import DashScopeEmbeddings
import time
# 初始化模型和缓存
from langchain.storage import LocalFileStore
# 初始化模型
embedding_model = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
storage = LocalFileStore("./embedding_cache/") # 本地缓存目录
cached_embeddings = CacheBackedEmbeddings.from_bytes_store(
embedding_model,
storage,
namespace="openai_emb" # 命名空间隔离不同模型
)
texts = ["小滴课堂AI大模型开发实战", "小滴课堂AI大模型开发实战"] # 故意重复
start_time = time.time()
# 第一次调用(写入缓存)
emb1 = cached_embeddings.embed_documents(texts)
print(f"首次调用嵌入维度: {len(emb1[0])}")
embedded1_end_time = time.time()
print(f"首次调用耗时: {embedded1_end_time - start_time}")
# 第二次调用(读取缓存)
emb2 = cached_embeddings.embed_documents(texts)
print(f"二次调用结果相等: {emb1 == emb2}")
embedded2_end_time = time.time()
print(f"二次调用耗时: {embedded2_end_time - embedded1_end_time}")
```
* 最佳实践建议
* **适用场景**
- 处理大量重复文本(如商品描述、法律条款)
- 需要控制API调用成本的商业应用
- 本地模型加速重复计算
* **存储选择策略**
| 存储类型 | 优点 | 缺点 | 适用场景 |
| :------------: | :----------------: | :-----------: | :-----------: |
| LocalFileStore | 零配置、易调试 | 不适合分布式 | 本地开发/测试 |
| RedisStore | 高性能、支持分布式 | 需要运维Redis | 生产环境集群 |
| InMemoryStore | 最快速度 | 重启丢失数据 | 临时测试 |
### 大模型必备技术Milvus向量数据库
#### 向量数据库介绍和技术选型思考
* 为什么要用向量数据库,不能用MySQL存储?
* 文档块通过嵌入模型处理后得到对应向量,下一步就是将向量存储到数据库中,方便后续进行检索使用

* 传统数据库的局限性
* **维度灾难**:传统索引(B-Tree/Hash)在100+维度时效率断崖式下降,无法高效处理高维向量(常达768-1536维)
* **相似度计算**:无法高效处理余弦相似度/Euclidean距离等复杂运算
* **实时性要求**:亿级向量场景下传统方案响应延迟高达秒级,暴力搜索时间复杂度O(N)
```python
// 传统关系型数据库查询(精确匹配)
SELECT * FROM products WHERE category = 'electronics';
// 向量数据库查询(相似度匹配)
Find top5 similar_products where description ≈ '高性能游戏本'
```
* 向量数据库的核心能力
* **相似性搜索**:余弦相似度/欧式距离
* **混合查询**:向量搜索 + 传统条件过滤
* **动态扩展**:支持实时数据更新
* **高效存储**:压缩向量存储技术
* 向量数据库典型应用场景
| 场景 | 案例 | 核心需求 |
| :--------: | :-------------: | :------------: |
| 推荐系统 | 电商商品推荐 | 高并发低延迟 |
| 语义搜索 | 法律条文检索 | 高精度召回 |
| AI代理记忆 | GPT长期记忆存储 | 快速上下文检索 |
| 图像检索 | 以图搜图系统 | 多模态支持 |
* 主流的向量数据库介绍
* 开源向量数据库
* **Milvus**
- **核心优势**:分布式架构支持千亿级向量规模,QPS超百万级,提供HNSW、IVF-PQ等多样化索引算法,支持高并发场景如金融风控、生物医药分子库检索。
- **优点**:高扩展性、多租户支持、完整的API生态(Python/Java/Go等)。
- **缺点**:部署复杂度高,运维成本较大,适合有专业团队的企业。
* **Qdrant**
- **核心优势**:基于Rust开发,支持稀疏向量检索(速度提升16倍),内置标量量化和产品量化技术优化存储效率,适合电商推荐、广告投放等高并发场景。
- **优点**:高性能过滤、云原生设计,支持地理空间和混合数据类型。
- **缺点**:社区生态较新,文档和案例相对较少。
* 云原生服务
* **Pinecone**
- **核心优势**:全托管服务,实时数据更新延迟低于100ms,支持Serverless计费(按查询付费),适合SaaS快速集成和中小型企业。
- **优点**:零运维、低延迟、无缝集成LangChain生态。
- **缺点**:成本较高,大规模数据场景费用显著。
* **腾讯云VectorDB**
- **核心优势**:国产化方案,单索引支持千亿向量,集成AI套件实现文档自动向量化,适合政务、金融等数据主权敏感场景。
- **优点**:端到端RAG解决方案,与腾讯云生态深度整合。
- **缺点**:依赖腾讯云生态,跨云部署受限。
* 轻量级工具
* **Chroma**
- **核心优势**:没有深厚数据库背景的开发者也能快速上手,5分钟完成单机部署,适合学术研究、初创团队验证。
- **优点**:开发友好、快速原型验证,支持LangChain集成。
- **缺点**:不适合生产级大规模应用,功能有限。
* **Faiss**
- **核心优势**:Meta开源的GPU加速检索库,百万级向量查询延迟低于10ms,常作为其他数据库的底层引擎。
- **优点**:性能标杆、算法丰富,支持混合检索架构。
- **缺点**:无托管服务,需自行处理分布式与高可用性。
* 传统数据库扩展
* **MongoDB Atlas**
- **核心优势**:文档数据库嵌入向量索引,支持每个文档存储16MB向量数据,适合已有MongoDB基础设施的企业智能化升级。
- **优点**:事务处理与向量检索一体化,兼容现有业务逻辑。
- **缺点**:向量检索性能弱于专用数据库,扩展性受限。
* 其他:PostgreSQL、ElasticSearch等
* 综合选型对比
| 维度\产品 | Pinecone | Milvus | Qdrant | Chroma |
| :----------: | :--------: | :-----------: | :-----------: | :------: |
| **部署模式** | 全托管 | 自建/云 | 自建/云 | 嵌入式 |
| **学习曲线** | 简单 | 复杂 | 中等 | 极简 |
| **扩展能力** | 自动扩展 | 手动分片 | 自动分片 | 单机 |
| **典型场景** | 生产级SaaS | 企业私有云 | 高性能需求 | 本地开发 |
| **成本模型** | 按用量付费 | 基础设施+运维 | 基础设施+运维 | 免费 |
* 技术选型建议
* **数据规模**
- **十亿级以上**:选择Milvus、腾讯云VectorDB等分布式方案。
- **百万级以下**:轻量级工具如Chroma或Faiss。
* **部署复杂度**
- **云服务优先**:中小企业选Pinecone或腾讯云VectorDB,省去运维成本。
- **私有化部署**:大型企业选Milvus、Qdrant,需专业团队支持。
* **成本考量**
- **开源方案**:Milvus、Qdrant适合长期可控成本。
- **按需付费**:小规模试用选Pinecone Serverless。
* **生态兼容性**
- **国产化需求**:腾讯云VectorDB或华为云等国产方案。
- **现有技术栈**:PostgreSQL/MongoDB扩展适合渐进式改造。
* **总结(花钱的多数更轻松方便)**
* 向量数据库的选择需结合数据规模、业务场景、团队能力和成本预算综合评估。
* 对于AI驱动的应用(如RAG、多模态搜索),建议优先考虑云原生或分布式开源方案(如Milvus、Pinecone);
* 传统业务系统可尝试数据库扩展插件以降低迁移成本,具体案例可参考各数据库的官方文档
#### 向量数据库Milvus介绍和架构讲解
* 什么是Milvus向量数据库
* 地址:https://milvus.io/
* 一种高性能、高扩展性的向量数据库,可在从笔记本电脑到大规模分布式系统等各种环境中高效运行。
* 可以开源软件的形式提供,也可以云服务的形式提供
* 核心能力:高性能、可扩展、低延迟,支持多种相似度计算方式(如欧氏距离、余弦相似度)。
| 维度 | 指标/能力 |
| :--------: | :-----------------------------------------: |
| 数据规模 | 支持**千亿级向量**,PB级存储 |
| 查询性能 | 亿级向量**亚秒级响应**(GPU加速) |
| 扩展性 | 水平扩展,支持**动态增删节点** |
| 查询类型 | 相似度搜索、混合查询、多向量联合查询 |
| 生态兼容性 | 支持Python/Java/Go/REST API,整合主流AI框架 |
* 适用场景:推荐系统、图像检索、自然语言处理(NLP)等
* 全球大厂使用者

* 支持部署的架构
* Milvus提供多种部署选项,包括本地部署、Docker、Kubernetes on-premises、云SaaS和面向企业的自带云(BYOC)
* Milvus Lite 是一个 Python 库,轻量级版本,适合在 Jupyter Notebooks 中进行快速原型开发,或在资源有限的边缘设备上运行
* Milvus Standalone 是单机服务器部署,所有组件都捆绑在一个 Docker 镜像中,方便部署
* Milvus Distributed 可部署在 K8S 集群上,采用云原生架构,适合十亿规模甚至更大的场景,该架构可确保关键组件的冗余。
* 应用场景
* 语义搜索: 找含义相近的内容,不依赖关键词匹配
```
# 搜索"如何养小猫咪" → 匹配到"幼猫护理指南"
```
* 智能分类:自动识别用户评论的情绪/类型
* 问答系统:快速找到与问题最相关的答案段落
* 什么是嵌入Embedding大模型
* Embedding 模型的主要任务是将文本转换为数值向量表示
* 这些向量可以用于计算文本之间的相似度、进行信息检索和聚类分析
* 文本嵌入的整体链路 `原始文本 → Embedding模型 → 数值向量 → 存储/比较`

* LLM 大模型 vs Embedding 大模型
| 维度 | LLM (如GPT-4、Claude) | Embedding 模型 (如BERT、text-embedding-3) |
| :----------: | :------------------------: | :---------------------------------------: |
| **核心能力** | 理解并生成人类语言 | 将文本转化为数学向量 |
| **输出形式** | 自然文本(对话/文章/代码) | 数值向量(如1536维浮点数) |
| **典型交互** | 多轮对话、持续创作 | 单次转换、批量处理 |
* 关键联系
* 数据基础相同:
* 都通过海量文本训练,理解语言规律
* 就像作家和图书管理员都读过很多书
* 协作关系
* 常组合使用,Embedding快速筛选相关信息,LLM精细加工生成最终结果
* 就像先让图书管理员找到资料,再让作家整理成报告
* 常见误区
* ❌ 误区1:"Embedding是简化版LLM"→ 其实它们是不同工种,就像厨师和营养师的关系
* ❌ 误区2:"LLM可以直接做Embedding的事"→ 虽然理论上可以,但就像用跑车送外卖——又贵又慢
* ❌ 误区3:"Embedding模型不需要训练"→ 好的Embedding也需要大量训练,就像图书管理员需要学习分类方法
* 一句话总结
* LLM是内容生产者,Embedding是内容组织者
* 它们就像餐厅里的厨师和配菜员,一个负责烹饪(生成内容),一个负责准备食材(组织信息)
* 组合应用场景
* 场景1:智能客服系统
* Embedding:把用户问题"我的订单怎么还没到?"转换成向量,快速匹配知识库中相似问题
* LLM:根据匹配到的问题模板,生成具体回答:"您的订单已发货,预计明天送达"
* 场景2:论文查重
* Embedding:把论文段落转为向量,计算与数据库的相似度
* LLM:若发现高相似度,自动改写重复段落并给出修改建议
#### LangChain框架文本嵌入Embedding实战
* LangChain框架中的Embedding
* 通过标准化接口集成了多种嵌入模型,支持开发者灵活调用
* **功能**:对接各类文本嵌入模型的标准化接口
* **作用**:将文本转换为向量,供后续检索/比较使用
* **类比**:不同品牌手机充电器 → LangChain是万能充电头
* 源码查看
```python
from langchain.embeddings import OpenAIEmbeddings
from abc import ABC, abstractmethod
from langchain_core.runnables.config import run_in_executor
class Embeddings(ABC):
@abstractmethod
def embed_documents(self, texts: list[str]) -> list[list[float]]:
"""Embed search docs.
Args:
texts: List of text to embed.
Returns:
List of embeddings.
"""
@abstractmethod
def embed_query(self, text: str) -> list[float]:
"""Embed query text.
Args:
text: Text to embed.
Returns:
Embedding.
"""
```
* 支持的嵌入模型类型【不同嵌入模型维度和精度不一样】
| 类型 | 代表模型 | 特点 |
| :------------: | :-----------------------------: | :--------------------: |
| 云端API | OpenAI, Cohere, HuggingFace Hub | 无需本地资源,按量付费 |
| 本地开源模型 | Sentence-Transformers, FastText | 数据隐私高,可离线运行 |
| 自定义微调模型 | 用户自行训练的模型 | 领域适配性强 |
* 核心API与属性
| 方法 | 作用 | 示例场景 |
| :----------------------: | :----------------------------: | :----------------: |
| `embed_query(text)` | 对单个文本生成向量 | 用户提问的实时嵌入 |
| `embed_documents(texts)` | 批量处理多个文本,返回向量列表 | 处理数据库文档 |
| `max_retries` | 失败请求重试次数 | 应对API不稳定 |
| `request_timeout` | 单次请求超时时间(秒) | 控制长文本处理时间 |
* 案例实战
* 在线嵌入模型使用,也可以使用其他的厂商
* 地址:https://bailian.console.aliyun.com/

```python
from langchain_community.embeddings import DashScopeEmbeddings
# 初始化模型
ali_embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
# 分析商品评论情感倾向
comments = [
"衣服质量很好,但是物流太慢了",
"性价比超高,会回购!",
"尺寸偏小,建议买大一号"
]
# 生成嵌入向量
embeddings = ali_embeddings.embed_documents(comments)
print(embeddings)
print(len(embeddings)) # 5
print(len(embeddings[0])) # 1536
```
#### 本地私有化部署嵌入大模型Embedding实战
* 为什么要本地部署嵌入大模型
* **对比云端风险**:第三方API可能造成数据泄露(如某云服务商API密钥泄露事件)
| 需求类型 | 典型场景 | 案例说明 |
| :------------: | :----------------: | :------------------------------: |
| **数据安全** | 政府/金融/医疗行业 | 医院病历分析需符合《数据安全法》 |
| **定制化需求** | 垂直领域术语适配 | 法律文书嵌入需理解专业法条词汇 |
| **成本控制** | 长期高频使用场景 | 电商评论分析每日百万次调用 |
| **网络限制** | 内网隔离环境 | 军工企业研发内部知识库 |
* 本地部署嵌入大模型数据闭环
```
用户数据 → 企业内网服务器 → 本地模型处理 → 结果存于本地数据库
```

* 部署实战
* 使用ollama下载嵌入大模型
* 地址:https://ollama.com/search?c=embed
```python
#下载嵌入模型
ollama run mofanke/acge_text_embedding
# 后台启动服务(默认端口11434)
ollama serve &
#查看运行的模型
ollama ps
```
* 嵌入模型请求测试
```
curl http://localhost:11434/api/embeddings -d '{"model": "mofanke/acge_text_embedding", "prompt": "小滴课堂AI大模型课程"}'
```
* 编码实战
* 由于 LangChain 0.3.x 尚未原生支持 Ollama 嵌入模型,需自定义接口类
* `pip install requests`
```python
from typing import List, Optional
from langchain.embeddings.base import Embeddings
import requests
class OllamaEmbeddings(Embeddings):
def __init__(self, model: str = "llama2", base_url: str = "http://localhost:11434"):
self.model = model
self.base_url = base_url
def _embed(self, text: str) -> List[float]:
try:
response = requests.post(
f"{self.base_url}/api/embeddings",
json={
"model": self.model,
"prompt": text # 注意:某些模型可能需要调整参数名(如"prompt"或"text")
}
)
response.raise_for_status()
return response.json().get("embedding", [])
except Exception as e:
raise ValueError(f"Ollama embedding error: {str(e)}")
def embed_query(self, text: str) -> List[float]:
return self._embed(text)
def embed_documents(self, texts: List[str]) -> List[List[float]]:
return [self._embed(text) for text in texts]
```
* 使用自定义嵌入模型处理文档
```python
embeddings = OllamaEmbeddings(
model="mofanke/acge_text_embedding",
base_url="http://localhost:11434"
)
# 分析商品评论情感倾向
comments = [
"衣服质量很好,但是物流太慢了",
"性价比超高,会回购!",
"尺寸偏小,建议买大一号"
]
# 生成嵌入向量
embeddings = embeddings.embed_documents(comments)
print(embeddings)
print(len(embeddings)) # 3
print(len(embeddings[0])) # 1024
```
#### 【面试题】RAG系统构建之嵌入模型性能优化
* 需求背景(面试高频题目)
* 嵌入计算的痛点
* 嵌入生成成本高:每次调用模型API都需要计算资源
* 重复计算浪费:相同文本多次生成嵌入浪费资源
* API调用限制:商业API有调用次数限制和成本
* 响应速度瓶颈:实时场景需要快速响应
* 解决方案:缓存
* 降低计算成本:相同文本只需计算一次
* 提升响应速度:缓存读取比模型计算快10-100倍
* 突破API限制:本地缓存不受远程API配额限制
* 支持离线场景:网络不可用时仍能获取历史嵌入
* `CacheBackedEmbeddings` 介绍
* 技术架构图
```python
[应用程序] → 检查缓存 → 命中 → 返回缓存嵌入
↓
未命中 → 调用模型 → 存储结果 → 返回新嵌入
```
* 是LangChain提供的缓存装饰器,支持 本地文件系统、Redis、数据库等存储方式,自动哈希文本生成唯一缓存键
```
from langchain.embeddings import CacheBackedEmbeddings
```
* 核心语法与参数
```python
from langchain.storage import LocalFileStore
from langchain.embeddings import CacheBackedEmbeddings
# 初始化
cache = CacheBackedEmbeddings(
underlying_embeddings=embedding_model, # 原始嵌入模型
document_embedding_store=storage, # 缓存存储对象
namespace="custom_namespace" # 可选命名空间(隔离不同项目)
)
```
| 参数 | 类型 | 作用 |
| :------------------------: | :--------: | :--------------------------------: |
| `underlying_embeddings` | Embeddings | 原始嵌入模型(如OpenAIEmbeddings) |
| `document_embedding_store` | BaseStore | 缓存存储实现类(如LocalFileStore) |
| `namespace` | str | 缓存命名空间(避免键冲突) |
* 存储支持多类型
```python
#这个包里面
from langchain.storage
__all__ = [
"create_kv_docstore",
"create_lc_store",
"EncoderBackedStore",
"InMemoryByteStore",
"InMemoryStore",
"InvalidKeyException",
"LocalFileStore",
"RedisStore",
"UpstashRedisByteStore",
"UpstashRedisStore",
]
```
* 应用案例:智能客服知识库加速
* 场景需求
* 知识库包含10万条QA对
* 每次用户提问需要检索最相关答案
* 传统方式每次请求都要计算所有问题嵌入
* 缓存方案
* 首次加载时全量预计算并缓存
* 后续请求直接读取缓存
* 新增问题时动态更新缓存
* 代码案例
* 基础版本(无缓存)
```python
from langchain.embeddings import OpenAIEmbeddings
# 初始化模型
embedder = OpenAIEmbeddings(openai_api_key="sk-xxx")
# 生成嵌入
vector = embedder.embed_documents("如何重置密码?")
print(f"向量维度:{len(vector)}")
```
* 带缓存版本
```python
from langchain.storage import LocalFileStore
from langchain.embeddings import CacheBackedEmbeddings
# 创建文件缓存
fs = LocalFileStore("./embedding_cache/")
# 组合缓存与模型(Java的装饰器模式模式类似)
cached_embedder = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings=embedder,
document_embedding_store=fs,
namespace="openai-embeddings" # 区分不同模型版本
)
# 首次调用(写入缓存)
vector1 = cached_embedder.embed_documents("如何重置密码?")
# 二次调用(读取缓存)
vector2 = cached_embedder.embed_documents("如何重置密码?")
print(f"结果一致性:{vector1 == vector2}") # 输出True
```
* 高级配置示例(分布式案例-存储Redis)
```python
# 带TTL的Redis缓存
from redis import Redis
from langchain.storage import RedisStore
redis_client = Redis(host="localhost", port=6379)
redis_store = RedisStore(redis_client, ttl=86400) # 24小时过期
cached_embedder = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings=embedder,
document_embedding_store=redis_store,
namespace="openai-v3"
)
```
#### 嵌入大模型CacheBackedEmbeddings案例实战
* **案例实战:对比嵌入大模型使用缓存前后性能区别**
* 注意:API设计区别
* `embed_documents`:面向批量文档预处理(适合缓存)
* `embed_query`:面向实时查询处理(默认不缓存)
* 设计考量因素
| 维度 | `embed_documents` | `embed_query` |
| :------: | :--------------------------------: | :------------------------------: |
| 使用场景 | 预处理大量重复文档(如知识库构建) | 实时响应用户查询 |
| 数据特征 | 高重复率(法律条款、产品描述) | 低重复率(用户提问多样化) |
| 性能损耗 | 批量处理可分摊缓存读写开销 | 单次查询增加延迟(缓存命中率低) |
| 存储效率 | 缓存大量重复文本收益显著 | 缓存大量唯一查询浪费资源 |
* 编码实战
```python
from langchain.embeddings import CacheBackedEmbeddings
# 已被弃用,需改为从 langchain_community.embeddings 导入
# from langchain.embeddings import DashScopeEmbeddings
from langchain_community.embeddings import DashScopeEmbeddings
import time
# 初始化模型和缓存
from langchain.storage import LocalFileStore
# 初始化模型
embedding_model = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
storage = LocalFileStore("./embedding_cache/") # 本地缓存目录
cached_embeddings = CacheBackedEmbeddings.from_bytes_store(
embedding_model,
storage,
namespace="openai_emb" # 命名空间隔离不同模型
)
texts = ["小滴课堂AI大模型开发实战", "小滴课堂AI大模型开发实战"] # 故意重复
start_time = time.time()
# 第一次调用(写入缓存)
emb1 = cached_embeddings.embed_documents(texts)
print(f"首次调用嵌入维度: {len(emb1[0])}")
embedded1_end_time = time.time()
print(f"首次调用耗时: {embedded1_end_time - start_time}")
# 第二次调用(读取缓存)
emb2 = cached_embeddings.embed_documents(texts)
print(f"二次调用结果相等: {emb1 == emb2}")
embedded2_end_time = time.time()
print(f"二次调用耗时: {embedded2_end_time - embedded1_end_time}")
```
* 最佳实践建议
* **适用场景**
- 处理大量重复文本(如商品描述、法律条款)
- 需要控制API调用成本的商业应用
- 本地模型加速重复计算
* **存储选择策略**
| 存储类型 | 优点 | 缺点 | 适用场景 |
| :------------: | :----------------: | :-----------: | :-----------: |
| LocalFileStore | 零配置、易调试 | 不适合分布式 | 本地开发/测试 |
| RedisStore | 高性能、支持分布式 | 需要运维Redis | 生产环境集群 |
| InMemoryStore | 最快速度 | 重启丢失数据 | 临时测试 |
### 大模型必备技术Milvus向量数据库
#### 向量数据库介绍和技术选型思考
* 为什么要用向量数据库,不能用MySQL存储?
* 文档块通过嵌入模型处理后得到对应向量,下一步就是将向量存储到数据库中,方便后续进行检索使用

* 传统数据库的局限性
* **维度灾难**:传统索引(B-Tree/Hash)在100+维度时效率断崖式下降,无法高效处理高维向量(常达768-1536维)
* **相似度计算**:无法高效处理余弦相似度/Euclidean距离等复杂运算
* **实时性要求**:亿级向量场景下传统方案响应延迟高达秒级,暴力搜索时间复杂度O(N)
```python
// 传统关系型数据库查询(精确匹配)
SELECT * FROM products WHERE category = 'electronics';
// 向量数据库查询(相似度匹配)
Find top5 similar_products where description ≈ '高性能游戏本'
```
* 向量数据库的核心能力
* **相似性搜索**:余弦相似度/欧式距离
* **混合查询**:向量搜索 + 传统条件过滤
* **动态扩展**:支持实时数据更新
* **高效存储**:压缩向量存储技术
* 向量数据库典型应用场景
| 场景 | 案例 | 核心需求 |
| :--------: | :-------------: | :------------: |
| 推荐系统 | 电商商品推荐 | 高并发低延迟 |
| 语义搜索 | 法律条文检索 | 高精度召回 |
| AI代理记忆 | GPT长期记忆存储 | 快速上下文检索 |
| 图像检索 | 以图搜图系统 | 多模态支持 |
* 主流的向量数据库介绍
* 开源向量数据库
* **Milvus**
- **核心优势**:分布式架构支持千亿级向量规模,QPS超百万级,提供HNSW、IVF-PQ等多样化索引算法,支持高并发场景如金融风控、生物医药分子库检索。
- **优点**:高扩展性、多租户支持、完整的API生态(Python/Java/Go等)。
- **缺点**:部署复杂度高,运维成本较大,适合有专业团队的企业。
* **Qdrant**
- **核心优势**:基于Rust开发,支持稀疏向量检索(速度提升16倍),内置标量量化和产品量化技术优化存储效率,适合电商推荐、广告投放等高并发场景。
- **优点**:高性能过滤、云原生设计,支持地理空间和混合数据类型。
- **缺点**:社区生态较新,文档和案例相对较少。
* 云原生服务
* **Pinecone**
- **核心优势**:全托管服务,实时数据更新延迟低于100ms,支持Serverless计费(按查询付费),适合SaaS快速集成和中小型企业。
- **优点**:零运维、低延迟、无缝集成LangChain生态。
- **缺点**:成本较高,大规模数据场景费用显著。
* **腾讯云VectorDB**
- **核心优势**:国产化方案,单索引支持千亿向量,集成AI套件实现文档自动向量化,适合政务、金融等数据主权敏感场景。
- **优点**:端到端RAG解决方案,与腾讯云生态深度整合。
- **缺点**:依赖腾讯云生态,跨云部署受限。
* 轻量级工具
* **Chroma**
- **核心优势**:没有深厚数据库背景的开发者也能快速上手,5分钟完成单机部署,适合学术研究、初创团队验证。
- **优点**:开发友好、快速原型验证,支持LangChain集成。
- **缺点**:不适合生产级大规模应用,功能有限。
* **Faiss**
- **核心优势**:Meta开源的GPU加速检索库,百万级向量查询延迟低于10ms,常作为其他数据库的底层引擎。
- **优点**:性能标杆、算法丰富,支持混合检索架构。
- **缺点**:无托管服务,需自行处理分布式与高可用性。
* 传统数据库扩展
* **MongoDB Atlas**
- **核心优势**:文档数据库嵌入向量索引,支持每个文档存储16MB向量数据,适合已有MongoDB基础设施的企业智能化升级。
- **优点**:事务处理与向量检索一体化,兼容现有业务逻辑。
- **缺点**:向量检索性能弱于专用数据库,扩展性受限。
* 其他:PostgreSQL、ElasticSearch等
* 综合选型对比
| 维度\产品 | Pinecone | Milvus | Qdrant | Chroma |
| :----------: | :--------: | :-----------: | :-----------: | :------: |
| **部署模式** | 全托管 | 自建/云 | 自建/云 | 嵌入式 |
| **学习曲线** | 简单 | 复杂 | 中等 | 极简 |
| **扩展能力** | 自动扩展 | 手动分片 | 自动分片 | 单机 |
| **典型场景** | 生产级SaaS | 企业私有云 | 高性能需求 | 本地开发 |
| **成本模型** | 按用量付费 | 基础设施+运维 | 基础设施+运维 | 免费 |
* 技术选型建议
* **数据规模**
- **十亿级以上**:选择Milvus、腾讯云VectorDB等分布式方案。
- **百万级以下**:轻量级工具如Chroma或Faiss。
* **部署复杂度**
- **云服务优先**:中小企业选Pinecone或腾讯云VectorDB,省去运维成本。
- **私有化部署**:大型企业选Milvus、Qdrant,需专业团队支持。
* **成本考量**
- **开源方案**:Milvus、Qdrant适合长期可控成本。
- **按需付费**:小规模试用选Pinecone Serverless。
* **生态兼容性**
- **国产化需求**:腾讯云VectorDB或华为云等国产方案。
- **现有技术栈**:PostgreSQL/MongoDB扩展适合渐进式改造。
* **总结(花钱的多数更轻松方便)**
* 向量数据库的选择需结合数据规模、业务场景、团队能力和成本预算综合评估。
* 对于AI驱动的应用(如RAG、多模态搜索),建议优先考虑云原生或分布式开源方案(如Milvus、Pinecone);
* 传统业务系统可尝试数据库扩展插件以降低迁移成本,具体案例可参考各数据库的官方文档
#### 向量数据库Milvus介绍和架构讲解
* 什么是Milvus向量数据库
* 地址:https://milvus.io/
* 一种高性能、高扩展性的向量数据库,可在从笔记本电脑到大规模分布式系统等各种环境中高效运行。
* 可以开源软件的形式提供,也可以云服务的形式提供
* 核心能力:高性能、可扩展、低延迟,支持多种相似度计算方式(如欧氏距离、余弦相似度)。
| 维度 | 指标/能力 |
| :--------: | :-----------------------------------------: |
| 数据规模 | 支持**千亿级向量**,PB级存储 |
| 查询性能 | 亿级向量**亚秒级响应**(GPU加速) |
| 扩展性 | 水平扩展,支持**动态增删节点** |
| 查询类型 | 相似度搜索、混合查询、多向量联合查询 |
| 生态兼容性 | 支持Python/Java/Go/REST API,整合主流AI框架 |
* 适用场景:推荐系统、图像检索、自然语言处理(NLP)等
* 全球大厂使用者

* 支持部署的架构
* Milvus提供多种部署选项,包括本地部署、Docker、Kubernetes on-premises、云SaaS和面向企业的自带云(BYOC)
* Milvus Lite 是一个 Python 库,轻量级版本,适合在 Jupyter Notebooks 中进行快速原型开发,或在资源有限的边缘设备上运行
* Milvus Standalone 是单机服务器部署,所有组件都捆绑在一个 Docker 镜像中,方便部署
* Milvus Distributed 可部署在 K8S 集群上,采用云原生架构,适合十亿规模甚至更大的场景,该架构可确保关键组件的冗余。

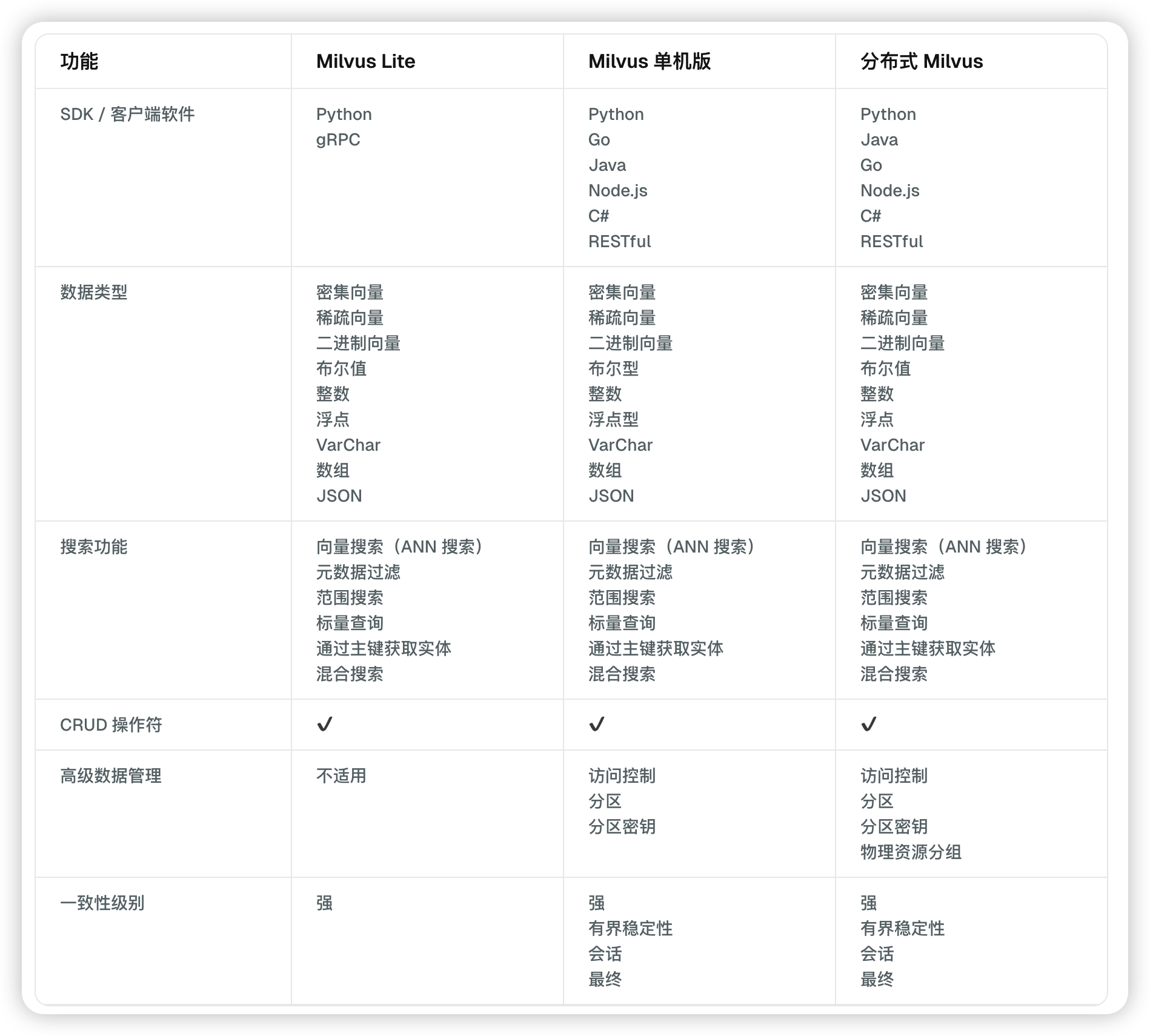 * Milvus 架构解析
* 数据处理流程 :插入数据 → 生成日志 → 持久化到存储层 → 构建索引 → 支持查询。
* Milvus 架构解析
* 数据处理流程 :插入数据 → 生成日志 → 持久化到存储层 → 构建索引 → 支持查询。
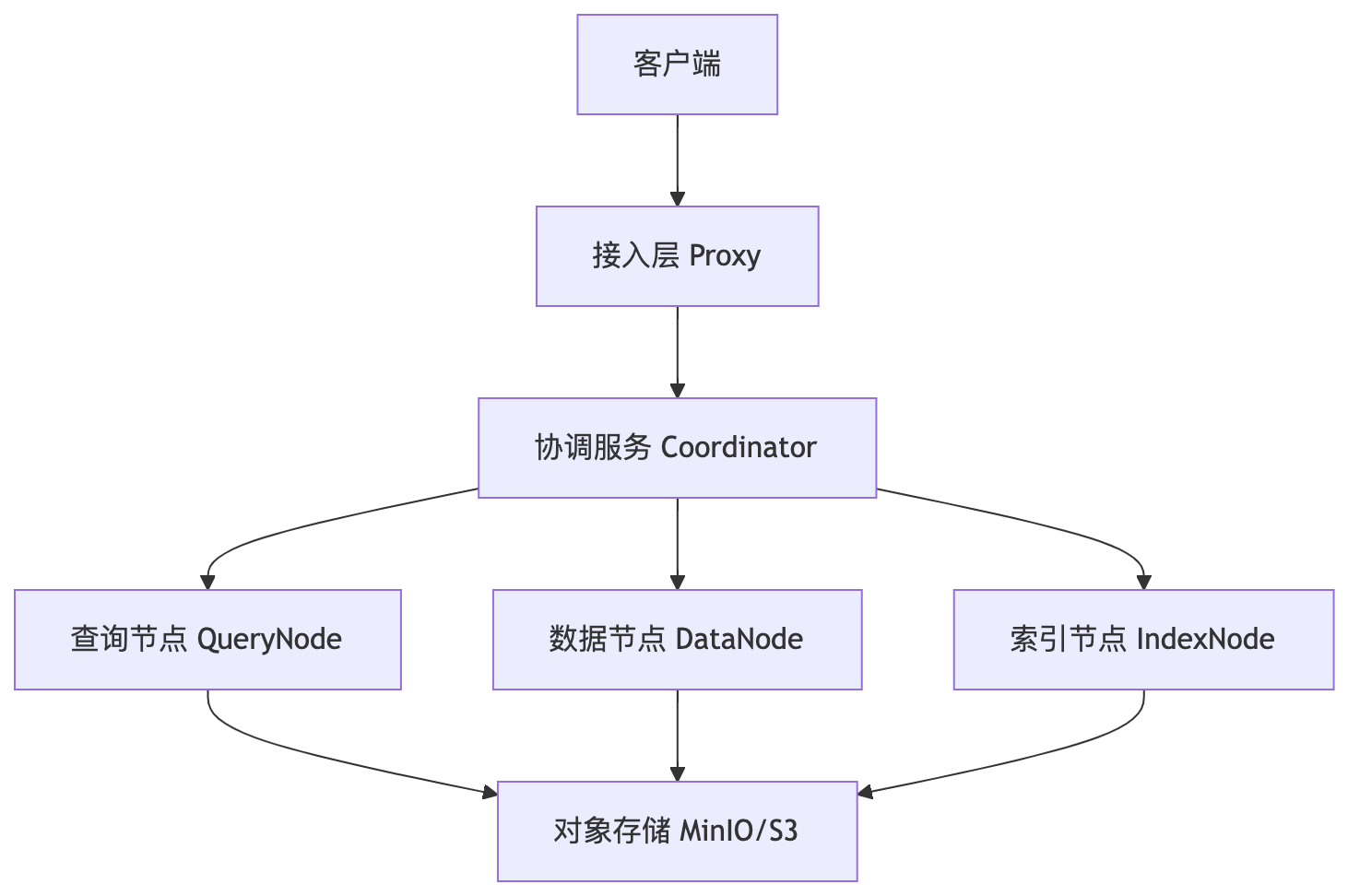 | 组件名称 | 核心职责 | 关键特性 |
| :-------------: | :----------------------------------------------------------: | :---------------------------: |
| **Proxy** | 客户端请求入口,路由转发,负载均衡与协议转换(gRPC/RESTful) | 支持负载均衡、连接池管理 |
| **Query Node** | 执行向量搜索,标量过滤,向量相似度计算与混合过滤 | 内存索引加载,GPU加速支持 |
| **Data Node** | 处理数据插入、日志流处理与数据持久化存储 | 写入日志(WAL)保障数据一致性 |
| **Index Node** | 负责索引构建与优化 | 支持后台异步构建索引 |
| **Coordinator** | 集群元数据管理、任务调度 | 高可用部署(etcd存储元数据) |
* 极速认知存储内容
* Collection 是一个二维表,具有固定的列和变化的行。
* 每列代表一个字段,每行代表一个实体。
* 下图显示了一个有 8 列和 6 个实体的 Collection
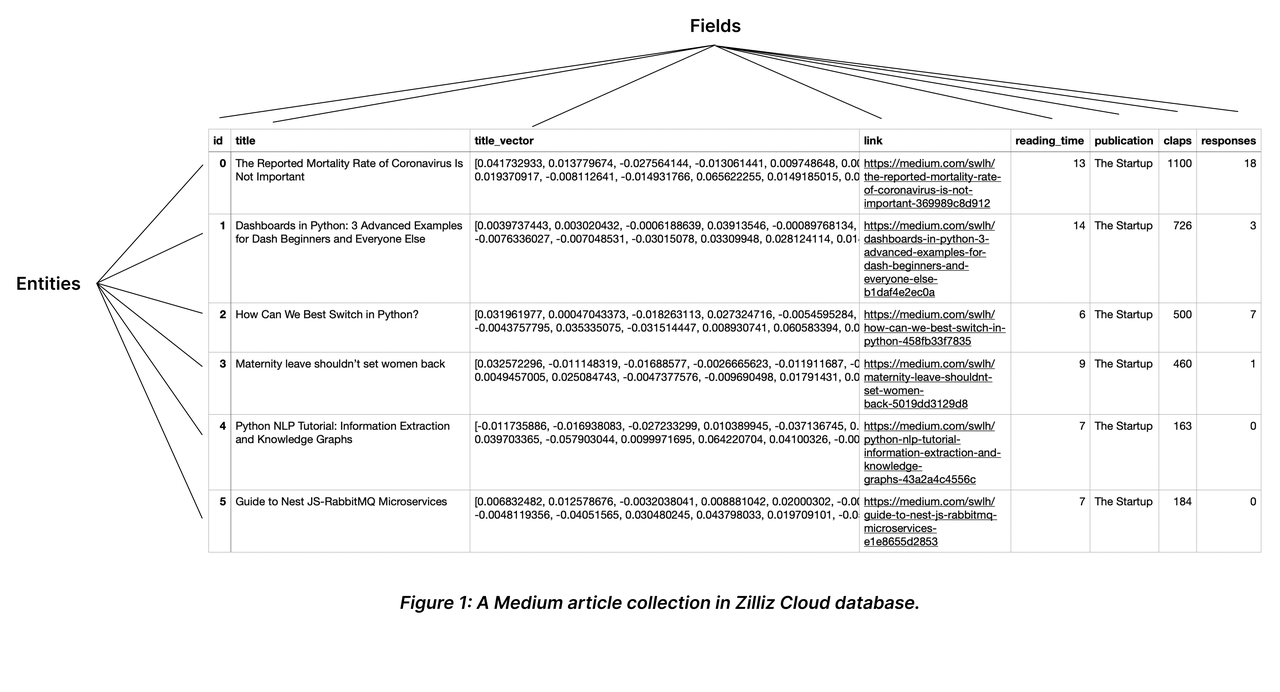
#### Milvus核心概念和数据结构讲解
* **向量数据库对比关系型数据库**
| Milvus 向量数据库 | 关系型数据库 |
| :---------------- | :----------- |
| Collection | 表 |
| Entity | 行 |
| Field | 表字段 |
* **基础数据结构**
* **Collection(集合)**
- 类比关系型数据库的“表”,用于存储和管理一组具有相同结构的实体(Entity)
- Schema 定义字段结构(主键、向量、标量字段),支持动态字段(Milvus 2.3+),自动生成唯一ID(可选)
- 例子
```python
pip install pymilvus==2.5.5
from pymilvus import FieldSchema, CollectionSchema, DataType
# 定义字段
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=768),
FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=50)
]
# 创建集合
schema = CollectionSchema(fields, description="商品向量库")
collection = Collection(name="products", schema=schema)
```
* **Entity(实体)**
- 数据的基本单位,包含多个字段(Field),如主键、标量字段(结构化数据)和向量字段。
- 主键(Primary Key):唯一标识实体,支持整数或字符串类型。
- 注意:Milvus 目前不支持主键去重,允许重复主键存在
- 组成要素
- **主键**:唯一标识(支持整数/字符串)
- **向量**:浮点数组(维度需固定)
- **标量字段**:元数据(文本/数值/布尔)
- 数据存储示意图
| ID (INT64) | Vector (FLOAT_VECTOR[768]) | Category (VARCHAR) | Price (FLOAT) |
| ---------- | -------------------------- | ------------------ | ------------- |
| 1001 | [0.12, 0.34, ..., 0.98] | "Electronics" | 299.99 |
| 1002 | [0.55, 0.21, ..., 0.11] | "Clothing" | 89.99 |
* **字段(Field)**
* 标量字段:存储数值、字符串等结构化数据,支持过滤查询(如 price < 100)。
* 向量字段:存储高维向量(如512维浮点数组),支持相似性搜索
* **查询方式(Query)**
* 向量搜索:输入一个向量,返回最相似的 Top-K 结果。
* 混合查询:结合向量相似度和标量过滤条件(如“价格 < 100”)
* **数据组织与扩展**
* **分区(Partition)**
- 逻辑划分集合数据,用于优化查询性能(如按时间或地域分区)。
- 每个分区可包含多个分片(Sharding)和段(Segment),查询时按分区减少扫描范围
* **分片(Sharding)**
- 数据写入时分散到不同节点,实现并行写入。
- 默认每个集合分2个分片,基于主键哈希分配
* **段(Segment)**
- 物理存储单元,自动合并插入数据形成数据文件。
- 段分为“增长段”(持续写入)和“密封段”(持久化存储),查询时合并所有段结果
* **索引**(类似MySQL有多个不同索引类型)
* 一种特殊的数据结构,用于快速查找和访问数据,存储在内存中. 本身不存储数据,是存储指向数据存储位置的指针或键值对。
* Milvus索引基于原始数据构建,提高对 collection 数据搜索的速度,一个向量字段仅支持一种索引类型。
* 为提高查询性能,Milvus 支持多种索引类型,可以为每个向量字段指定一种索引类型。
* 索引类型(先大体知道即可)
| 索引类型 | 适用场景 | 内存消耗 | 精度 | 构建速度 |
| :------: | :--------------: | :------: | :--: | :------: |
| FLAT | 小数据集精准搜索 | 高 | 100% | 快 |
| IVF_FLAT | 平衡型场景 | 中 | 98% | 较快 |
| HNSW | 高召回率需求 | 高 | 99% | 慢 |
| IVF_PQ | 超大规模数据 | 低 | 95% | 快 |
* **相似度计算**
* **欧氏距离(Euclidean Distance L2)**
* 数值越小越相似,理解为两个向量为两个点,欧式距离就是这两个点的直线距离
* 两点之间的距离,最小值为0,最大值不确定
* 两个点的距离,距离越近,则相似度越高,距离越大,则差异性越大
* **内积(Inner Product 简写 IP)**
* 内积又称之为点积,数值越大越相似 `a·b=|a||b|cosθ `
```
# 向量A = [a1, a2,..., an]
# 向量B = [b1, b2,..., bn]
IP = a1*b1 + a2*b2 + ... + an*bn
```
* **余弦相似度(Cosine)**
* 基于向量夹角的相似度。
#### Milvus的分区-分片-段结构和最佳实践
* 分区-分片-段 很多同学懵逼,用图书馆比喻理解三者关系
* 想象管理一个超大型图书馆(类比 **Collection** 集合),里面存放了上亿本书。
* 为了更好地管理图书,用了三种组织方式
* **分区(Partition)**:按书籍**主题**划分区域
* 比如:1楼科技区、2楼文学区、3楼艺术区
* **作用**:快速定位某一类书籍,避免全馆搜索
* **类比**:电商平台按商品类别(电器/服装/食品)分区存储
* **分片(Shard)**:每个主题区内设置**多个平行书架**
* 比如:科技区分成10个相同结构的书架,每个书架存100万本
* **作用**:多人同时查找时,不同书架可并行工作
* **类比**:分布式系统中用分片实现水平扩展
* **段(Segment)**:每个书架上的**可拆卸书盒**
* 比如:每个书架由多个书盒组成,新书先放临时盒,写满后密封成固定盒
* **作用**:优化存储空间,旧书盒可压缩归档
* **类比**:数据库将数据分块存储,便于后台合并优化
* 三者协作关系
| 组件名称 | 核心职责 | 关键特性 |
| :-------------: | :----------------------------------------------------------: | :---------------------------: |
| **Proxy** | 客户端请求入口,路由转发,负载均衡与协议转换(gRPC/RESTful) | 支持负载均衡、连接池管理 |
| **Query Node** | 执行向量搜索,标量过滤,向量相似度计算与混合过滤 | 内存索引加载,GPU加速支持 |
| **Data Node** | 处理数据插入、日志流处理与数据持久化存储 | 写入日志(WAL)保障数据一致性 |
| **Index Node** | 负责索引构建与优化 | 支持后台异步构建索引 |
| **Coordinator** | 集群元数据管理、任务调度 | 高可用部署(etcd存储元数据) |
* 极速认知存储内容
* Collection 是一个二维表,具有固定的列和变化的行。
* 每列代表一个字段,每行代表一个实体。
* 下图显示了一个有 8 列和 6 个实体的 Collection

#### Milvus核心概念和数据结构讲解
* **向量数据库对比关系型数据库**
| Milvus 向量数据库 | 关系型数据库 |
| :---------------- | :----------- |
| Collection | 表 |
| Entity | 行 |
| Field | 表字段 |
* **基础数据结构**
* **Collection(集合)**
- 类比关系型数据库的“表”,用于存储和管理一组具有相同结构的实体(Entity)
- Schema 定义字段结构(主键、向量、标量字段),支持动态字段(Milvus 2.3+),自动生成唯一ID(可选)
- 例子
```python
pip install pymilvus==2.5.5
from pymilvus import FieldSchema, CollectionSchema, DataType
# 定义字段
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=768),
FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=50)
]
# 创建集合
schema = CollectionSchema(fields, description="商品向量库")
collection = Collection(name="products", schema=schema)
```
* **Entity(实体)**
- 数据的基本单位,包含多个字段(Field),如主键、标量字段(结构化数据)和向量字段。
- 主键(Primary Key):唯一标识实体,支持整数或字符串类型。
- 注意:Milvus 目前不支持主键去重,允许重复主键存在
- 组成要素
- **主键**:唯一标识(支持整数/字符串)
- **向量**:浮点数组(维度需固定)
- **标量字段**:元数据(文本/数值/布尔)
- 数据存储示意图
| ID (INT64) | Vector (FLOAT_VECTOR[768]) | Category (VARCHAR) | Price (FLOAT) |
| ---------- | -------------------------- | ------------------ | ------------- |
| 1001 | [0.12, 0.34, ..., 0.98] | "Electronics" | 299.99 |
| 1002 | [0.55, 0.21, ..., 0.11] | "Clothing" | 89.99 |
* **字段(Field)**
* 标量字段:存储数值、字符串等结构化数据,支持过滤查询(如 price < 100)。
* 向量字段:存储高维向量(如512维浮点数组),支持相似性搜索
* **查询方式(Query)**
* 向量搜索:输入一个向量,返回最相似的 Top-K 结果。
* 混合查询:结合向量相似度和标量过滤条件(如“价格 < 100”)
* **数据组织与扩展**
* **分区(Partition)**
- 逻辑划分集合数据,用于优化查询性能(如按时间或地域分区)。
- 每个分区可包含多个分片(Sharding)和段(Segment),查询时按分区减少扫描范围
* **分片(Sharding)**
- 数据写入时分散到不同节点,实现并行写入。
- 默认每个集合分2个分片,基于主键哈希分配
* **段(Segment)**
- 物理存储单元,自动合并插入数据形成数据文件。
- 段分为“增长段”(持续写入)和“密封段”(持久化存储),查询时合并所有段结果
* **索引**(类似MySQL有多个不同索引类型)
* 一种特殊的数据结构,用于快速查找和访问数据,存储在内存中. 本身不存储数据,是存储指向数据存储位置的指针或键值对。
* Milvus索引基于原始数据构建,提高对 collection 数据搜索的速度,一个向量字段仅支持一种索引类型。
* 为提高查询性能,Milvus 支持多种索引类型,可以为每个向量字段指定一种索引类型。
* 索引类型(先大体知道即可)
| 索引类型 | 适用场景 | 内存消耗 | 精度 | 构建速度 |
| :------: | :--------------: | :------: | :--: | :------: |
| FLAT | 小数据集精准搜索 | 高 | 100% | 快 |
| IVF_FLAT | 平衡型场景 | 中 | 98% | 较快 |
| HNSW | 高召回率需求 | 高 | 99% | 慢 |
| IVF_PQ | 超大规模数据 | 低 | 95% | 快 |
* **相似度计算**
* **欧氏距离(Euclidean Distance L2)**
* 数值越小越相似,理解为两个向量为两个点,欧式距离就是这两个点的直线距离
* 两点之间的距离,最小值为0,最大值不确定
* 两个点的距离,距离越近,则相似度越高,距离越大,则差异性越大
* **内积(Inner Product 简写 IP)**
* 内积又称之为点积,数值越大越相似 `a·b=|a||b|cosθ `
```
# 向量A = [a1, a2,..., an]
# 向量B = [b1, b2,..., bn]
IP = a1*b1 + a2*b2 + ... + an*bn
```
* **余弦相似度(Cosine)**
* 基于向量夹角的相似度。
#### Milvus的分区-分片-段结构和最佳实践
* 分区-分片-段 很多同学懵逼,用图书馆比喻理解三者关系
* 想象管理一个超大型图书馆(类比 **Collection** 集合),里面存放了上亿本书。
* 为了更好地管理图书,用了三种组织方式
* **分区(Partition)**:按书籍**主题**划分区域
* 比如:1楼科技区、2楼文学区、3楼艺术区
* **作用**:快速定位某一类书籍,避免全馆搜索
* **类比**:电商平台按商品类别(电器/服装/食品)分区存储
* **分片(Shard)**:每个主题区内设置**多个平行书架**
* 比如:科技区分成10个相同结构的书架,每个书架存100万本
* **作用**:多人同时查找时,不同书架可并行工作
* **类比**:分布式系统中用分片实现水平扩展
* **段(Segment)**:每个书架上的**可拆卸书盒**
* 比如:每个书架由多个书盒组成,新书先放临时盒,写满后密封成固定盒
* **作用**:优化存储空间,旧书盒可压缩归档
* **类比**:数据库将数据分块存储,便于后台合并优化
* 三者协作关系
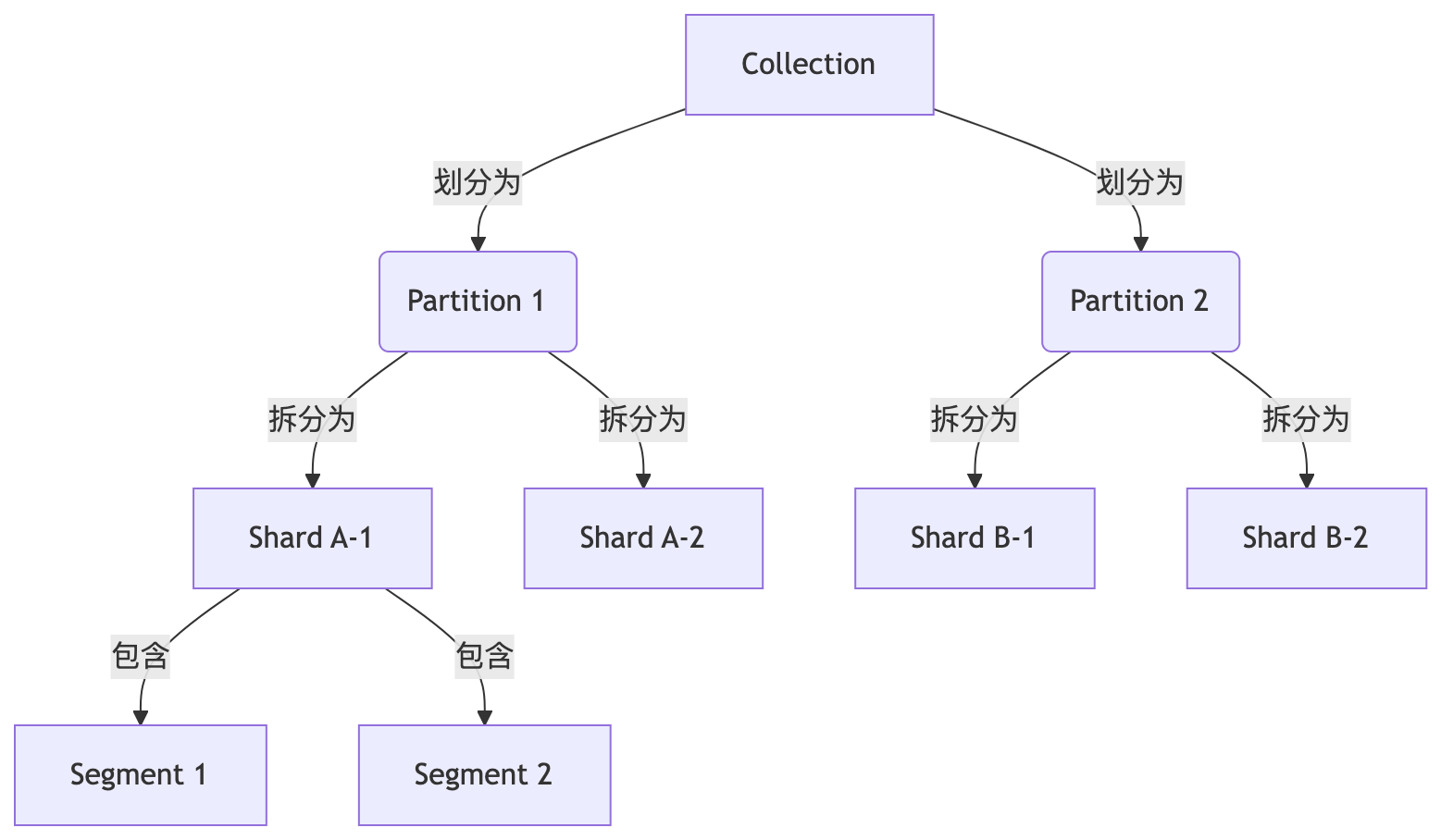 | 维度 | 分区(Partition) | 分片(Shard) | 段(Segment) |
| :--------: | :---------------: | :--------------------: | :----------------: |
| **层级** | 逻辑划分 | 物理分布 | 物理存储单元 |
| **可见性** | 用户主动创建管理 | 系统自动分配 | 完全由系统管理 |
| **目的** | 业务数据隔离 | 负载均衡与扩展 | 存储优化与查询加速 |
| **类比** | 图书馆的不同楼层 | 楼层内的多个相同书架 | 书架上的可替换书盒 |
| **操作** | 手动指定查询分区 | 自动路由请求到不同节点 | 自动合并/压缩 |
* 实际工作流程例子
* **场景**:用户上传10万条商品数据到电商平台
* **分区阶段**
* 按业务维度划分(如用户ID、时间范围), 示例:`partition_2024Q1`, `vip_users`
```python
# 按商品类别创建分区
# 电子产品存入electronics分区
collection.create_partition("electronics")
# 服装类存入clothing分区
collection.create_partition("clothing")
```
* **分片阶段(自动完成)**
* 系统自动将数据均分到3个分片(假设集群有3个节点)
| 维度 | 分区(Partition) | 分片(Shard) | 段(Segment) |
| :--------: | :---------------: | :--------------------: | :----------------: |
| **层级** | 逻辑划分 | 物理分布 | 物理存储单元 |
| **可见性** | 用户主动创建管理 | 系统自动分配 | 完全由系统管理 |
| **目的** | 业务数据隔离 | 负载均衡与扩展 | 存储优化与查询加速 |
| **类比** | 图书馆的不同楼层 | 楼层内的多个相同书架 | 书架上的可替换书盒 |
| **操作** | 手动指定查询分区 | 自动路由请求到不同节点 | 自动合并/压缩 |
* 实际工作流程例子
* **场景**:用户上传10万条商品数据到电商平台
* **分区阶段**
* 按业务维度划分(如用户ID、时间范围), 示例:`partition_2024Q1`, `vip_users`
```python
# 按商品类别创建分区
# 电子产品存入electronics分区
collection.create_partition("electronics")
# 服装类存入clothing分区
collection.create_partition("clothing")
```
* **分片阶段(自动完成)**
* 系统自动将数据均分到3个分片(假设集群有3个节点)
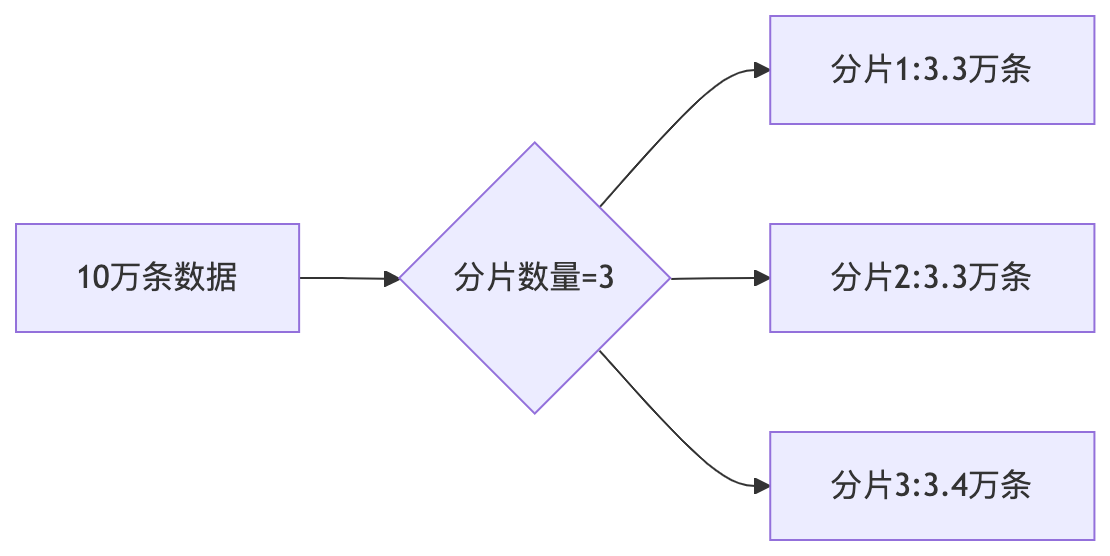 * **段阶段(自动完成)**
* 分片内数据按512MB大小自动切割成多个段
* **段阶段(自动完成)**
* 分片内数据按512MB大小自动切割成多个段
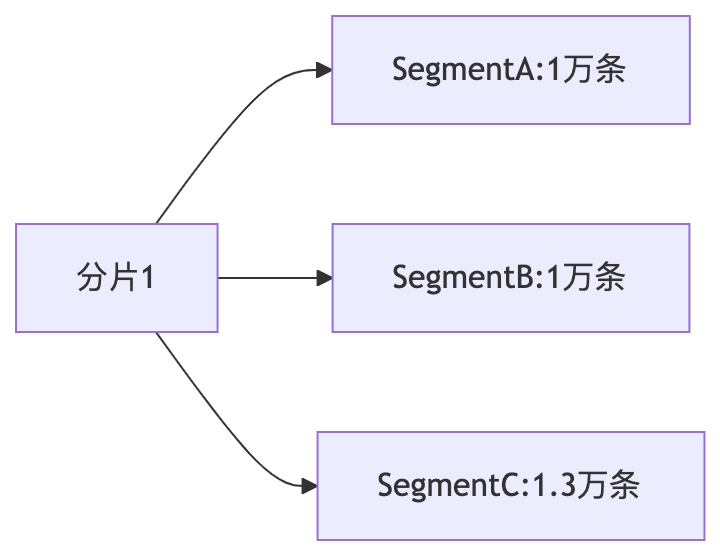 * 三者协作原理
* **写入过程**
```
新数据 → 选择分区 → 分配到分片 → 写入活跃段 → 段写满后冻结 → 生成新段
```
* **查询过程**
```
用户请求 → 定位分区 → 并行查询所有相关分片 → 各分片扫描所有段 → 合并结果排序
```
* **合并优化**
```python
# 自动将小段合并成大段(类似HBase Compaction)
[Segment1(100MB)] + [Segment2(100MB)] → [SegmentMerged(200MB)]
```
* 注意: 分区的意义是通过划定分区减少数据读取,而分片的意义在于多台机器上并行写入操作。
* **开发注意事项**
* **分区使用技巧**
- 按时间分区:`2023Q1`, `2023Q2`
- 按业务线分区:`user_profiles`, `product_info`
- **错误示范**:创建超过1000个分区(影响元数据性能)
```python
# 好的实践:按时间分区
client.create_partition(
collection_name="logs",
partition_name="2024-01"
)
# 坏的实践:每个用户一个分区(容易超过限制)
```
* **分片配置建议**
* ❌ 8核机器设置128分片 → 线程频繁切换导致性能下降
* ✅ 使用公式:`分片数 = 节点数 × CPU核心数`
| 分片数少 | 分片数多 |
| :------------: | :------------: |
| 单分片数据量大 | 单分片数据量小 |
| 写入吞吐低 | 写入吞吐高 |
| 易成性能瓶颈 | 资源消耗大 |
```python
# 创建集合时指定
collection = Collection(
name="product_images",
shards_num=64, # 分片数 = 8台 × 8核 = 64
partitions=[
"electronics",
"clothing",
"home_appliances"
]
)
# 调整段配置
client.set_property("dataCoord.segment.maxSize", "1024") # 1GB
client.set_property("dataCoord.segment.sealProportion", "0.7")
```
* 段优化策略
* 监控段大小:`collection.get_segment_info()`
* 手动触发合并:`collection.compact()`
* 设置段容量阈值:`storage.segmentSize=1024` (单位MB)
* 根据数据特性调整
```python
if 向量维度 > 1024:
maxSize = 512 # 降段大小缓解内存压力
else:
maxSize = 1024
```
#### Milvus部署架构选择和Docker部署实战
* 部署架构选择
* 选择取决于项目的阶段和规模,Milvus 为从快速原型开发到大规模企业部署的各种需求提供了灵活而强大的解决方案。
- **Milvus Lite**建议用于较小的数据集,多达几百万个向量, 不支持WINDOWS系统。
- **Milvus Standalone**适用于中型数据集,可扩展至 1 亿向量。
- **Milvus Distributed 专为**大规模部署而设计,能够处理从一亿到数百亿向量的数据集。

* Milvus分层架构(Docker部署都包括了)
```python
┌───────────────────────────────┐
│ Coordinator │ ← 管理元数据、负载均衡
├───────────────┬───────────────┤
│ Query Node │ Data Node │ ← 处理查询与数据存储
├───────────────┴───────────────┤
│ Object Storage (S3) │ ← 持久化存储(可选MinIO、AWS S3)
└───────────────────────────────┘
```
* Milvus Standalone 是单机服务器部署,所有组件都打包到一个Docker 镜像中,部署方便。
* 此外,Milvus Standalone 通过主从复制支持高可用性。
* 有钱的当我没说,直接购买云厂商的服务:https://help.aliyun.com/zh/milvus
* LInux服务器部署Milvus实战
* 阿里云网络安全组记得开放端口 `2379`、`9091`, `19530`
* 注意: 默认没加权限校验,生产环境使用一般都是内网,结合配置IP白名单
* 版本和课程保持一致,不然很多不兼容!!!
* 下载相关资料 ,使用**【wget】或者【浏览器】远程下载相关依赖包(需要替换群里最新的)**
```python
原生资料下载方式(账号 - 密码 - ip地址 - 端口 需要替换群里最新的,【其他路径不变】)
wget --http-user=用户名 --http-password=密码 http://ip:端口/dcloud_pan/standalone_embed.sh
#比如 命令行下
wget --http-user=admin --http-password=xdclass.net888 http://47.115.31.28:9088/dcloud_pan/standalone_embed.sh
# 比如 浏览器直接访问
http://47.115.31.28:9088/dcloud_pan/standalone_embed.sh
```
* 解压后执行【**依赖很多,版本差异大,务必按照下面执行,否则课程无法进行下去,加我微信 xdclass6**】
```python
#启动
bash standalone_embed.sh start
#停止
bash standalone_embed.sh stop
#删除
bash standalone_embed.sh delete
#升级
bash standalone_embed.sh upgrade
```
* 运行安装脚本后
- 一个名为 Milvus 的 docker 容器已在**19530** 端口启动。
- 嵌入式 etcd 与 Milvus 安装在同一个容器中,服务端口为**2379**。
- Milvus 数据卷被映射到当前文件夹中的**volumes/milvus**
- 访问 `http://${MILVUS_PROXY_IP}:9091/webui` 例子: http://47.119.128.20:9091/webui/
* 注意
* Milvus Web UI 与 Attu等可视化工具 不同,它是一个内置工具,只是提供简单直观的界面,查看系统的基本信息
* 主要功能:运行环境、数据库/ Collections 详情、任务和慢查询请求,不支持数据库管理和操作任务
* 参考:https://milvus.io/docs/zh/milvus-webui.md
#### Milvus可视化客户端安装实战
* Attu 可视化客户端介绍
* 是一款专为 **Milvus 向量数据库**设计的开源图形化管理工具,通过直观的界面简化了数据库的日常操作与维护流程
* **跨平台支持**:提供 Docker 镜像,适配 Windows、Linux 和 macOS
* **开箱即用**:无需编写代码即可完成 Milvus 的日常管理,降低学习成本
* **社区与生态**:由 Zilliz 团队维护,与 Milvus 深度集成,持续更新功能
* **版本兼容性**:注意 Attu 与 Milvus 版本的匹配,避免接口不兼容问题【**当前安装的Milvus版本 V2.5X**】
* GitHub地址:https://github.com/zilliztech/attu
* 核心功能
* 数据库与集合管理
* 数据库管理:支持创建、删除数据库,默认提供 default 数据库且不可删除。
* 集合(Collection)操作:可创建集合、定义字段(主键、标量字段、向量字段)、构建索引,并支持数据导入/导出。
* 分区与分片:支持按业务需求划分分区(如按时间或用户组),优化查询效率;默认分片数为 2,支持水平扩展。
* 向量检索与混合查询
* 相似性搜索:输入向量即可快速检索 Top-K 相似结果,支持欧氏距离(L2)、余弦相似度等度量方式。
* 标量过滤:通过 Advanced Filter 功能结合标量字段(如价格、标签)进行条件筛选,提升搜索精准度。
* 数据加载与释放:可将数据加载至内存加速检索,或释放内存以优化资源占用。
* 用户与权限管理
* 多角色权限控制:支持创建用户与角色,并分配细粒度权限(如全局权限、集合操作权限)。
* 权限类型:涵盖数据插入、删除、查询等操作,
* 例如:
* 全局权限:创建/删除数据库、管理资源组。
* 集合权限:加载/释放数据、构建索引、执行搜索。
* 用户权限:更新用户凭证、查询用户信息
* 安装实战(根据系统选择对应的客户端下载,输入ip+端口)
### Milvus向量数据库多案例实战
#### Python整合向量数据库Milvus案例实战
* Python操作Milvus实战
* 安装 Milvus Python SDK, 支持 Python、Node.js、GO 和 Java SDK。
* 建议安装与所安装 Milvus 服务器版本相匹配的 PyMilvus 版本
* 安装
```
pip install pymilvus==2.5.5
```
* 验证安装 如果 PyMilvus 安装正确,运行以下命令时不会出现异常
```
python -c "from pymilvus import Collection"
```
* 接口可分为以下几类:
* **DDL / DCL:**createCollection / createPartition / dropCollection / dropPartition / hasCollection / hasPartition
* **DML / Produce:**插入 / 删除 / 上移
* **DQL:**搜索/查询
* 操作Milvus数据库
* 使用connect()连接 Milvus 服务器,进行相关操作
```python
#也可以使用MilvusClient
#from pymilvus import MilvusClient
#client = MilvusClient("http://47.119.128.20:19530")
from pymilvus import connections, db
conn = connections.connect(host="47.119.128.20", port=19530)
# 创建数据库
#db.create_database("my_database")
# 使用数据库
db.using_database("my_database")
# 列出数据库
dbs = db.list_database()
print(dbs)
#['default', 'my_database']
# 删除数据库
db.drop_database("my_database")
```
* Collection与Schema的创建和管理
* Collection 是一个二维表,具有固定的列和变化的行,每列代表一个字段,每行代表一个实体。
* 要实现这样的结构化数据管理,需要一个 Schema定义 Collections 的表结构
* 每个Schema由多个`FieldSchema`组成:
```python
from pymilvus import FieldSchema, DataType
# 字段定义示例
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=128),
FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=50)
]
```
* 字段类型详解
| 数据类型 | 说明 | 示例 |
| :-------------: | :----------: | :---------------: |
| `INT8/16/32/64` | 整型 | `DataType.INT64` |
| `FLOAT` | 单精度浮点数 | `DataType.FLOAT` |
| `DOUBLE` | 双精度浮点数 | `DataType.DOUBLE` |
| `VARCHAR` | 变长字符串 | `max_length=255` |
| `FLOAT_VECTOR` | 浮点向量 | `dim=768` |
* 创建collection实战
```python
from pymilvus import connections
from pymilvus import FieldSchema, DataType
from pymilvus import CollectionSchema, Collection
conn = connections.connect(host="47.119.128.20", port=19530)
# 步骤1:定义字段
fields = [
FieldSchema("id", DataType.INT64, is_primary=True),
FieldSchema("vector", DataType.FLOAT_VECTOR, dim=128),
FieldSchema("tag", DataType.VARCHAR, max_length=50)
]
# 步骤2:创建Schema
schema = CollectionSchema(fields, description="示例集合")
# 步骤3:实例化Collection
collection = Collection(
name="demo_collection",
schema=schema,
shards_num=2 # 分片数(分布式扩展关键)
)
```
* 关键参数解析
| 参数 | 说明 | 推荐值 |
| :-----------: | :------------------------: | :--------------: |
| `shards_num` | 分片数量(创建后不可修改) | 集群节点数×2 |
| `description` | 集合描述信息 | 建议填写业务用途 |
* 动态字段Schema
* 在集合中启用动态字段后,所有未在 Schema 中定义的字段及其值都将作为键值对存储在动态字段中
```python
# 启用动态字段(Milvus 2.3+)
schema = CollectionSchema(
fields,
enable_dynamic_field=True
)
```
* 案例讲解
* 假设 Collections Schema 只定义两个字段,名为`id` 和`vector` ,启用了动态字段,在 Collections 中插入以下数据集
* 数据集包含 多个实体,每个实体都包括字段`id`,`vector`, 和`color` ,Schema 中没有定义`color` 字段。
* 由于 Collections 启用了动态字段,因此字段`color` 将作为键值对存储在动态字段中。
```python
[
{id: 0, vector: [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], color: "pink_8682"},
{id: 7, vector: [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], color: "grey_8510"},
{id: 8, vector: [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], color: "white_9381"},
{id: 9, vector: [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], color: "purple_4976"}
]
```
| 类型 | 特点 | 适用场景 |
| :------------: | :---------------------------: | :----------------------------: |
| **静态Schema** | 严格字段定义 | 数据结构固定的业务(用户画像) |
| **动态Schema** | 允许灵活字段(需Milvus 2.3+) | 日志类多变数据 |
#### Milvus索引操作和最佳实践避坑指南
* 为什么需要索引?
* 加速查询:避免暴力比对,快速定位相似向量, 平衡召回率与查询速度
* 节省资源:减少内存占用和计算开销, 建议为经常访问的向量和标量创建索引
* 常见的索引类型
| 索引类型 | 适用场景 | 内存占用 | 精度 | 构建速度 |
| :------: | :----------------------: | :------: | :-----: | :------: |
| FLAT | 小数据精确搜索(<100万) | 高 | 100% | 快 |
| IVF_FLAT | 大数据平衡场景(千万级) | 中 | 95%-98% | 较快 |
| HNSW | 高召回率需求 | 高 | 98%-99% | 慢 |
| DISKANN | 超大规模(10亿+) | 低 | 90%-95% | 最慢 |
* Milvus索引操作
* 创建索引
```python
# 导入MilvusClient和DataType模块,用于连接Milvus服务器并操作数据类型
from pymilvus import MilvusClient, DataType
# 实例化MilvusClient以连接到指定的Milvus服务器
client = MilvusClient(
uri="http://47.119.128.20:19530"
)
# 创建schema对象,设置自动ID生成和动态字段特性
schema = MilvusClient.create_schema(
auto_id=False,
enable_dynamic_field=True,
)
# 向schema中添加字段"id",数据类型为INT64,作为主键
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
# 向schema中添加字段"vector",数据类型为FLOAT_VECTOR,维度为5
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=5)
# 使用create_collection方法根据schema创建集合"customized_setup"
client.create_collection(
collection_name="customized_setup",
schema=schema,
)
# 准备索引参数,为"vector"字段创建索引
index_params = MilvusClient.prepare_index_params()
# 添加索引配置,指定字段名、度量类型、索引类型、索引名和参数
index_params.add_index(
field_name="vector",
metric_type="COSINE", # 距离计算方式 (L2/IP/COSINE)
index_type="IVF_FLAT",
index_name="vector_index",
params={ "nlist": 128 } #聚类中心数 (建议值:sqrt(数据量))
)
# 创建索引,不等待索引创建完成即返回
client.create_index(
collection_name="customized_setup",
index_params=index_params,
sync=False # 是否等待索引创建完成后再返回。默认为True。
)
```
* 参数说明
| 参数 | 参数 |
| ----------------- | ------------------------------------------------------------ |
| `field_name` | 指定字段名称 |
| `metric_type` | 用于衡量向量间相似性的算法。值有**IP**、**L2**、**COSINE**、**JACCARD**、**HAMMING**。只有当指定字段是向量字段时才可用。 |
| `index_type` | 索引类型 |
| `index_name` | 索引名称 |
| `params` | 指定索引类型的微调参数 |
| `collection_name` | Collections 的名称。 |
| `sync` | 控制与客户端请求相关的索引构建方式。有效值: `True` (默认):客户端等待索引完全建立后才返回。在该过程完成之前不会收到响应。`False`:客户端收到请求后立即返回,索引在后台建立 |
* 查看索引信息
```python
#列出索引名称
res = client.list_indexes(
collection_name="customized_setup"
)
print(res)
#获取索引详细信息
res = client.describe_index(
collection_name="customized_setup",
index_name="vector_index"
)
print(res)
```
* 删除索引
* 删除前需确保无查询正在使用该索引
* 删除后需重新创建索引才能进行有效查询
```python
#如果不再需要索引,可以直接将其删除。
client.drop_index(
collection_name="customized_setup",
index_name="vector_index"
)
print("索引已删除")
```
* 最佳实践与避坑指南
* **Schema设计原则**
- 主键选择
- 推荐自增ID避免冲突
- 禁止使用向量字段作为主键
- **字段数量**:单个集合不超过32个字段
- **向量维度**:创建后不可修改,需提前规划
* **索引选择策略**:
- 百万级以下 → FLAT
- 百万到亿级 → IVF/HNSW
- 十亿级以上 → DISKANN
* **操作规范**:
- 数据插入完成后再建索引
- 定期重建索引(数据变更超过30%)
- 为高频查询字段建立独立索引
* **常见错误处理**
| 错误场景 | 解决方案 |
| :--------------: | :----------------------------------: |
| "字段类型不匹配" | 检查插入数据与Schema定义的一致性 |
| "主键冲突" | 插入前检查ID唯一性,或使用自动生成ID |
| "向量维度错误" | 校验dim参数与数据实际维度 |
#### Milvus向量数据库的DML操作实战
* 核心DML操作实战
* 创建集合(Collection),集合是Milvus中数据存储的基本单位,需定义字段和索引
* `auto_id=True`时无需手动指定主键
* 动态字段(`enable_dynamic_field=True`)允许灵活扩展非预定义字段
```python
# 导入MilvusClient和DataType模块,用于连接Milvus服务器并操作数据类型
from pymilvus import MilvusClient, DataType
# 实例化MilvusClient以连接到指定的Milvus服务器
client = MilvusClient(
uri="http://47.119.128.20:19530"
)
# 定义Schema
schema = client.create_schema(auto_id=False, enable_dynamic_field=True)
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=128)
schema.verify() # 验证Schema
# 定义索引参数
index_params = client.prepare_index_params()
index_params.add_index(
field_name="vector",
index_type="IVF_FLAT", # 量化索引,平衡速度与精度
metric_type="L2", # 相似性度量标准(欧式距离)
params={"nlist": 1024} # 聚类中心数
)
# 创建集合
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)
```
* 插入数据(Insert)支持单条或批量插入【可视化工具那边需要加载,包括查询等都是需要加载状态才可以操作】
```python
data = [
{"id": 1, "vector": [0.1]*128, "text": "Sample text 1"},
{"id": 2, "vector": [0.2]*128, "text": "Sample text 2"}
]
# 插入数据
insert_result = client.insert(
collection_name="my_collection",
data=data
)
print("插入ID列表:", insert_result["ids"]) # 返回主键ID
```
* 删除数据(Delete)通过主键或条件表达式删除
```python
# 按主键删除
client.delete(
collection_name="my_collection",
ids=[1, 2] # 主键列表
)
# 按条件删除(如删除text字段为空的记录)
client.delete(
collection_name="my_collection",
filter="text == ''"
)
```
* 更新数据(Update)Milvus不支持直接更新,需通过“删除+插入”实现:
```python
# 删除旧数据
client.delete(collection_name="my_collection", ids=[3])
# 插入新数据
client.insert(
collection_name="my_collection",
data=[{"id": 3, "vector": [0.3]*128, "text": "Updated text"}]
)
```
#### Milvus向量Search查询综合案例实战
* 需求说明
* 创建包含混合数据类型(标量+向量)的集合
* 批量插入结构化和非结构化数据
* 实现带过滤条件的混合查询
* 验证端到端的向量搜索流程
* Search语法深度解析
* 核心参数说明
```python
results = client 或 collection.search(
data=[[0.12, 0.23, ..., 0.88]], # 查询向量(必须)
anns_field="vector", # 要搜索的向量字段名(必须)
param={"metric_type": "L2", "params": {"nprobe": 10}}, # 搜索参数
limit=10, # 返回结果数量
expr="price > 50", # 过滤表达式(可选)
output_fields=["product_id", "price"], # 返回的字段
)
```
| 参数 | 类型 | 说明 | 常用值 |
| :-----------: | :--: | :----------: | :--------------------------------------: |
| data | list | 查询向量列表 | 二维数组 |
| anns_field | str | 向量字段名 | 创建时定义的字段 |
| param | dict | 搜索参数 | 包含metric_type和params |
| limit | int | 返回结果数 | 5-100 |
| expr | str | 过滤条件 | price > 50 AND category == 'electronics' |
| output_fields | list | 返回字段 | ["field1", "field2"] |
* 搜索案例实战(MilvusClient方式)
* 准备数据
```python
from pymilvus import (
connections,MilvusClient,
FieldSchema, CollectionSchema, DataType,
Collection, utility
)
import random
# # 创建Milvus客户端
client = MilvusClient(
uri="http://47.119.128.20:19530",
)
#删除已存在的同名集合
if client.has_collection("book"):
client.drop_collection("book")
# 定义字段
fields = [
FieldSchema(name="book_id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=50),
FieldSchema(name="price", dtype=DataType.DOUBLE),
FieldSchema(name="book_intro", dtype=DataType.FLOAT_VECTOR, dim=4)
]
# 创建集合Schema
schema = CollectionSchema(
fields=fields,
description="Book search collection"
)
#创建集合
client.create_collection(collection_name="book", schema=schema)
# 生成测试数据
num_books = 1000
categories = ["科幻", "科技", "文学", "历史"]
titles = ["量子世界", "AI简史", "时光之轮", "文明起源", "未来简史", "数据科学"]
data = []
for i in range(num_books):
data.append({
"title": f"{random.choice(titles)}_{i}",
"category": random.choice(categories),
"price": round(random.uniform(10, 100), 2),
"book_intro": [random.random() for _ in range(4)] # 4维向量
})
# 批量插入
insert_result = client.insert(
collection_name="book",
data=data
)
print(f"插入数据量:{len(insert_result['ids'])}")
```
* 创建索引
```python
# 准备索引参数,为"vector"字段创建索引
index_params = MilvusClient.prepare_index_params()
# 添加索引配置,指定字段名、度量类型、索引类型、索引名和参数
index_params.add_index(
field_name="book_intro",
metric_type="L2", # 距离计算方式 (L2/IP/COSINE)
index_type="IVF_FLAT",
index_name="vector_index",
params={ "nlist": 128 } #聚类中心数 (建议值:sqrt(数据量))
)
# 创建索引,不等待索引创建完成即返回
client.create_index(
collection_name="book",
index_params=index_params
)
print("索引创建完成")
```
* 执行查询【执行查询前需要加载才可以使用】
```python
client.load_collection(collection_name="book") # 加载集合到内存
# 生成查询向量
query_vector = [random.random() for _ in range(4)]
# 执行带过滤条件的向量搜索
results = client.search(
collection_name="book",
data=[query_vector], # 支持批量查询
filter="category == '科幻' and price < 50",
output_fields=["title", "category", "price"],
limit=3,
search_params={"nprobe": 10}
)
# 解析结果
print("\n科幻类且价格<50的搜索结果:")
for result in results[0]: # 第一个查询结果集
print(f"ID: {result['book_id']}")
print(f"距离: {result['distance']:.4f}")
print(f"标题: {result['entity']['title']}")
print(f"价格: {result['entity']['price']:.2f}")
print("-" * 30)
```
* 向量数据库完整工作流程示意图
```
1. 创建集合Schema
↓
2. 插入测试数据
↓
3. 创建向量索引
↓
4. 加载集合到内存
↓
5. 执行混合查询(向量+标量过滤)
```
* 全量查询案例演示
* 测试是否有 output_fields 字段,返回结果的差异
```python
# 案例1:基础向量查询
basic_res = client.search(
collection_name="book",
data=[query_vector],
limit=5
)
# 案例2:分页查询
page_res = client.search(
collection_name="book",
data=[query_vector],
offset=2,
limit=3
)
# 案例3:批量查询
batch_res = client.search(
collection_name="book",
data=[query_vector, [0.5]*4], # 同时查询两个向量,每个向量都会返回2条
limit=2
)
```
* 集合状态
```python
# 验证集合状态
print(client.describe_collection("book"))
# 索引状态检查
print(client.list_indexes("book"))
```
* 新旧版本对比表
| 功能 | PyMilvus旧版 | MilvusClient新版 |
| :----------- | :---------------------- | :---------------------------- |
| 连接管理 | 需要手动管理connections | 客户端自动管理 |
| 数据插入格式 | 多列表结构 | 字典列表 |
| 字段定义 | 使用FieldSchema | 在create_collection中直接定义 |
| 返回结果格式 | 对象属性访问 | 标准化字典格式 |
| 错误处理 | 异常类捕获 | 统一错误码系统 |
| 动态字段支持 | 需要额外配置 | 参数开启即可 |
### MMR搜索和LangChain整合Milvus实战
#### 相似度Similarity和MMR最大边界相关搜索
* 搜索的行业应用案例:电商推荐系统(明白两个差异)
* **相似度搜索**:
```
"用户点击商品A → 推荐相似商品B、C"
```
* **MMR搜索**:
```
"用户浏览历史多样 → 推荐跨品类商品"
```
* 基础相似度搜索(Similarity Search)
* **原理**:通过向量空间中的距离计算(余弦相似度/L2距离等)找出最接近目标向量的结果
* 三者协作原理
* **写入过程**
```
新数据 → 选择分区 → 分配到分片 → 写入活跃段 → 段写满后冻结 → 生成新段
```
* **查询过程**
```
用户请求 → 定位分区 → 并行查询所有相关分片 → 各分片扫描所有段 → 合并结果排序
```
* **合并优化**
```python
# 自动将小段合并成大段(类似HBase Compaction)
[Segment1(100MB)] + [Segment2(100MB)] → [SegmentMerged(200MB)]
```
* 注意: 分区的意义是通过划定分区减少数据读取,而分片的意义在于多台机器上并行写入操作。
* **开发注意事项**
* **分区使用技巧**
- 按时间分区:`2023Q1`, `2023Q2`
- 按业务线分区:`user_profiles`, `product_info`
- **错误示范**:创建超过1000个分区(影响元数据性能)
```python
# 好的实践:按时间分区
client.create_partition(
collection_name="logs",
partition_name="2024-01"
)
# 坏的实践:每个用户一个分区(容易超过限制)
```
* **分片配置建议**
* ❌ 8核机器设置128分片 → 线程频繁切换导致性能下降
* ✅ 使用公式:`分片数 = 节点数 × CPU核心数`
| 分片数少 | 分片数多 |
| :------------: | :------------: |
| 单分片数据量大 | 单分片数据量小 |
| 写入吞吐低 | 写入吞吐高 |
| 易成性能瓶颈 | 资源消耗大 |
```python
# 创建集合时指定
collection = Collection(
name="product_images",
shards_num=64, # 分片数 = 8台 × 8核 = 64
partitions=[
"electronics",
"clothing",
"home_appliances"
]
)
# 调整段配置
client.set_property("dataCoord.segment.maxSize", "1024") # 1GB
client.set_property("dataCoord.segment.sealProportion", "0.7")
```
* 段优化策略
* 监控段大小:`collection.get_segment_info()`
* 手动触发合并:`collection.compact()`
* 设置段容量阈值:`storage.segmentSize=1024` (单位MB)
* 根据数据特性调整
```python
if 向量维度 > 1024:
maxSize = 512 # 降段大小缓解内存压力
else:
maxSize = 1024
```
#### Milvus部署架构选择和Docker部署实战
* 部署架构选择
* 选择取决于项目的阶段和规模,Milvus 为从快速原型开发到大规模企业部署的各种需求提供了灵活而强大的解决方案。
- **Milvus Lite**建议用于较小的数据集,多达几百万个向量, 不支持WINDOWS系统。
- **Milvus Standalone**适用于中型数据集,可扩展至 1 亿向量。
- **Milvus Distributed 专为**大规模部署而设计,能够处理从一亿到数百亿向量的数据集。

* Milvus分层架构(Docker部署都包括了)
```python
┌───────────────────────────────┐
│ Coordinator │ ← 管理元数据、负载均衡
├───────────────┬───────────────┤
│ Query Node │ Data Node │ ← 处理查询与数据存储
├───────────────┴───────────────┤
│ Object Storage (S3) │ ← 持久化存储(可选MinIO、AWS S3)
└───────────────────────────────┘
```
* Milvus Standalone 是单机服务器部署,所有组件都打包到一个Docker 镜像中,部署方便。
* 此外,Milvus Standalone 通过主从复制支持高可用性。
* 有钱的当我没说,直接购买云厂商的服务:https://help.aliyun.com/zh/milvus
* LInux服务器部署Milvus实战
* 阿里云网络安全组记得开放端口 `2379`、`9091`, `19530`
* 注意: 默认没加权限校验,生产环境使用一般都是内网,结合配置IP白名单
* 版本和课程保持一致,不然很多不兼容!!!
* 下载相关资料 ,使用**【wget】或者【浏览器】远程下载相关依赖包(需要替换群里最新的)**
```python
原生资料下载方式(账号 - 密码 - ip地址 - 端口 需要替换群里最新的,【其他路径不变】)
wget --http-user=用户名 --http-password=密码 http://ip:端口/dcloud_pan/standalone_embed.sh
#比如 命令行下
wget --http-user=admin --http-password=xdclass.net888 http://47.115.31.28:9088/dcloud_pan/standalone_embed.sh
# 比如 浏览器直接访问
http://47.115.31.28:9088/dcloud_pan/standalone_embed.sh
```
* 解压后执行【**依赖很多,版本差异大,务必按照下面执行,否则课程无法进行下去,加我微信 xdclass6**】
```python
#启动
bash standalone_embed.sh start
#停止
bash standalone_embed.sh stop
#删除
bash standalone_embed.sh delete
#升级
bash standalone_embed.sh upgrade
```
* 运行安装脚本后
- 一个名为 Milvus 的 docker 容器已在**19530** 端口启动。
- 嵌入式 etcd 与 Milvus 安装在同一个容器中,服务端口为**2379**。
- Milvus 数据卷被映射到当前文件夹中的**volumes/milvus**
- 访问 `http://${MILVUS_PROXY_IP}:9091/webui` 例子: http://47.119.128.20:9091/webui/
* 注意
* Milvus Web UI 与 Attu等可视化工具 不同,它是一个内置工具,只是提供简单直观的界面,查看系统的基本信息
* 主要功能:运行环境、数据库/ Collections 详情、任务和慢查询请求,不支持数据库管理和操作任务
* 参考:https://milvus.io/docs/zh/milvus-webui.md
#### Milvus可视化客户端安装实战
* Attu 可视化客户端介绍
* 是一款专为 **Milvus 向量数据库**设计的开源图形化管理工具,通过直观的界面简化了数据库的日常操作与维护流程
* **跨平台支持**:提供 Docker 镜像,适配 Windows、Linux 和 macOS
* **开箱即用**:无需编写代码即可完成 Milvus 的日常管理,降低学习成本
* **社区与生态**:由 Zilliz 团队维护,与 Milvus 深度集成,持续更新功能
* **版本兼容性**:注意 Attu 与 Milvus 版本的匹配,避免接口不兼容问题【**当前安装的Milvus版本 V2.5X**】
* GitHub地址:https://github.com/zilliztech/attu

* 核心功能
* 数据库与集合管理
* 数据库管理:支持创建、删除数据库,默认提供 default 数据库且不可删除。
* 集合(Collection)操作:可创建集合、定义字段(主键、标量字段、向量字段)、构建索引,并支持数据导入/导出。
* 分区与分片:支持按业务需求划分分区(如按时间或用户组),优化查询效率;默认分片数为 2,支持水平扩展。
* 向量检索与混合查询
* 相似性搜索:输入向量即可快速检索 Top-K 相似结果,支持欧氏距离(L2)、余弦相似度等度量方式。
* 标量过滤:通过 Advanced Filter 功能结合标量字段(如价格、标签)进行条件筛选,提升搜索精准度。
* 数据加载与释放:可将数据加载至内存加速检索,或释放内存以优化资源占用。
* 用户与权限管理
* 多角色权限控制:支持创建用户与角色,并分配细粒度权限(如全局权限、集合操作权限)。
* 权限类型:涵盖数据插入、删除、查询等操作,
* 例如:
* 全局权限:创建/删除数据库、管理资源组。
* 集合权限:加载/释放数据、构建索引、执行搜索。
* 用户权限:更新用户凭证、查询用户信息
* 安装实战(根据系统选择对应的客户端下载,输入ip+端口)

### Milvus向量数据库多案例实战
#### Python整合向量数据库Milvus案例实战
* Python操作Milvus实战
* 安装 Milvus Python SDK, 支持 Python、Node.js、GO 和 Java SDK。
* 建议安装与所安装 Milvus 服务器版本相匹配的 PyMilvus 版本
* 安装
```
pip install pymilvus==2.5.5
```
* 验证安装 如果 PyMilvus 安装正确,运行以下命令时不会出现异常
```
python -c "from pymilvus import Collection"
```
* 接口可分为以下几类:
* **DDL / DCL:**createCollection / createPartition / dropCollection / dropPartition / hasCollection / hasPartition
* **DML / Produce:**插入 / 删除 / 上移
* **DQL:**搜索/查询
* 操作Milvus数据库
* 使用connect()连接 Milvus 服务器,进行相关操作
```python
#也可以使用MilvusClient
#from pymilvus import MilvusClient
#client = MilvusClient("http://47.119.128.20:19530")
from pymilvus import connections, db
conn = connections.connect(host="47.119.128.20", port=19530)
# 创建数据库
#db.create_database("my_database")
# 使用数据库
db.using_database("my_database")
# 列出数据库
dbs = db.list_database()
print(dbs)
#['default', 'my_database']
# 删除数据库
db.drop_database("my_database")
```
* Collection与Schema的创建和管理
* Collection 是一个二维表,具有固定的列和变化的行,每列代表一个字段,每行代表一个实体。
* 要实现这样的结构化数据管理,需要一个 Schema定义 Collections 的表结构
* 每个Schema由多个`FieldSchema`组成:
```python
from pymilvus import FieldSchema, DataType
# 字段定义示例
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=128),
FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=50)
]
```
* 字段类型详解
| 数据类型 | 说明 | 示例 |
| :-------------: | :----------: | :---------------: |
| `INT8/16/32/64` | 整型 | `DataType.INT64` |
| `FLOAT` | 单精度浮点数 | `DataType.FLOAT` |
| `DOUBLE` | 双精度浮点数 | `DataType.DOUBLE` |
| `VARCHAR` | 变长字符串 | `max_length=255` |
| `FLOAT_VECTOR` | 浮点向量 | `dim=768` |
* 创建collection实战
```python
from pymilvus import connections
from pymilvus import FieldSchema, DataType
from pymilvus import CollectionSchema, Collection
conn = connections.connect(host="47.119.128.20", port=19530)
# 步骤1:定义字段
fields = [
FieldSchema("id", DataType.INT64, is_primary=True),
FieldSchema("vector", DataType.FLOAT_VECTOR, dim=128),
FieldSchema("tag", DataType.VARCHAR, max_length=50)
]
# 步骤2:创建Schema
schema = CollectionSchema(fields, description="示例集合")
# 步骤3:实例化Collection
collection = Collection(
name="demo_collection",
schema=schema,
shards_num=2 # 分片数(分布式扩展关键)
)
```
* 关键参数解析
| 参数 | 说明 | 推荐值 |
| :-----------: | :------------------------: | :--------------: |
| `shards_num` | 分片数量(创建后不可修改) | 集群节点数×2 |
| `description` | 集合描述信息 | 建议填写业务用途 |
* 动态字段Schema
* 在集合中启用动态字段后,所有未在 Schema 中定义的字段及其值都将作为键值对存储在动态字段中
```python
# 启用动态字段(Milvus 2.3+)
schema = CollectionSchema(
fields,
enable_dynamic_field=True
)
```
* 案例讲解
* 假设 Collections Schema 只定义两个字段,名为`id` 和`vector` ,启用了动态字段,在 Collections 中插入以下数据集
* 数据集包含 多个实体,每个实体都包括字段`id`,`vector`, 和`color` ,Schema 中没有定义`color` 字段。
* 由于 Collections 启用了动态字段,因此字段`color` 将作为键值对存储在动态字段中。
```python
[
{id: 0, vector: [0.3580376395471989, -0.6023495712049978, 0.18414012509913835, -0.26286205330961354, 0.9029438446296592], color: "pink_8682"},
{id: 7, vector: [-0.33445148015177995, -0.2567135004164067, 0.8987539745369246, 0.9402995886420709, 0.5378064918413052], color: "grey_8510"},
{id: 8, vector: [0.39524717779832685, 0.4000257286739164, -0.5890507376891594, -0.8650502298996872, -0.6140360785406336], color: "white_9381"},
{id: 9, vector: [0.5718280481994695, 0.24070317428066512, -0.3737913482606834, -0.06726932177492717, -0.6980531615588608], color: "purple_4976"}
]
```
| 类型 | 特点 | 适用场景 |
| :------------: | :---------------------------: | :----------------------------: |
| **静态Schema** | 严格字段定义 | 数据结构固定的业务(用户画像) |
| **动态Schema** | 允许灵活字段(需Milvus 2.3+) | 日志类多变数据 |
#### Milvus索引操作和最佳实践避坑指南
* 为什么需要索引?
* 加速查询:避免暴力比对,快速定位相似向量, 平衡召回率与查询速度
* 节省资源:减少内存占用和计算开销, 建议为经常访问的向量和标量创建索引
* 常见的索引类型
| 索引类型 | 适用场景 | 内存占用 | 精度 | 构建速度 |
| :------: | :----------------------: | :------: | :-----: | :------: |
| FLAT | 小数据精确搜索(<100万) | 高 | 100% | 快 |
| IVF_FLAT | 大数据平衡场景(千万级) | 中 | 95%-98% | 较快 |
| HNSW | 高召回率需求 | 高 | 98%-99% | 慢 |
| DISKANN | 超大规模(10亿+) | 低 | 90%-95% | 最慢 |
* Milvus索引操作
* 创建索引
```python
# 导入MilvusClient和DataType模块,用于连接Milvus服务器并操作数据类型
from pymilvus import MilvusClient, DataType
# 实例化MilvusClient以连接到指定的Milvus服务器
client = MilvusClient(
uri="http://47.119.128.20:19530"
)
# 创建schema对象,设置自动ID生成和动态字段特性
schema = MilvusClient.create_schema(
auto_id=False,
enable_dynamic_field=True,
)
# 向schema中添加字段"id",数据类型为INT64,作为主键
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
# 向schema中添加字段"vector",数据类型为FLOAT_VECTOR,维度为5
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=5)
# 使用create_collection方法根据schema创建集合"customized_setup"
client.create_collection(
collection_name="customized_setup",
schema=schema,
)
# 准备索引参数,为"vector"字段创建索引
index_params = MilvusClient.prepare_index_params()
# 添加索引配置,指定字段名、度量类型、索引类型、索引名和参数
index_params.add_index(
field_name="vector",
metric_type="COSINE", # 距离计算方式 (L2/IP/COSINE)
index_type="IVF_FLAT",
index_name="vector_index",
params={ "nlist": 128 } #聚类中心数 (建议值:sqrt(数据量))
)
# 创建索引,不等待索引创建完成即返回
client.create_index(
collection_name="customized_setup",
index_params=index_params,
sync=False # 是否等待索引创建完成后再返回。默认为True。
)
```
* 参数说明
| 参数 | 参数 |
| ----------------- | ------------------------------------------------------------ |
| `field_name` | 指定字段名称 |
| `metric_type` | 用于衡量向量间相似性的算法。值有**IP**、**L2**、**COSINE**、**JACCARD**、**HAMMING**。只有当指定字段是向量字段时才可用。 |
| `index_type` | 索引类型 |
| `index_name` | 索引名称 |
| `params` | 指定索引类型的微调参数 |
| `collection_name` | Collections 的名称。 |
| `sync` | 控制与客户端请求相关的索引构建方式。有效值: `True` (默认):客户端等待索引完全建立后才返回。在该过程完成之前不会收到响应。`False`:客户端收到请求后立即返回,索引在后台建立 |
* 查看索引信息
```python
#列出索引名称
res = client.list_indexes(
collection_name="customized_setup"
)
print(res)
#获取索引详细信息
res = client.describe_index(
collection_name="customized_setup",
index_name="vector_index"
)
print(res)
```
* 删除索引
* 删除前需确保无查询正在使用该索引
* 删除后需重新创建索引才能进行有效查询
```python
#如果不再需要索引,可以直接将其删除。
client.drop_index(
collection_name="customized_setup",
index_name="vector_index"
)
print("索引已删除")
```
* 最佳实践与避坑指南
* **Schema设计原则**
- 主键选择
- 推荐自增ID避免冲突
- 禁止使用向量字段作为主键
- **字段数量**:单个集合不超过32个字段
- **向量维度**:创建后不可修改,需提前规划
* **索引选择策略**:
- 百万级以下 → FLAT
- 百万到亿级 → IVF/HNSW
- 十亿级以上 → DISKANN
* **操作规范**:
- 数据插入完成后再建索引
- 定期重建索引(数据变更超过30%)
- 为高频查询字段建立独立索引
* **常见错误处理**
| 错误场景 | 解决方案 |
| :--------------: | :----------------------------------: |
| "字段类型不匹配" | 检查插入数据与Schema定义的一致性 |
| "主键冲突" | 插入前检查ID唯一性,或使用自动生成ID |
| "向量维度错误" | 校验dim参数与数据实际维度 |
#### Milvus向量数据库的DML操作实战
* 核心DML操作实战
* 创建集合(Collection),集合是Milvus中数据存储的基本单位,需定义字段和索引
* `auto_id=True`时无需手动指定主键
* 动态字段(`enable_dynamic_field=True`)允许灵活扩展非预定义字段
```python
# 导入MilvusClient和DataType模块,用于连接Milvus服务器并操作数据类型
from pymilvus import MilvusClient, DataType
# 实例化MilvusClient以连接到指定的Milvus服务器
client = MilvusClient(
uri="http://47.119.128.20:19530"
)
# 定义Schema
schema = client.create_schema(auto_id=False, enable_dynamic_field=True)
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
schema.add_field(field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=128)
schema.verify() # 验证Schema
# 定义索引参数
index_params = client.prepare_index_params()
index_params.add_index(
field_name="vector",
index_type="IVF_FLAT", # 量化索引,平衡速度与精度
metric_type="L2", # 相似性度量标准(欧式距离)
params={"nlist": 1024} # 聚类中心数
)
# 创建集合
client.create_collection(
collection_name="my_collection",
schema=schema,
index_params=index_params
)
```
* 插入数据(Insert)支持单条或批量插入【可视化工具那边需要加载,包括查询等都是需要加载状态才可以操作】
```python
data = [
{"id": 1, "vector": [0.1]*128, "text": "Sample text 1"},
{"id": 2, "vector": [0.2]*128, "text": "Sample text 2"}
]
# 插入数据
insert_result = client.insert(
collection_name="my_collection",
data=data
)
print("插入ID列表:", insert_result["ids"]) # 返回主键ID
```
* 删除数据(Delete)通过主键或条件表达式删除
```python
# 按主键删除
client.delete(
collection_name="my_collection",
ids=[1, 2] # 主键列表
)
# 按条件删除(如删除text字段为空的记录)
client.delete(
collection_name="my_collection",
filter="text == ''"
)
```
* 更新数据(Update)Milvus不支持直接更新,需通过“删除+插入”实现:
```python
# 删除旧数据
client.delete(collection_name="my_collection", ids=[3])
# 插入新数据
client.insert(
collection_name="my_collection",
data=[{"id": 3, "vector": [0.3]*128, "text": "Updated text"}]
)
```
#### Milvus向量Search查询综合案例实战
* 需求说明
* 创建包含混合数据类型(标量+向量)的集合
* 批量插入结构化和非结构化数据
* 实现带过滤条件的混合查询
* 验证端到端的向量搜索流程
* Search语法深度解析
* 核心参数说明
```python
results = client 或 collection.search(
data=[[0.12, 0.23, ..., 0.88]], # 查询向量(必须)
anns_field="vector", # 要搜索的向量字段名(必须)
param={"metric_type": "L2", "params": {"nprobe": 10}}, # 搜索参数
limit=10, # 返回结果数量
expr="price > 50", # 过滤表达式(可选)
output_fields=["product_id", "price"], # 返回的字段
)
```
| 参数 | 类型 | 说明 | 常用值 |
| :-----------: | :--: | :----------: | :--------------------------------------: |
| data | list | 查询向量列表 | 二维数组 |
| anns_field | str | 向量字段名 | 创建时定义的字段 |
| param | dict | 搜索参数 | 包含metric_type和params |
| limit | int | 返回结果数 | 5-100 |
| expr | str | 过滤条件 | price > 50 AND category == 'electronics' |
| output_fields | list | 返回字段 | ["field1", "field2"] |
* 搜索案例实战(MilvusClient方式)
* 准备数据
```python
from pymilvus import (
connections,MilvusClient,
FieldSchema, CollectionSchema, DataType,
Collection, utility
)
import random
# # 创建Milvus客户端
client = MilvusClient(
uri="http://47.119.128.20:19530",
)
#删除已存在的同名集合
if client.has_collection("book"):
client.drop_collection("book")
# 定义字段
fields = [
FieldSchema(name="book_id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=50),
FieldSchema(name="price", dtype=DataType.DOUBLE),
FieldSchema(name="book_intro", dtype=DataType.FLOAT_VECTOR, dim=4)
]
# 创建集合Schema
schema = CollectionSchema(
fields=fields,
description="Book search collection"
)
#创建集合
client.create_collection(collection_name="book", schema=schema)
# 生成测试数据
num_books = 1000
categories = ["科幻", "科技", "文学", "历史"]
titles = ["量子世界", "AI简史", "时光之轮", "文明起源", "未来简史", "数据科学"]
data = []
for i in range(num_books):
data.append({
"title": f"{random.choice(titles)}_{i}",
"category": random.choice(categories),
"price": round(random.uniform(10, 100), 2),
"book_intro": [random.random() for _ in range(4)] # 4维向量
})
# 批量插入
insert_result = client.insert(
collection_name="book",
data=data
)
print(f"插入数据量:{len(insert_result['ids'])}")
```
* 创建索引
```python
# 准备索引参数,为"vector"字段创建索引
index_params = MilvusClient.prepare_index_params()
# 添加索引配置,指定字段名、度量类型、索引类型、索引名和参数
index_params.add_index(
field_name="book_intro",
metric_type="L2", # 距离计算方式 (L2/IP/COSINE)
index_type="IVF_FLAT",
index_name="vector_index",
params={ "nlist": 128 } #聚类中心数 (建议值:sqrt(数据量))
)
# 创建索引,不等待索引创建完成即返回
client.create_index(
collection_name="book",
index_params=index_params
)
print("索引创建完成")
```
* 执行查询【执行查询前需要加载才可以使用】
```python
client.load_collection(collection_name="book") # 加载集合到内存
# 生成查询向量
query_vector = [random.random() for _ in range(4)]
# 执行带过滤条件的向量搜索
results = client.search(
collection_name="book",
data=[query_vector], # 支持批量查询
filter="category == '科幻' and price < 50",
output_fields=["title", "category", "price"],
limit=3,
search_params={"nprobe": 10}
)
# 解析结果
print("\n科幻类且价格<50的搜索结果:")
for result in results[0]: # 第一个查询结果集
print(f"ID: {result['book_id']}")
print(f"距离: {result['distance']:.4f}")
print(f"标题: {result['entity']['title']}")
print(f"价格: {result['entity']['price']:.2f}")
print("-" * 30)
```
* 向量数据库完整工作流程示意图
```
1. 创建集合Schema
↓
2. 插入测试数据
↓
3. 创建向量索引
↓
4. 加载集合到内存
↓
5. 执行混合查询(向量+标量过滤)
```
* 全量查询案例演示
* 测试是否有 output_fields 字段,返回结果的差异
```python
# 案例1:基础向量查询
basic_res = client.search(
collection_name="book",
data=[query_vector],
limit=5
)
# 案例2:分页查询
page_res = client.search(
collection_name="book",
data=[query_vector],
offset=2,
limit=3
)
# 案例3:批量查询
batch_res = client.search(
collection_name="book",
data=[query_vector, [0.5]*4], # 同时查询两个向量,每个向量都会返回2条
limit=2
)
```
* 集合状态
```python
# 验证集合状态
print(client.describe_collection("book"))
# 索引状态检查
print(client.list_indexes("book"))
```
* 新旧版本对比表
| 功能 | PyMilvus旧版 | MilvusClient新版 |
| :----------- | :---------------------- | :---------------------------- |
| 连接管理 | 需要手动管理connections | 客户端自动管理 |
| 数据插入格式 | 多列表结构 | 字典列表 |
| 字段定义 | 使用FieldSchema | 在create_collection中直接定义 |
| 返回结果格式 | 对象属性访问 | 标准化字典格式 |
| 错误处理 | 异常类捕获 | 统一错误码系统 |
| 动态字段支持 | 需要额外配置 | 参数开启即可 |
### MMR搜索和LangChain整合Milvus实战
#### 相似度Similarity和MMR最大边界相关搜索
* 搜索的行业应用案例:电商推荐系统(明白两个差异)
* **相似度搜索**:
```
"用户点击商品A → 推荐相似商品B、C"
```
* **MMR搜索**:
```
"用户浏览历史多样 → 推荐跨品类商品"
```
* 基础相似度搜索(Similarity Search)
* **原理**:通过向量空间中的距离计算(余弦相似度/L2距离等)找出最接近目标向量的结果
 * 核心特点
* **纯向量驱动**:仅依赖向量空间中的几何距离,余弦相似度、L2距离
* **结果同质化**:返回最相似的连续区域数据
* **高性能**:时间复杂度 O(n + klogk)
* 参数配置模板,方法 `vector_store.similarity_search( )`
```python
vector_store.as_retriever(
search_type="similarity",
search_kwargs={
"k": 5, # 返回数量
"score_threshold": 0.65, # 相似度得分的最低要求,相似度≥65%的才考虑
"filter": "category == 'AI'", # 元数据过滤
"param": { # Milvus专属参数
"nprobe": 32, #nprobe是Milvus中用于控制搜索时访问的聚类数量的参数,nprobe越大,搜索越精确但耗时更长。
"radius": 0.8 #是在范围搜索中使用的参数,指定搜索的半径范围,结合score_threshold可用于限定结果的范围
}
}
)
```
* 典型应用场景
* 精确语义匹配(专利检索、论文查重)
* 基于内容的推荐("更多类似内容")
* 敏感信息过滤(高阈值精准匹配)
* 最大边界相关搜索(MMR Search)
* Maximal Marginal Relevance,最大边际相关性, 是一种信息检索和推荐系统中常用的算法
* 核心目标是 在返回的结果中平衡相关性与多样性,避免返回大量高度相似的内容。
* 设计初衷是解决传统相似性搜索(如余弦相似度)可能导致的“信息冗余”问题,在需要覆盖多角度信息或推荐多样化内容的场景中效果显著
* **原理**:在相似度和多样性之间进行权衡,避免结果冗余
* 核心特点
* **纯向量驱动**:仅依赖向量空间中的几何距离,余弦相似度、L2距离
* **结果同质化**:返回最相似的连续区域数据
* **高性能**:时间复杂度 O(n + klogk)
* 参数配置模板,方法 `vector_store.similarity_search( )`
```python
vector_store.as_retriever(
search_type="similarity",
search_kwargs={
"k": 5, # 返回数量
"score_threshold": 0.65, # 相似度得分的最低要求,相似度≥65%的才考虑
"filter": "category == 'AI'", # 元数据过滤
"param": { # Milvus专属参数
"nprobe": 32, #nprobe是Milvus中用于控制搜索时访问的聚类数量的参数,nprobe越大,搜索越精确但耗时更长。
"radius": 0.8 #是在范围搜索中使用的参数,指定搜索的半径范围,结合score_threshold可用于限定结果的范围
}
}
)
```
* 典型应用场景
* 精确语义匹配(专利检索、论文查重)
* 基于内容的推荐("更多类似内容")
* 敏感信息过滤(高阈值精准匹配)
* 最大边界相关搜索(MMR Search)
* Maximal Marginal Relevance,最大边际相关性, 是一种信息检索和推荐系统中常用的算法
* 核心目标是 在返回的结果中平衡相关性与多样性,避免返回大量高度相似的内容。
* 设计初衷是解决传统相似性搜索(如余弦相似度)可能导致的“信息冗余”问题,在需要覆盖多角度信息或推荐多样化内容的场景中效果显著
* **原理**:在相似度和多样性之间进行权衡,避免结果冗余
 * 算法原理图解
```
初始候选集(fetch_k=20)
│
├── 相似度排序
│ [1, 2, 3, ..., 20]
│
└── 多样性选择(λ=0.5)
↓
最终结果(k=5)
[1, 5, 12, 3, 18] # 兼顾相似与差异
```
* 参数配置模板, 方法 `vector_store.max_marginal_relevance_search( )`
```python
mmr_retriever = vector_store.as_retriever(
search_type="mmr",
search_kwargs={
"k": 3, #最终返回的结果数量,MMR 会从更大的候选集中筛选出 3 个最相关且多样化的结果
"fetch_k": 20, #指定 MMR 算法的候选集大小,fetch_k 越大,候选集越广,结果可能越多样,但计算成本更高
"lambda_mult": 0.6, #控制相关性与多样性之间的权衡系数。范围为 [0, 1]:接近1 结果更相似。接近0:结果差异更大
"param": {
"nprobe": 64, # 针对Milvus的IVF 类索引,控制搜索的聚类数量,搜索的聚类范围越广,召回率越高,但速度越慢
"ef": 128 # Milvus HNSW索引,控制搜索的深度,值越大搜索越精确,耗时增加;值越小速度更快,可能漏掉相关结果
}
}
)
```
* 关键参数解析
| 参数 | 相似度搜索 | MMR搜索 | 影响效果 |
| :-------------: | :------------: | :--------------: | :------------------------------------: |
| k | 控制结果数量 | 控制最终结果数量 | 值越大返回越多但可能降低精度 |
| lambda_mult | 无 | 0-1之间 | 值越大越偏向相关性,值越小越强调多样性 |
| score_threshold | 过滤低质量结果 | 通常不使用 | 阈值设置需根据embedding模型调整 |
| filter | 元数据过滤 | 支持同左 | 可结合业务维度进行筛选 |
* 典型应用场景
* 多样化推荐:电商跨品类推荐
* 知识发现:科研文献探索
* 内容生成:生成多样化文案
* 对比决策矩阵
| 维度 | Similarity Search | MMR Search |
| :----------: | :----------------: | :-----------------: |
| **结果质量** | 高相似度但可能重复 | 多样性更佳 |
| **响应速度** | 平均 120ms | 平均 200-300ms |
| **内存消耗** | 低(仅存储topK) | 高(需缓存fetch_k) |
| **适用场景** | 精确匹配、去重 | 推荐系统、知识发现 |
| **可解释性** | 直观的相似度排序 | 综合评分需二次解释 |
* 企业推荐系统架构示例
* 算法原理图解
```
初始候选集(fetch_k=20)
│
├── 相似度排序
│ [1, 2, 3, ..., 20]
│
└── 多样性选择(λ=0.5)
↓
最终结果(k=5)
[1, 5, 12, 3, 18] # 兼顾相似与差异
```
* 参数配置模板, 方法 `vector_store.max_marginal_relevance_search( )`
```python
mmr_retriever = vector_store.as_retriever(
search_type="mmr",
search_kwargs={
"k": 3, #最终返回的结果数量,MMR 会从更大的候选集中筛选出 3 个最相关且多样化的结果
"fetch_k": 20, #指定 MMR 算法的候选集大小,fetch_k 越大,候选集越广,结果可能越多样,但计算成本更高
"lambda_mult": 0.6, #控制相关性与多样性之间的权衡系数。范围为 [0, 1]:接近1 结果更相似。接近0:结果差异更大
"param": {
"nprobe": 64, # 针对Milvus的IVF 类索引,控制搜索的聚类数量,搜索的聚类范围越广,召回率越高,但速度越慢
"ef": 128 # Milvus HNSW索引,控制搜索的深度,值越大搜索越精确,耗时增加;值越小速度更快,可能漏掉相关结果
}
}
)
```
* 关键参数解析
| 参数 | 相似度搜索 | MMR搜索 | 影响效果 |
| :-------------: | :------------: | :--------------: | :------------------------------------: |
| k | 控制结果数量 | 控制最终结果数量 | 值越大返回越多但可能降低精度 |
| lambda_mult | 无 | 0-1之间 | 值越大越偏向相关性,值越小越强调多样性 |
| score_threshold | 过滤低质量结果 | 通常不使用 | 阈值设置需根据embedding模型调整 |
| filter | 元数据过滤 | 支持同左 | 可结合业务维度进行筛选 |
* 典型应用场景
* 多样化推荐:电商跨品类推荐
* 知识发现:科研文献探索
* 内容生成:生成多样化文案
* 对比决策矩阵
| 维度 | Similarity Search | MMR Search |
| :----------: | :----------------: | :-----------------: |
| **结果质量** | 高相似度但可能重复 | 多样性更佳 |
| **响应速度** | 平均 120ms | 平均 200-300ms |
| **内存消耗** | 低(仅存储topK) | 高(需缓存fetch_k) |
| **适用场景** | 精确匹配、去重 | 推荐系统、知识发现 |
| **可解释性** | 直观的相似度排序 | 综合评分需二次解释 |
* 企业推荐系统架构示例
 #### 新版LangChain向量数据库VectorStore设计
* LangChain 向量存储体系架构
* RAG系统核心设计模式
```
Document
│
▼
Text Splitter
│
▼
Embedding Model
│
▼
[Milvus|Chroma|Pinecone...] ←→ VectorStore
```
* LangChain设计抽象类`VectorStore`,统一接口,具体的实现由各自数据库负责
* 文档(如果过期就忽略) https://python.langchain.com/docs/integrations/vectorstores/
* 安装依赖 `pip install langchain-milvus`
```
from langchain_core.vectorstores import VectorStore
```
#### 新版LangChain向量数据库VectorStore设计
* LangChain 向量存储体系架构
* RAG系统核心设计模式
```
Document
│
▼
Text Splitter
│
▼
Embedding Model
│
▼
[Milvus|Chroma|Pinecone...] ←→ VectorStore
```
* LangChain设计抽象类`VectorStore`,统一接口,具体的实现由各自数据库负责
* 文档(如果过期就忽略) https://python.langchain.com/docs/integrations/vectorstores/
* 安装依赖 `pip install langchain-milvus`
```
from langchain_core.vectorstores import VectorStore
```
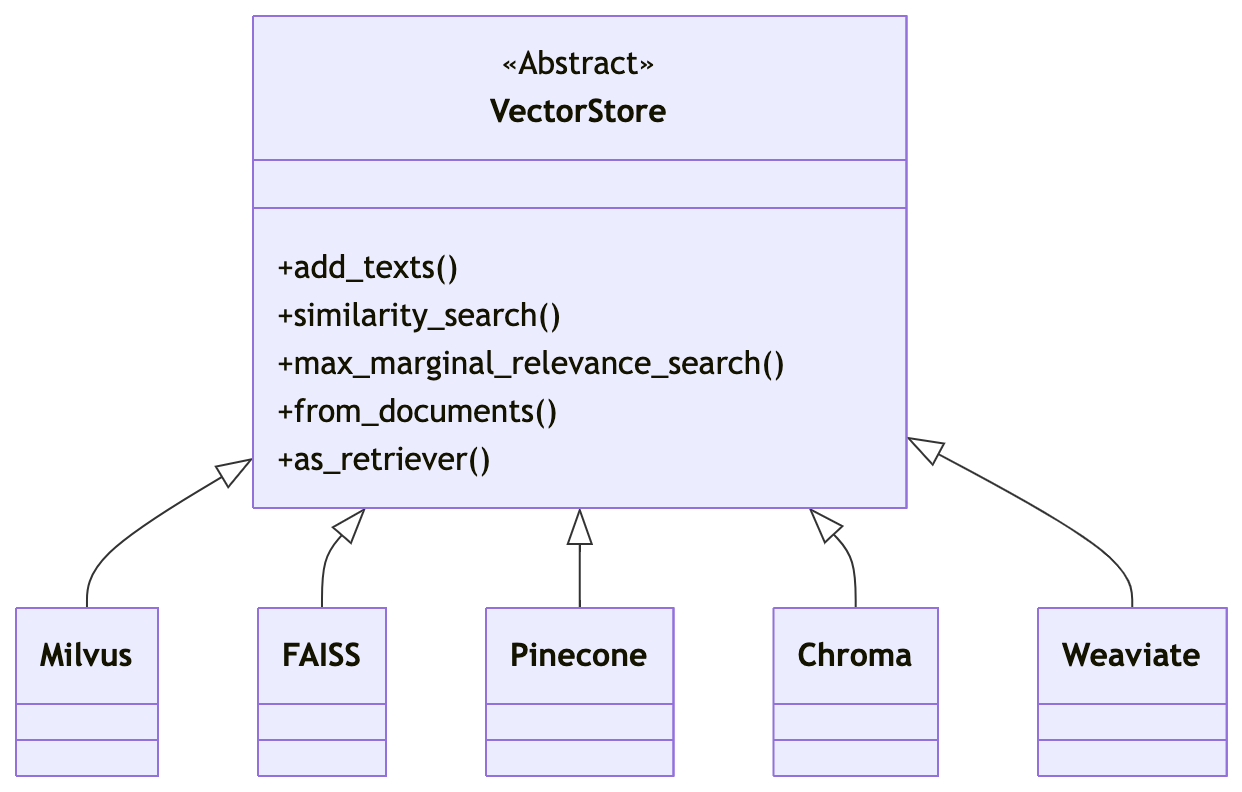 * VectorStore 核心方法详解
* 通用方法列表
| 方法名 | 作用描述 | 常用参数示例 |
| :------------------------------: | :--------------------: | :----------------------------: |
| from_documents() | 从文档创建向量库 | documents, embedding, **kwargs |
| add_documents() | 追加文档到已有库 | documents |
| similarity_search() | 相似度查询 | query, k=4 |
| similarity_search_with_score() | 带相似度得分的查询 | query, k=4 |
| max_marginal_relevance_search( ) | MMR最大边界搜索 | query, k=4 |
| as_retriever() | 转换为检索器供链式调用 | search_kwargs={} |
* 初始化方法
```python
@classmethod
def from_documents(
cls,
documents: List[Document],
embedding: Embeddings,
**kwargs
) -> VectorStore:
"""
文档自动转换存储
:param documents: LangChain Document对象列表
:param embedding: 文本向量化模型
:param kwargs: 向量库特有参数
:return: 初始化的VectorStore实例
"""
```
* 和`add_documents()`区别
| 特性 | `from_documents()` | `add_documents()` |
| :----------: | :----------------------: | :--------------------: |
| **方法类型** | 类方法(静态方法) | 实例方法 |
| **主要用途** | 初始化集合并批量插入文档 | 向已存在的集合追加文档 |
| **集合创建** | 自动创建新集合 | 要求集合已存在 |
| **性能消耗** | 高(需建索引+数据迁移) | 低(仅数据插入) |
| **典型场景** | 首次数据入库 | 增量数据更新 |
| **连接参数** | 需要完整连接配置 | 复用已有实例的配置 |
* 数据插入方法
```
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
**kwargs
) -> List[str]:
"""
插入文本数据到向量库
:param texts: 文本内容列表
:param metadatas: 对应的元数据列表
:return: 插入文档的ID列表
"""
```
* 相似性搜索方法
```python
def similarity_search(
self,
query: str,
k: int = 4,
filter: Optional[dict] = None,
**kwargs
) -> List[Document]:
"""
执行相似性搜索
:param query: 查询文本
:param k: 返回结果数量
:param filter: 元数据过滤条件
:return: 匹配的Document列表
"""
```
* 最大边界相关算法(MMR)
```python
def max_marginal_relevance_search(
self,
query: str,
k: int = 4,
fetch_k: int = 20,
lambda_mult: float = 0.5
) -> List[Document]:
"""
多样性增强搜索
:param k: 返回结果数量
:param fetch_k: 初始获取数量
:param lambda_mult: 多样性权重(0-1)
"""
```
* 不同向量数据库支持特性不一样
| 特性 | Milvus | FAISS | Pinecone | Chroma |
| :----------: | :----: | :---: | :------: | :----: |
| 分布式支持 | ✓ | ✗ | ✓ | ✗ |
| 元数据过滤 | ✓ | ✗ | ✓ | ✓ |
| 自动索引管理 | ✓ | ✗ | ✓ | ✓ |
| 本地运行 | ✓ | ✓ | ✗ | ✓ |
| 相似度算法 | 8种 | 4种 | 3种 | 2种 |
* 场景:知识库冷启动
* VectorStore 核心方法详解
* 通用方法列表
| 方法名 | 作用描述 | 常用参数示例 |
| :------------------------------: | :--------------------: | :----------------------------: |
| from_documents() | 从文档创建向量库 | documents, embedding, **kwargs |
| add_documents() | 追加文档到已有库 | documents |
| similarity_search() | 相似度查询 | query, k=4 |
| similarity_search_with_score() | 带相似度得分的查询 | query, k=4 |
| max_marginal_relevance_search( ) | MMR最大边界搜索 | query, k=4 |
| as_retriever() | 转换为检索器供链式调用 | search_kwargs={} |
* 初始化方法
```python
@classmethod
def from_documents(
cls,
documents: List[Document],
embedding: Embeddings,
**kwargs
) -> VectorStore:
"""
文档自动转换存储
:param documents: LangChain Document对象列表
:param embedding: 文本向量化模型
:param kwargs: 向量库特有参数
:return: 初始化的VectorStore实例
"""
```
* 和`add_documents()`区别
| 特性 | `from_documents()` | `add_documents()` |
| :----------: | :----------------------: | :--------------------: |
| **方法类型** | 类方法(静态方法) | 实例方法 |
| **主要用途** | 初始化集合并批量插入文档 | 向已存在的集合追加文档 |
| **集合创建** | 自动创建新集合 | 要求集合已存在 |
| **性能消耗** | 高(需建索引+数据迁移) | 低(仅数据插入) |
| **典型场景** | 首次数据入库 | 增量数据更新 |
| **连接参数** | 需要完整连接配置 | 复用已有实例的配置 |
* 数据插入方法
```
def add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
**kwargs
) -> List[str]:
"""
插入文本数据到向量库
:param texts: 文本内容列表
:param metadatas: 对应的元数据列表
:return: 插入文档的ID列表
"""
```
* 相似性搜索方法
```python
def similarity_search(
self,
query: str,
k: int = 4,
filter: Optional[dict] = None,
**kwargs
) -> List[Document]:
"""
执行相似性搜索
:param query: 查询文本
:param k: 返回结果数量
:param filter: 元数据过滤条件
:return: 匹配的Document列表
"""
```
* 最大边界相关算法(MMR)
```python
def max_marginal_relevance_search(
self,
query: str,
k: int = 4,
fetch_k: int = 20,
lambda_mult: float = 0.5
) -> List[Document]:
"""
多样性增强搜索
:param k: 返回结果数量
:param fetch_k: 初始获取数量
:param lambda_mult: 多样性权重(0-1)
"""
```
* 不同向量数据库支持特性不一样
| 特性 | Milvus | FAISS | Pinecone | Chroma |
| :----------: | :----: | :---: | :------: | :----: |
| 分布式支持 | ✓ | ✗ | ✓ | ✗ |
| 元数据过滤 | ✓ | ✗ | ✓ | ✓ |
| 自动索引管理 | ✓ | ✗ | ✓ | ✓ |
| 本地运行 | ✓ | ✓ | ✗ | ✓ |
| 相似度算法 | 8种 | 4种 | 3种 | 2种 |
* 场景:知识库冷启动
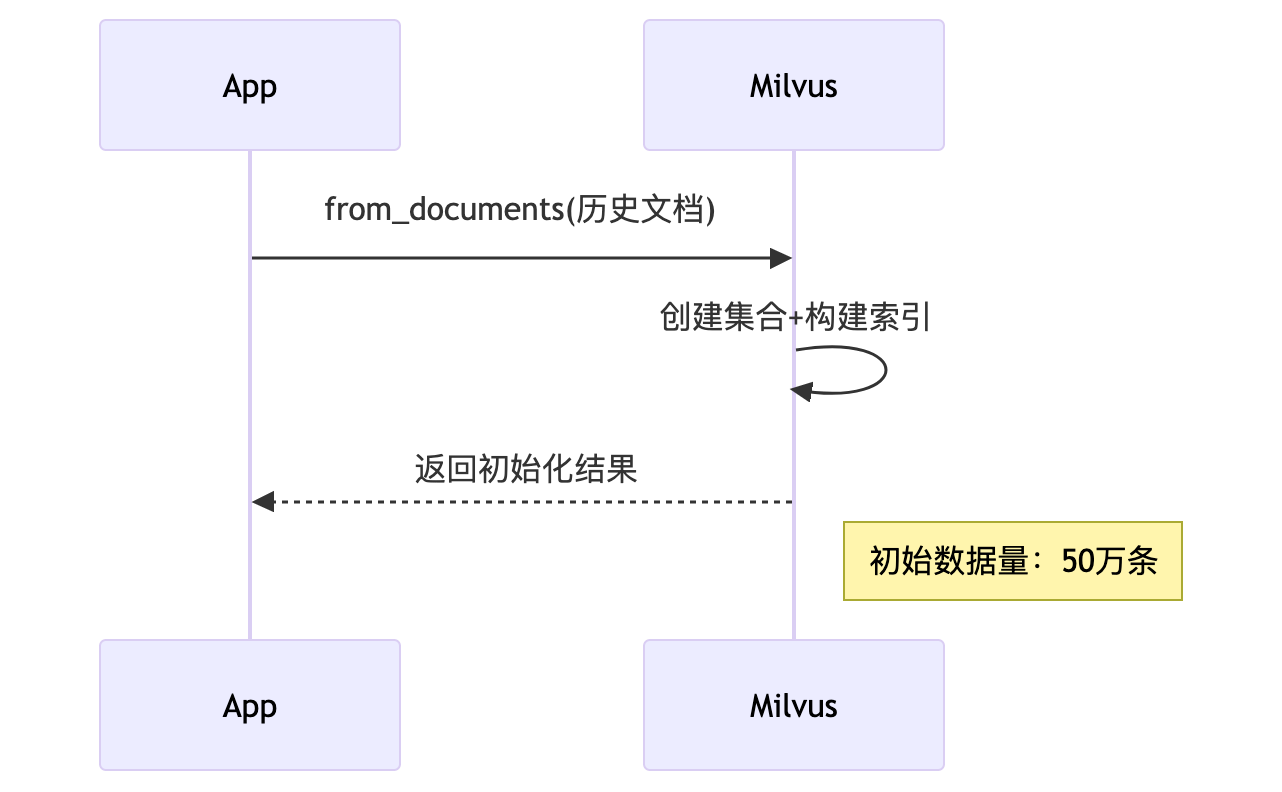 #### LangChain整合Milvus新增和删除实战
* 需求
* 使用LangChain整合向量数据库Milvus
* 实现新增和删除向量数据库的数据实战
* 文档(如果过期就忽略)
* https://python.langchain.com/docs/integrations/vectorstores/milvus/
* 案例实战
* 准备数据
```python
from langchain_community.embeddings import DashScopeEmbeddings
#from langchain.vectorstores import Milvus
from langchain_milvus import Milvus
from langchain_core.documents import Document
from uuid import uuid4
# 初始化模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
vector_store = Milvus(
embeddings,
connection_args={"uri": "http://47.119.128.20:19530"},
collection_name="langchain_example",
)
document_1 = Document(
page_content="I had chocolate chip pancakes and scrambled eggs for breakfast this morning.",
metadata={"source": "tweet"},
)
document_2 = Document(
page_content="The weather forecast for tomorrow is cloudy and overcast, with a high of 62 degrees.",
metadata={"source": "news"},
)
document_3 = Document(
page_content="Building an exciting new project with LangChain - come check it out!",
metadata={"source": "tweet"},
)
document_4 = Document(
page_content="Robbers broke into the city bank and stole $1 million in cash.",
metadata={"source": "news"},
)
document_5 = Document(
page_content="Wow! That was an amazing movie. I can't wait to see it again.",
metadata={"source": "tweet"},
)
document_6 = Document(
page_content="Is the new iPhone worth the price? Read this review to find out.",
metadata={"source": "website"},
)
document_7 = Document(
page_content="The top 10 soccer players in the world right now.",
metadata={"source": "website"},
)
document_8 = Document(
page_content="LangGraph is the best framework for building stateful, agentic applications!",
metadata={"source": "tweet"},
)
document_9 = Document(
page_content="The stock market is down 500 points today due to fears of a recession.",
metadata={"source": "news"},
)
document_10 = Document(
page_content="I have a bad feeling I am going to get deleted :(",
metadata={"source": "tweet"},
)
documents = [
document_1,document_2,document_3,document_4,document_5,document_6,
document_7,document_8,document_9,document_10,
]
```
* 插入
```python
ids = [ str(i+1) for i in range(len(documents))]
print(ids)
result = vector_store.add_documents(documents=documents, ids=ids)
print(result)
```
* 删除
```python
result = vector_store.delete(ids=["1"])
print(result)
#(insert count: 0, delete count: 1, upsert count: 0, timestamp: 456798840753225732, success count: 0, err count: 0
```
#### LangChain实战MMR和相似性搜索实战
* 需求
* 使用LangChain整合向量数据库Milvus
* 测试相关搜索:相似度搜索和MMR搜索
* 案例实战
* 准备数据【**执行多次有多条重复记录,向量数据库不会去重,方便测试MMR**】
```python
from langchain_community.embeddings import DashScopeEmbeddings
#from langchain.vectorstores import Milvus
from langchain_milvus import Milvus
from langchain_core.documents import Document
# 初始化模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
document_1 = Document(
page_content="LangChain支持多种数据库集成,小滴课堂的AI大课",
metadata={"source": "xdclass.net/doc1"},
)
document_2 = Document(
page_content="Milvus擅长处理向量搜索,老王的课程不错",
metadata={"source": "xdclass.net/doc2"},
)
document_3 = Document(
page_content="我要去学小滴课堂的架构大课",
metadata={"source": "xdclass.net/doc3"},
)
document_4 = Document(
page_content="今天天气不错,老王和老帆去按摩了",
metadata={"source": "xdclass.net/doc4"},
)
documents = [document_1,document_2,document_3,document_4]
vector_store = Milvus.from_documents(
documents=documents,
embedding=embeddings,
collection_name="mmr_test",
connection_args={"uri": "http://47.119.128.20:19530"}
)
```
* 相似性搜索(向量数据库插入多个重复数据,看是否会返回一样的)
```python
# 相似性搜索
query = "如何进行数据库集成?"
results = vector_store.similarity_search(query, k=2)
for doc in results:
print(f"内容:{doc.page_content}\n元数据:{doc.metadata}\n")
# 混合搜索(结合元数据过滤)
results = vector_store.similarity_search(
query,
k=2,
expr='source == "xdclass.net/doc1"'
)
print(results)
```
* MMR搜索(跨类搭配,向量数据库插入多个重复数据,看是否会返回一样的)
```python
# MMR推荐(跨类搭配)
diverse_results = vector_store.max_marginal_relevance_search(
query="如何进行数据库集成",
k=2,
fetch_k=10,
lambda_mult=0.4,
# expr="category in ['shoes', 'clothes', 'accessories']",
search_params={
"metric_type": "IP",
"params": {"nprobe": 32}
}
)
print(diverse_results)
```
### Retrievers检索器+RAG文档助手项目实战
#### LangChain检索器Retrievers案例实战
* 什么是`Retriever`
* **统一接口**:标准化检索流程,无论数据来源如何,最终输出`Document`对象列表。
* **多源混合检索**:支持同时查询向量库、传统数据库和搜索引擎【提高召回率】
* **与VectorStore的关系**:Retriever不直接管理存储,依赖VectorStore(如FAISS、Chroma)实现向量化与检索。
* **RAG中的角色**:作为检索增强生成(RAG)流程的“数据入口”,为生成模型提供精准上下文
#### LangChain整合Milvus新增和删除实战
* 需求
* 使用LangChain整合向量数据库Milvus
* 实现新增和删除向量数据库的数据实战
* 文档(如果过期就忽略)
* https://python.langchain.com/docs/integrations/vectorstores/milvus/
* 案例实战
* 准备数据
```python
from langchain_community.embeddings import DashScopeEmbeddings
#from langchain.vectorstores import Milvus
from langchain_milvus import Milvus
from langchain_core.documents import Document
from uuid import uuid4
# 初始化模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
vector_store = Milvus(
embeddings,
connection_args={"uri": "http://47.119.128.20:19530"},
collection_name="langchain_example",
)
document_1 = Document(
page_content="I had chocolate chip pancakes and scrambled eggs for breakfast this morning.",
metadata={"source": "tweet"},
)
document_2 = Document(
page_content="The weather forecast for tomorrow is cloudy and overcast, with a high of 62 degrees.",
metadata={"source": "news"},
)
document_3 = Document(
page_content="Building an exciting new project with LangChain - come check it out!",
metadata={"source": "tweet"},
)
document_4 = Document(
page_content="Robbers broke into the city bank and stole $1 million in cash.",
metadata={"source": "news"},
)
document_5 = Document(
page_content="Wow! That was an amazing movie. I can't wait to see it again.",
metadata={"source": "tweet"},
)
document_6 = Document(
page_content="Is the new iPhone worth the price? Read this review to find out.",
metadata={"source": "website"},
)
document_7 = Document(
page_content="The top 10 soccer players in the world right now.",
metadata={"source": "website"},
)
document_8 = Document(
page_content="LangGraph is the best framework for building stateful, agentic applications!",
metadata={"source": "tweet"},
)
document_9 = Document(
page_content="The stock market is down 500 points today due to fears of a recession.",
metadata={"source": "news"},
)
document_10 = Document(
page_content="I have a bad feeling I am going to get deleted :(",
metadata={"source": "tweet"},
)
documents = [
document_1,document_2,document_3,document_4,document_5,document_6,
document_7,document_8,document_9,document_10,
]
```
* 插入
```python
ids = [ str(i+1) for i in range(len(documents))]
print(ids)
result = vector_store.add_documents(documents=documents, ids=ids)
print(result)
```
* 删除
```python
result = vector_store.delete(ids=["1"])
print(result)
#(insert count: 0, delete count: 1, upsert count: 0, timestamp: 456798840753225732, success count: 0, err count: 0
```
#### LangChain实战MMR和相似性搜索实战
* 需求
* 使用LangChain整合向量数据库Milvus
* 测试相关搜索:相似度搜索和MMR搜索
* 案例实战
* 准备数据【**执行多次有多条重复记录,向量数据库不会去重,方便测试MMR**】
```python
from langchain_community.embeddings import DashScopeEmbeddings
#from langchain.vectorstores import Milvus
from langchain_milvus import Milvus
from langchain_core.documents import Document
# 初始化模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
document_1 = Document(
page_content="LangChain支持多种数据库集成,小滴课堂的AI大课",
metadata={"source": "xdclass.net/doc1"},
)
document_2 = Document(
page_content="Milvus擅长处理向量搜索,老王的课程不错",
metadata={"source": "xdclass.net/doc2"},
)
document_3 = Document(
page_content="我要去学小滴课堂的架构大课",
metadata={"source": "xdclass.net/doc3"},
)
document_4 = Document(
page_content="今天天气不错,老王和老帆去按摩了",
metadata={"source": "xdclass.net/doc4"},
)
documents = [document_1,document_2,document_3,document_4]
vector_store = Milvus.from_documents(
documents=documents,
embedding=embeddings,
collection_name="mmr_test",
connection_args={"uri": "http://47.119.128.20:19530"}
)
```
* 相似性搜索(向量数据库插入多个重复数据,看是否会返回一样的)
```python
# 相似性搜索
query = "如何进行数据库集成?"
results = vector_store.similarity_search(query, k=2)
for doc in results:
print(f"内容:{doc.page_content}\n元数据:{doc.metadata}\n")
# 混合搜索(结合元数据过滤)
results = vector_store.similarity_search(
query,
k=2,
expr='source == "xdclass.net/doc1"'
)
print(results)
```
* MMR搜索(跨类搭配,向量数据库插入多个重复数据,看是否会返回一样的)
```python
# MMR推荐(跨类搭配)
diverse_results = vector_store.max_marginal_relevance_search(
query="如何进行数据库集成",
k=2,
fetch_k=10,
lambda_mult=0.4,
# expr="category in ['shoes', 'clothes', 'accessories']",
search_params={
"metric_type": "IP",
"params": {"nprobe": 32}
}
)
print(diverse_results)
```
### Retrievers检索器+RAG文档助手项目实战
#### LangChain检索器Retrievers案例实战
* 什么是`Retriever`
* **统一接口**:标准化检索流程,无论数据来源如何,最终输出`Document`对象列表。
* **多源混合检索**:支持同时查询向量库、传统数据库和搜索引擎【提高召回率】
* **与VectorStore的关系**:Retriever不直接管理存储,依赖VectorStore(如FAISS、Chroma)实现向量化与检索。
* **RAG中的角色**:作为检索增强生成(RAG)流程的“数据入口”,为生成模型提供精准上下文
 * 有多个实现:VectorStoreRetriever、MultiQueryRetriever、SelfQueryRetriever等
* 特点
* **模块化设计**:支持插件式扩展,可自定义检索算法(如混合搜索、重排序)。
* **异步支持**:通过`async_get_relevant_documents`实现高并发场景下的高效检索。
* **链式调用**:可与LangChain的其他组件(如Text Splitters、Memory)无缝集成。
```
# from langchain_core.retrievers import BaseRetriever
```
* 补充知识点:召回率(Recall)信息检索和机器学习中衡量模型找全相关结果能力的核心指标
* 比如
* 在文档检索中,如果有100篇相关文档,系统找出了80篇,那么召回率就是80%。
* 召回率高意味着系统漏掉的少,但可能夹杂了不相关的结果,这时候准确率可能低。
* Retriever常见类型之基础检索器 `VectorStoreRetriever`
* 基础使用参考案例
```python
#将文档嵌入为向量,通过相似度计算(如余弦相似度)检索
from langchain_community.vectorstores import FAISS
retriever = FAISS.from_documents(docs, embeddings).as_retriever(
search_type="mmr", # 最大边际相关性
search_kwargs={"k": 5, "filter": {"category": "news"}}
)
```
* `as_retriever()` 方法介绍
* 将向量库实例转换为检索器对象,实现与 LangChain 链式调用(如 `RetrievalQA`)的无缝对接。
* 源码
```python
def as_retriever(self, **kwargs: Any) -> VectorStoreRetriever:
tags = kwargs.pop("tags", None) or [] + self._get_retriever_tags()
return VectorStoreRetriever(vectorstore=self, tags=tags, **kwargs)
"""
向量库实例转换为检索器对象,实现与 LangChain 链式调用
"""
```
* 关键参数详解
* search_type 搜索类型
| 类型 | 适用场景 | Milvus 对应操作 |
| :----------------------------: | :------------: | :-------------------------------: |
| `"similarity"` | 基础相似度检索 | `search()` |
| `"mmr"` | 多样性结果优化 | `max_marginal_relevance_search()` |
| `"similarity_score_threshold"` | 阈值过滤检索 | `search()` + `score_threshold` |
```python
# MMR 检索配置示例
mmr_retriever = vector_store.as_retriever(
search_type="mmr",
search_kwargs={
"k": 3,
"fetch_k": 20,
"lambda_mult": 0.5
}
)
```
* search_kwargs 参数详解
| 参数 | 类型 | 默认值 | 说明 |
| :-------------: | :------: | :----: | :-----------------: |
| `k` | int | 4 | 返回结果数量 |
| `filter`/`expr` | str/dict | None | 元数据过滤条件 |
| `param` | dict | None | Milvus 搜索参数配置 |
* 综合案例实战
* 默认是similarity search
````python
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_milvus import Milvus
from langchain_core.documents import Document
# 初始化模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
document_1 = Document(
page_content="LangChain支持多种数据库集成,小滴课堂的AI大课",
metadata={"source": "xdclass.net/doc1"},
)
document_2 = Document(
page_content="Milvus擅长处理向量搜索,老王的课程不错",
metadata={"source": "xdclass.net/doc2"},
)
document_3 = Document(
page_content="我要去学小滴课堂的架构大课",
metadata={"source": "xdclass.net/doc3"},
)
document_4 = Document(
page_content="今天天气不错,老王和老帆去按摩了",
metadata={"source": "xdclass.net/doc4"},
)
documents = [document_1,document_2,document_3,document_4]
vector_store = Milvus.from_documents(
documents=documents,
embedding=embeddings,
collection_name="retriever_test1",
connection_args={"uri": "http://47.119.128.20:19530"}
)
#默认是 similarity search
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
results = retriever.invoke("如何进行数据库操作")
for result in results:
print(f"内容 {result.page_content} 元数据 {result.metadata}")
````
* 可以调整为MMR检索
```
retriever = vector_store.as_retriever(search_type="mmr",search_kwargs={"k": 2})
```
#### 大厂面试题-如何提升大模型召回率和实战
* **LLM大模型开发高频面试题:如何提升大模型召回率和准确率?**
* 需求背景
* 当原始查询不够明确时,或者当文档库中的内容使用不同的术语表达同一概念时
* 单一查询可能无法有效检案到所有相关内容;
* 或者用户的问题可能有不同的表达方式,导致的检索结果不理想,
* 需要从多个角度切入才能找到最相关的文档片段。这种情况下,生成多个变体查询可以提高召回率,确保覆盖更多相关文档。
* `MultiQueryRetriever`
* 通过生成多个相关查询来增强检索效果,解决单一查询可能不够全面或存在歧义的问题。
* 原理:
* **查询扩展技术**:通过LLM生成N个相关查询(如改写、扩展、翻译),合并结果去重,生成多个变体查询
* **双重增强效果**:提升召回率(+25%↑)和准确率(+18%↑)的平衡

* 用法
```python
retriever = MultiQueryRetriever.from_llm(
retriever=base_retriever,
llm=ChatOpenAI()
)
```
* **典型问题场景**
- **术语差异问题**:用户提问使用"SSL证书" vs 文档中使用"TLS证书"
- **表述模糊问题**:"怎么备份数据库" vs "数据库容灾方案实施步骤"
- **多语言混合**:中英文混杂查询(常见于技术文档检索)
- **专业领域知识**:医学问诊中的症状不同描述方式
* 案例实战
```python
from langchain_community.embeddings import DashScopeEmbeddings
#from langchain.vectorstores import Milvus
from langchain_milvus import Milvus
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import TextLoader
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_text_splitters import RecursiveCharacterTextSplitter
import logging
# 设置日志记录的基本配置
logging.basicConfig()
# 设置多查询检索器的日志记录级别为INFO
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
# 使用TextLoader加载文本数据
loader = TextLoader("data/qa.txt")
# 加载数据到变量中
data = loader.load()
# 初始化文本分割器,将文本分割成小块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=10)
# 执行文本分割
splits = text_splitter.split_documents(data)
# 初始化模型
embedding = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
# 初始化向量数据库
vector_store = Milvus.from_documents(
documents=splits,
embedding=embedding,
collection_name="mulit_retriever2",
connection_args={"uri": "http://47.119.128.20:19530"}
)
# 定义问题
question = "老王不知道为啥抽筋了"
# 初始化语言模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 从语言模型中创建多查询检索器
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vector_store.as_retriever(), llm=llm
)
# 使用检索器执行问题检索
results = retriever_from_llm.invoke(question)
# 打印检索到的结果数量
len(results)
# 遍历并打印每个检索结果的内容和元数据
for result in results:
print(f"内容 {result.page_content} 元数据 {result.metadata}")
# 以下是未使用的代码片段,已将其注释掉
# vector_store = Milvus(
# embeddings,
# connection_args={"uri": "http://47.119.128.20:19530"},
# collection_name="mmr_test",
# )
# print(vector_store)
```
#### RAG综合项目实战-AI文档问答助手
* **需求:在线文档的问答助手,方便查找相关手册和接口API**
* 主要功能包括
* 文档加载与切分、向量嵌入生成、向量存储与检索。
* 基于检索增强生成(Retrieval-Augmented Generation, RAG)的问答。
* 技术选型:LangChain框架+Milvus向量数据库
* **实现的功能**
* 文档加载与切分
* 使用`WebBaseLoader`从指定URL加载文档。
* 使用`RecursiveCharacterTextSplitter`将加载的文档按照指定的块大小和重叠大小进行切分。
* 向量嵌入生成
- 使用`DashScopeEmbeddings`生成文档切片的向量嵌入,模型为`text-embedding-v2`,支持最大重试次数为3次。
* 向量存储与检索
- 使用`Milvus`作为向量数据库,创建名为`doc_qa_db`的Collection。
- 将生成的向量嵌入存储到Milvus中,并支持相似性检索。
* 基于RAG的问答
- 初始化`ChatOpenAI`模型,使用`qwen-plus`作为LLM模型。
- 定义`PromptTemplate`,用于构建输入给LLM的提示信息。
- 构建RAG链,结合相似性检索结果和LLM生成回答。
* 编码实战
```python
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_milvus import Milvus
from langchain.schema.runnable import RunnablePassthrough
from langchain.prompts import PromptTemplate
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_openai import ChatOpenAI
# 设置Milvus Collection名称。
COLLECTION_NAME = 'doc_qa_db'
# 初始化WebBaseLoader加载指定URL的文档。
loader = WebBaseLoader([
'https://milvus.io/docs/overview.md',
'https://milvus.io/docs/release_notes.md'
])
# 加载文档。
docs = loader.load()
# 初始化RecursiveCharacterTextSplitter,用于切分文档。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=0)
# 使用LangChain将输入文档按照chunk_size切分。
all_splits = text_splitter.split_documents(docs)
# 初始化DashScopeEmbeddings,设置embedding模型为DashScope的text-embedding-v2。
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
# 创建connection,为阿里云Milvus的访问域名。
connection_args = {"uri": "http://47.119.128.20:19530"}
# 创建Collection。
vector_store = Milvus(
embedding_function=embeddings,
connection_args=connection_args,
collection_name=COLLECTION_NAME,
drop_old=True,
).from_documents(
all_splits,
embedding=embeddings,
collection_name=COLLECTION_NAME,
connection_args=connection_args,
)
# vector_store = Milvus(
# embeddings,
# connection_args={"uri": "http://47.119.128.20:19530"},
# collection_name=COLLECTION_NAME,
# )
# 利用Milvus向量数据库进行相似性检索。
query = "What are the main components of Milvus?"
docs = vector_store.similarity_search(query)
print(len(docs))
# 初始化ChatOpenAI模型。
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 将上述相似性检索的结果作为retriever,提出问题输入到LLM之后,获取检索增强之后的回答。
retriever = vector_store.as_retriever()
```
* 编码测试实战
```python
# 定义PromptTemplate,用于构建输入给LLM的prompt。
template = """你是AI文档助手,使用以下上下文来回答最后的问题。
如果你不知道答案,就说你不知道,不要试图编造答案。
最多使用10句话,并尽可能简洁地回答。总是在答案的末尾说“谢谢你的提问!”.
{context}
问题: {question}
"""
rag_prompt = PromptTemplate.from_template(template)
# 构建Retrieval-Augmented Generation链。
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
)
# 调用rag_chain回答问题。
print(rag_chain.invoke("什么是Milvus."))
```
* 应用场景
* 教育领域:可用于备课笔记、课程内容总结等场景。
* 企业知识库:帮助企业快速构建基于内部文档的知识问答系统。
* 技术支持:提供技术文档的智能检索与问答服务。
* 扩展方向
* 支持更多类型的文档加载器(如PDF、Word等)。
* 增加多语言支持。
* 优化向量嵌入生成与检索效率
* 大家的疑惑点(下一章讲解)
```python
# 构建Retrieval-Augmented Generation链。
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
)
```
* 在 `rag_chain` 的定义中,`{"context": retriever, "question": RunnablePassthrough()}` 创建了一个输入字典。
* `context` 的值来自 `retriever`,它将使用向量存储检索与问题相关的文档片段。
* `question`键的值通过 `RunnablePassthrough()` 直接传递,用户输入的问题会被透传到后续的处理步骤。
* 输入字典随后会被传递给 `rag_prompt`,构建最终的提示(prompt)被传递给 `llm`(语言模型),生成最终的回答
* 总结:
* 用户输入的问题会同时传给`retriever`和`RunnablePassthrough()`
* `retriever`完成检索后,会自动把结果赋值给`context`。
* 检索结果`context`和用户输入`question`一并传给提示模板`prompt_template`。
### 解析和多实现类案例实战
#### LangChain核心之Runnable接口底层实现
* 什么是`Runnable`接口
* 是LangChain框架中所有组件的核心抽象接口,用于封装可执行的逻辑单元(如模型调用、数据处理、API集成等)。
* 通过实现统一的`invoke`、`batch`、`stream`等方法,支持模块化构建链式任务,允许开发者以声明式编程LCEL串联不同组件
```
from langchain_core.runnables
```
* 为什么要使用`Runnable`
- **统一接口**:所有组件(如Prompt模板、模型、解析器)均实现Runnable接口,确保类型兼容和链式调用的无缝衔接
- **灵活组合**:通过管道符`|`将多个Runnable串联成链,简化复杂逻辑的编排,类似数据流处理
- **动态配置**:支持运行时参数绑定、组件替换和错误恢复机制(如`with_retry()`),提升系统灵活性和鲁棒性
- **异步与性能优化**:内置异步方法(如`ainvoke`)和并行处理(如`RunnableParallel`),适用于高并发场景
* 什么是`RunnableSequence`
* 是LangChain中用于构建**顺序执行链**的核心组件,通过管道符`|`将多个Runnable串联,形成线性执行流程,是`Runnable`子类
```
from langchain_core.runnables import RunnableSequence
```
* 执行 LCEL链调用的方法(invoke/stream/batch),链中的每个组件也调用对应的方法,将输出作为下一个组件的输入
```python
#RunnableSequence.invoke 的源码解读
def invoke(
self, input: Input, config: Optional[RunnableConfig] = None, **kwargs: Any
) -> Output:
# invoke all steps in sequence
try:
for i, step in enumerate(self.steps):
# mark each step as a child run
config = patch_config(
config, callbacks=run_manager.get_child(f"seq:step:{i + 1}")
)
with set_config_context(config) as context:
if i == 0:
input = context.run(step.invoke, input, config, **kwargs)
else:
input = context.run(step.invoke, input, config)
```
* 从LECL表达式开始理解
```
chain = prompt | model | output_parser # 通过|直接连接
```
* **数据流传递**
* 每个Runnable的输出作为下一个Runnable的输入,形成单向数据流。
* 例如,若链为`A | B | C`,则执行流程为`A的输出 → B的输入 → B的输出 → C的输入`
* **统一接口**:
* 所有组件(如Prompt模板、模型、输出解析器)均实现`Runnable`接口,确保类型兼容性和链式调用的无缝衔接
* **延迟执行**:
* 链的构建仅定义逻辑关系,实际执行在调用`invoke`或`stream`时触发,支持动态参数绑定和运行时配置
* **底层实现**:
* 管道符`|`在Python中被重写为`__or__`方法,实际调用`RunnableSequence`构造函数,
* 将多个Runnable存入内部列表`steps`中, 执行时按顺序遍历列表并调用每个Runnable的`invoke`方法
* Runnable接口定义了以下核心方法,支持多种执行模式
```python
class Runnable(Generic[Input, Output]):
#处理单个输入,返回输出。
def invoke(self, input: Input) -> Output: ...
#异步处理单个输入。
async def ainvoke(self, input: Input) -> Output: ...
#逐块生成输出,适用于实时响应。
def stream(self, input: Input) -> Iterator[Output]: ...
#批量处理输入列表,提升吞吐量。
def batch(self, inputs: List[Input]) -> List[Output]: ...
```
| 方法 | 说明 | 使用场景 |
| :---------: | :----------: | :----------: |
| `invoke()` | 同步执行 | 单次调用 |
| `batch()` | 批量同步执行 | 处理数据集 |
| `stream()` | 流式输出 | 实时生成文本 |
| `ainvoke()` | 异步执行 | Web服务集成 |
* 具有多个子类实现
| 组件 | 特点 | 适用场景 |
| :-------------------: | :------: | :------------: |
| `RunnableSequence` | 顺序执行 | 线性处理流水线 |
| `RunnableBranch` | 条件路由 | 分支选择逻辑 |
| `RunnableParallel` | 并行执行 | 多任务独立处理 |
| `RunnablePassthrough` | 数据透传 | 保留原始输入 |
#### RunnablePassthrough介绍和透传参数实战
* `RunnablePassthrough`
* 核心功能:用于在链中直接传递输入数据,不进行任何修改,或通过 `.assign()` 扩展上下文字段

* 应用场景:
- 保留原始输入数据供后续步骤使用。
- 动态添加新字段到上下文中(如结合检索结果与用户问题)
* 基础用法
```python
from langchain_core.runnables import RunnablePassthrough
# 直接传递输入
chain = RunnablePassthrough() | model
output = chain.invoke("Hello")
```
* 扩展字段案例
* 案例一
```python
# 使用 assign() 添加新字段
from langchain_core.runnables import RunnablePassthrough
# 使用 assign() 方法添加新字段,该方法接收一个关键字参数,其值是一个函数
# 这个函数定义了如何处理输入数据以生成新字段
# 在这个例子中,lambda 函数接收一个输入 x,并返回 x["num"] * 2 的结果
# 这将创建一个新的字段 'processed',其值是输入字段 'num' 的两倍
chain = RunnablePassthrough.assign(processed=lambda x: x["num"] * 2)
# 调用 chain 对象的 invoke 方法,传入一个包含 'num' 字段的字典
# 这将执行之前定义的 lambda 函数,并在输入字典的基础上添加 'processed' 字段
# 最后输出处理后的字典
output = chain.invoke({"num": 3}) # 输出 {'num':3, 'processed':6}
print(output)
```
* 案例二(伪代码)
```python
# 构建包含原始问题和处理上下文的链
chain = (
RunnablePassthrough.assign(
context=lambda x: retrieve_documents(x["question"])
)
| prompt
| llm
)
# 输入结构
input_data = {"question": "LangChain是什么?"}
response = chain.invoke(input_data)
```
* 透传参数LLM案例实战
* 用户输入的问题会同时传给`retriever`和`RunnablePassthrough()`
* `retriever`完成检索后,会自动把结果赋值给`context`。
* 检索结果`context`和用户输入`question`一并传给提示模板`prompt_template`。
* **输出**:模型根据检索到的上下文生成答案
```python
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_milvus import Milvus
from langchain_core.documents import Document
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# 初始化模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
document_1 = Document(
page_content="LangChain支持多种数据库集成,小滴课堂的AI大课",
metadata={"source": "xdclass.net/doc1"},
)
document_2 = Document(
page_content="Milvus擅长处理向量搜索,老王的课程不错",
metadata={"source": "xdclass.net/doc2"},
)
documents = [document_1,document_2]
vector_store = Milvus.from_documents(
documents=documents,
embedding=embeddings,
collection_name="runnable_test",
connection_args={"uri": "http://47.119.128.20:19530"}
)
#默认是 similarity search
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
prompt = ChatPromptTemplate.from_template("基于上下文回答:{context}\n问题:{question}")
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
chain = {
"context": retriever,
"question": RunnablePassthrough() # 直接传递用户问题
} | prompt | model
result = chain.invoke("LangChain支持数据库吗")
print(result)
```
#### AI智能推荐实战之RunnableParallel并行链
* `RunnableParallel` 介绍
* 并行执行多个 Runnable,合并结果为一个字典,键为子链名称,值为对应输出
```
class RunnableParallel(Runnable[Input, Dict[str, Any]]):
"""
并行执行多个Runnable的容器类
输出结果为字典结构:{key1: result1, key2: result2...}
"""
```
* 在 LCEL 链上,会将字典隐形转换为`RunnableParallel`
```python
multi_retrieval_chain = (
RunnableParallel({
"context1": retriever1, #数据源一
"context2": retriever2, #数据源二
"question": RunnablePassthrough()
})
| prompt_template
| llm
| outputParser
)
======= 自动化转换为下面,写法一样 ========
multi_retrieval_chain = (
{
"context1": retriever1, #数据源一
"context2": retriever2, #数据源二
"question": RunnablePassthrough()
}
| prompt_template
| llm
| outputParser
)
```
* 特点
| 特性 | 说明 | 示例 |
| :----------: | :--------------------: | :------------------------: |
| **并行执行** | 所有子Runnable同时运行 | 3个任务耗时2秒(而非累加) |
| **类型安全** | 强制校验输入输出类型 | 自动检测字典字段类型 |
* 有多个实现:VectorStoreRetriever、MultiQueryRetriever、SelfQueryRetriever等
* 特点
* **模块化设计**:支持插件式扩展,可自定义检索算法(如混合搜索、重排序)。
* **异步支持**:通过`async_get_relevant_documents`实现高并发场景下的高效检索。
* **链式调用**:可与LangChain的其他组件(如Text Splitters、Memory)无缝集成。
```
# from langchain_core.retrievers import BaseRetriever
```
* 补充知识点:召回率(Recall)信息检索和机器学习中衡量模型找全相关结果能力的核心指标
* 比如
* 在文档检索中,如果有100篇相关文档,系统找出了80篇,那么召回率就是80%。
* 召回率高意味着系统漏掉的少,但可能夹杂了不相关的结果,这时候准确率可能低。
* Retriever常见类型之基础检索器 `VectorStoreRetriever`
* 基础使用参考案例
```python
#将文档嵌入为向量,通过相似度计算(如余弦相似度)检索
from langchain_community.vectorstores import FAISS
retriever = FAISS.from_documents(docs, embeddings).as_retriever(
search_type="mmr", # 最大边际相关性
search_kwargs={"k": 5, "filter": {"category": "news"}}
)
```
* `as_retriever()` 方法介绍
* 将向量库实例转换为检索器对象,实现与 LangChain 链式调用(如 `RetrievalQA`)的无缝对接。
* 源码
```python
def as_retriever(self, **kwargs: Any) -> VectorStoreRetriever:
tags = kwargs.pop("tags", None) or [] + self._get_retriever_tags()
return VectorStoreRetriever(vectorstore=self, tags=tags, **kwargs)
"""
向量库实例转换为检索器对象,实现与 LangChain 链式调用
"""
```
* 关键参数详解
* search_type 搜索类型
| 类型 | 适用场景 | Milvus 对应操作 |
| :----------------------------: | :------------: | :-------------------------------: |
| `"similarity"` | 基础相似度检索 | `search()` |
| `"mmr"` | 多样性结果优化 | `max_marginal_relevance_search()` |
| `"similarity_score_threshold"` | 阈值过滤检索 | `search()` + `score_threshold` |
```python
# MMR 检索配置示例
mmr_retriever = vector_store.as_retriever(
search_type="mmr",
search_kwargs={
"k": 3,
"fetch_k": 20,
"lambda_mult": 0.5
}
)
```
* search_kwargs 参数详解
| 参数 | 类型 | 默认值 | 说明 |
| :-------------: | :------: | :----: | :-----------------: |
| `k` | int | 4 | 返回结果数量 |
| `filter`/`expr` | str/dict | None | 元数据过滤条件 |
| `param` | dict | None | Milvus 搜索参数配置 |
* 综合案例实战
* 默认是similarity search
````python
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_milvus import Milvus
from langchain_core.documents import Document
# 初始化模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
document_1 = Document(
page_content="LangChain支持多种数据库集成,小滴课堂的AI大课",
metadata={"source": "xdclass.net/doc1"},
)
document_2 = Document(
page_content="Milvus擅长处理向量搜索,老王的课程不错",
metadata={"source": "xdclass.net/doc2"},
)
document_3 = Document(
page_content="我要去学小滴课堂的架构大课",
metadata={"source": "xdclass.net/doc3"},
)
document_4 = Document(
page_content="今天天气不错,老王和老帆去按摩了",
metadata={"source": "xdclass.net/doc4"},
)
documents = [document_1,document_2,document_3,document_4]
vector_store = Milvus.from_documents(
documents=documents,
embedding=embeddings,
collection_name="retriever_test1",
connection_args={"uri": "http://47.119.128.20:19530"}
)
#默认是 similarity search
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
results = retriever.invoke("如何进行数据库操作")
for result in results:
print(f"内容 {result.page_content} 元数据 {result.metadata}")
````
* 可以调整为MMR检索
```
retriever = vector_store.as_retriever(search_type="mmr",search_kwargs={"k": 2})
```
#### 大厂面试题-如何提升大模型召回率和实战
* **LLM大模型开发高频面试题:如何提升大模型召回率和准确率?**
* 需求背景
* 当原始查询不够明确时,或者当文档库中的内容使用不同的术语表达同一概念时
* 单一查询可能无法有效检案到所有相关内容;
* 或者用户的问题可能有不同的表达方式,导致的检索结果不理想,
* 需要从多个角度切入才能找到最相关的文档片段。这种情况下,生成多个变体查询可以提高召回率,确保覆盖更多相关文档。
* `MultiQueryRetriever`
* 通过生成多个相关查询来增强检索效果,解决单一查询可能不够全面或存在歧义的问题。
* 原理:
* **查询扩展技术**:通过LLM生成N个相关查询(如改写、扩展、翻译),合并结果去重,生成多个变体查询
* **双重增强效果**:提升召回率(+25%↑)和准确率(+18%↑)的平衡

* 用法
```python
retriever = MultiQueryRetriever.from_llm(
retriever=base_retriever,
llm=ChatOpenAI()
)
```
* **典型问题场景**
- **术语差异问题**:用户提问使用"SSL证书" vs 文档中使用"TLS证书"
- **表述模糊问题**:"怎么备份数据库" vs "数据库容灾方案实施步骤"
- **多语言混合**:中英文混杂查询(常见于技术文档检索)
- **专业领域知识**:医学问诊中的症状不同描述方式
* 案例实战
```python
from langchain_community.embeddings import DashScopeEmbeddings
#from langchain.vectorstores import Milvus
from langchain_milvus import Milvus
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import TextLoader
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_text_splitters import RecursiveCharacterTextSplitter
import logging
# 设置日志记录的基本配置
logging.basicConfig()
# 设置多查询检索器的日志记录级别为INFO
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)
# 使用TextLoader加载文本数据
loader = TextLoader("data/qa.txt")
# 加载数据到变量中
data = loader.load()
# 初始化文本分割器,将文本分割成小块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=10)
# 执行文本分割
splits = text_splitter.split_documents(data)
# 初始化模型
embedding = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
# 初始化向量数据库
vector_store = Milvus.from_documents(
documents=splits,
embedding=embedding,
collection_name="mulit_retriever2",
connection_args={"uri": "http://47.119.128.20:19530"}
)
# 定义问题
question = "老王不知道为啥抽筋了"
# 初始化语言模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 从语言模型中创建多查询检索器
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vector_store.as_retriever(), llm=llm
)
# 使用检索器执行问题检索
results = retriever_from_llm.invoke(question)
# 打印检索到的结果数量
len(results)
# 遍历并打印每个检索结果的内容和元数据
for result in results:
print(f"内容 {result.page_content} 元数据 {result.metadata}")
# 以下是未使用的代码片段,已将其注释掉
# vector_store = Milvus(
# embeddings,
# connection_args={"uri": "http://47.119.128.20:19530"},
# collection_name="mmr_test",
# )
# print(vector_store)
```
#### RAG综合项目实战-AI文档问答助手
* **需求:在线文档的问答助手,方便查找相关手册和接口API**
* 主要功能包括
* 文档加载与切分、向量嵌入生成、向量存储与检索。
* 基于检索增强生成(Retrieval-Augmented Generation, RAG)的问答。
* 技术选型:LangChain框架+Milvus向量数据库
* **实现的功能**
* 文档加载与切分
* 使用`WebBaseLoader`从指定URL加载文档。
* 使用`RecursiveCharacterTextSplitter`将加载的文档按照指定的块大小和重叠大小进行切分。
* 向量嵌入生成
- 使用`DashScopeEmbeddings`生成文档切片的向量嵌入,模型为`text-embedding-v2`,支持最大重试次数为3次。
* 向量存储与检索
- 使用`Milvus`作为向量数据库,创建名为`doc_qa_db`的Collection。
- 将生成的向量嵌入存储到Milvus中,并支持相似性检索。
* 基于RAG的问答
- 初始化`ChatOpenAI`模型,使用`qwen-plus`作为LLM模型。
- 定义`PromptTemplate`,用于构建输入给LLM的提示信息。
- 构建RAG链,结合相似性检索结果和LLM生成回答。
* 编码实战
```python
from langchain_community.document_loaders import WebBaseLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_milvus import Milvus
from langchain.schema.runnable import RunnablePassthrough
from langchain.prompts import PromptTemplate
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_openai import ChatOpenAI
# 设置Milvus Collection名称。
COLLECTION_NAME = 'doc_qa_db'
# 初始化WebBaseLoader加载指定URL的文档。
loader = WebBaseLoader([
'https://milvus.io/docs/overview.md',
'https://milvus.io/docs/release_notes.md'
])
# 加载文档。
docs = loader.load()
# 初始化RecursiveCharacterTextSplitter,用于切分文档。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=0)
# 使用LangChain将输入文档按照chunk_size切分。
all_splits = text_splitter.split_documents(docs)
# 初始化DashScopeEmbeddings,设置embedding模型为DashScope的text-embedding-v2。
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
# 创建connection,为阿里云Milvus的访问域名。
connection_args = {"uri": "http://47.119.128.20:19530"}
# 创建Collection。
vector_store = Milvus(
embedding_function=embeddings,
connection_args=connection_args,
collection_name=COLLECTION_NAME,
drop_old=True,
).from_documents(
all_splits,
embedding=embeddings,
collection_name=COLLECTION_NAME,
connection_args=connection_args,
)
# vector_store = Milvus(
# embeddings,
# connection_args={"uri": "http://47.119.128.20:19530"},
# collection_name=COLLECTION_NAME,
# )
# 利用Milvus向量数据库进行相似性检索。
query = "What are the main components of Milvus?"
docs = vector_store.similarity_search(query)
print(len(docs))
# 初始化ChatOpenAI模型。
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 将上述相似性检索的结果作为retriever,提出问题输入到LLM之后,获取检索增强之后的回答。
retriever = vector_store.as_retriever()
```
* 编码测试实战
```python
# 定义PromptTemplate,用于构建输入给LLM的prompt。
template = """你是AI文档助手,使用以下上下文来回答最后的问题。
如果你不知道答案,就说你不知道,不要试图编造答案。
最多使用10句话,并尽可能简洁地回答。总是在答案的末尾说“谢谢你的提问!”.
{context}
问题: {question}
"""
rag_prompt = PromptTemplate.from_template(template)
# 构建Retrieval-Augmented Generation链。
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
)
# 调用rag_chain回答问题。
print(rag_chain.invoke("什么是Milvus."))
```
* 应用场景
* 教育领域:可用于备课笔记、课程内容总结等场景。
* 企业知识库:帮助企业快速构建基于内部文档的知识问答系统。
* 技术支持:提供技术文档的智能检索与问答服务。
* 扩展方向
* 支持更多类型的文档加载器(如PDF、Word等)。
* 增加多语言支持。
* 优化向量嵌入生成与检索效率
* 大家的疑惑点(下一章讲解)
```python
# 构建Retrieval-Augmented Generation链。
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| rag_prompt
| llm
)
```
* 在 `rag_chain` 的定义中,`{"context": retriever, "question": RunnablePassthrough()}` 创建了一个输入字典。
* `context` 的值来自 `retriever`,它将使用向量存储检索与问题相关的文档片段。
* `question`键的值通过 `RunnablePassthrough()` 直接传递,用户输入的问题会被透传到后续的处理步骤。
* 输入字典随后会被传递给 `rag_prompt`,构建最终的提示(prompt)被传递给 `llm`(语言模型),生成最终的回答
* 总结:
* 用户输入的问题会同时传给`retriever`和`RunnablePassthrough()`
* `retriever`完成检索后,会自动把结果赋值给`context`。
* 检索结果`context`和用户输入`question`一并传给提示模板`prompt_template`。
### 解析和多实现类案例实战
#### LangChain核心之Runnable接口底层实现
* 什么是`Runnable`接口
* 是LangChain框架中所有组件的核心抽象接口,用于封装可执行的逻辑单元(如模型调用、数据处理、API集成等)。
* 通过实现统一的`invoke`、`batch`、`stream`等方法,支持模块化构建链式任务,允许开发者以声明式编程LCEL串联不同组件
```
from langchain_core.runnables
```
* 为什么要使用`Runnable`
- **统一接口**:所有组件(如Prompt模板、模型、解析器)均实现Runnable接口,确保类型兼容和链式调用的无缝衔接
- **灵活组合**:通过管道符`|`将多个Runnable串联成链,简化复杂逻辑的编排,类似数据流处理
- **动态配置**:支持运行时参数绑定、组件替换和错误恢复机制(如`with_retry()`),提升系统灵活性和鲁棒性
- **异步与性能优化**:内置异步方法(如`ainvoke`)和并行处理(如`RunnableParallel`),适用于高并发场景
* 什么是`RunnableSequence`
* 是LangChain中用于构建**顺序执行链**的核心组件,通过管道符`|`将多个Runnable串联,形成线性执行流程,是`Runnable`子类
```
from langchain_core.runnables import RunnableSequence
```
* 执行 LCEL链调用的方法(invoke/stream/batch),链中的每个组件也调用对应的方法,将输出作为下一个组件的输入
```python
#RunnableSequence.invoke 的源码解读
def invoke(
self, input: Input, config: Optional[RunnableConfig] = None, **kwargs: Any
) -> Output:
# invoke all steps in sequence
try:
for i, step in enumerate(self.steps):
# mark each step as a child run
config = patch_config(
config, callbacks=run_manager.get_child(f"seq:step:{i + 1}")
)
with set_config_context(config) as context:
if i == 0:
input = context.run(step.invoke, input, config, **kwargs)
else:
input = context.run(step.invoke, input, config)
```
* 从LECL表达式开始理解
```
chain = prompt | model | output_parser # 通过|直接连接
```
* **数据流传递**
* 每个Runnable的输出作为下一个Runnable的输入,形成单向数据流。
* 例如,若链为`A | B | C`,则执行流程为`A的输出 → B的输入 → B的输出 → C的输入`
* **统一接口**:
* 所有组件(如Prompt模板、模型、输出解析器)均实现`Runnable`接口,确保类型兼容性和链式调用的无缝衔接
* **延迟执行**:
* 链的构建仅定义逻辑关系,实际执行在调用`invoke`或`stream`时触发,支持动态参数绑定和运行时配置
* **底层实现**:
* 管道符`|`在Python中被重写为`__or__`方法,实际调用`RunnableSequence`构造函数,
* 将多个Runnable存入内部列表`steps`中, 执行时按顺序遍历列表并调用每个Runnable的`invoke`方法
* Runnable接口定义了以下核心方法,支持多种执行模式
```python
class Runnable(Generic[Input, Output]):
#处理单个输入,返回输出。
def invoke(self, input: Input) -> Output: ...
#异步处理单个输入。
async def ainvoke(self, input: Input) -> Output: ...
#逐块生成输出,适用于实时响应。
def stream(self, input: Input) -> Iterator[Output]: ...
#批量处理输入列表,提升吞吐量。
def batch(self, inputs: List[Input]) -> List[Output]: ...
```
| 方法 | 说明 | 使用场景 |
| :---------: | :----------: | :----------: |
| `invoke()` | 同步执行 | 单次调用 |
| `batch()` | 批量同步执行 | 处理数据集 |
| `stream()` | 流式输出 | 实时生成文本 |
| `ainvoke()` | 异步执行 | Web服务集成 |
* 具有多个子类实现
| 组件 | 特点 | 适用场景 |
| :-------------------: | :------: | :------------: |
| `RunnableSequence` | 顺序执行 | 线性处理流水线 |
| `RunnableBranch` | 条件路由 | 分支选择逻辑 |
| `RunnableParallel` | 并行执行 | 多任务独立处理 |
| `RunnablePassthrough` | 数据透传 | 保留原始输入 |
#### RunnablePassthrough介绍和透传参数实战
* `RunnablePassthrough`
* 核心功能:用于在链中直接传递输入数据,不进行任何修改,或通过 `.assign()` 扩展上下文字段

* 应用场景:
- 保留原始输入数据供后续步骤使用。
- 动态添加新字段到上下文中(如结合检索结果与用户问题)
* 基础用法
```python
from langchain_core.runnables import RunnablePassthrough
# 直接传递输入
chain = RunnablePassthrough() | model
output = chain.invoke("Hello")
```
* 扩展字段案例
* 案例一
```python
# 使用 assign() 添加新字段
from langchain_core.runnables import RunnablePassthrough
# 使用 assign() 方法添加新字段,该方法接收一个关键字参数,其值是一个函数
# 这个函数定义了如何处理输入数据以生成新字段
# 在这个例子中,lambda 函数接收一个输入 x,并返回 x["num"] * 2 的结果
# 这将创建一个新的字段 'processed',其值是输入字段 'num' 的两倍
chain = RunnablePassthrough.assign(processed=lambda x: x["num"] * 2)
# 调用 chain 对象的 invoke 方法,传入一个包含 'num' 字段的字典
# 这将执行之前定义的 lambda 函数,并在输入字典的基础上添加 'processed' 字段
# 最后输出处理后的字典
output = chain.invoke({"num": 3}) # 输出 {'num':3, 'processed':6}
print(output)
```
* 案例二(伪代码)
```python
# 构建包含原始问题和处理上下文的链
chain = (
RunnablePassthrough.assign(
context=lambda x: retrieve_documents(x["question"])
)
| prompt
| llm
)
# 输入结构
input_data = {"question": "LangChain是什么?"}
response = chain.invoke(input_data)
```
* 透传参数LLM案例实战
* 用户输入的问题会同时传给`retriever`和`RunnablePassthrough()`
* `retriever`完成检索后,会自动把结果赋值给`context`。
* 检索结果`context`和用户输入`question`一并传给提示模板`prompt_template`。
* **输出**:模型根据检索到的上下文生成答案
```python
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_milvus import Milvus
from langchain_core.documents import Document
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# 初始化模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
document_1 = Document(
page_content="LangChain支持多种数据库集成,小滴课堂的AI大课",
metadata={"source": "xdclass.net/doc1"},
)
document_2 = Document(
page_content="Milvus擅长处理向量搜索,老王的课程不错",
metadata={"source": "xdclass.net/doc2"},
)
documents = [document_1,document_2]
vector_store = Milvus.from_documents(
documents=documents,
embedding=embeddings,
collection_name="runnable_test",
connection_args={"uri": "http://47.119.128.20:19530"}
)
#默认是 similarity search
retriever = vector_store.as_retriever(search_kwargs={"k": 2})
prompt = ChatPromptTemplate.from_template("基于上下文回答:{context}\n问题:{question}")
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
chain = {
"context": retriever,
"question": RunnablePassthrough() # 直接传递用户问题
} | prompt | model
result = chain.invoke("LangChain支持数据库吗")
print(result)
```
#### AI智能推荐实战之RunnableParallel并行链
* `RunnableParallel` 介绍
* 并行执行多个 Runnable,合并结果为一个字典,键为子链名称,值为对应输出
```
class RunnableParallel(Runnable[Input, Dict[str, Any]]):
"""
并行执行多个Runnable的容器类
输出结果为字典结构:{key1: result1, key2: result2...}
"""
```
* 在 LCEL 链上,会将字典隐形转换为`RunnableParallel`
```python
multi_retrieval_chain = (
RunnableParallel({
"context1": retriever1, #数据源一
"context2": retriever2, #数据源二
"question": RunnablePassthrough()
})
| prompt_template
| llm
| outputParser
)
======= 自动化转换为下面,写法一样 ========
multi_retrieval_chain = (
{
"context1": retriever1, #数据源一
"context2": retriever2, #数据源二
"question": RunnablePassthrough()
}
| prompt_template
| llm
| outputParser
)
```
* 特点
| 特性 | 说明 | 示例 |
| :----------: | :--------------------: | :------------------------: |
| **并行执行** | 所有子Runnable同时运行 | 3个任务耗时2秒(而非累加) |
| **类型安全** | 强制校验输入输出类型 | 自动检测字典字段类型 |
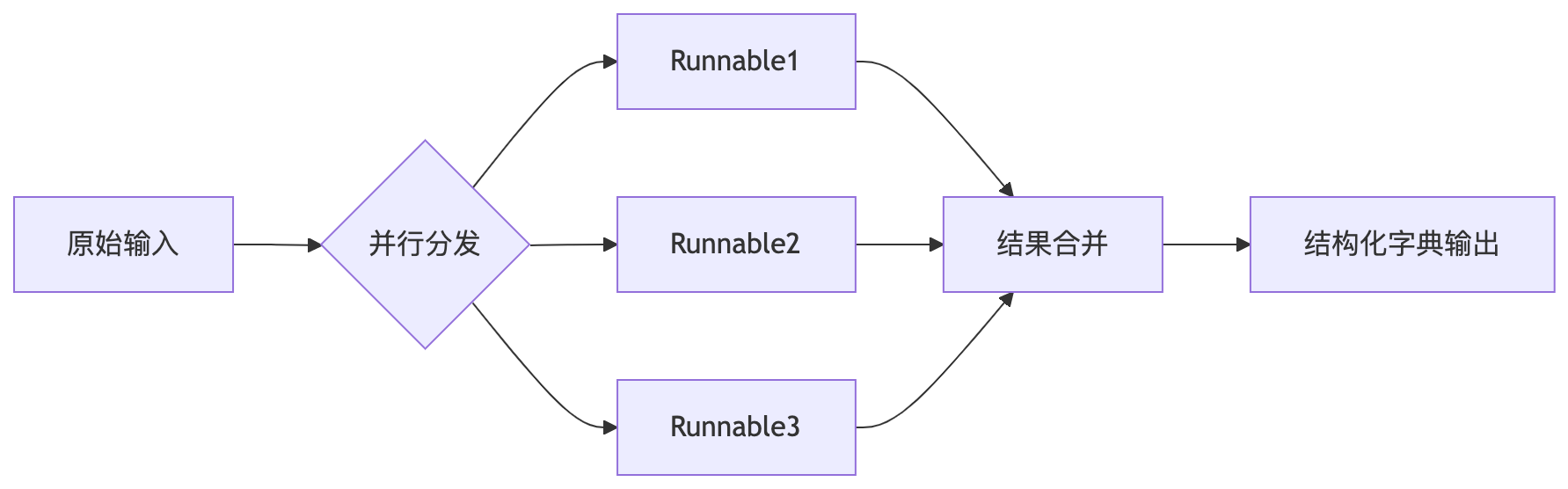 * API 与用法, 构造函数所有子链接收相同的输入
```python
from langchain_core.runnables import RunnableParallel
runnable = RunnableParallel(
key1=chain1,
key2=chain2
)
```
* 应用场景:
* **数据并行处理器**:同时处理多个数据流
* **结构化数据装配器**:构建标准化的输出格式
* **流水线分叉合并器**:实现Map-Reduce模式中的Map阶段
* 举例
* 多维度数据分析
```
analysis_chain = RunnableParallel({
"sentiment": sentiment_analyzer,
"keywords": keyword_extractor,
"entities": ner_recognizer
})
```
* 多模型对比系统
```python
model_comparison = RunnableParallel({
"gpt4": gpt4_chain,
"claude": claude_chain,
"gemini": gemini_chain
})
```
* 智能文档处理系统
```python
document_analyzer = RunnableParallel({
"summary": summary_chain, # 摘要生成
"toc": toc_generator, # 目录提取
"stats": RunnableLambda(lambda doc: {
"char_count": len(doc),
"page_count": doc.count("PAGE_BREAK") + 1
})
})
# 处理200页PDF文本
analysis_result = document_analyzer.invoke(pdf_text)
```
* 案例实战
* 场景:并行生成景点与书籍推荐
```python
from langchain_core.runnables import RunnableParallel
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
#构建解析器
parser = JsonOutputParser()
prompt_attractions = ChatPromptTemplate.from_template("""列出{city}的{num}个景点。返回 JSON 格式:
{{
"num": "编号",
"city": "城市",
"introduce": "景点介绍",
}}
""")
prompt_books = ChatPromptTemplate.from_template("""列出{city}相关的{num}本书返回 JSON 格式:
{{
"num": "编号",
"city": "城市",
"introduce": "书籍介绍",
}} """)
chain1 = prompt_attractions | model | parser
chain2 = prompt_books | model | parser
chain = RunnableParallel(
attractions = chain1 ,
books = chain2
)
output = chain.invoke({"city": "南京", "num": 3})
print(output)
```
#### RunnableLambda介绍和包装链式函数实战
* `RunnableLambda`
* 核心功能
* 将任意 Python 函数转换为 Runnable,将普通的 Python 函数或可调用对象转换为 `Runnable`对象,无缝集成到链中
* 把自己需要的功能通过自定义函数 + RunnableLambda的方式包装,可以跟任何外部系统打通,集成到 LCEL 链
```
class RunnableLambda(Runnable[Input, Output]):
"""
将任意Python函数转换为符合Runnable协议的对象
实现自定义逻辑与LangChain生态的无缝集成
"""
```
* 与普通函数的区别
| 特性 | 普通函数 | RunnableLambda |
| :------: | :-----------------: | :-------------------: |
| 可组合性 | ❌ 无法直接接入Chain | ✅ 支持` |
| 类型校验 | ❌ 动态类型 | ✅ 静态类型检查 |
| 异步支持 | ❌ 需手动实现 | ✅ 原生支持async/await |
| 批量处理 | ❌ 需循环调用 | ✅ 自动批量优化 |
* 适合场景:
* 插入自定义逻辑(如日志记录、数据清洗)
* 转换数据格式(如 JSON 解析)。
* API 与用法
```python
from langchain_core.runnables import RunnableLambda
def log_input(x):
print(f"Input: {x}")
return x
chain = prompt | RunnableLambda(log_input) | model
```
* 案例实战
* 基础文本处理链
```python
from langchain_core.runnables import RunnableLambda
text_clean_chain = (
RunnableLambda(lambda x: x.strip())
| RunnableLambda(str.lower)
)
result = text_clean_chain.invoke(" Hello123World ")
print(result) # 输出 "helloworld"
```
* 打印中间结果并过滤敏感词(在链中插入自定义处理逻辑)
```python
from langchain_core.runnables import RunnableLambda
from langchain_openai import ChatOpenAI
def filter_content(text: str) -> str:
return text.replace("暴力", "***")
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
chain = (
RunnableLambda(lambda x: x["user_input"])
| RunnableLambda(filter_content)
| model
)
result = chain.invoke({"user_input": "暴力内容"})
print(result) # 输出过滤后的结果
```
#### 智能客服路由实战之RunnableBranch条件分支
* `RunnableBranch`
* 核心功能:根据条件选择执行不同的子链,类似 if-else 路由
* API 与用法
```python
from langchain_core.runnables import RunnableBranch
#条件函数:接收输入,返回布尔值。
branch = RunnableBranch(
(condition1, chain1),
(condition2, chain2),
default_chain
)
"""
参数说明:
- Condition: 返回bool的可调用对象
- Runnable: 条件满足时执行的分支
- default: 所有条件不满足时执行的默认分支
技术细节:
1. 条件按声明顺序
2. 第一个满足条件的分支会被执行
3. 无默认分支且所有条件不满足时抛出异常
"""
```
* API 与用法, 构造函数所有子链接收相同的输入
```python
from langchain_core.runnables import RunnableParallel
runnable = RunnableParallel(
key1=chain1,
key2=chain2
)
```
* 应用场景:
* **数据并行处理器**:同时处理多个数据流
* **结构化数据装配器**:构建标准化的输出格式
* **流水线分叉合并器**:实现Map-Reduce模式中的Map阶段
* 举例
* 多维度数据分析
```
analysis_chain = RunnableParallel({
"sentiment": sentiment_analyzer,
"keywords": keyword_extractor,
"entities": ner_recognizer
})
```
* 多模型对比系统
```python
model_comparison = RunnableParallel({
"gpt4": gpt4_chain,
"claude": claude_chain,
"gemini": gemini_chain
})
```
* 智能文档处理系统
```python
document_analyzer = RunnableParallel({
"summary": summary_chain, # 摘要生成
"toc": toc_generator, # 目录提取
"stats": RunnableLambda(lambda doc: {
"char_count": len(doc),
"page_count": doc.count("PAGE_BREAK") + 1
})
})
# 处理200页PDF文本
analysis_result = document_analyzer.invoke(pdf_text)
```
* 案例实战
* 场景:并行生成景点与书籍推荐
```python
from langchain_core.runnables import RunnableParallel
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
#构建解析器
parser = JsonOutputParser()
prompt_attractions = ChatPromptTemplate.from_template("""列出{city}的{num}个景点。返回 JSON 格式:
{{
"num": "编号",
"city": "城市",
"introduce": "景点介绍",
}}
""")
prompt_books = ChatPromptTemplate.from_template("""列出{city}相关的{num}本书返回 JSON 格式:
{{
"num": "编号",
"city": "城市",
"introduce": "书籍介绍",
}} """)
chain1 = prompt_attractions | model | parser
chain2 = prompt_books | model | parser
chain = RunnableParallel(
attractions = chain1 ,
books = chain2
)
output = chain.invoke({"city": "南京", "num": 3})
print(output)
```
#### RunnableLambda介绍和包装链式函数实战
* `RunnableLambda`
* 核心功能
* 将任意 Python 函数转换为 Runnable,将普通的 Python 函数或可调用对象转换为 `Runnable`对象,无缝集成到链中
* 把自己需要的功能通过自定义函数 + RunnableLambda的方式包装,可以跟任何外部系统打通,集成到 LCEL 链
```
class RunnableLambda(Runnable[Input, Output]):
"""
将任意Python函数转换为符合Runnable协议的对象
实现自定义逻辑与LangChain生态的无缝集成
"""
```
* 与普通函数的区别
| 特性 | 普通函数 | RunnableLambda |
| :------: | :-----------------: | :-------------------: |
| 可组合性 | ❌ 无法直接接入Chain | ✅ 支持` |
| 类型校验 | ❌ 动态类型 | ✅ 静态类型检查 |
| 异步支持 | ❌ 需手动实现 | ✅ 原生支持async/await |
| 批量处理 | ❌ 需循环调用 | ✅ 自动批量优化 |
* 适合场景:
* 插入自定义逻辑(如日志记录、数据清洗)
* 转换数据格式(如 JSON 解析)。
* API 与用法
```python
from langchain_core.runnables import RunnableLambda
def log_input(x):
print(f"Input: {x}")
return x
chain = prompt | RunnableLambda(log_input) | model
```
* 案例实战
* 基础文本处理链
```python
from langchain_core.runnables import RunnableLambda
text_clean_chain = (
RunnableLambda(lambda x: x.strip())
| RunnableLambda(str.lower)
)
result = text_clean_chain.invoke(" Hello123World ")
print(result) # 输出 "helloworld"
```
* 打印中间结果并过滤敏感词(在链中插入自定义处理逻辑)
```python
from langchain_core.runnables import RunnableLambda
from langchain_openai import ChatOpenAI
def filter_content(text: str) -> str:
return text.replace("暴力", "***")
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
chain = (
RunnableLambda(lambda x: x["user_input"])
| RunnableLambda(filter_content)
| model
)
result = chain.invoke({"user_input": "暴力内容"})
print(result) # 输出过滤后的结果
```
#### 智能客服路由实战之RunnableBranch条件分支
* `RunnableBranch`
* 核心功能:根据条件选择执行不同的子链,类似 if-else 路由
* API 与用法
```python
from langchain_core.runnables import RunnableBranch
#条件函数:接收输入,返回布尔值。
branch = RunnableBranch(
(condition1, chain1),
(condition2, chain2),
default_chain
)
"""
参数说明:
- Condition: 返回bool的可调用对象
- Runnable: 条件满足时执行的分支
- default: 所有条件不满足时执行的默认分支
技术细节:
1. 条件按声明顺序
2. 第一个满足条件的分支会被执行
3. 无默认分支且所有条件不满足时抛出异常
"""
```
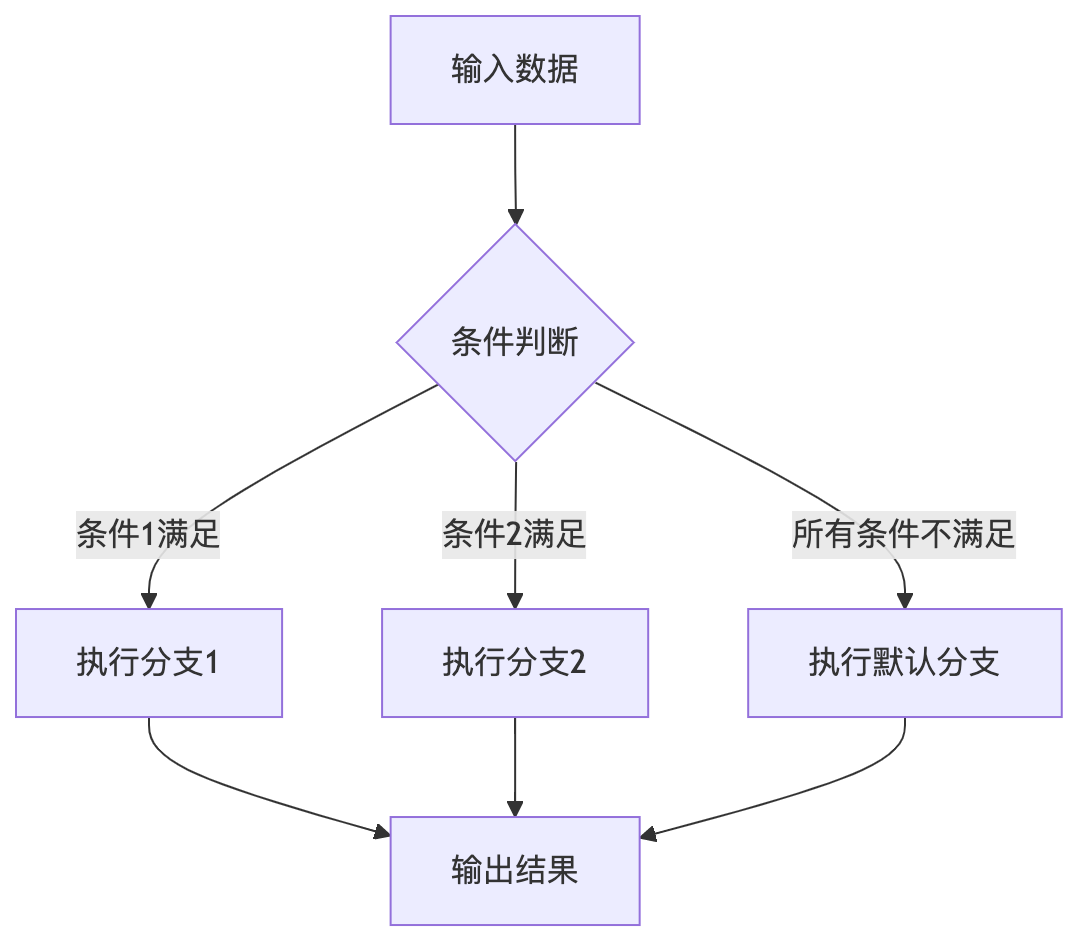 * 适合场景:
* 多任务分类(如区分数学问题与物理问题)
* 错误处理分支(如主链失败时调用备用链)
* 多轮对话路由(根据对话历史选择回复策略)
```
# 根据对话历史选择回复策略
branch = RunnableBranch(
(lambda x: "投诉" in x["history"], complaint_handler),
(lambda x: "咨询" in x["history"], inquiry_handler),
default_responder
)
```
* 智能路由系统(根据输入类型路由处理方式)
```python
# 定义分类函数
def detect_topic(input_text):
if "天气" in input_text:
return "weather"
elif "新闻" in input_text:
return "news"
else:
return "general"
# 构建分支链
branch_chain = RunnableBranch(
(lambda x: detect_topic(x["input"]) == "weather", weather_chain),
(lambda x: detect_topic(x["input"]) == "news", news_chain),
general_chain
)
# 执行示例
branch_chain.invoke({"input": "北京今天天气怎么样?"})
```
* 案例实战:需要构建一个 **智能客服系统**,根据用户输入的请求类型自动路由到不同的处理流程:
* **技术问题**:路由到技术支持链。
* **账单问题**:路由到财务链。
* **默认问题**:路由到通用问答链。
* 步骤
* 导入依赖
```python
from langchain_core.runnables import RunnableBranch, RunnableLambda
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
```
* 定义模型
```python
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
```
* 定义子链
```python
# 技术支持链
tech_prompt = ChatPromptTemplate.from_template(
"你是一名技术支持专家,请回答以下技术问题:{input}"
)
tech_chain = tech_prompt | model | StrOutputParser()
# 财务链
billing_prompt = ChatPromptTemplate.from_template(
"你是一名财务专员,请处理以下账单问题:{input}"
)
billing_chain = billing_prompt | model | StrOutputParser()
# 默认通用链
default_prompt = ChatPromptTemplate.from_template(
"你是一名客服,请回答以下问题:{input}"
)
default_chain = default_prompt | model | StrOutputParser()
```
* 定义路由条件函数
```python
def is_tech_question(input: dict) -> bool:
# 获取 "input" 键对应的值
input_value = input.get("input", "")
# 检查是否包含关键词
return "技术" in input_value or "故障" in input_value
def is_billing_question(input: dict) -> bool:
# 获取 "input" 键对应的值
input_value = input.get("input", "")
# 检查是否包含关键词
return "账单" in input_value or "支付" in input_value
```
* 构建 RunnableBranch
```python
branch = RunnableBranch(
(is_tech_question, tech_chain), # 技术问题 → tech_chain
(is_billing_question, billing_chain), # 账单问题 → billing_chain
default_chain # 默认问题 → default_chain
)
full_chain = RunnableLambda(lambda x: {"input": x}) | branch
```
* 测试案例
```python
# 测试技术问题
tech_response = full_chain.invoke("我的账号登录失败,提示技术故障")
print("技术问题响应:", tech_response)
# 测试账单问题
billing_response = full_chain.invoke("我的账单金额有误,请核对")
print("账单问题响应:", billing_response)
# 测试默认问题
default_response = full_chain.invoke("你们公司的地址在哪里?")
print("默认问题响应:", default_response)
#输出示例
#技术问题响应: 建议您尝试清除浏览器缓存或重置密码。若问题持续,请联系我们的技术支持团队。
#账单问题响应: 已记录您的账单问题,财务部门将在24小时内与您联系核实。
#默认问题响应: 我们的公司地址是北京市海淀区中关村大街1号。
```
* 关键原理解析
* **条件路由逻辑**
* `RunnableBranch` 接收一个由 `(条件函数, Runnable)` 组成的列表。
* 按顺序检查条件,第一个满足条件的分支会被执行,若均不满足则执行默认分支
* **输入处理**:
* 输入需为字典格式(如 `{"input": "问题内容"}`),通过 `RunnableLambda` 包装原始输入为字典
* **链式组合**:
* 每个分支链(如 `tech_chain`)独立处理输入,输出结果直接返回给调用方
* **调试技巧**:
- 添加日志中间件(通过 `RunnableLambda`)记录路由决策过程
```python
def log_decision(input_data):
print(f"路由检查输入:{input_data}")
return input_data
log_chain_branch = RunnableLambda(log_decision) | branch
full_chain = RunnableLambda(lambda x: {"input": x}) | log_chain_branch
```
* 总结与最佳实践
* **组合使用**:通过 `|` 串联或嵌套 `Runnable` 类,构建复杂逻辑。
* **性能优化**:利用 `RunnableParallel` 减少 IO 等待时间。
* **调试技巧**:使用 `RunnableLambda` 插入日志或数据检查点。
* **容错设计**:结合 `RunnableBranch` 和 提升健壮性
### 进阶LLM之Agent智能体和Tool工具实战
#### 大模型Agent智能体介绍和应用场景
* 什么是智能体Agent
* 是一种**具备自主决策能力的AI系统**,通过感知环境、分析信息、调用工具、执行动作的闭环过程完成任务
* 智能体 = 大语言模型(LLM) + 工具(Tools) + 记忆(Memory)
* 核心架构
```
用户输入 → 大模型推理 → 工具选择 → 执行工具 → 结果验证 → 输出响应
↑ ↓ ↑
记忆系统 ↔ 工具库 ↔ 知识库
```
* 类比:一个具备自主决策能力的虚拟助手,能根据目标自主调用工具完成任务
* 适合场景:
* 多任务分类(如区分数学问题与物理问题)
* 错误处理分支(如主链失败时调用备用链)
* 多轮对话路由(根据对话历史选择回复策略)
```
# 根据对话历史选择回复策略
branch = RunnableBranch(
(lambda x: "投诉" in x["history"], complaint_handler),
(lambda x: "咨询" in x["history"], inquiry_handler),
default_responder
)
```
* 智能路由系统(根据输入类型路由处理方式)
```python
# 定义分类函数
def detect_topic(input_text):
if "天气" in input_text:
return "weather"
elif "新闻" in input_text:
return "news"
else:
return "general"
# 构建分支链
branch_chain = RunnableBranch(
(lambda x: detect_topic(x["input"]) == "weather", weather_chain),
(lambda x: detect_topic(x["input"]) == "news", news_chain),
general_chain
)
# 执行示例
branch_chain.invoke({"input": "北京今天天气怎么样?"})
```
* 案例实战:需要构建一个 **智能客服系统**,根据用户输入的请求类型自动路由到不同的处理流程:
* **技术问题**:路由到技术支持链。
* **账单问题**:路由到财务链。
* **默认问题**:路由到通用问答链。
* 步骤
* 导入依赖
```python
from langchain_core.runnables import RunnableBranch, RunnableLambda
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
```
* 定义模型
```python
#定义模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
```
* 定义子链
```python
# 技术支持链
tech_prompt = ChatPromptTemplate.from_template(
"你是一名技术支持专家,请回答以下技术问题:{input}"
)
tech_chain = tech_prompt | model | StrOutputParser()
# 财务链
billing_prompt = ChatPromptTemplate.from_template(
"你是一名财务专员,请处理以下账单问题:{input}"
)
billing_chain = billing_prompt | model | StrOutputParser()
# 默认通用链
default_prompt = ChatPromptTemplate.from_template(
"你是一名客服,请回答以下问题:{input}"
)
default_chain = default_prompt | model | StrOutputParser()
```
* 定义路由条件函数
```python
def is_tech_question(input: dict) -> bool:
# 获取 "input" 键对应的值
input_value = input.get("input", "")
# 检查是否包含关键词
return "技术" in input_value or "故障" in input_value
def is_billing_question(input: dict) -> bool:
# 获取 "input" 键对应的值
input_value = input.get("input", "")
# 检查是否包含关键词
return "账单" in input_value or "支付" in input_value
```
* 构建 RunnableBranch
```python
branch = RunnableBranch(
(is_tech_question, tech_chain), # 技术问题 → tech_chain
(is_billing_question, billing_chain), # 账单问题 → billing_chain
default_chain # 默认问题 → default_chain
)
full_chain = RunnableLambda(lambda x: {"input": x}) | branch
```
* 测试案例
```python
# 测试技术问题
tech_response = full_chain.invoke("我的账号登录失败,提示技术故障")
print("技术问题响应:", tech_response)
# 测试账单问题
billing_response = full_chain.invoke("我的账单金额有误,请核对")
print("账单问题响应:", billing_response)
# 测试默认问题
default_response = full_chain.invoke("你们公司的地址在哪里?")
print("默认问题响应:", default_response)
#输出示例
#技术问题响应: 建议您尝试清除浏览器缓存或重置密码。若问题持续,请联系我们的技术支持团队。
#账单问题响应: 已记录您的账单问题,财务部门将在24小时内与您联系核实。
#默认问题响应: 我们的公司地址是北京市海淀区中关村大街1号。
```
* 关键原理解析
* **条件路由逻辑**
* `RunnableBranch` 接收一个由 `(条件函数, Runnable)` 组成的列表。
* 按顺序检查条件,第一个满足条件的分支会被执行,若均不满足则执行默认分支
* **输入处理**:
* 输入需为字典格式(如 `{"input": "问题内容"}`),通过 `RunnableLambda` 包装原始输入为字典
* **链式组合**:
* 每个分支链(如 `tech_chain`)独立处理输入,输出结果直接返回给调用方
* **调试技巧**:
- 添加日志中间件(通过 `RunnableLambda`)记录路由决策过程
```python
def log_decision(input_data):
print(f"路由检查输入:{input_data}")
return input_data
log_chain_branch = RunnableLambda(log_decision) | branch
full_chain = RunnableLambda(lambda x: {"input": x}) | log_chain_branch
```
* 总结与最佳实践
* **组合使用**:通过 `|` 串联或嵌套 `Runnable` 类,构建复杂逻辑。
* **性能优化**:利用 `RunnableParallel` 减少 IO 等待时间。
* **调试技巧**:使用 `RunnableLambda` 插入日志或数据检查点。
* **容错设计**:结合 `RunnableBranch` 和 提升健壮性
### 进阶LLM之Agent智能体和Tool工具实战
#### 大模型Agent智能体介绍和应用场景
* 什么是智能体Agent
* 是一种**具备自主决策能力的AI系统**,通过感知环境、分析信息、调用工具、执行动作的闭环过程完成任务
* 智能体 = 大语言模型(LLM) + 工具(Tools) + 记忆(Memory)
* 核心架构
```
用户输入 → 大模型推理 → 工具选择 → 执行工具 → 结果验证 → 输出响应
↑ ↓ ↑
记忆系统 ↔ 工具库 ↔ 知识库
```
* 类比:一个具备自主决策能力的虚拟助手,能根据目标自主调用工具完成任务
 * 与传统LLM的关键区别
| 维度 | 常规LLM | Agent |
| :------: | :-----------: | :---------------: |
| 交互方式 | 单轮问答 | 多轮决策链 |
| 能力范围 | 文本生成 | 工具调用+环境交互 |
| 记忆机制 | 短期上下文 | 长期记忆存储 |
| 输出形式 | 自然语言 | 结构化动作序列 |
| 应用场景 | 内容创作/问答 | 复杂任务自动化 |
* 与传统LLM的关键区别
| 维度 | 常规LLM | Agent |
| :------: | :-----------: | :---------------: |
| 交互方式 | 单轮问答 | 多轮决策链 |
| 能力范围 | 文本生成 | 工具调用+环境交互 |
| 记忆机制 | 短期上下文 | 长期记忆存储 |
| 输出形式 | 自然语言 | 结构化动作序列 |
| 应用场景 | 内容创作/问答 | 复杂任务自动化 |
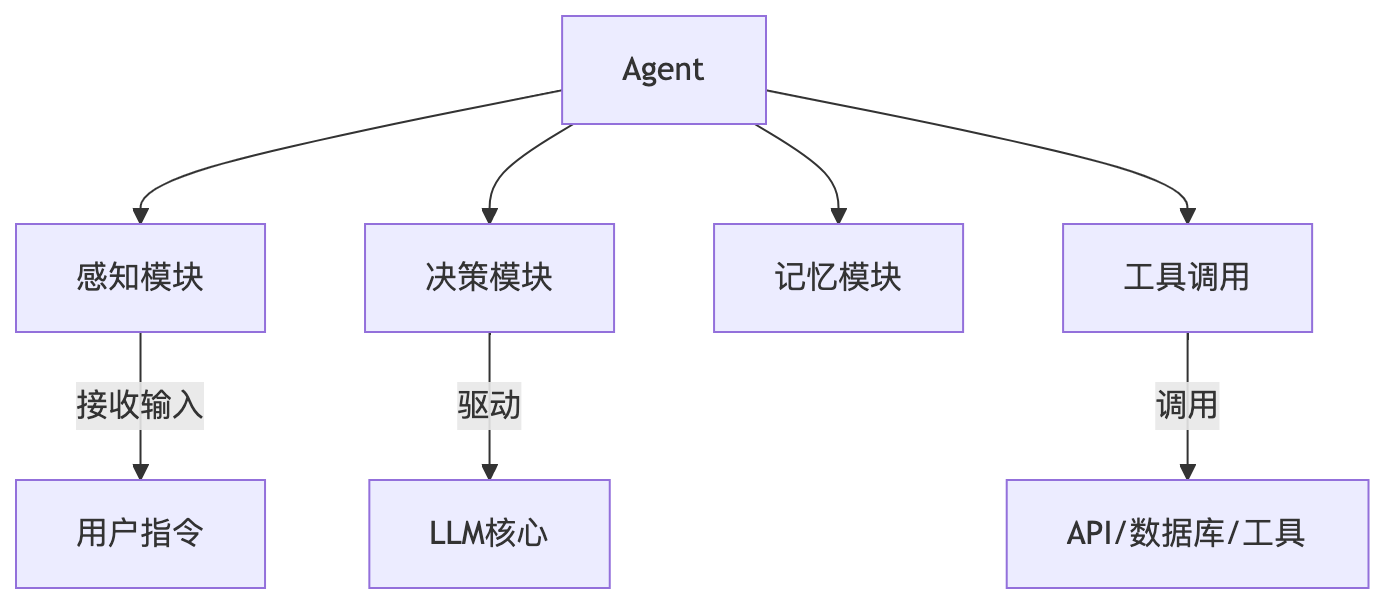 * 常规大模型和Agent案例场景对比
| 测试用例 | 传统模式响应 | Agent模式响应 |
| :--------------: | :----------: | :---------------------------: |
| "北京天气" | 温度数据 | "北京当前晴,12℃,建议穿外套" |
| "明天需要带伞吗" | 无法处理 | 调用天气API分析降水概率 |
| "上周三天气如何" | 报错 | 自动切换历史天气数据库工具 |
* 典型应用场景
* 医疗行业 - 诊断辅助Agent
* 传统系统痛点:
* 基于固定规则的专家系统、无法处理复杂症状组合、知识更新依赖人工维护
* Agent方案关键能力
* 结合最新医学论文(通过工具实时检索,常规大模型没法获取最新数据)
* 自动生成检查建议清单
* 保留患者完整诊疗历史
```python
medical_agent = AgentExecutor(
tools=[
SymptomAnalyzerTool,
MedicalLiteratureTool,
LabTestRecommenderTool
],
memory=PatientHistoryMemory()
)
# 交互示例
response = medical_agent.invoke({
"input": "患者女35岁,持续低烧两周,伴有关节痛",
"history": "既往有类风湿病史"
})
# 输出:建议进行抗核抗体检测+推荐专科医生
```
* 教育行业 - 个性化学习Agent
* 传统在线教育
```python
// 固定学习路径
public class LearningService {
public String getNextStep(String userId) {
int score = db.getUserScore(userId);
if (score < 60) {
return "重新学习第三章";
}
return "进入第四章";
}
}
```
* Agent方案关键能力
* 动态调整学习路径(基于实时掌握程度)
* 多模态教学内容推荐(视频/图文/交互实验)
* 自动生成错题分析报告
```python
class TutorAgent:
tools = [
KnowledgeGraphTool,
ExerciseRecommenderTool,
LearningStyleAnalyzerTool
]
def guide_student(self, studentQuery):
# 动态决策:
# 1. 分析学生知识薄弱点
# 2. 根据学习风格推荐资料
# 3. 生成个性化练习计划
return self.agent_executor.invoke(studentQuery)
```
* Agent智能体案例(伪代码)
```python
from langchain.agents import AgentExecutor, create_react_agent
from langchain import hub
# 定义工具集
tools = [
Tool(
name="WeatherCheck",
func=get_weather_api_data,
description="查询实时天气数据"
),
Tool(
name="CalendarAccess",
func=read_google_calendar,
description="访问用户日历信息"
)
]
# 构建Agent
prompt = hub.pull("hwchase17/react")
agent = create_react_agent(
llm=ChatOpenAI(temperature=0),
tools=tools,
prompt=prompt
)
# 执行示例
agent_executor = AgentExecutor(agent=agent, tools=tools)
result = agent_executor.invoke({
"input": "帮我安排明天北京的户外会议,需要考虑天气情况"
})
print(result["output"])
#典型输出示例
思考过程:
1. 需要确定明天北京的天气(调用WeatherCheck)
2. 查询明天下午2点的天气预报
3. 如果天气适宜,查找明天下午的空闲时段(调用CalendarAccess)
4. 综合结果建议会议时间
最终输出:建议将会议安排在明天下午15:00,天气预报显示晴,气温22℃。
```
#### 大模型痛点和LangChain工具Tool实战
* 需求背景:
* **大模型的短板**:虽然大语言模型(LLM)擅长文本生成,但缺乏:
- 实时数据获取能力(如天气/股票)、精确数学计算能力
- 专业领域知识(如法律/医疗)、外部系统对接能力
* Tool工具就是解决这类问题的,通过Tool机制,好比给大模型插入翅膀
* 大模型的Tool工具
* Tool是LLM与外部世界交互的接口,让大模型能调用外部功能(如API、函数、数据库)
* 核心
* 突破大模型静态知识库限制
* 实时获取外部数据(如天气/股票)
* 执行复杂计算业务逻辑
* 连接现有软件系统(如CRM、各个系统API)
* 工具生命周期
```
工具定义 → 2. Agent注册 → 3. 自动调用 → 4. 结果处理
```
* LangChain里面创建工具
* @tool装饰器
* 通过简单的@tool装饰器或StructuredTool即可实现,适用于大多数用例,
* @tool但不能同时有同步和异步的方法,只能单独使用
* LangChain Runnables
* 接受字符串或字典输入的LangChain Runnables使用as_tool方法转换为工具
* 允许为参数指定名称、描述和其他模式信息;
* 继承BaseTool类:
* 通过从BaseTool进行子类化来定义自定义工具,提供了对工具定义的最大控制,但需要编写更多的代码。
* LangChain里面Tool实战
* **@tool 装饰器**:用来定义一个简单的工具函数,, 可以直接给函数加上这个装饰器,让函数成为可调用的工具
* 简单定义, **需要加上文档字符串注释描述,AI才知道工具的用途**
```python
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""把传递的两个参数相乘"""
return a * b
print("工具名称:", multiply.name)
print("工具描述:", multiply.description)
print("工具参数:", multiply.args)
print("工具返回值:", multiply.return_direct)
print("工具详细的schema:",multiply.args_schema.model_json_schema())
print(multiply.invoke({"a": 2, "b": 3}))
#定义了一个 `multiply` 工具,用于两个数字相乘,并在调用时显示该工具的名称、描述和参数列表。
```
* 配置参数
```python
from pydantic import BaseModel, Field
from langchain_core.tools import tool
class CalculatorInput(BaseModel):
a: int = Field(description="第一个参数")
b: int = Field(description="第二个参数")
@tool("multiplication-tool", args_schema=CalculatorInput, return_direct=True)
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
# Let's inspect some of the attributes associated with the tool.
print("工具名称:", multiply.name)
print("工具描述:", multiply.description)
print("工具参数:", multiply.args)
print("工具返回值:", multiply.return_direct)
print("工具详细的schema:",multiply.args_schema.model_json_schema())
```
* 核心组件
| **组件** | **作用** | **示例** |
| :---------------------------- | :--------------------------------------------------------- | :----------------------------- |
| **名称(name)** | 工具唯一标识符,代理通过名称匹配调用工具 | `wikipedia`、`google_search` |
| **描述(description)** | 工具功能的自然语言描述,代理根据描述决定是否调用工具 | "查询维基百科内容" |
| **输入参数(args_schema)** | 定义工具的参数格式(Pydantic模型),用于参数校验与提示生成 | `query: str` |
| **执行函数(func)** | 实际执行操作的函数(如调用API、运行Shell命令) | `def run(query: str): ...` |
| **返回模式(return_direct)** | 若为`True`,代理直接返回工具结果,不再生成额外文本 | 适用于无需进一步推理的简单任务 |
* `StructuredTool ` 介绍
* 是LangChain中用于定义**结构化参数工具**的基类,相比普通`@tool`装饰器,它支持:
- **严格的参数模式定义**(基于Pydantic模型)
- **多参数输入校验**
- **自动生成工具调用示例**
* **适用场景**:需要多个输入参数或复杂参数类型的工具
| **特性** | **普通@tool装饰器** | **StructuredTool** |
| :------------- | :--------------------------- | :------------------------------- |
| **参数定义** | 简单参数(单个字符串或字典) | 基于Pydantic模型的严格参数模式 |
| **参数校验** | 弱校验(依赖代码逻辑) | 强校验(自动类型检查和格式验证) |
| **多参数支持** | 需手动解析字典参数 | 直接映射多个命名参数 |
| **使用复杂度** | 快速定义简单工具 | 适合复杂业务逻辑的工具 |
* 案例实战
```python
from pydantic import BaseModel, Field
from langchain_core.tools import StructuredTool
# 定义输入参数的数据结构
class CalculatorInput(BaseModel):
a: int = Field(description="第一个数字")
b: int = Field(description="第二个数字")
# 定义计算函数
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
# 封装工具
calculator = StructuredTool.from_function(
func=multiply,
name="Calculator",
description="用于计算两个数字的乘积",
args_schema=CalculatorInput,
return_direct=True,
)
print("工具名称:", calculator.name)
print("工具描述:", calculator.description)
print("工具参数:", calculator.args)
print("工具返回值:", calculator.return_direct)
print("工具详细的schema:",calculator.args_schema.model_json_schema())
# 调用工具
print("工具调用结果:", calculator.invoke({"a": 2, "b": 3}))
```
* 使用继承`BaseTool`子类进行创建工具
```python
from pydantic import BaseModel, Field
from typing import Type
from langchain_core.tools import BaseTool
from pydantic import BaseModel
class CalculatorInput(BaseModel):
a: int = Field(description="第一个参数")
b: int = Field(description="第二个参数")
class CustomCalculatorTool(BaseTool):
name: str = "Calculator"
description: str = "当你需要计算数学问题时候使用"
args_schema: Type[BaseModel] = CalculatorInput
return_direct: bool = True
def _run(
self, a: int, b: int
) -> str:
"""使用工具."""
return a * b
calculator = CustomCalculatorTool()
print("工具名称:", calculator.name)
print("工具描述:", calculator.description)
print("工具参数:", calculator.args)
print("工具返回值:", calculator.return_direct)
print("工具详细的schema:",calculator.args_schema.model_json_schema())
print(calculator.invoke({"a": 2, "b": 3}))
```
#### LLM大模型绑定工具Tool案例实战
* 需求
* 定义了工具,需要把工具绑定给大模型, 大模型会在合适的时候,选择对应的工具函数
* **解决痛点**:如天气查询/股票数据/订单处理等需要实时数据的场景
* **类比理解**:给大模型装"手和脚",像钢铁侠的AI助手贾维斯可操作战甲
* 注意
* 虽然“工具调用”这个名称暗示模型直接执行某些操作,但实际上并非如此!
* 模型仅生成工具的参数,实际运行工具(或不运行)取决于用户的需求
| 要素 | 作用 | 示例 |
| :------: | :------------------------------: | :------------------------------: |
| 工具描述 | 告诉模型工具的功能和使用方法 | 天气查询API的输入输出说明 |
| 参数解析 | 从自然语言中提取结构化参数 | 提取"北京今天温度"中的城市和日期 |
| 执行反馈 | 将工具返回结果重新组织成自然语言 | 把JSON天气数据转为口语化描述 |
* 技术实现流程
```
用户输入 → 大模型分析意图 → 选择工具 → 提取参数 → 调用工具 → 结果格式化 → 最终回复
```
* 大模型绑定工具api
* 支持工具调用功能的聊天模型, 直接使用`.bind_tools( )`方法,传入工具列表即可
```python
def bind_tools(
self,
tools: Sequence[Union[Dict[str, Any], Type, Callable, BaseTool]],
*,
tool_choice: Optional[
Union[dict, str, Literal["auto", "none", "required", "any"], bool]
] = None,
strict: Optional[bool] = None,
parallel_tool_calls: Optional[bool] = None,
**kwargs: Any,
) -> Runnable[LanguageModelInput, BaseMessage]:
```
* 注意:不是全部大模型都是支持绑定工具列表,
* 大模型绑定工具的伪代码参考
```python
tools = [add, multiply]
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
llm_with_tools = llm.bind_tools(tools)
query = "What is 3 * 12?"
resp = llm_with_tools.invoke(query)
```
* 工具调用
* 第一步
* 大模型如果需要调用工具,则生成响应里面包括了工具调用信息,本身的content内容为空
* 大模型响应的消息 或消息块 作为工具调用对象的列表,位于`.tool_calls`属性中。
* 聊天模型可以同时调用多个工具, 包含 工具名称、参数值字典和(可选)标识符的类型字典。
* 没有工具调用的消息 默认将此属性设置为空列表
```python
# 使用绑定工具的模型处理用户查询
ai_msg = llm_with_tools.invoke(messages)
# 打印ai_msg对象的tool_calls属性,显示AI消息中包含的工具调用信息
print(ai_msg.tool_calls)
{'tool_calls':
[
{
'id': 'call_ea723d86cf804a088b946a',
'function': {'arguments': '{"a": 3, "b": 12}', 'name': 'multiply'},
'type': 'function', 'index': 0}
]
}
```
* 第二步
* 提取大模型响应信息里面的选择的工具,代码编写 选择对应的工具进行执行
```python
# 遍历AI消息中的工具调用
for tool_call in ai_msg.tool_calls:
# 根据工具调用的名称选择相应的工具函数
selected_tool = {"add": add, "multiply": multiply}[tool_call["name"].lower()]
print(f"selected_tool:{selected_tool}")
# 调用选中的工具函数并获取结果
tool_msg = selected_tool.invoke(tool_call)
print(f"tool_msg:{tool_msg}")
# 将工具调用的结果添加到messages列表中
messages.append(tool_msg)
```
* `invoke()`执行后,会生成执行结果对象 `ToolMessage`, 包括与模型生成的原始工具调用中的 `id` 匹配的 `tool_call_id`
```
ToolMessage(content='36', name='multiply', tool_call_id='call_1319a58494c54998842092')]
```
* 第三步
* 将工具调用的结果添加到消息messages列表中,再传递给大模型,大模型会重新进行执行,组织对应的语言返回
```python
# 再次使用绑定工具的模型处理更新后的messages列表
reslut = llm_with_tools.invoke(messages)
# 打印最终结果
print(f"最终结果:{reslut}")
最终结果: content='3 乘以 12 的结果是 36。' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 16, 'prompt_tokens': 272, 'total_tokens': 288, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'qwen-plus', 'system_fingerprint': None, 'id': 'chatcmpl-b499cd0b-29d4-9d83-8473-e41d7214223d', 'finish_reason': 'stop', 'logprobs': None} id='run-8046aa25-091a-4df3-a49a-aa36811c8d44-0' usage_metadata={'input_tokens': 272, 'output_tokens': 16, 'total_tokens': 288, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}
```
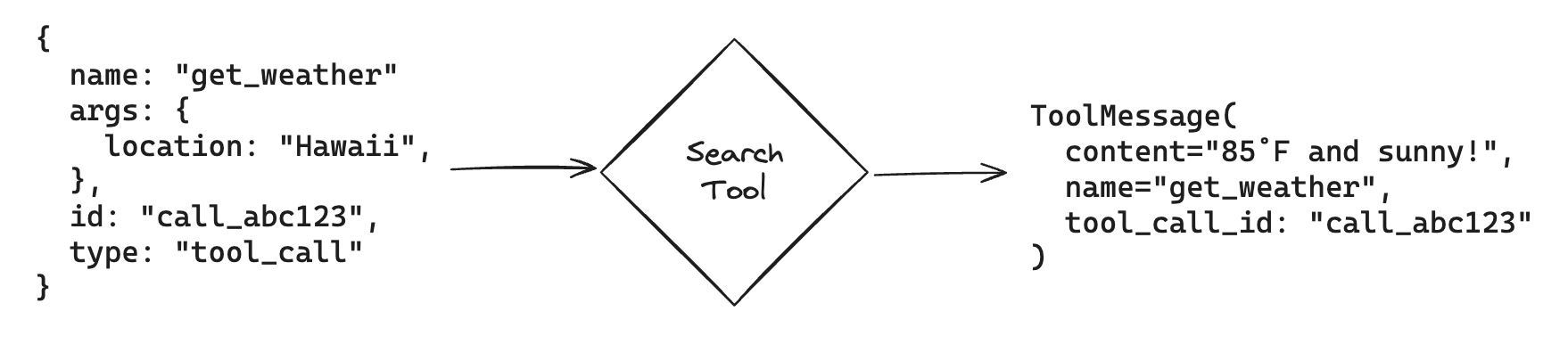

* 完整案例实战
```python
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
# 定义一个加法工具函数
@tool
def add(a: int, b: int) -> int:
"""Adds a and b."""
return a + b
# 定义一个乘法工具函数
@tool
def multiply(a: int, b: int) -> int:
"""Multiplies a and b."""
return a * b
# 定义模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 将前面定义的工具函数整合到一个列表中
tools = [add, multiply]
# 将工具函数绑定到语言模型
llm_with_tools = llm.bind_tools(tools)
# 定义用户查询
query = "3 * 12 结果是多少"
# 创建一个包含用户查询的messages列表
messages = [HumanMessage(query)]
# 使用绑定工具的模型处理用户查询
ai_msg = llm_with_tools.invoke(messages)
# 打印ai_msg对象,以便用户可以看到AI的消息响应
print(ai_msg)
# 打印ai_msg对象的tool_calls属性,显示AI消息中包含的工具调用信息
print(ai_msg.tool_calls)
# 将AI的消息添加到messages列表中
messages.append(ai_msg)
# 遍历AI消息中的工具调用
for tool_call in ai_msg.tool_calls:
# 根据工具调用的名称选择相应的工具函数
selected_tool = {"add": add, "multiply": multiply}[tool_call["name"].lower()]
print(f"selected_tool:{selected_tool}")
# 调用选中的工具函数并获取结果
tool_msg = selected_tool.invoke(tool_call)
print(f"tool_msg:{tool_msg}")
# 将工具调用的结果添加到messages列表中
messages.append(tool_msg)
# 打印更新后的messages列表
print(f"打印更新后的messages列表:{messages}")
# 再次使用绑定工具的模型处理更新后的messages列表
reslut = llm_with_tools.invoke(messages)
# 打印最终结果
print(res
```
#### LangChain内置工具包和联网搜索实战
* LangChain工具包
* 方便开发者快速使用各种主流工具,LangChain官方加入了很多内置工具,开箱即用
* 所有工具都是 BaseTool 的子类,且工具是 Runnable可运行组件,支持 invoke、stream 等方法进行调用
* 也可以通过 name、 description、args、 returu_direct 等属性来获取到工具的相关信息
* 如果内置工具包不满足,即可以自定义工具
* 地址(失效忽略即可):https://python.langchain.com/docs/integrations/tools/
* 常规大模型和Agent案例场景对比
| 测试用例 | 传统模式响应 | Agent模式响应 |
| :--------------: | :----------: | :---------------------------: |
| "北京天气" | 温度数据 | "北京当前晴,12℃,建议穿外套" |
| "明天需要带伞吗" | 无法处理 | 调用天气API分析降水概率 |
| "上周三天气如何" | 报错 | 自动切换历史天气数据库工具 |
* 典型应用场景
* 医疗行业 - 诊断辅助Agent
* 传统系统痛点:
* 基于固定规则的专家系统、无法处理复杂症状组合、知识更新依赖人工维护
* Agent方案关键能力
* 结合最新医学论文(通过工具实时检索,常规大模型没法获取最新数据)
* 自动生成检查建议清单
* 保留患者完整诊疗历史
```python
medical_agent = AgentExecutor(
tools=[
SymptomAnalyzerTool,
MedicalLiteratureTool,
LabTestRecommenderTool
],
memory=PatientHistoryMemory()
)
# 交互示例
response = medical_agent.invoke({
"input": "患者女35岁,持续低烧两周,伴有关节痛",
"history": "既往有类风湿病史"
})
# 输出:建议进行抗核抗体检测+推荐专科医生
```
* 教育行业 - 个性化学习Agent
* 传统在线教育
```python
// 固定学习路径
public class LearningService {
public String getNextStep(String userId) {
int score = db.getUserScore(userId);
if (score < 60) {
return "重新学习第三章";
}
return "进入第四章";
}
}
```
* Agent方案关键能力
* 动态调整学习路径(基于实时掌握程度)
* 多模态教学内容推荐(视频/图文/交互实验)
* 自动生成错题分析报告
```python
class TutorAgent:
tools = [
KnowledgeGraphTool,
ExerciseRecommenderTool,
LearningStyleAnalyzerTool
]
def guide_student(self, studentQuery):
# 动态决策:
# 1. 分析学生知识薄弱点
# 2. 根据学习风格推荐资料
# 3. 生成个性化练习计划
return self.agent_executor.invoke(studentQuery)
```
* Agent智能体案例(伪代码)
```python
from langchain.agents import AgentExecutor, create_react_agent
from langchain import hub
# 定义工具集
tools = [
Tool(
name="WeatherCheck",
func=get_weather_api_data,
description="查询实时天气数据"
),
Tool(
name="CalendarAccess",
func=read_google_calendar,
description="访问用户日历信息"
)
]
# 构建Agent
prompt = hub.pull("hwchase17/react")
agent = create_react_agent(
llm=ChatOpenAI(temperature=0),
tools=tools,
prompt=prompt
)
# 执行示例
agent_executor = AgentExecutor(agent=agent, tools=tools)
result = agent_executor.invoke({
"input": "帮我安排明天北京的户外会议,需要考虑天气情况"
})
print(result["output"])
#典型输出示例
思考过程:
1. 需要确定明天北京的天气(调用WeatherCheck)
2. 查询明天下午2点的天气预报
3. 如果天气适宜,查找明天下午的空闲时段(调用CalendarAccess)
4. 综合结果建议会议时间
最终输出:建议将会议安排在明天下午15:00,天气预报显示晴,气温22℃。
```
#### 大模型痛点和LangChain工具Tool实战
* 需求背景:
* **大模型的短板**:虽然大语言模型(LLM)擅长文本生成,但缺乏:
- 实时数据获取能力(如天气/股票)、精确数学计算能力
- 专业领域知识(如法律/医疗)、外部系统对接能力
* Tool工具就是解决这类问题的,通过Tool机制,好比给大模型插入翅膀
* 大模型的Tool工具
* Tool是LLM与外部世界交互的接口,让大模型能调用外部功能(如API、函数、数据库)
* 核心
* 突破大模型静态知识库限制
* 实时获取外部数据(如天气/股票)
* 执行复杂计算业务逻辑
* 连接现有软件系统(如CRM、各个系统API)
* 工具生命周期
```
工具定义 → 2. Agent注册 → 3. 自动调用 → 4. 结果处理
```
* LangChain里面创建工具
* @tool装饰器
* 通过简单的@tool装饰器或StructuredTool即可实现,适用于大多数用例,
* @tool但不能同时有同步和异步的方法,只能单独使用
* LangChain Runnables
* 接受字符串或字典输入的LangChain Runnables使用as_tool方法转换为工具
* 允许为参数指定名称、描述和其他模式信息;
* 继承BaseTool类:
* 通过从BaseTool进行子类化来定义自定义工具,提供了对工具定义的最大控制,但需要编写更多的代码。
* LangChain里面Tool实战
* **@tool 装饰器**:用来定义一个简单的工具函数,, 可以直接给函数加上这个装饰器,让函数成为可调用的工具
* 简单定义, **需要加上文档字符串注释描述,AI才知道工具的用途**
```python
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""把传递的两个参数相乘"""
return a * b
print("工具名称:", multiply.name)
print("工具描述:", multiply.description)
print("工具参数:", multiply.args)
print("工具返回值:", multiply.return_direct)
print("工具详细的schema:",multiply.args_schema.model_json_schema())
print(multiply.invoke({"a": 2, "b": 3}))
#定义了一个 `multiply` 工具,用于两个数字相乘,并在调用时显示该工具的名称、描述和参数列表。
```
* 配置参数
```python
from pydantic import BaseModel, Field
from langchain_core.tools import tool
class CalculatorInput(BaseModel):
a: int = Field(description="第一个参数")
b: int = Field(description="第二个参数")
@tool("multiplication-tool", args_schema=CalculatorInput, return_direct=True)
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
# Let's inspect some of the attributes associated with the tool.
print("工具名称:", multiply.name)
print("工具描述:", multiply.description)
print("工具参数:", multiply.args)
print("工具返回值:", multiply.return_direct)
print("工具详细的schema:",multiply.args_schema.model_json_schema())
```
* 核心组件
| **组件** | **作用** | **示例** |
| :---------------------------- | :--------------------------------------------------------- | :----------------------------- |
| **名称(name)** | 工具唯一标识符,代理通过名称匹配调用工具 | `wikipedia`、`google_search` |
| **描述(description)** | 工具功能的自然语言描述,代理根据描述决定是否调用工具 | "查询维基百科内容" |
| **输入参数(args_schema)** | 定义工具的参数格式(Pydantic模型),用于参数校验与提示生成 | `query: str` |
| **执行函数(func)** | 实际执行操作的函数(如调用API、运行Shell命令) | `def run(query: str): ...` |
| **返回模式(return_direct)** | 若为`True`,代理直接返回工具结果,不再生成额外文本 | 适用于无需进一步推理的简单任务 |
* `StructuredTool ` 介绍
* 是LangChain中用于定义**结构化参数工具**的基类,相比普通`@tool`装饰器,它支持:
- **严格的参数模式定义**(基于Pydantic模型)
- **多参数输入校验**
- **自动生成工具调用示例**
* **适用场景**:需要多个输入参数或复杂参数类型的工具
| **特性** | **普通@tool装饰器** | **StructuredTool** |
| :------------- | :--------------------------- | :------------------------------- |
| **参数定义** | 简单参数(单个字符串或字典) | 基于Pydantic模型的严格参数模式 |
| **参数校验** | 弱校验(依赖代码逻辑) | 强校验(自动类型检查和格式验证) |
| **多参数支持** | 需手动解析字典参数 | 直接映射多个命名参数 |
| **使用复杂度** | 快速定义简单工具 | 适合复杂业务逻辑的工具 |
* 案例实战
```python
from pydantic import BaseModel, Field
from langchain_core.tools import StructuredTool
# 定义输入参数的数据结构
class CalculatorInput(BaseModel):
a: int = Field(description="第一个数字")
b: int = Field(description="第二个数字")
# 定义计算函数
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
# 封装工具
calculator = StructuredTool.from_function(
func=multiply,
name="Calculator",
description="用于计算两个数字的乘积",
args_schema=CalculatorInput,
return_direct=True,
)
print("工具名称:", calculator.name)
print("工具描述:", calculator.description)
print("工具参数:", calculator.args)
print("工具返回值:", calculator.return_direct)
print("工具详细的schema:",calculator.args_schema.model_json_schema())
# 调用工具
print("工具调用结果:", calculator.invoke({"a": 2, "b": 3}))
```
* 使用继承`BaseTool`子类进行创建工具
```python
from pydantic import BaseModel, Field
from typing import Type
from langchain_core.tools import BaseTool
from pydantic import BaseModel
class CalculatorInput(BaseModel):
a: int = Field(description="第一个参数")
b: int = Field(description="第二个参数")
class CustomCalculatorTool(BaseTool):
name: str = "Calculator"
description: str = "当你需要计算数学问题时候使用"
args_schema: Type[BaseModel] = CalculatorInput
return_direct: bool = True
def _run(
self, a: int, b: int
) -> str:
"""使用工具."""
return a * b
calculator = CustomCalculatorTool()
print("工具名称:", calculator.name)
print("工具描述:", calculator.description)
print("工具参数:", calculator.args)
print("工具返回值:", calculator.return_direct)
print("工具详细的schema:",calculator.args_schema.model_json_schema())
print(calculator.invoke({"a": 2, "b": 3}))
```
#### LLM大模型绑定工具Tool案例实战
* 需求
* 定义了工具,需要把工具绑定给大模型, 大模型会在合适的时候,选择对应的工具函数
* **解决痛点**:如天气查询/股票数据/订单处理等需要实时数据的场景
* **类比理解**:给大模型装"手和脚",像钢铁侠的AI助手贾维斯可操作战甲
* 注意
* 虽然“工具调用”这个名称暗示模型直接执行某些操作,但实际上并非如此!
* 模型仅生成工具的参数,实际运行工具(或不运行)取决于用户的需求
| 要素 | 作用 | 示例 |
| :------: | :------------------------------: | :------------------------------: |
| 工具描述 | 告诉模型工具的功能和使用方法 | 天气查询API的输入输出说明 |
| 参数解析 | 从自然语言中提取结构化参数 | 提取"北京今天温度"中的城市和日期 |
| 执行反馈 | 将工具返回结果重新组织成自然语言 | 把JSON天气数据转为口语化描述 |
* 技术实现流程
```
用户输入 → 大模型分析意图 → 选择工具 → 提取参数 → 调用工具 → 结果格式化 → 最终回复
```
* 大模型绑定工具api
* 支持工具调用功能的聊天模型, 直接使用`.bind_tools( )`方法,传入工具列表即可
```python
def bind_tools(
self,
tools: Sequence[Union[Dict[str, Any], Type, Callable, BaseTool]],
*,
tool_choice: Optional[
Union[dict, str, Literal["auto", "none", "required", "any"], bool]
] = None,
strict: Optional[bool] = None,
parallel_tool_calls: Optional[bool] = None,
**kwargs: Any,
) -> Runnable[LanguageModelInput, BaseMessage]:
```
* 注意:不是全部大模型都是支持绑定工具列表,
* 大模型绑定工具的伪代码参考
```python
tools = [add, multiply]
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o-mini")
llm_with_tools = llm.bind_tools(tools)
query = "What is 3 * 12?"
resp = llm_with_tools.invoke(query)
```
* 工具调用
* 第一步
* 大模型如果需要调用工具,则生成响应里面包括了工具调用信息,本身的content内容为空
* 大模型响应的消息 或消息块 作为工具调用对象的列表,位于`.tool_calls`属性中。
* 聊天模型可以同时调用多个工具, 包含 工具名称、参数值字典和(可选)标识符的类型字典。
* 没有工具调用的消息 默认将此属性设置为空列表
```python
# 使用绑定工具的模型处理用户查询
ai_msg = llm_with_tools.invoke(messages)
# 打印ai_msg对象的tool_calls属性,显示AI消息中包含的工具调用信息
print(ai_msg.tool_calls)
{'tool_calls':
[
{
'id': 'call_ea723d86cf804a088b946a',
'function': {'arguments': '{"a": 3, "b": 12}', 'name': 'multiply'},
'type': 'function', 'index': 0}
]
}
```
* 第二步
* 提取大模型响应信息里面的选择的工具,代码编写 选择对应的工具进行执行
```python
# 遍历AI消息中的工具调用
for tool_call in ai_msg.tool_calls:
# 根据工具调用的名称选择相应的工具函数
selected_tool = {"add": add, "multiply": multiply}[tool_call["name"].lower()]
print(f"selected_tool:{selected_tool}")
# 调用选中的工具函数并获取结果
tool_msg = selected_tool.invoke(tool_call)
print(f"tool_msg:{tool_msg}")
# 将工具调用的结果添加到messages列表中
messages.append(tool_msg)
```
* `invoke()`执行后,会生成执行结果对象 `ToolMessage`, 包括与模型生成的原始工具调用中的 `id` 匹配的 `tool_call_id`
```
ToolMessage(content='36', name='multiply', tool_call_id='call_1319a58494c54998842092')]
```
* 第三步
* 将工具调用的结果添加到消息messages列表中,再传递给大模型,大模型会重新进行执行,组织对应的语言返回
```python
# 再次使用绑定工具的模型处理更新后的messages列表
reslut = llm_with_tools.invoke(messages)
# 打印最终结果
print(f"最终结果:{reslut}")
最终结果: content='3 乘以 12 的结果是 36。' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 16, 'prompt_tokens': 272, 'total_tokens': 288, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}}, 'model_name': 'qwen-plus', 'system_fingerprint': None, 'id': 'chatcmpl-b499cd0b-29d4-9d83-8473-e41d7214223d', 'finish_reason': 'stop', 'logprobs': None} id='run-8046aa25-091a-4df3-a49a-aa36811c8d44-0' usage_metadata={'input_tokens': 272, 'output_tokens': 16, 'total_tokens': 288, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}
```


* 完整案例实战
```python
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
# 定义一个加法工具函数
@tool
def add(a: int, b: int) -> int:
"""Adds a and b."""
return a + b
# 定义一个乘法工具函数
@tool
def multiply(a: int, b: int) -> int:
"""Multiplies a and b."""
return a * b
# 定义模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 将前面定义的工具函数整合到一个列表中
tools = [add, multiply]
# 将工具函数绑定到语言模型
llm_with_tools = llm.bind_tools(tools)
# 定义用户查询
query = "3 * 12 结果是多少"
# 创建一个包含用户查询的messages列表
messages = [HumanMessage(query)]
# 使用绑定工具的模型处理用户查询
ai_msg = llm_with_tools.invoke(messages)
# 打印ai_msg对象,以便用户可以看到AI的消息响应
print(ai_msg)
# 打印ai_msg对象的tool_calls属性,显示AI消息中包含的工具调用信息
print(ai_msg.tool_calls)
# 将AI的消息添加到messages列表中
messages.append(ai_msg)
# 遍历AI消息中的工具调用
for tool_call in ai_msg.tool_calls:
# 根据工具调用的名称选择相应的工具函数
selected_tool = {"add": add, "multiply": multiply}[tool_call["name"].lower()]
print(f"selected_tool:{selected_tool}")
# 调用选中的工具函数并获取结果
tool_msg = selected_tool.invoke(tool_call)
print(f"tool_msg:{tool_msg}")
# 将工具调用的结果添加到messages列表中
messages.append(tool_msg)
# 打印更新后的messages列表
print(f"打印更新后的messages列表:{messages}")
# 再次使用绑定工具的模型处理更新后的messages列表
reslut = llm_with_tools.invoke(messages)
# 打印最终结果
print(res
```
#### LangChain内置工具包和联网搜索实战
* LangChain工具包
* 方便开发者快速使用各种主流工具,LangChain官方加入了很多内置工具,开箱即用
* 所有工具都是 BaseTool 的子类,且工具是 Runnable可运行组件,支持 invoke、stream 等方法进行调用
* 也可以通过 name、 description、args、 returu_direct 等属性来获取到工具的相关信息
* 如果内置工具包不满足,即可以自定义工具
* 地址(失效忽略即可):https://python.langchain.com/docs/integrations/tools/
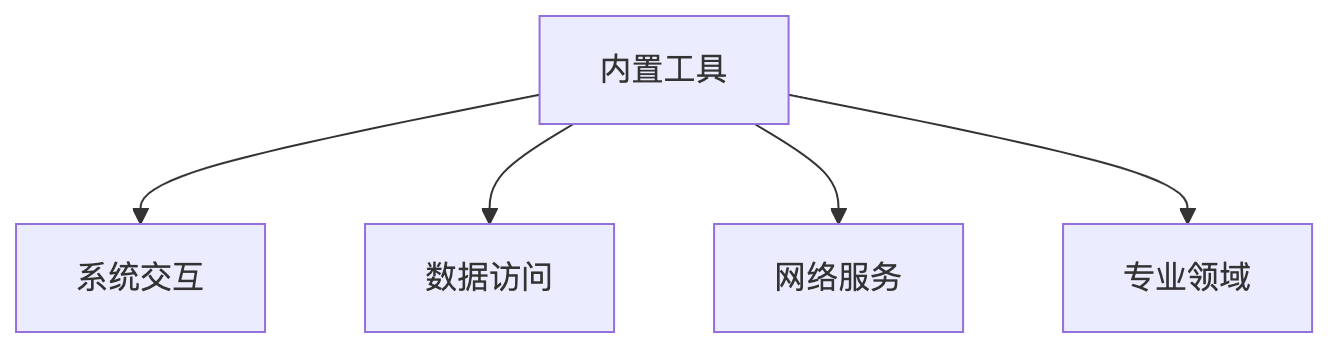 * 如何使用内置工具包【联网搜索例子】
* 选择对应的工具->安装依赖包->编写代码实战
* 案例实战
* 搜索工具:选择 SearchApi,注册时100次免费搜索,注册账号获取 APIKEY
* 如何使用内置工具包【联网搜索例子】
* 选择对应的工具->安装依赖包->编写代码实战
* 案例实战
* 搜索工具:选择 SearchApi,注册时100次免费搜索,注册账号获取 APIKEY
 * 编写代码
```python
# 导入操作系统接口模块,用于与环境变量交互
import os
# 从langchain_community.utilities模块中导入SearchApiAPIWrapper类,用于封装搜索API
from langchain_community.utilities import SearchApiAPIWrapper
# 设置环境变量SEARCHAPI_API_KEY,用于认证搜索API的密钥
os.environ["SEARCHAPI_API_KEY"] = "qQBHMQo4Rk8SihmpJjCs7fML"
# 实例化SearchApiAPIWrapper对象,用于调用搜索API
search = SearchApiAPIWrapper()
# 调用run方法执行搜索操作,参数为查询腾讯股价的中文字符串
result = search.run("今天腾讯的股价是多少")
# 输出搜索结果
print(result)
```
* 拓展
* SearchApi 包装器可以自定义为使用不同的引擎,如 Google News、Google Jobs、Google Scholar
* 其他可以在 SearchApi 文档中找到的引擎。执行查询时可以传递 SearchApi 支持的所有参数。
```
search = SearchApiAPIWrapper(engine="google_jobs")
```
* 获取元数据
```python
result_meta = search.results("今天腾讯的股价是多少")
print(result_meta)
```
#### 兜底降级-LangChain调用工具Tool异常处理
* 需求背景
* 智能体(Agent)在调用外部工具(如 API、数据库、搜索引擎)时,会遇到各种不可预知的错误
* 例如:
- 网络请求失败(如 API 无响应)
- 权限不足(如访问密钥失效)
- 输入参数不合法(如格式错误)
- 资源限制(如 API 调用次数超限)
* 如果智能体不处理这些错误,会导致:
* **程序崩溃**:直接抛出未捕获的异常。
* **用户困惑**:返回难以理解的错误堆栈信息。
* **无法恢复**:智能体无法根据错误调整策略(如重试或切换工具)
* 解决方案 `ToolException`:
* 通过 ToolException 统一捕获和处理工具调用中的错误,使智能体具备容错能力和用户友好的错误反馈
* ToolException 的核心作用
* 统一错误格式:将不同工具的异常转换为标准格式,方便智能体解析。
* 错误上下文传递:保留错误原因、工具名称等关键信息。
* 使用场景举例
* **API 调用失败**:如天气查询接口超时。
* **权限校验失败**:如访问数据库的密钥过期。
* **输入参数校验**:如用户输入的城市名不存在。
* **资源限制**:如每日调用次数用尽。
* 案例实战
* 方式一:配置响应 `handle_tool_error=True` 默认是false
```python
from langchain_core.tools import tool, ToolException, StructuredTool
def search(query: str) -> str:
"""
执行搜索查询
"""
# 引发一个ToolException来模拟搜索结果为空的情况
raise ToolException(f"相关搜索结果为空:{query}")
# 使用StructuredTool从函数创建一个工具实例
# handle_tool_error参数设置为True,表示工具将处理内部异常
search_tool = StructuredTool.from_function(
func=search,
name="search",
description="搜索工具",
handle_tool_error=True
)
# 调用search_tool的invoke方法来执行搜索工具, 传递一个包含查询参数的字典
resp = search_tool.invoke({"query": "腾讯的股价多少"})
# 打印搜索工具的响应结果
print(resp)
```
* 方式二:配置响应 `handle_tool_error=”错误信息“`
```python
from langchain_core.tools import tool, ToolException, StructuredTool
def search(query: str) -> str:
"""
执行搜索查询
"""
# 引发一个ToolException来模拟搜索结果为空的情况
raise ToolException(f"相关搜索结果为空:{query}")
# 使用StructuredTool从函数创建一个工具实例
# handle_tool_error参数设置为True,表示工具将处理内部异常
search_tool = StructuredTool.from_function(
func=search,
name="search",
description="搜索工具",
handle_tool_error="搜索结果失败,请重试"
)
# 调用search_tool的invoke方法来执行搜索工具,传递一个包含查询参数的字典
resp = search_tool.invoke({"query": "腾讯的股价多少"})
# 打印搜索工具的响应结果
print(resp)
```
* 方式三:配置自定义处理函数-兜底降级
```python
from langchain_core.tools import tool, ToolException, StructuredTool
def search(query: str) -> str:
"""
执行搜索查询
"""
# 引发一个ToolException来模拟搜索结果为空的情况
raise ToolException(f"相关搜索结果为空:{query}")
#自定义异常处理函数
def _handle_tool_error(error: ToolException) -> str:
"""
自定义异常处理函数
"""
return f"搜索结果失败,自定义异常,请重试:{error}"
# 使用StructuredTool从函数创建一个工具实例
# handle_tool_error参数设置为True,表示工具将处理内部异常
search_tool = StructuredTool.from_function(
func=search,
name="search",
description="搜索工具",
handle_tool_error=_handle_tool_error
)
# 调用search_tool的invoke方法来执行搜索工具,传递一个包含查询参数的字典
resp = search_tool.invoke({"query": "腾讯的股价多少"})
# 打印搜索工具的响应结果
print(resp)
```
#### 插上翅膀-LLM增加联网搜索功能实
* 需求说明
* 实现了一个结合大语言模型(LLM)和工具调用的智能问答系统。
* 用户可以通过自然语言输入问题,系统会根据问题内容判断是否需要调用外部工具(如搜索引擎或计算工具),返回最终答案。
* 交互流程图
* 编写代码
```python
# 导入操作系统接口模块,用于与环境变量交互
import os
# 从langchain_community.utilities模块中导入SearchApiAPIWrapper类,用于封装搜索API
from langchain_community.utilities import SearchApiAPIWrapper
# 设置环境变量SEARCHAPI_API_KEY,用于认证搜索API的密钥
os.environ["SEARCHAPI_API_KEY"] = "qQBHMQo4Rk8SihmpJjCs7fML"
# 实例化SearchApiAPIWrapper对象,用于调用搜索API
search = SearchApiAPIWrapper()
# 调用run方法执行搜索操作,参数为查询腾讯股价的中文字符串
result = search.run("今天腾讯的股价是多少")
# 输出搜索结果
print(result)
```
* 拓展
* SearchApi 包装器可以自定义为使用不同的引擎,如 Google News、Google Jobs、Google Scholar
* 其他可以在 SearchApi 文档中找到的引擎。执行查询时可以传递 SearchApi 支持的所有参数。
```
search = SearchApiAPIWrapper(engine="google_jobs")
```
* 获取元数据
```python
result_meta = search.results("今天腾讯的股价是多少")
print(result_meta)
```
#### 兜底降级-LangChain调用工具Tool异常处理
* 需求背景
* 智能体(Agent)在调用外部工具(如 API、数据库、搜索引擎)时,会遇到各种不可预知的错误
* 例如:
- 网络请求失败(如 API 无响应)
- 权限不足(如访问密钥失效)
- 输入参数不合法(如格式错误)
- 资源限制(如 API 调用次数超限)
* 如果智能体不处理这些错误,会导致:
* **程序崩溃**:直接抛出未捕获的异常。
* **用户困惑**:返回难以理解的错误堆栈信息。
* **无法恢复**:智能体无法根据错误调整策略(如重试或切换工具)
* 解决方案 `ToolException`:
* 通过 ToolException 统一捕获和处理工具调用中的错误,使智能体具备容错能力和用户友好的错误反馈
* ToolException 的核心作用
* 统一错误格式:将不同工具的异常转换为标准格式,方便智能体解析。
* 错误上下文传递:保留错误原因、工具名称等关键信息。
* 使用场景举例
* **API 调用失败**:如天气查询接口超时。
* **权限校验失败**:如访问数据库的密钥过期。
* **输入参数校验**:如用户输入的城市名不存在。
* **资源限制**:如每日调用次数用尽。
* 案例实战
* 方式一:配置响应 `handle_tool_error=True` 默认是false
```python
from langchain_core.tools import tool, ToolException, StructuredTool
def search(query: str) -> str:
"""
执行搜索查询
"""
# 引发一个ToolException来模拟搜索结果为空的情况
raise ToolException(f"相关搜索结果为空:{query}")
# 使用StructuredTool从函数创建一个工具实例
# handle_tool_error参数设置为True,表示工具将处理内部异常
search_tool = StructuredTool.from_function(
func=search,
name="search",
description="搜索工具",
handle_tool_error=True
)
# 调用search_tool的invoke方法来执行搜索工具, 传递一个包含查询参数的字典
resp = search_tool.invoke({"query": "腾讯的股价多少"})
# 打印搜索工具的响应结果
print(resp)
```
* 方式二:配置响应 `handle_tool_error=”错误信息“`
```python
from langchain_core.tools import tool, ToolException, StructuredTool
def search(query: str) -> str:
"""
执行搜索查询
"""
# 引发一个ToolException来模拟搜索结果为空的情况
raise ToolException(f"相关搜索结果为空:{query}")
# 使用StructuredTool从函数创建一个工具实例
# handle_tool_error参数设置为True,表示工具将处理内部异常
search_tool = StructuredTool.from_function(
func=search,
name="search",
description="搜索工具",
handle_tool_error="搜索结果失败,请重试"
)
# 调用search_tool的invoke方法来执行搜索工具,传递一个包含查询参数的字典
resp = search_tool.invoke({"query": "腾讯的股价多少"})
# 打印搜索工具的响应结果
print(resp)
```
* 方式三:配置自定义处理函数-兜底降级
```python
from langchain_core.tools import tool, ToolException, StructuredTool
def search(query: str) -> str:
"""
执行搜索查询
"""
# 引发一个ToolException来模拟搜索结果为空的情况
raise ToolException(f"相关搜索结果为空:{query}")
#自定义异常处理函数
def _handle_tool_error(error: ToolException) -> str:
"""
自定义异常处理函数
"""
return f"搜索结果失败,自定义异常,请重试:{error}"
# 使用StructuredTool从函数创建一个工具实例
# handle_tool_error参数设置为True,表示工具将处理内部异常
search_tool = StructuredTool.from_function(
func=search,
name="search",
description="搜索工具",
handle_tool_error=_handle_tool_error
)
# 调用search_tool的invoke方法来执行搜索工具,传递一个包含查询参数的字典
resp = search_tool.invoke({"query": "腾讯的股价多少"})
# 打印搜索工具的响应结果
print(resp)
```
#### 插上翅膀-LLM增加联网搜索功能实
* 需求说明
* 实现了一个结合大语言模型(LLM)和工具调用的智能问答系统。
* 用户可以通过自然语言输入问题,系统会根据问题内容判断是否需要调用外部工具(如搜索引擎或计算工具),返回最终答案。
* 交互流程图
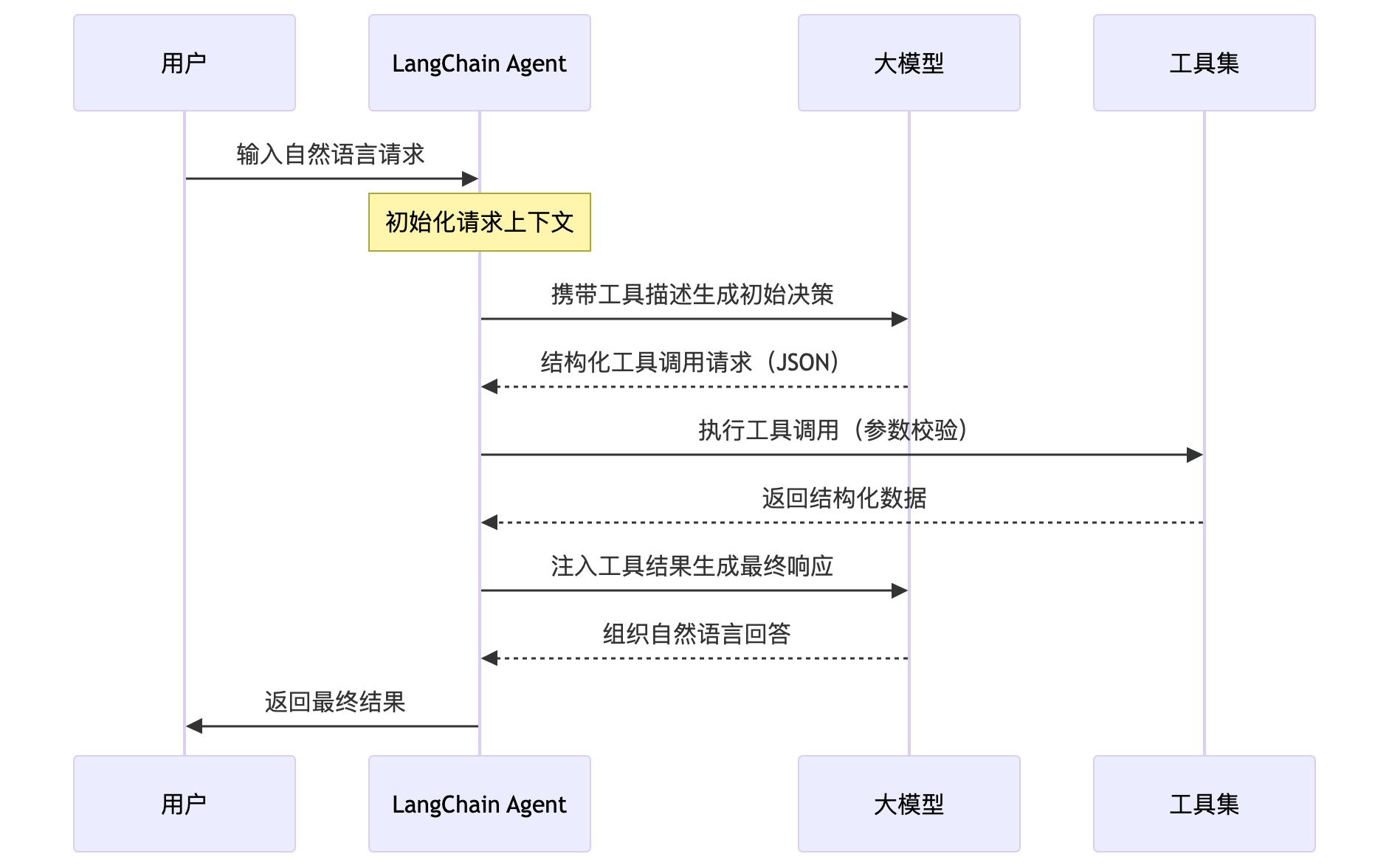 * 步骤思路
* 配置SearchAPI的API密钥,
* 实例化`SearchApiAPIWrapper`对象,用于调用搜索API。
* 定义多个工具函数,供系统在回答问题时调用。
- **web_search**: 用于搜索实时信息、最新事件或未知领域知识。
- 输入参数:`query`(字符串类型,搜索关键词)。
- 返回值:搜索结果的标题和摘要。
- **multiply**: 用于计算两个整数的乘积。
- 输入参数:`a`和`b`(均为整数类型)。
- 返回值:两数相乘的结果。
* 初始化大语言模型(LLM),并将其与工具绑定,形成一个智能问答Agent。
- **关键点**
- 使用`ChatOpenAI`类初始化LLM,指定模型名称、API密钥、温度等参数。
- 创建聊天提示模板(`ChatPromptTemplate`),定义系统角色和用户输入格式。
- 将工具列表与LLM绑定,具备工具调用能力的Agent。
* 构建运行链(`chain`),将用户输入传递给提示模板和Agent,生成响应。
- **关键点**
- 用户输入通过`RunnablePassthrough`传递到提示模板。
- 提示模板生成的消息进一步传递给Agent处理。
* 根据据LLM生成的响应,判断是否要调用工具。如果需要调用工具并将结果合并到历史消息中,重新传递给LLM生成最终答案。
- **关键点**
- 通过`resp.tool_calls`判断是否需要调用工具。
- 调用工具后,将结果以`ToolMessage`形式添加到历史消息中。
- 最终结果由LLM根据更新的历史消息生成。
* 案例代码实战
```python
# 基于LangChain 0.3.x的SearchApi工具实战(需安装依赖)
# pip install langchain-core langchain-openai langchain-community
from langchain_community.utilities import SearchApiAPIWrapper
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langchain_core.messages import ToolMessage
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
import os
from langchain_core.tools import tool
from pydantic import Field
# ======================
# 第一步:配置搜索工具
# ======================
# 注册SearchAPI获取密钥:https://www.searchapi.io/
# 设置SearchAPI的API密钥
os.environ["SEARCHAPI_API_KEY"] = "qQBHMQo4Rk8SihmpJjCs7fML"
# 实例化SearchApiAPIWrapper对象,用于调用搜索API
search = SearchApiAPIWrapper()
# ======================
# 第二步:定义搜索工具
# ======================
@tool("web_search", return_direct=True)
def web_search(query: str) -> str:
"""
当需要获取实时信息、最新事件或未知领域知识时使用,输入应为搜索关键词
"""
try:
results = search.results(query) # 获取前3条结果
return "\n\n".join([
f"来源:{res['title']}\n内容:{res['snippet']}"
for res in results['organic_results']
])
except Exception as e:
return f"搜索失败:{str(e)}"
@tool("multiply")
def multiply(a: int, b: int) -> int:
"""
把传递的两个参数相乘
"""
return a * b
# ======================
# 第三步:绑定LLM创建Agent
# ======================
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 创建聊天提示模板
prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个AI助手,名称叫老王,请根据用户输入的查询问题,必要时可以调用工具帮用户解答"),
("human", "{query}"),
]
)
# 定义工具字典
tool_dict = {
"web_search": web_search,
"multiply": multiply
}
# 从字典中提取工具列表
tools = [ tool_dict[tool_name] for tool_name in tool_dict ]
# 绑定工具到大模型
llm_with_tools = llm.bind_tools(tools=tools)
# 创建运行链
chain = {"query":RunnablePassthrough()} | prompt | llm_with_tools
# 定义查询
query = "你是谁?"
# 执行链并获取响应
resp = chain.invoke({"query":query})
print(resp)
#判断是否需要调用工具 content=''不一定需要调用,根据tool_calls进行判断
```
* 编码实战
```python
#判断是否需要调用工具 content=''不一定需要调用,根据tool_calls进行判断
# ======================
# 第四步:获取工具调用
# ======================
tool_calls = resp.tool_calls
if len(tool_calls) <= 0:
print(f"不需要调用工具:{resp.content}")
else:
#将历史消息合并,包括用户输入和AI输出
history_messages = prompt.invoke(query).to_messages()
history_messages.append(resp)
print(f"历史消息:{history_messages}")
#循环调用工具
for tool_call in tool_calls:
tool_name = tool_call.get("name")
tool_args = tool_call.get("args")
tool_resp = tool_dict[tool_name].invoke(tool_args)
print(f"一次调用工具:{tool_name},参数:{tool_args},结果:{tool_resp}")
#将工具调用结果添加到历史消息中
history_messages.append(
ToolMessage(
tool_call_id=tool_call.get("id"),
name=tool_name,
content=tool_resp
)
)
print(f"历史消息:{history_messages}")
resp = llm_with_tools.invoke(history_messages)
print(f"最终结果:{resp}")
print(f"调用工具后的结果:{resp.content}")
```
* 案例测试实战
```
#query = "9*3是多少"
#query = "今天是腾讯股价是多少"
```
* 扩展功能建议
- **多语言支持**:增加对多种语言的输入和输出支持。
- **更多工具集成**:集成更多类型的工具,如翻译工具、图像识别工具等。
- **用户反馈机制**:允许用户对系统生成的答案进行评价,优化模型性能。
### 大模型链路调试平台之LangSmith实战
#### 大模型LLM调用链路分析和LangSmith介绍
* 需求背景
* 开发基于大语言模型(LLM)的智能体时,会遇到以下问题:
* 调试困难
* LLM 的输出不可预测,难以追踪中间步骤(如思维链、工具调用)。
* 错误定位耗时(如工具返回异常,但不知道具体哪一步出错)。
* 测试复杂
* 需要验证不同输入场景下的输出稳定性。
* 手动测试效率低,缺乏自动化验证。
* 监控缺失
* 生产环境中的智能体行为难以追踪(如 API 调用延迟、错误率)。
* 无法分析用户高频问题或模型性能瓶颈。
* **LangSmith 是什么**
* **LangChain官方出品**的LLM应用开发调试与监控平台
* 地址:https://smith.langchain.com/
* 解决大模型应用开发中的**调试困难**、**效果追踪**、**生产监控**三大痛点
* 类似:Java中的Spring Boot Actuator(监控)、ELK Stack(日志分析)
* 核心功能说明
* 调试与追踪
- 记录智能体完整执行链路(LLM 调用、工具调用、中间结果)。
- 可视化展示每一步的输入输出和耗时。
- 统计成功率、延迟等关键指标。
* 生产监控
- 实时监控 API 调用异常(如超时、错误响应)。
- 分析用户高频请求和模型性能趋势
* 功能矩阵
| 功能模块 | 作用描述 | 典型应用场景 |
| :----------: | :---------------------------------------: | :---------------------: |
| 运行追踪 | 记录LLM调用链的完整执行过程 | 调试复杂Chain/Agent逻辑 |
| 提示工程分析 | 对比不同Prompt模板的实际效果 | 优化系统提示词 |
| 版本对比 | 比对不同模型版本或参数的表现 | 模型升级效果验证 |
| 生产监控 | 实时监控API调用指标(延迟、成本、错误率) | 服务健康状态跟踪 |
| 团队协作 | 共享调试结果和监控仪表盘 | 多人协作开发LLM应用 |
* LangSmith 系统架构
* SDK捕获所有LLM相关操作
* 加密传输到LangSmith服务端
* 数据存储与索引
* 可视化界面动态查询
```
[Your Application]
│
▼
[LangChain SDK] → [LangSmith API]
│ │
▼ ▼
[LLM Providers] [Trace Storage]
│ │
▼ ▼
[External Tools] [Analytics Engine]
```
* 相关环境实战
* 注册地址:https://smith.langchain.com/
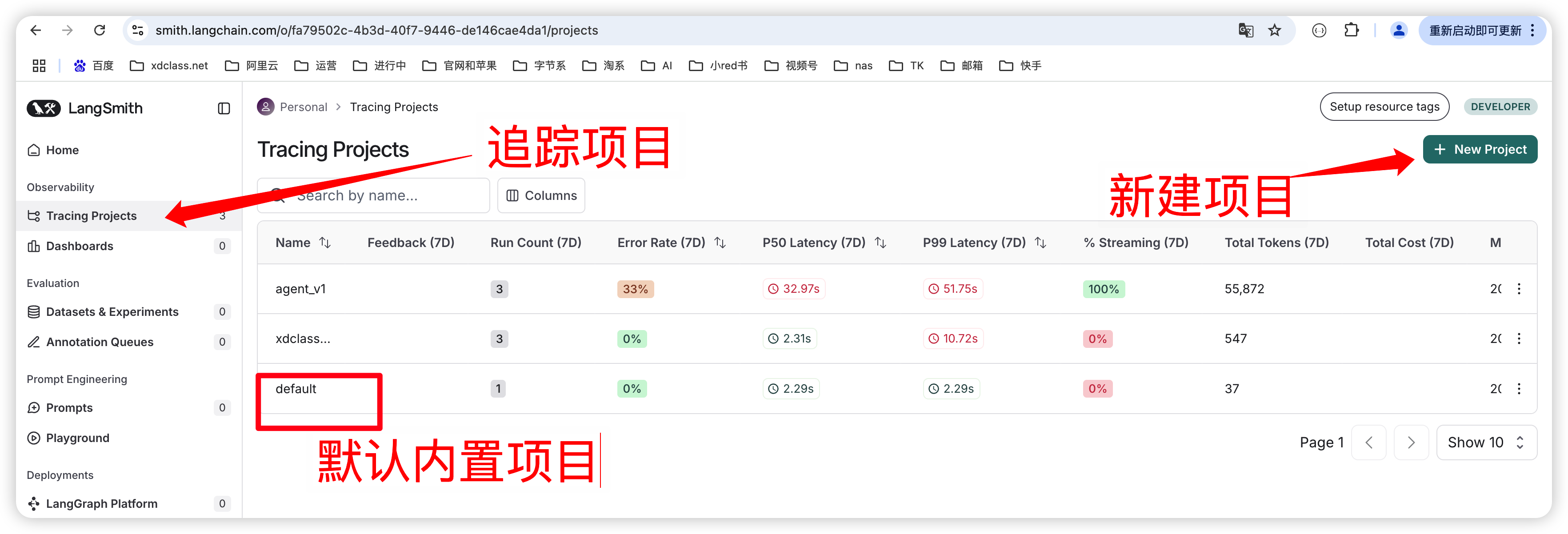
* 配置项目前准备
* 项目安装依赖
```
pip install langsmith==0.3.19
```
* 生成密钥,记得保存
* 配置项目名称(不存在的话会自动新建)
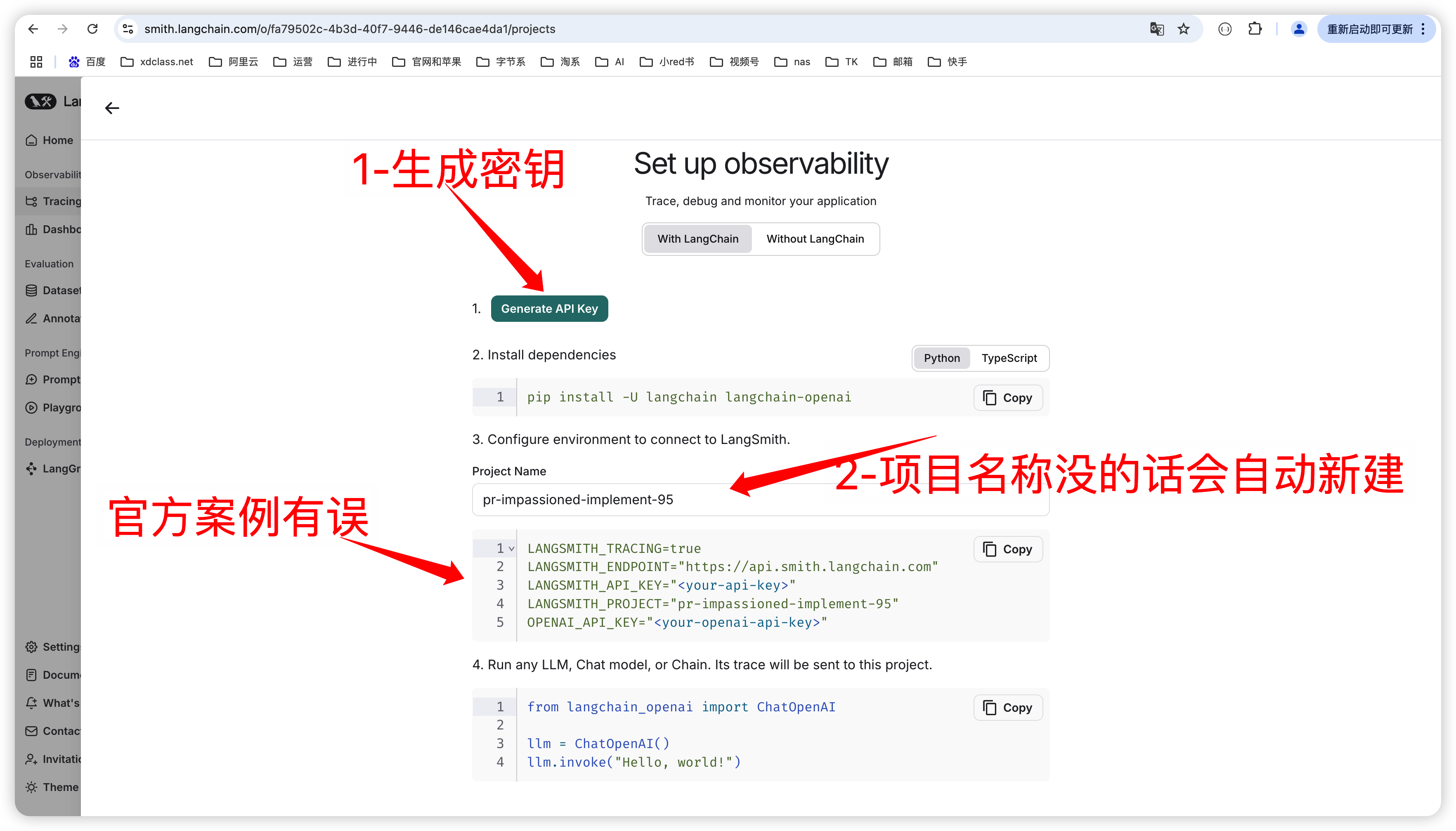
#### 大模型调用接入LangSmith分析实战
**简介: 大模型调用接入LangSmith分析实战**
* LangChain接入调用链路分析实战
* 项目配置
```
#示例配置
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "ls_xxxxx" # 替换为实际Key
os.environ["LANGCHAIN_PROJECT"] = "My_Project" # 自定义项目名
os.environ["LANGSMITH_ENDPOINT"] = "https://api.smith.langchain.com" #后端接口路径
```
```python
#真正配置
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "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"
os.environ["LANGSMITH_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGSMITH_PROJECT"] = "agent_v1"
```
* 如果需要本地私有化部署 langfuse
* 案例实战分析
* 单独案例测试
```python
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "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"
os.environ["LANGSMITH_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGSMITH_PROJECT"] = "xdclass_test_v1"
from langchain_openai import ChatOpenAI
import logging
logging.basicConfig(level=logging.DEBUG)
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
resp = llm.invoke("什么是智能体")
print(resp.content)
```
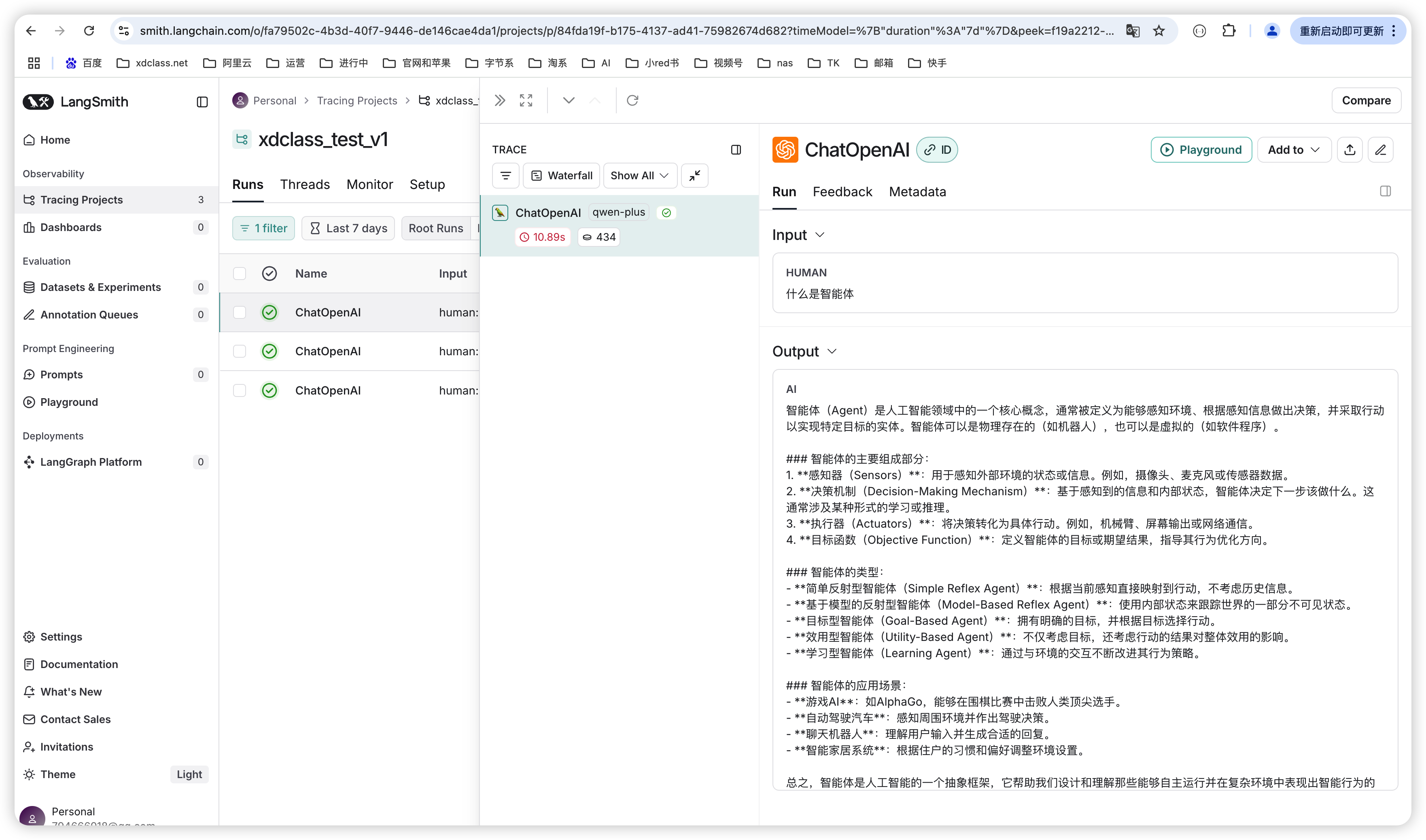
* 进阶案例测试【选择之前的案例代码-43.2】
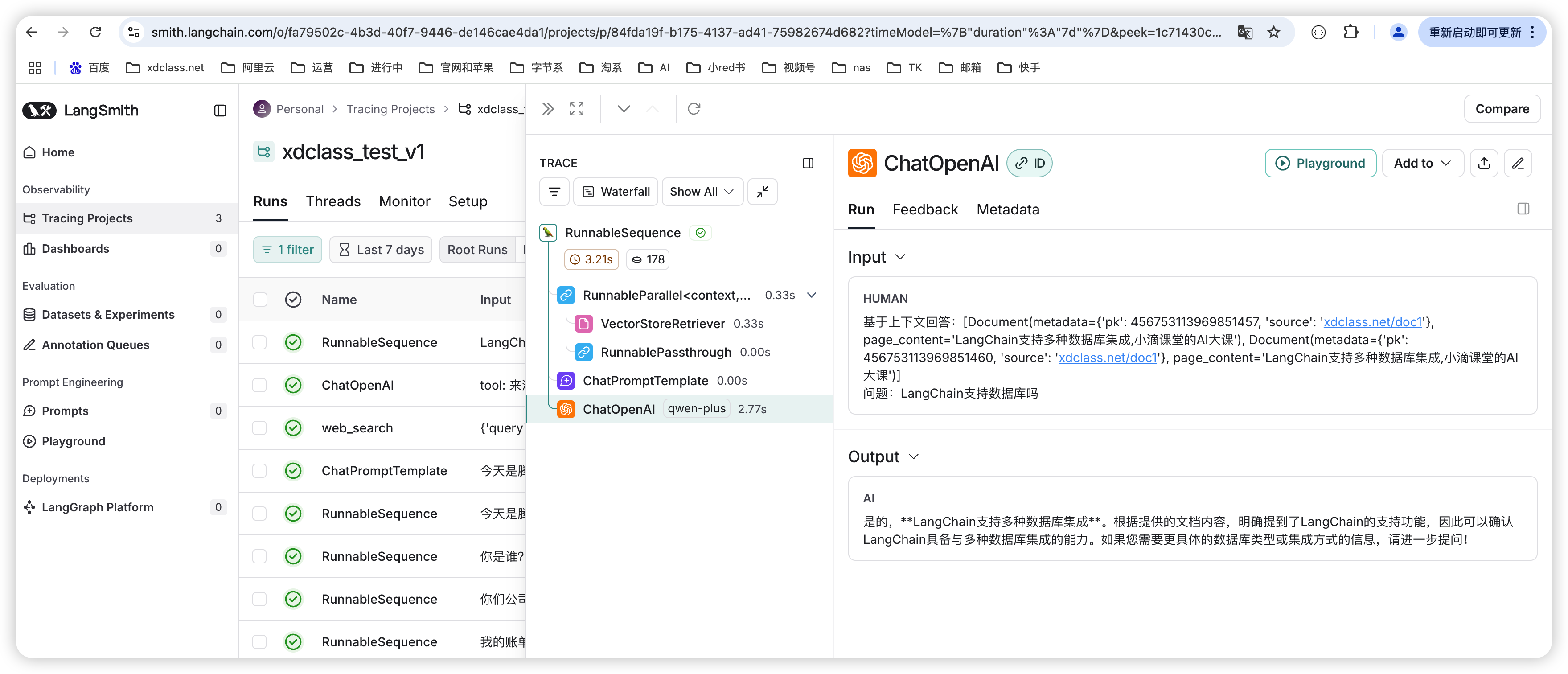
### 模型Agent智能体进阶开发实战
#### 大模型智能体之CoT思维链和ReAct推理行动
* 需求背景:为什么需要CoT/ReAct?
* 问题场景:传统大模型直接输出结果,但复杂任务(数学推理/多步骤决策)易出错
* 核心需求:让模型展示思考过程 + 动态调整策略
* 类比理解:
* 普通模型 → 考试直接写答案
* CoT → 在试卷上写解题步骤
* ReAct → 边查公式手册边解题
* 什么是CoT(思维链,Chain of Thought)
* **核心机制**:通过显式生成推理步骤得出最终答案
```python
"""
问题:...[输入问题]...
思考步骤:
1. 第一步分析(如提取关键数据)
2. 第二步计算(如公式应用)
3. ...(更多步骤)
最终答案:...[结论]...
"""
比如问题:A超市苹果每斤5元,买3斤送1斤;B超市同品质苹果每斤6元但买二送一。买8斤哪家更划算?
CoT推理:
1. A超市实际获得:3+1=4斤,花费3×5=15元 → 单价15/4=3.75元/斤
2. 买8斤需要购买两次活动:4×2=8斤 → 总价15×2=30元
3. B超市每3斤花费6×2=12元 → 单价12/3=4元/斤
4. 买8斤需购买3次活动(3×3=9斤)花费12×3=36元 → 实际单价36/9=4元/斤
5. 结论:A超市更优惠
```
* 是一种促使大语言模型产生一系列中间推理步骤,进而得出最终答案的技术。
* 以往的大模型通常直接给出问题的答案,而 CoT 鼓励模型展示其思考过程,就像人类在解决复杂问题时逐步推导一样。
* 这种方法能增强模型在处理复杂推理任务时的性能,尤其是涉及算术、常识推理和符号操作的任务。
* 局限性
* **依赖模型知识**:若模型内部知识错误,推理链条也可能错误(如“太阳绕地球转”)。
* **不适用于动态信息**:无法处理需要实时数据的问题(如“今天天气如何”)。
* **步骤冗余**:简单问题可能因分步反而降低效率。
* 案例说明:算术问题
* 问题:小明有 5 个苹果,小红给他 3 个,然后他吃了 2 个,还剩下多少个苹果?
* 无 CoT 回答:“6 个”。
* CoT 回答:
* 首先,小明原本有 5 个苹果,小红又给了他 3 个,那么此时他拥有的苹果数为 5 + 3 = 8 个。
* 接着,他吃了 2 个苹果,所以剩下的苹果数是 8 - 2 = 6 个。
* 因此,小明最后还剩下 6 个苹果。
* 应用场景
* 教育领域
* 用于辅导学生学习数学、科学等学科的推理问题。
* 通过展示推理过程,学生能更好地理解解题思路,提高学习效果。
* 智能客服
* 在回答客户复杂问题时,展示推理过程能让客户更清楚解决方案的由来,增强客户对服务的信任。
* 什么是ReAct(推理与行动,Reasoning and Acting)
* **交互逻辑**:循环执行"思考-行动-观察"步骤
```python
"""
问题:...[输入问题]...
思考:当前需要解决的问题是...
行动:调用__工具名称__(参数)
观察:工具返回结果...
思考:根据结果分析...
(循环直至得出结论)
答案:...[最终结果]...
"""
比如问题:2027年诺贝尔文学奖得主的代表作是什么?
ReAct流程:
[思考] 需要先确定最新获奖者 → 调用搜索工具
[行动] 使用DuckDuckGo搜索"2027诺贝尔文学奖获得者"
[观察] 结果显示:法国作家安妮·艾诺
[思考] 需要确认其代表作品 → 调用维基百科工具
[行动] 查询维基百科"安妮·艾诺"
[观察] 主要作品:《悠悠岁月》《位置》等
[结论] 代表作是《悠悠岁月》
```
* ReAct 是一种让大模型结合推理和行动的范式,不是前端框架React
* 模型不仅要进行推理,还能根据推理结果调用外部工具(如搜索引擎、数据库等)来获取额外信息,从而更有效地解决问题。
* 它使模型能够与外部环境交互,拓展了模型的能力边界。
* ReAct的优势
* 减少幻觉:通过实时调用外部工具验证信息,降低模型编造错误答案的概率。
* 处理复杂任务:适合多步骤问题(如数学计算、事实核查),传统单次生成容易出错。
* 透明可解释:模型的推理过程以自然语言呈现,便于人类理解其决策逻辑。
* 案例说明:
* 问题:2027 年 NBA 总冠军是哪个队伍?
* 无 ReAct 处理:由于模型训练数据可能存在时效性问题,可能无法给出准确答案或给出过时的信息。
* ReAct 处理:
* 推理:模型意识到自己可能没有最新的 2026 年 NBA 总冠军信息,需要调用外部资源获取。
* 行动:调用体育新闻网站的 API 或搜索引擎查询相关信息。
* 结果:获取到最新信息后,给出准确回答,如 “2026年 NBA 总冠军是 [具体队伍名称]。
* 应用场景
* 知识问答系统
* 处理需要实时信息或特定领域最新数据的问题,如财经数据、体育赛事结果、科技动态等。
* 任务自动化
* 在自动化流程中,根据任务需求调用不同的工具和服务,如预订机票、查询物流信息、控制智能家居设备等。
* 技术框架对比
| 维度 | CoT | ReAct |
| :---------------: | :-------------------------------: | :---------------------------------: |
| **核心组件** | 纯提示工程,依赖模型知识 | 代理(Agent)+ 工具调用 |
| **数据依赖** | 仅依赖内部知识 | 可接入外部数据源/API |
| **错误修复** | 单次推理完成 | 可通过多次行动修正结果 |
| **适用场景** | 理论推导/数学计算 | 实时信息查询/复杂任务分解 |
| **计算开销** | 低 | 中高(涉及外部调用) |
| **LangChain组件** | `ChatPromptTemplate` + `LLMChain` | `Agent` + `Tools` + `AgentExecutor` |
| **优势** | 简单、透明 | 实时交互,扩展性强 |
| **缺点** | 无法获取最新信息 | 依赖工具API的稳定性 |
* 应用场景指南
| 场景类型 | 推荐方法 | 原因说明 |
| :--------------: | :------: | :------------------------: |
| 数学/逻辑推理 | CoT | 无需外部数据,单步推理高效 |
| 实时数据获取 | ReAct | 需要调用搜索/API工具 |
| 多步骤决策任务 | ReAct | 支持动态调整执行路径 |
| 知识密集型问答 | CoT | 依赖模型内部知识库 |
| 复杂问题分解执行 | 混合架构 | 兼顾推理与执行效率 |
* **开发建议**:
* **方法选择原则**:
- 纯推理 → CoT
- 需实时数据 → ReAct
* **提示工程技巧**:
- CoT需明确定义步骤格式
- ReAct要严格规范行动命名(如`调用API名称_参数`)
* **常见陷阱**:
- CoT可能产生错误中间步骤
- ReAct需处理API调用失败情况
* 通过`verbose=True`参数观察两种方法的执行过程差异
* LangChain框架的模块化设计,可以灵活组合这两种技术,适应不同场景需求
#### 大模型的Zero-Shot和Few-Shot案例实战
**简介: 大模型的Zero-Shot和Few-Shot案例讲解**
* **零样本(Zero-Shot)学习**
* 模型在**没有特定任务训练数据**的情况下,直接通过预训练知识和自然语言理解能力完成任务。
* 例如,直接要求模型生成从未见过的任务结果(如翻译、分类)。
* **核心原理**:依赖大模型在预训练阶段学习到的通用知识泛化能力
* 示例
- 用户输入:“将这句话翻译成中文:Hello, how are you?”
- 模型输出:“你好”
* **少量样本(Few-Shot)学习【照猫画虎】**
- 模型通过**少量示例(通常3-5个)** 快速理解任务格式和需求,提升任务表现。
- 例如,提供几个问答示例后,模型能模仿格式回答新问题。
- **核心原理**:通过示例激发模型的上下文学习(In-Context Learning)能力,提升输出准确性和一致性。
- 示例
```
输入:“苹果 -> 水果”,输出:“香蕉 -> 水果”
输入:“汽车 -> 交通工具”,输出:“飞机 -> 交通工具”
输入:“猫 ->”,输出:“动物”
```
* 应用场景对比
| **场景** | **零样本(Zero-Shot)** | **少量样本(Few-Shot)** |
| :----------------: | :------------------------: | :------------------------------------------: |
| **适用任务复杂度** | 简单任务(如翻译、分类) | 复杂任务(如逻辑推理、特定格式生成) |
| **数据依赖** | 无需示例 | 需要少量高质量示例 |
| **输出可控性** | 较低(依赖模型预训练知识) | 较高(通过示例明确格式和规则) |
| **典型用例** | 快速原型开发、通用问答 | 领域特定任务(如法律文档解析、医疗术语抽取) |
* 案例实战
* 零样本学习案例:直接通过指令调用大模型生成答案
```python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# 零样本提示模板
zero_shot_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业翻译,将文本从{source_lang}翻译到{target_lang}"),
("human", "{text}")
])
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 链式调用
chain = zero_shot_prompt | llm
# 执行翻译(中文→英文)
response = chain.invoke({
"source_lang": "中文",
"target_lang": "英文",
"text": "今天天气不错,我要学习AI大模型开发"
})
print(response.content)
```
* 少量样本学习案例: 通过示例指导模型理解任务格式
```python
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
from langchain_openai import ChatOpenAI
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 示例数据
examples = [
{
"input": "苹果公司的总部在哪里?",
"output": "根据我的大量思考:苹果公司的总部位于美国加利福尼亚州的库比蒂诺(Cupertino)。"
},
{
"input": "OpenAI的CEO是谁?",
"output": "根据我的大量思考:OpenAI的现任CEO是萨姆·阿尔特曼(Sam Altman)。"
}
]
# 定义单条示例模板
example_template = """
输入:{input}
输出:{output}
"""
example_prompt = PromptTemplate(
template=example_template
input_variables=["input", "output"],
)
# 构建Few-Shot提示模板
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="输入:{question}\n输出:",
input_variables=["question"]
)
# 创建Chain并调用
few_shot_chain = few_shot_prompt | llm
response = few_shot_chain.invoke({"question": "亚马逊的创始人是谁?"})
print(response.content) # 输出:根据我的大量思考:亚马逊的创始人是杰夫·贝索斯(Jeff Bezos)。
```
* 总结
* **零样本 vs 少量样本**:
- 零样本依赖模型预训练知识,适合通用任务。
- 少量样本通过示例提升任务适配性,适合专业场景。
* **LangChain 实现要点**:
- **零样本**:使用 `AgentType.ZERO_SHOT_REACT_DESCRIPTION` 初始化智能体。
- **少量样本**:通过 `PromptTemplate` 设计含示例的提示词。
* **设计原则**:
- **清晰指令**:明确任务目标和输出格式。
- **示例质量**:少量样本的示例需覆盖典型场景。
#### LangChain智能体执行引擎AgentExecutor
* 需求背景:为什么需要 AgentExecutor?
* 问题:当智能体(Agent)需要执行多步操作(如多次调用工具、循环推理)时,开发者需手动处理:
* 执行循环:根据模型输出决定是否继续调用工具。
* 错误处理:捕获工具调用或模型解析中的异常。
* 流程控制:限制最大迭代次数,防止无限循环。
* 日志记录:追踪每一步的输入、输出和中间状态。
* 痛点:
* 代码冗余:重复编写循环和错误处理逻辑。
* 维护成本高:复杂任务中难以保证流程稳定性。
* 可观测性差:难以调试多步骤执行过程。
* `AgentExecutor` 介绍
* LangChain 提供的智能体执行引擎,封装了执行循环、错误处理和日志追踪,让开发者聚焦业务逻辑。
* 核心功能
| **功能** | **说明** |
| :--------------: | :----------------------------------------------------------: |
| **执行循环控制** | 自动迭代执行智能体的 `思考 -> 行动 -> 观察` 流程,直到满足终止条件。 |
| **错误处理** | 捕获工具调用异常、模型解析错误,支持自定义重试或回退逻辑。 |
| **迭代限制** | 通过 `max_iterations` 防止无限循环(如模型陷入死循环)。 |
| **日志与追踪** | 记录每一步的详细执行过程(需设置 `verbose=True`),支持集成 LangSmith。 |
| **输入输出处理** | 统一格式化最终结果,隐藏中间步骤细节(除非显式要求输出)。 |
* 关键参数
| **参数** | **作用** |
| :-------------------------: | :----------------------------------------------------------: |
| `agent` | 绑定的智能体实例(如 `create_react_agent` 的返回值)。 |
| `tools` | 智能体可调用的工具列表。 |
| `verbose` | 是否打印详细执行日志(调试时建议开启)。 |
| `max_iterations` | 最大迭代次数,防止死循环。 |
| `handle_parsing_errors` | 自动处理模型输出解析错误(如返回无效工具名),可设置为 `True` 或自定义函数。 |
| `return_intermediate_steps` | 是否返回中间步骤结果(用于调试或展示完整链路)。 |
* 使用场景:何时需要 `AgentExecutor`
* **多步骤任务**:
- 例如:先调用搜索工具获取数据,再调用计算工具处理结果
```python
# 示例:计算商品折扣价
"思考:需要先获取商品价格,再计算折扣。"
"行动1:调用 get_price(商品A)"
"观察1:价格=100元"
"行动2:调用 calculate_discount(100, 20%)"
"观察2:折扣价=80元"
```
* **工具依赖场景**:
- 例如:预订航班需要先查询航班号,再调用支付接口。
* **复杂推理任务**:
- 例如:解决数学问题需多次尝试不同公式。
* **生产环境部署**:
- 需保证服务稳定性(自动处理超时、限流等异常)
* 伪代码参考
```python
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
max_iterations=3,
handle_parsing_errors=True
)
# 执行查询(自动处理循环和错误)
response = agent_executor.invoke({"input": "北京的气温是多少华氏度?"})
print(response["output"]) # 输出:25℃ = 77℉
```
#### LangChain智能体之initialize_agent开发实战
* 需求背景
| 手工调用工具的问题 | `initialize_agent`解决方案 |
| :----------------------: | :--------------------------: |
| 需要手动编写工具选择逻辑 | 自动根据输入选择最合适的工具 |
| 缺乏错误重试机制 | 内置异常处理和重试策略 |
| 输出格式不统一 | 标准化响应格式 |
| 难以处理多工具协作场景 | 自动编排工具调用顺序 |
* 手动执行需要开发者自己处理任务分解、工具选择、参数生成、结果整合等步骤
* Agent利用大模型的推理能力自动完成这些步骤,提高了开发效率和系统的灵活性。
* 解决方案:
* langchain内置多个方法快速创建智能体,能减少手动编码的复杂性,提升系统的智能性和适应性。
* 包括自动化任务分解、动态工具选择、错误处理、结果整合等
* 主要包含以下核心方法:
* `initialize_agent`:通用初始化方法,快速构建智能体(兼容旧版)返回AgentExecutor。
* `create_react_agent`:基于 ReAct 框架的智能体,支持多步推理。
* `create_tool_calling_agent`:专为工具调用优化的智能体,支持结构化输出。
* 其他方法:如 `create_json_agent`(处理 JSON )、`create_openai_tools_agent`(适配 OpenAI 工具调用格式)
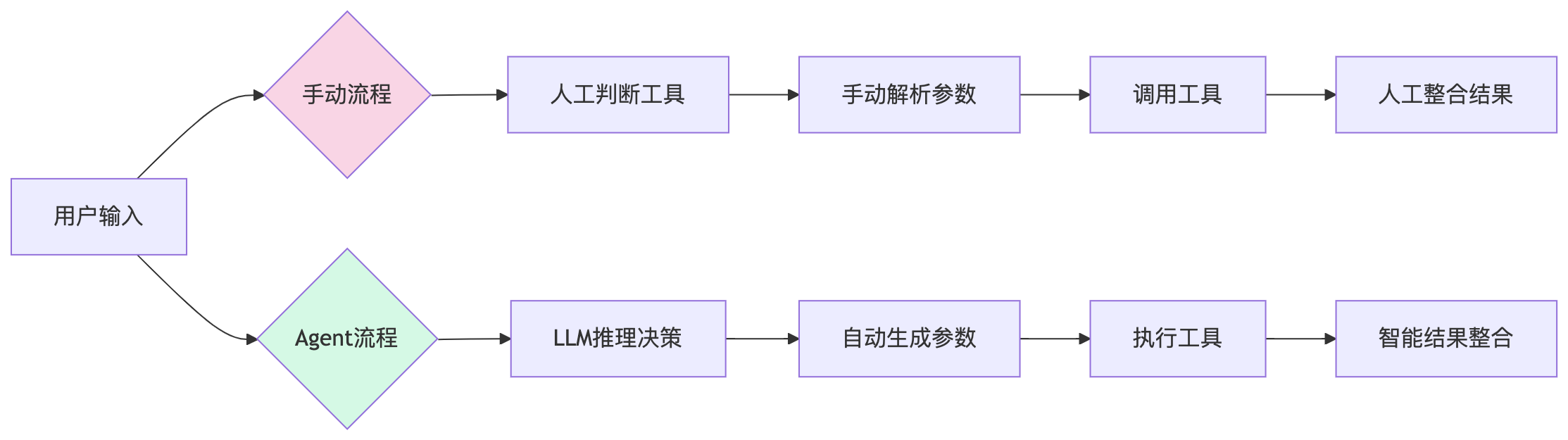
* `initialize_agent` 方法介绍
* 通过封装智能体的决策逻辑和工具调度,旧版方法,未来可能被弃用
* **适用场景**:快速原型开发、简单任务处理
* 实现
* 自动化工具选择:根据输入动态调用合适的工具。
* 流程标准化:统一处理错误、重试、结果格式化。
* 简化开发:一行代码完成智能体初始化。
* 语法与参数详解
```python
from langchain.agents import initialize_agent
def initialize_agent(
tools: Sequence[BaseTool], # 可用工具列表
llm: BaseLanguageModel, # 大模型实例
agent: Optional[AgentType] = None, # Agent类型
verbose: bool = False, # 是否显示详细过程
) -> AgentExecutor:
```
* **关键参数说明**:`agent_type`
| AgentType | 适用场景 | 特点 |
| :-----------------------------------------: | :------------------------------------: | :-----------------------: |
| ZERO_SHOT_REACT_DESCRIPTION | 通用任务处理 | 基于ReAct框架,零样本学习 |
| STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION | 结构化输入输出 | 支持复杂参数类型 |
| CONVERSATIONAL_REACT_DESCRIPTION | 多轮对话场景 | 保留对话历史上下文 |
| SELF_ASK_WITH_SEARCH | 结合自问自答和搜索工具,适合问答场景。 | 自动生成中间问题并验证 |
* 案例实战
```python
from langchain.agents import initialize_agent, AgentType
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langchain.agents import initialize_agent
from langchain_community.utilities import SearchApiAPIWrapper
import os
# 设置SearchAPI的API密钥
os.environ["SEARCHAPI_API_KEY"] = "qQBHMQo4Rk8SihmpJjCs7fML"
# 实例化SearchApiAPIWrapper对象,用于调用搜索API
search = SearchApiAPIWrapper()
#定义搜索工具
@tool("web_search", return_direct=True)
def web_search(query: str) -> str:
"""
当需要获取实时信息、最新事件或未知领域知识时使用,输入应为搜索关键词
"""
try:
results = search.results(query) # 获取前3条结果
return "\n\n".join([
f"来源:{res['title']}\n内容:{res['snippet']}"
for res in results['organic_results']
])
except Exception as e:
return f"搜索失败:{str(e)}"
# 使用 @tool 定义进行数学计算的工具
@tool("math_calculator", return_direct=True)
def math_calculator(expression: str) -> str:
"""用于进行数学计算,输入应该是一个有效的数学表达式,如 '2 + 3' 或 '5 * 4'"""
try:
result = eval(expression)
return str(result)
except Exception as e:
return f"计算出错: {str(e)}"
#不同大模型效果不一样,有些会报错,不支持多个输入参数的工具
@tool("multiply")
def multiply(a: int, b: int) -> int:
"""
把传递的两个参数相乘
"""
return a * b
# 创建工具列表
tools = [math_calculator,web_search]
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 使用 initialize_agent 创建代理
agent_chain = initialize_agent(
tools=tools, # 使用的工具列表
llm=llm, # 使用的语言模型
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, # 指定代理类型
verbose=True, # 打开详细日志,便于查看代理的思考过程
handle_parsing_errors=True #自动处理解析错误,提高Agent的稳定性。
)
#打印对应的智能体,更清晰底层逻辑
print(agent_chain.agent.llm_chain)
print(agent_chain.agent.llm_chain.prompt.template)
print(agent_chain.agent.llm_chain.prompt.input_variables)
# 测试代理
# 需求 1: 计算 5 乘以 6 的结果
result1 = agent_chain.invoke({"input":"计算 5 乘以 6 的结果"})
print("计算 5 乘以 6 的结果:", result1)
# 需求 2: 获取当前日期
#result2 = agent_chain.run("腾讯最新的股价")
#result2 = agent_chain.invoke({"input":"腾讯最新的股价"})
#print("腾讯最新的股价:", result2
```
#### 个人AI助理智能体之tool_calling_agent实战
* `create_tool_calling_agent `方法介绍
* 是 LangChain 0.3 新增的智能体创建方法, 要求模型直接返回工具调用参数(如 JSON 格式),减少中间解析错误。
* **结构化工具调用**:显式调用工具并传递结构化参数(支持复杂数据类型)
* **多步骤任务处理**:适合需要按顺序调用多个工具的场景
* **精准控制**:通过自定义 Prompt 模板指导 Agent 行为
* 方法参数
```python
from langchain.agents import create_tool_calling_agent
agent = create_tool_calling_agent(
llm: BaseLanguageModel, # 语言模型实例(需支持结构化输出)
tools: List[BaseTool], # 工具列表
prompt: ChatPromptTemplate # 提示模板(需明确工具调用规则)
)
```
| 参数 | 类型 | 必填 | 说明 |
| :----: | :----------------: | :--: | :----------------------------------------------------------: |
| llm | BaseLanguageModel | 是 | 支持工具调用的模型(如 `ChatOpenAI`) |
| tools | Sequence[BaseTool] | 是 | 工具列表,每个工具需用 `@tool` 装饰器定义 |
| prompt | ChatPromptTemplate | 是 | 控制 Agent 行为的提示模板,需包含 `tools` 和 `tool_names` 的占位符 |
* 适用场景
* API 集成:如调用天气查询、支付接口等需要严格参数格式的场景。
* 多工具协作:模型需根据输入动态选择多个工具并传递参数。
* 高精度任务:如金融计算、医疗诊断等容错率低的场景。
* 案例实战: 个人AI助理智能体
```python
from langchain_openai import ChatOpenAI
from langchain.agents import create_tool_calling_agent, Tool, AgentExecutor
from langchain.tools import tool
from datetime import datetime
from langchain_core.prompts import ChatPromptTemplate
# 定义获取当前日期的工具函数
@tool
def get_current_date() -> str:
"""获取当前日期"""
formatted_date = datetime.now().strftime("%Y-%m-%d")
return f"The current date is {formatted_date}"
# 定义搜索航班的工具函数
@tool
def search_flights(from_city: str, to_city: str, date: str) -> str:
"""根据城市和日期搜索可用航班"""
return f"找到航班:{from_city} -> {to_city},日期:{date},价格:¥1200"
# 定义预订航班的工具函数
@tool
def book_flight(flight_id: str, user: str) -> str:
"""预订指定航班"""
return f"用户 {user} 成功预订航班 {flight_id}"
# 定义获取股票价格的函数
def get_stock_price(symbol) -> str:
return f"The price of {symbol} is $100."
# 创建工具列表,包括获取股票价格、搜索航班、预订航班和获取当前日期的工具
tools = [
Tool(
name="get_stock_price",
func=get_stock_price,
description="获取指定的股票价格"
),
search_flights,
book_flight,
get_current_date
]
# 初始化大模型
llm = ChatOpenAI(
model_name="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 定义聊天提示模板
prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个AI助手,必要时可以调用工具回复问题"),
("human", "我叫老王,经常出差,身份证号是 4414231993210223213332"),
#("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
]
)
# 创建代理
agent = create_tool_calling_agent(llm, tools, prompt)
# 初始化代理执行器 , verbose=True可以看到思考明细, return_intermediate_steps返回中间结果
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True,return_intermediate_steps=True)
# 运行代理并获取结果
result = agent_executor.invoke({"input": "苹果股票是多少?根据我的行程,帮我查询下明天的航班,从广州去北京,并定机票"})
print(f"最终结果:{result}"
```
#### 旅游规划智能体之react_agent实战
* **ReAct 框架**:
* **Re**asoning + **Act**ing 是一种结合推理和行动的智能体设计模式
* 由以下步骤循环组成:
* **推理(Reason)**:分析当前状态,决定下一步行动(如调用工具或直接回答)。
* **行动(Act)**:执行选定的操作(如调用工具、查询数据)。
* **观察(Observe)**:获取行动结果,更新状态,进入下一轮循环。
```
[Thought] <-- 推理阶段(分析当前状况)
[Action] <-- 行动阶段(调用工具)
[Observation] <-- 环境反馈(工具返回结果)
```
* **`create_react_agent`**
* LangChain 提供的专用方法,用于创建基于 ReAct 框架的智能体
* 适合需要**多步动态决策**的任务(如复杂问答、数学问题求解)。
* 方法参数与语法
```python
from langchain.agents import create_react_agent
agent = create_react_agent(
llm: BaseLanguageModel, # 必须支持 ReAct 格式
tools: Sequence[BaseTool],# 工具集(需详细文档)
prompt: ChatPromptTemplate # 必须包含 ReAct 特殊标记
) -> Runnable
```
* 参考使用的提示模板结构
```python
# 官方推荐模板(从 hub 获取)
prompt = hub.pull("hwchase17/react")
# 模板核心内容示例:
"""
Answer the following questions using the following tools:
{tools}
Use the following format:
Question: the input question
Thought: 需要始终进行的思考过程
Action: 要执行的动作,必须是 [{tool_names}] 之一
Action Input: 动作的输入
Observation: 动作的结果
...(重复思考/行动循环)
Final Answer: 最终答案
"""
```
* 与其它方法的对比选型
| 场景特征 | 推荐方法 | 原因说明 |
| :--------------: | :-----------------------: | :--------------------: |
| 需要逐步推理 | create_react_agent | 显式思考链支持复杂逻辑 |
| **严格参数传递** | create_tool_calling_agent | 结构化输入更可靠 |
| 快速简单任务 | initialize_agent | 开箱即用最简配置 |
| 需要自我修正 | create_react_agent | 错误后可重新推理 |
| 与人类协作调试 | create_react_agent | 完整思考链易读性好 |
* 适用场景
* 多步骤任务:例如:“查询北京的气温,并计算对应的华氏度。”
* 动态工具选择:根据中间结果决定下一步调用哪个工具。
* 复杂推理任务:例如:“如果明天下雨,推荐室内活动;否则推荐户外活动。
* 案例实战:智能推荐助手
```python
from langchain_openai import ChatOpenAI
from langchain.tools import tool
from langchain_community.utilities import SearchApiAPIWrapper
import os
from langchain_core.prompts import PromptTemplate
from langchain.agents import create_react_agent, AgentExecutor
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气"""
# 模拟数据
weather_data = {
"北京": "晴,25℃",
"上海": "雨,20℃",
"广州": "多云,28℃"
}
return weather_data.get(city, "暂不支持该城市")
@tool
def recommend_activity(weather: str) -> str:
"""根据天气推荐活动"""
if "雨" in weather:
return "推荐室内活动:博物馆参观。"
elif "晴" in weather:
return "推荐户外活动:公园骑行。"
else:
return "推荐一般活动:城市观光。"
# 定义搜索工具
os.environ["SEARCHAPI_API_KEY"] = "qQBHMQo4Rk8SihmpJjCs7fML"
@tool("web_search", return_direct=True)
def web_search(query: str) -> str:
"""
当需要获取实时信息、最新事件或未知领域知识时使用,输入应为搜索关键词
"""
try:
search = SearchApiAPIWrapper()
results = search.results(query) # 获取前3条结果
return "\n\n".join([
f"来源:{res['title']}\n内容:{res['snippet']}"
for res in results['organic_results']
])
except Exception as e:
return f"搜索失败:{str(e)}"
tools = [get_weather, recommend_activity, web_search]
# 初始化大模型
llm = ChatOpenAI(
model_name="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 使用 LangChain 预定义的 ReAct 提示模板,https://smith.langchain.com/hub/hwchase17/react
#from langchain import hub
#prompt = hub.pull("hwchase17/react")
# 模板内容示例:
template = """
Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}
"""
prompt = PromptTemplate.from_template(template)
# 创建 ReAct 智能体
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True, # 打印详细执行过程
max_iterations=3, # 限制最大迭代次数,
handle_parsing_errors=lambda _: "请检查输入格式", # 错误处理
return_intermediate_steps=True # 保留中间步骤
)
# 执行查询
response = agent_executor.invoke({
"input": "我在北京玩3天,根据天气推荐活动, 顺便查询腾讯的股价是多少"
})
print(response)
```
#### LLM综合实战-文档网络智能问答助手开发
* 需求说明
* 智能体核心功能
* **多模态知识整合**
* 深度结合 **Milvus 向量数据库** 的本地文档知识与 **实时网络搜索能力**,实现对复杂问题的分步解析与回答。
* 支持同时处理 **结构化文档问答**(如技术框架详解)和 **实时信息查询**(如股价、日期等动态数据)。
* **智能工具决策**
- 自动判断问题类型:
- **文档相关问题**(如 "什么是Milvus?")调用 **Milvus 向量检索工具**,精准匹配本地知识库内容。
- **实时信息需求**(如 "腾讯股价")触发 **Web 搜索工具**,获取最新数据。
- 支持 **多问题串联回答**,例如一次性处理包含技术解释、时间查询、股价查询的复合任务。
* **交互式回答增强**
- 通过 **LangChain Agent 框架** 的动态决策流程,展示问题拆解与工具调用的全过程(如中间思考步骤)。
- 提供 **结构化输出**,清晰标注每个答案的来源(如 "来自 Milvus 文档" 或 "来自实时搜索")。
* 技术亮点:
* 工具链集成:无缝融合 Milvus 向量检索 + 网络搜索API + 大模型推理(如 Qwen-Plus)。
* 可视化流程:通过 LangSmith 追踪 Agent 的决策路径
* 自定义提示模板:支持灵活调整 Agent 的行为逻辑(如切换 create_tool_calling_agent 或 create_react_agent 模式)。
* 应用场景
* 技术文档问答:快速解析 Milvus 版本、功能、与 LangChain 的集成方法。
* 实时数据查询:动态获取股票价格、当前日期等时效性信息。
* 多步骤问题处理:如 "解释Milvus的工作原理,同时比较其与Faiss的优劣,最后给出GitHub最新教程链接"。
* 功能效果演示
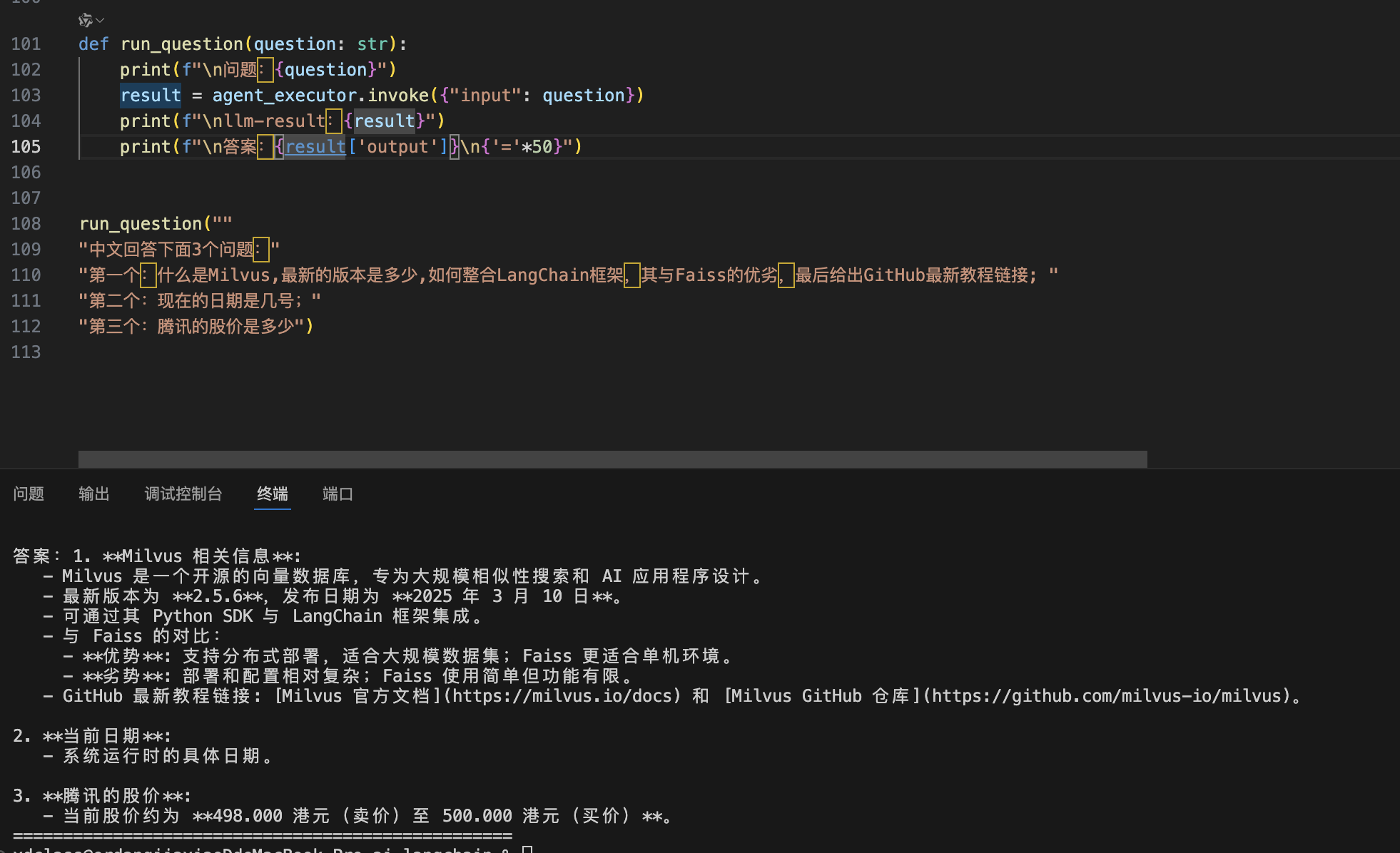
* 编码实战
```python
from langchain_community.utilities import SearchApiAPIWrapper
from langchain_core.tools import tool
from langchain.agents import AgentExecutor, create_tool_calling_agent,create_react_agent
from langchain.tools.retriever import create_retriever_tool
from langchain_milvus import Milvus
from langchain.prompts import PromptTemplate,ChatPromptTemplate
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_openai import ChatOpenAI
import os
from pydantic import Field
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "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"
os.environ["LANGSMITH_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGSMITH_PROJECT"] = "agent_v1"
# 配置搜索工具
os.environ["SEARCHAPI_API_KEY"] = "qQBHMQo4Rk8SihmpJjCs7fML"
search = SearchApiAPIWrapper()
@tool("web_search")
def web_search(query: str) -> str:
"""当需要获取实时信息、最新事件或未知领域知识时使用,输入应为搜索关键词"""
try:
results = search.results(query) # 获取前3条结果
return "\n\n".join([
f"来源:{res['title']}\n内容:{res['snippet']}"
for res in results['organic_results']
])
except Exception as e:
return f"搜索失败:{str(e)}"
#初始化嵌入模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
vector_store = Milvus(
embeddings,
connection_args={"uri": "http://47.119.128.20:19530"},
collection_name='doc_qa_db',
)
#获取检索器
retriever = vector_store.as_retriever()
retriever_tool = create_retriever_tool(
retriever,
"milvus_retriever",
"搜索有关 Milvus 的信息。对于任何有关 Milvus 的问题,你必须使用这个工具!",
)
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
tools = [web_search, retriever_tool]
# #构建提示模板 ,采用create_tool_calling_agent的提示词模版
```
* 编码实战
```python
# #构建提示模板 ,采用create_tool_calling_agent的提示词模版
# prompt = ChatPromptTemplate.from_messages([
# ("system", "你是一个AI文档助手,拥有多个工具,必要时可以利用工具来回答问题。"),
# ("user", "{input}"),
# ("placeholder", "{agent_scratchpad}")
# ])
# # 创建Agent执行器
# agent = create_tool_calling_agent(llm, tools,prompt)
#构建提示模板 ,采用create_react_agent的提示词模版
prompt = PromptTemplate.from_template('''Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}''')
agent = create_react_agent(llm, tools,prompt)
#创建Agent执行器
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True,handle_parsing_errors=True,return_intermediate_steps=True)
def run_question(question: str):
print(f"\n问题:{question}")
result = agent_executor.invoke({"input": question})
print(f"\nllm-result:{result}")
print(f"\n答案:{result['output']}\n{'='*50}")
```
* 案例测试
* 提问输入问题
```
run_question("中文回答下面3个问题:第一个:什么是Milvus,最新的版本是多少,如何整合LangChain框架,其与Faiss的优劣,最后给出GitHub最新教程链接; 第二个:现在的日期是几号;第三个:腾讯的股价是多少")
```
* LangSmith调用链路分析
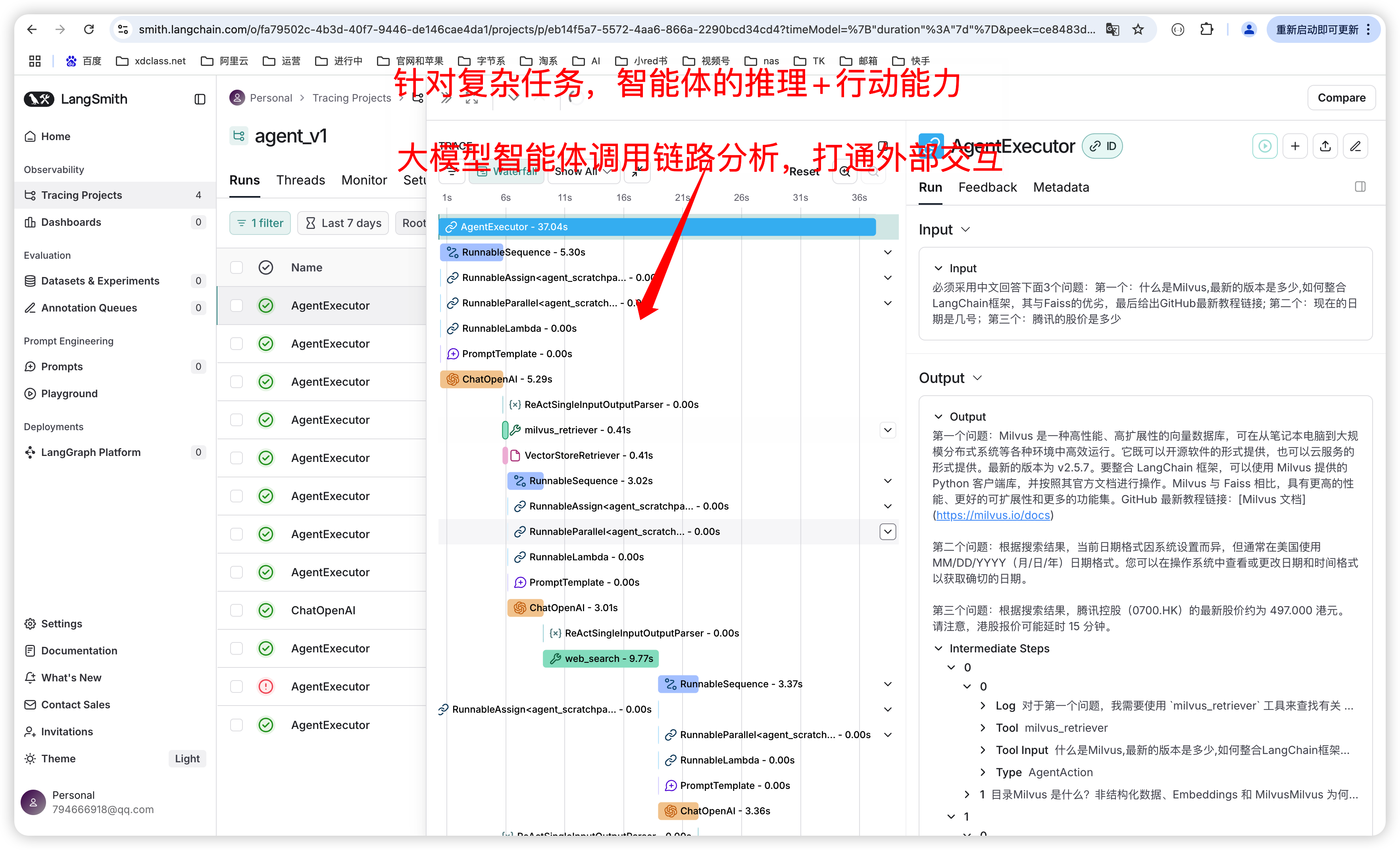
* 切换不同创建agent方法和提示词进行测试
* 打印输出中间思考步骤
* 使用 AgentExecutor 的 `return_intermediate_steps` 参数
```python
#print("最终结果:", result["output"])
#print("中间步骤:", result["intermediate_steps"])
def run_question(question: str):
print(f"\n问题:{question}")
result = agent_executor.invoke({"input": question})
print(f"\nllm-result:{result}")
print(f"\n答案:{result['output']}\n{'='*50}")
# 输出完整执行轨迹
print("=== 完整执行链 ===")
for step in result["intermediate_steps"]:
print(f"Action: {step[0].tool}")
print(f"Input: {step[0].tool_input}")
print(f"Observation: {step[1]}\n")
```
* 总结说明
* 在AI智能体开发中,不同的任务需要不同的交互逻辑,因此需要不同类型的智能体来高效处理不同任务。
* 例如:
- 有些任务需要智能体先“思考”再行动(如解数学题)。
- 有些任务需要直接调用工具完成(如查天气、调用计算器)
* **关键选择点**:
* 任务是否需要分解步骤 → 选`create_react_agent`;
* 任务是否单一明确 → 选`create_tool_calling_agent`。
* **进阶技巧**:
* 混合使用两种智能体(如先用React分解任务,再调用Tool-Calling执行子任务)
* 共同点
- 均基于大模型(如LLM大模型)驱动。
- 依赖预定义的工具集(Tools)。
* **底层关系**:
* `create_tool_calling_agent` 可视为 `create_react_agent` 的简化版(跳过显式推理步骤)。
### 老王忘不了的痛-大模型存储记忆实战
#### LLM大模型存储记忆功能介绍和应用场景
* 需求背景:为什么需要存储记忆功能?
* 长对话上下文遗忘问题
```
# 示例:第二次提问时模型已“失忆”
user_input1 = "我叫张三"
ai_response1 = "你好张三!"
user_input2 = "我叫什么名字?"
ai_response2 = "抱歉,我不知道您的名字。" # 期望回答“张三”
```
* 大模型(如 GPT-4)单次对话的上下文窗口有限(通常为 4k-128k tokens),导致多轮对话中容易丢失早期信息。
* 例如,用户询问 “如何制作蛋糕” 后接着问 “需要烤箱吗”
* 模型若无法记住前一轮对话,可能回答 “需要烤箱” 但忘记蛋糕配方的关键步骤。
* 个性化服务与用户偏好记忆
* 在客服、教育、医疗等场景中,用户需要模型记住个人信息(如姓名、病史)或历史行为(如订单记录、学习进度)。
* 例如,医疗助手需根据患者的历史诊断结果提供建议。
* 复杂任务的状态管理
* 涉及多步骤的任务(如旅行规划、代码调试)需要模型跟踪中间状态。
* 例如,用户要求 “规划上海到北京的三天行程”,模型需记住已推荐的景点、交通方式等。
* LangChain方法
* 短期记忆:通过 Memory 模块存储对话历史,确保模型在多轮交互中保持连贯
* 长期记忆:将用户数据存储在外部数据库或向量数据库(如 Milvus、Pinecone),实现跨会话的长期记忆
* 记忆功能的核心设计
* 两种类型
| 维度 | 短期记忆 | 长期记忆 |
| :------------: | :----------------------------------: | :-----------------------------------------: |
| **存储方式** | 内存缓存, 模型输入中的历史消息 | 数据库持久化存储, 向量库/文件 |
| **容量限制** | 受上下文窗口限制(如4k-128k tokens) | 理论上无上限 |
| **访问速度** | 毫秒级 | 百毫秒级(依赖检索算法) |
| **典型应用** | 对话连贯性保持, 即时对话、单次任务 | 个性化服务、用户画像构建,跨会话记忆、知识库 |
| **实现复杂度** | 低 | 高 |
| **成本** | 低(无额外存储开销) | 中高(需维护存储系统) |
| **示例** | 聊天中记住前3轮对话 | 用户资料、项目历史记录 |
* 记忆的实现方式
* **短期记忆**:通过拼接历史消息实现(`[用户: 你好][AI: 你好!]`)。
* 长期记忆
- **结构化存储**:用数据库记录关键信息(如用户喜好)。
- **向量化存储**:将文本转为向量存入向量库(如Milvus)。
- **混合模式**:短期记忆 + 长期检索增强(RAG)
* 应用场景与案例
* 个性化教育助手 (伪代码)
```python
from langchain.memory import VectorStoreRetrieverMemory
# 初始化记忆系统
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
memory = VectorStoreRetrieverMemory(retriever=retriever)
# 运行示例
memory.save_context(
{"input": "我的学习目标是掌握微积分"},
{"output": "目标已记录,将推荐相关资源"}
)
memory.save_context(
{"input": "请解释洛必达法则"},
{"output": f"{explanation} 已添加到你的学习清单"}
)
# 后续对话
query = "根据我的目标推荐学习资料"
relevant_memories = memory.load_memory_variables({"query": query})
# 返回微积分相关记忆
```
* 电商推荐引擎
```python
from langchain.retrievers import TimeWeightedVectorStoreRetriever
# 带时间权重的记忆系统
retriever = TimeWeightedVectorStoreRetriever(
vectorstore=vectorstore,
decay_rate=0.95, # 记忆衰减系数
k=5
)
# 记忆示例数据
retriever.add_documents([
Document(page_content="用户2026-12-01购买手机", metadata={"type": "purchase"}),
Document(page_content="用户2027-03-15浏览笔记本电脑", metadata={"type": "browse"}),
Document(page_content="用户2027-06-20退货耳机", metadata={"type": "return"})
])
# 获取最新加权记忆
relevant_memories = retriever.get_relevant_documents("用户兴趣分析")
```
* 大模型长短期记忆选择决策树
* 基础用法:短期对话记忆
* 进阶用法:长期记忆 + 向量数据库
* 高级用法:多用户隔离记忆(会话级)
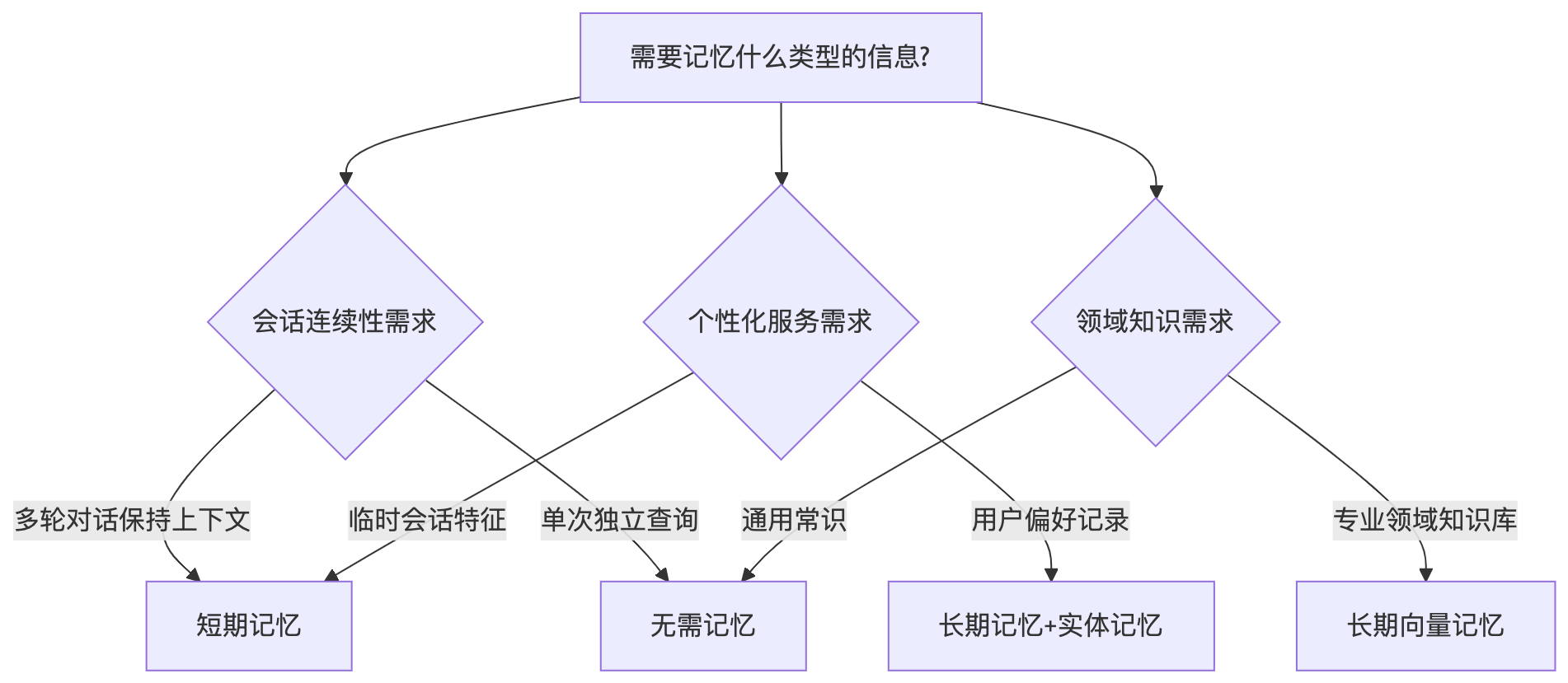
#### LLM存储记忆功能之BaseChatMemory实战
* `BaseChatMemory` 介绍
* 是 LangChain 中所有**聊天型记忆模块的基类**,定义了记忆存储和检索的通用接口。
```
from langchain.memory.chat_memory import BaseChatMemory
```
* 可通过继承此类实现自定义记忆逻辑(如过滤敏感信息、动态清理策略)
* 注意:部分API虽然过期,但也需要知道核心思想, 新旧我们都有讲
* 核心作用
* **标准化接口**:统一 `save_context()`(保存上下文)和 `load_memory_variables()`(加载记忆)方法。
* **状态管理**:维护对话历史(`chat_memory` 属性),支持消息的增删改查。
* **扩展性**:允许开发者覆盖默认行为(如自定义存储格式、加密数据)
* 关键属性
* `chat_memory`
* 存储对话消息的容器,类型为 ChatMessageHistory,包含 messages 列表
* 每条消息为 BaseMessage 对象,如 HumanMessage、AIMessage
* 核心方法
* `save_context` 保存用户输入和模型输出到 chat_memory。
```
memory.save_context({"input": "你好"}, {"output": "你好!有什么可以帮您?"})
# 等价于:
memory.chat_memory.add_user_message("你好")
memory.chat_memory.add_ai_message("你好!有什么可以帮您?")
```
* `load_memory_variables` 返回当前记忆内容(通常为 {"history": "对话历史字符串"}
```
variables = memory.load_memory_variables({})
print(variables["history"]) # 输出:Human: 你好\nAI: 你好!有什么可以帮您?
```
* `clear()` 清空所有记忆
```
#调用
chat_memory.clear()
```
* `BaseChatMemory`的子类
| **类名** | **说明** |
| :------------------------------: | :----------------------------------------------------------: |
| `ConversationBufferMemory` | 直接存储原始对话历史(继承 `BaseChatMemory`)。 |
| `ConversationBufferWindowMemory` | 仅保留最近 N 轮对话(通过 `k` 参数控制,覆盖消息存储逻辑)。 |
| `ConversationSummaryMemory` | 存储模型生成的对话摘要(覆盖 `load_memory_variables` 生成摘要)。 |
| 自定义类 | 继承 `BaseChatMemory`,按需重写 `save_context` 或 `load_memory_variables` |
* 案例实战
* `ConversationBufferMemory`
```python
from langchain.memory import ConversationBufferMemory
# 初始化对话缓冲记忆
memory = ConversationBufferMemory(
memory_key="chat_history", #存储进去的Key,和获取的时候需要保持一致
return_messages=True,
)
# 添加用户消息和 AI 消息
memory.chat_memory.add_user_message("你的名字是什么")
memory.chat_memory.add_ai_message("二当家")
# 加载记忆内容
memory_variables = memory.load_memory_variables({})
print("记忆内容:", memory_variables)
```
* `ConversationBufferWindowMemory `
* 滑动窗口式对话记忆, 此类在对话记录中引入窗口机制,仅保存最近的 `k` 条对话历史。
* **k 参数**:定义窗口大小,表示最多保留的对话记录条数, 适合长对话或对历史要求不高的应用。
```python
from langchain.memory import ConversationBufferWindowMemory
# 初始化窗口记忆,设置窗口大小为 2
memory = ConversationBufferWindowMemory(k=2, memory_key="chat_history")
# 保存一些消息
memory.save_context({"input": "你叫什么名字"}, {"output": "你好,我是三当家"})
memory.save_context({"input": "小滴课堂怎么样"}, {"output": "小滴课堂是适合初学者的计算机学习平台"})
memory.save_context({"input": "好的,我去了解下"}, {"output": "希望对你有帮助!"})
# 获取窗口内的对话历史
window_history = memory.load_memory_variables({})
print("当前窗口内的对话历史:", window_history)
```
#### 【面试题】LLM存储优化-大量长对话如何解决
* 面试官
* 传统对话系统每次交互独立,模型无法感知历史对话内容,如何解决?
* 长对话超出模型的Token处理能力,导致信息截断或性能下降,如何解决?
* **大模型场景题目的需求背景【重要】**
* **大模型的上下文限制**
* 大语言模型(如GPT-4、DeepSeek等虽然能处理复杂的对话任务
* 但其输入长度存在限制(如Token上限),无法直接存储长期对话历史
* **对话连贯性需求**
* 实际应用中(如客服系统、智能助手),用户问题常依赖上下文。
* 例如,用户先问“人工智能的定义”,再要求“详细说明”,模型需基于历史回答才能生成合理响应
* 资源优化需求
* 直接存储完整对话历史会占用大量内存或数据库资源,且频繁传递完整上下文会增加计算成本。
| 问题类型 | 具体表现 | 后果 |
| :------: | :----------------------------: | :------------------------: |
| 技术限制 | 长对话超出模型上下文窗口 | 关键信息丢失,回答质量下降 |
| 效率瓶颈 | 全量历史数据检索耗时(>500ms) | 响应延迟影响用户体验 |
| 业务需求 | 需快速定位历史问题关键点 | 客服质检、争议溯源效率低 |
| 合规风险 | 存储用户敏感对话原文 | 数据泄露风险增加 |
* 面试回答要点
* **核心目标**
* 通过摘要存储实现对话上下文的长期维护,解决大模型Token限制与对话连贯性问题。
* 技术实现
* 记忆模块:LangChain提供ConversationBufferMemory(完整历史)和ConversationSummaryMemory(摘要存储)等
* 摘要生成:调用LLM对历史对话生成摘要,后续交互仅传递摘要而非完整历史
* **优势**
- 减少Token消耗,适配模型输入限制。
- 提升对话系统的长期记忆能力。
- 支持分布式存储(如MongoDB、Milvus),扩展性强
* `ConversationSummaryMemory`
* 通过模型生成对话的摘要,帮助保留重要信息,而不保存完整历史,适合需要长期记忆的场景。
* 原理就是提示词,让AI帮出来摘要,而且可以定制
```python
请将以下对话压缩为简短摘要,保留用户需求和关键结果:
对话历史:
{history}
当前对话:
Human: {input}
AI: {output}
摘要:
"""
```
* **load_memory_variables**:返回当前会话的摘要信息。
```python
from langchain.memory import ConversationSummaryMemory
from langchain_openai import ChatOpenAI
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 初始化摘要记忆
memory = ConversationSummaryMemory(llm=llm)
# 模拟对话
memory.save_context({"input": "你叫什么名字?"}, {"output": "你好,我是三当家。"})
memory.save_context({"input": "你能告诉我机器学习吗?"}, {"output": "机器学习是人工智能的一个分支。"})
# 获取摘要
summary = memory.load_memory_variables({})
print("当前对话摘要:", summary)
```
#### 基于LangChain的带摘要存储对话系统实战
* 实战案例
* 基于LangChain的带摘要存储对话系统
```python
from langchain.memory import ConversationSummaryMemory
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 初始化模型和记忆模块
memory = ConversationSummaryMemory(
llm=llm,
memory_key="chat_history", # 与prompt中的变量名一致
return_messages=True
)
# 定义提示模板(必须包含chat_history占位符)
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个助手,需基于对话历史回答问题。当前摘要:{chat_history}"),
("human", "{input}")
])
# # 创建链并绑定记忆模块
# chain = LLMChain(
# llm=llm,
# prompt=prompt,
# memory=memory,
# verbose=True # 调试时查看详细流程
# )
# 定义LCEL链式流程
chain = (
# 注入输入和记忆
RunnablePassthrough.assign(
chat_history=lambda _: memory.load_memory_variables({})["chat_history"]
)
| prompt # 将输入传递给提示模板
| llm # 调用模型
| StrOutputParser() # 解析模型输出为字符串
)
# 模拟多轮对话
user_inputs = [
"人工智能的定义是什么?",
"小滴课堂上面有什么课程可以学习",
"人工智能它在医疗领域有哪些应用?"
]
for query in user_inputs:
# 执行对话
response = chain.invoke({"input": query})
# 打印结果
print(f"\n用户:{query}")
print(f"AI:{response}")
#使用 LLMChain 而非原始LCEL链时,每次 invoke() 会自动调用 memory.save_context()。
#手动调用场景需显式保存:
memory.save_context({"input": query}, {"output": response})
print("当前记忆摘要:", memory.load_memory_variables({})["chat_history"])
```
* 示例输出
```markdown
用户:人工智能的定义是什么?
AI:人工智能是模拟人类智能的计算机系统...
当前记忆摘要: 用户询问人工智能的定义,助手解释了其核心是通过算法模拟人类认知能力。
用户:小滴课堂上面有什么课程可以学习
AI:如果“小滴课堂”是一个特定的学习平台,建议直接查询该平台提供的课程列表以获取最新信息
当前记忆摘要: 首先询问了人工智能的定义,AI解释了人工智能是计算机科学的一个分支,随后,人类问到“小滴课堂”上有什么课程可以学习
用户:它在医疗领域有哪些应用?
AI:在医疗影像分析、药物研发...
当前记忆摘要: 用户问及医疗应用,助手提到影像分析、药物研发和个性化诊疗是主要方向。
```
* 关键步骤讲解
* **链式组合 (`|` 操作符)**
通过管道符连接多个组件:
- `RunnablePassthrough`:传递原始输入
- `prompt`:格式化提示词
- `llm`:调用大模型
- `StrOutputParser`:解析输出为字符串
* **记忆管理**
- `memory.load_memory_variables()`:加载当前摘要到提示词
- `memory.save_context()`:手动保存对话记录(LCEL需要显式保存)
* **变量绑定**
使用 `RunnablePassthrough.assign` 动态注入 `chat_history` 变量,确保与提示模板匹配
* 注意: 变量名一致性
- `memory_key` 必须与提示模板中的变量名一致(示例中均为 `chat_history`)。
- 错误示例:如果模板用 `{summary}` 但 `memory_key` 设为 `history`,会导致变量未注入
* LCEL与 LLMChain 的核心区别
| 特性 | LCEL 实现 | LLMChain 实现 |
| :------------- | :--------------------------- | :------------------ |
| **记忆管理** | 需手动调用 `save_context` | 自动保存上下文 |
| **链式组合** | 支持任意步骤组合 | 固定结构 |
| **调试灵活性** | 可插入日志中间件 | 依赖 `verbose=True` |
| **扩展性** | 容易添加路由、分支等复杂逻辑 | 适合简单线性流程 |
#### MessagesPlaceholder和多轮AI翻译助手实战
* `MessagesPlaceholder `介绍
* 是 LangChain 中用于在 **聊天型提示模板(ChatPromptTemplate)** 中动态插入消息列表的占位符。
* 允许开发者将历史对话记录、系统消息等结构化地嵌入到 Prompt 中,从而支持多轮对话场景的上下文管理
* 适用场景
* 多角色对话:在聊天机器人中,区分系统指令、用户输入和AI响应。
* 历史对话注入:将历史消息作为上下文传递给模型,确保对话连贯性。
* 模块化Prompt设计:灵活组合不同来源的消息(如系统消息、检索结果等)
* 与普通PromptTemplate的区别
* PromptTemplate:用于单字符串模板,适合简单问答。
* ChatPromptTemplate:专为多角色消息设计,必须使用 MessagesPlaceholder 处理消息列表
* 例如
```python
ChatPromptTemplate.from_messages([
("system", "你是一个助手"),
MessagesPlaceholder(variable_name="history"),
("human", "{input}")
])
```
* 核心功能对比
| 功能特性 | MessagesPlaceholder | 传统列表存储 |
| :--------------: | :--------------------------: | :----------------: |
| **动态插入** | ✅ 支持运行时动态调整消息顺序 | ❌ 固定顺序 |
| **消息类型感知** | ✅ 区分 system/human/AI | ❌ 统一存储为字符串 |
| **内存集成** | ✅ 自动与Memory组件同步 | ❌ 需手动管理 |
| **结构化操作** | ✅ 支持消息元数据 | ❌ 纯文本存储 |
* 使用步骤
* 定义模板与占位符
* 在 ChatPromptTemplate 中通过 MessagesPlaceholder 声明占位位置
* **并指定变量名(需与 Memory 模块的 memory_key 一致)**
```python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个翻译助手"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}")
])
```
* 绑定记忆模块
* 使用 ConversationBufferMemory 或 ConversationSummaryMemory 存储对话历史,
* 并确保 memory_key 与占位符变量名匹配
```python
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
memory_key="chat_history", # 必须与MessagesPlaceholder的variable_name一致
return_messages=True # 返回消息对象而非字符串
)
```
* 链式调用与历史管理
* 在链式调用中自动注入历史消息,需使用 LLMChain 或 `RunnableWithMessageHistory`
```python
from langchain.chains import LLMChain
from langchain_community.chat_models import ChatOpenAI
llm = ChatOpenAI()
chain = LLMChain(llm=llm, prompt=prompt, memory=memory)
```
* 案例测试
```python
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_models import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains import LLMChain
from langchain_openai import ChatOpenAI
# 1. 初始化模型与记忆模块
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# 2. 定义包含MessagesPlaceholder的Prompt模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个翻译助手,需参考历史对话优化翻译结果。"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "请翻译以下内容:{input}")
])
# 3. 创建链并绑定记忆
chain = LLMChain(llm=llm, prompt=prompt, memory=memory)
# 4. 模拟多轮对话
user_inputs = [
"Translate 'Hello' to Chinese",
"Use the translation in a sentence",
"Now translate 'Goodbye'"
]
for query in user_inputs:
response = chain.invoke({"input": query})
print(f"用户:{query}")
print(f"AI:{response['text']}\n")
print("当前对话历史:", memory.load_memory_variables({})["chat_history"], "\n")
```
* LCEL表达式案例
```python
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_models import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains import LLMChain
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# 1. 初始化模型与记忆模块
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# 2. 定义包含MessagesPlaceholder的Prompt模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个翻译助手,需参考历史对话优化翻译结果。"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "请翻译以下内容:{input}")
])
# 3. 创建链并绑定记忆
#chain = LLMChain(llm=llm, prompt=prompt, memory=memory)
#定义LECL表达式,构建chain
chain = (
RunnablePassthrough.assign(
chat_history = lambda _ : memory.load_memory_variables({})['chat_history']
)
| prompt
| llm
| StrOutputParser()
)
# 4. 模拟多轮对话
user_inputs = [
"Translate 'Hello' to Chinese",
"Use the translation in a sentence",
"Now translate 'Goodbye'"
]
for query in user_inputs:
response = chain.invoke({"input": query})
print(f"用户:{query}")
print(f"AI:{response}\n")
memory.save_context({"input": query}, {"output": response})
print("当前对话历史:", memory.load_memory_variables({})["chat_history"], "\n")
```
#### LLM复杂记忆存储-多会话隔离案例实战
* 背景与需求
* 当多个会话同时与对话系统交互时,需确保每个会话的对话历史独立存储,避免以下问题:
- **数据混淆**:会话A的对话内容泄露给会话B。
- **上下文丢失**:不同会话的对话历史互相覆盖。
- **隐私安全**:敏感信息因隔离不当导致泄露。
* **典型场景**
- **客服系统**:不同会话咨询需独立记录。
- **教育应用**:每个学生与AI助教的对话需单独存档。
- **医疗助手**:患者健康信息需严格隔离。
* **解决方案:为每个会话分配唯一ID,通过ID隔离的对话历史。**
* `RunnableWithMessageHistory` 介绍
* 是 LangChain 中用于**动态管理多用户对话历史**的高级封装类,主要解决以下问题
* **会话隔离**:为不同用户/会话(通过 `session_id`)独立存储对话历史。
* **记忆注入**:自动将历史消息注入到链的每次执行中,无需手动传递。
* **灵活存储**:支持自定义历史存储后端(内存、数据库、Redis 等)。
* 核心参数
```
from langchain_core.runnables.history import RunnableWithMessageHistory
```
| 参数 | 类型 | 必填 | 说明 |
| :--------------------: | :-------------------------------------: | :--: | :-------------------------------------: |
| `runnable` | Runnable | 是 | 基础处理链(需支持消息历史输入) |
| `get_session_history` | Callable[[str], BaseChatMessageHistory] | 是 | 根据session_id获取历史存储实例的函数 |
| `input_messages_key` | str | 否 | 输入消息在字典中的键名(默认"input") |
| `history_messages_key` | str | 否 | 历史消息在字典中的键名(默认"history") |
* 使用场景
* **多用户对话系统**:为每个用户维护独立的对话历史(如客服系统)。
* **长期会话管理**:结合数据库存储历史,支持跨设备会话恢复。
* 案例实战
```python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai.chat_models import ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
# 存储会话历史的字典,可以改其他存储结构
store = {}
# 获取会话历史的函数 如果给定的session_id不在store中,则为其创建一个新的ChatMessageHistory实例
def get_session_history(session_id):
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
# 初始化大模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 构建聊天提示模板,包含系统消息、历史消息占位符和人类消息
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是一个小滴课堂AI助手,擅长能力{ability}。用30个字以内回答",
),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
# 创建Runnable管道,将提示模板和模型结合在一起
runnable = prompt | model
# 创建带有会话历史的Runnable ,使用get_session_history函数来管理会话历史
with_message_history = RunnableWithMessageHistory(
runnable,
get_session_history,
input_messages_key="input", #输入消息在字典中的键名(默认"input")
history_messages_key="history", #历史消息在字典中的键名(默认"history")
)
# 第一次调用带有会话历史的Runnable,提供用户输入和会话ID
response1=with_message_history.invoke(
{"ability": "Java开发", "input": HumanMessage("什么是jvm")},
config={"configurable": {"session_id": "user_123"}},#历史信息存入session_id
)
print(f"response1:{response1.content}",end="\n\n")
# 第二次调用带有会话历史的Runnable,用户请求重新回答上一个问题
response2=with_message_history.invoke(
{"ability": "Java开发", "input": HumanMessage("重新回答一次")},
config={"configurable": {"session_id": "user_123"}},#历史信息存入session_id,如果改为其他session_id,则不会关联到之前的会话历史
)
print(f"response2:{response2.content}",end="\n\n")
# 打印存储的会话历史
print(f"存储内容:{store}")
```
#### 再进阶复杂存储-多租户多会话隔离案例实战
* 需求背景
* 系统需要支持多个用户访问,每个用户拥有唯一的标识符(`user_id`)。
* 用户之间的会话历史完全隔离,避免数据混淆。
* 业务场景中,存在一个用户多个会话的场景
* 存储里面需要支持多用户,多会话的方案, 支持不同用户在多个会话中与AI助手交互。
* 目标:
* **多租户支持**:每个用户拥有独立的标识符(`user_id`),确保不同用户之间的数据隔离。
* **多会话支持**:每个用户可以同时维护多个会话(`session_id`),每个会话的历史记录相互独立。
* **灵活扩展性**:支持自定义存储结构和参数配置,便于未来扩展到分布式存储或其他存储介质
* 知识点
* `history_factory_config`
- 是一个配置列表,用于定义额外的可配置字段,(如 `user_id` 和 `session_id`),这些字段可以影响会话历史的生成逻辑。
- 通过自定义参数来增强系统的灵活性,例如指定用户标识符或对话标识符,从而实现多租户或多会话的支持
* `ConfigurableFieldSpec`
* 是一个类,用于定义一个可配置字段的元信息,包括字段的 ID、类型、名称、描述、默认值等。
```
from langchain_core.runnables import ConfigurableFieldSpec
```
* 为 `RunnableWithMessageHistory` 提供灵活的参数支持,使得开发者可以通过配置动态调整行为。
| 参数名 | 类型 | 描述 | 示例值 |
| :------------ | :----- | :----------------------------------------------------------- | :--------------------- |
| `id` | `str` | 字段的唯一标识符,用于在配置中引用该字段。 | `"user_id"` |
| `annotation` | `type` | 字段的数据类型,用于类型检查和验证。 | `str` |
| `name` | `str` | 字段的名称,通常用于UI展示或调试信息。 | `"用户ID"` |
| `description` | `str` | 字段的描述信息,用于说明该字段的用途。 | `"用户的唯一标识符。"` |
| `default` | `any` | 字段的默认值,如果未提供值时使用。 | `""` |
| `is_shared` | `bool` | 是否为共享字段。如果为 `True`,则该字段在整个运行过程中保持不变。 | `True` |
* 解决方案
* 使用 `user_id` 和 `session_id` 组合作为键值,存储在全局字典 `store` 中。
* 在调用 `get_session_history` 函数时,传入 `user_id` 和 `session_id`,确保获取正确的会话历史。
* 案例实战
```python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai.chat_models import ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables import ConfigurableFieldSpec
# 存储会话历史的字典,可以改其他存储结构
store = {}
# 获取会话历史的函数 如果给定的session_id不在store中,则为其创建一个新的ChatMessageHistory实例
def get_session_history(user_id: str,session_id: str):
if (user_id, session_id) not in store:
store[(user_id, session_id)] = ChatMessageHistory()
return store[(user_id, session_id)]
# 初始化大模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 构建聊天提示模板,包含系统消息、历史消息占位符和人类消息
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是一个小滴课堂AI助手,擅长能力{ability}。用30个字以内回答",
),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
# 创建Runnable管道,将提示模板和模型结合在一起
runnable = prompt | model
# 创建带有会话历史的Runnable ,使用get_session_history函数来管理会话历史
with_message_history = RunnableWithMessageHistory(
runnable,
get_session_history,
input_messages_key="input", #输入消息在字典中的键名(默认"input")
history_messages_key="history", #历史消息在字典中的键名(默认"history")
# 定义一些自定义的参数
history_factory_config=[
ConfigurableFieldSpec(
id="user_id",
annotation=str,
name="用户ID",
description="用户的唯一标识符。",
default="",
is_shared=True,
),
ConfigurableFieldSpec(
id="session_id",
annotation=str,
name="对话 ID",
description="对话的唯一标识符。",
default="",
is_shared=True,
),
]
)
# 第一次调用带有会话历史的Runnable,提供用户输入和会话ID
response1=with_message_history.invoke(
{"ability": "Java开发", "input": HumanMessage("什么是jvm")},
config={'configurable' : { "user_id" : "1" , "session_id" : "1" }}
)
print(f"response1:{response1.content}",end="\n\n")
# 第二次调用带有会话历史的Runnable,用户请求重新回答上一个问题
response2=with_message_history.invoke(
{"ability": "Java开发", "input": HumanMessage("重新回答一次")},
#历史信息存入session_id,如果改为其他session_id,则不会关联到之前的会话历史
config={'configurable' : { "user_id" : "1" , "session_id" : "2" }},
)
print(f"response2:{response2.content}",end="\n\n")
# 打印存储的会话历史
print(f"存储内容:{store}")
```
#### 大模型长期记忆解决方案和案例实战
* 长期记忆的核心需求
* 大模型(LLM)本身不具备长期记忆能力,需通过外部系统实现以下目标:
* **跨会话记忆持久化**:用户多次对话中产生的关键信息需永久存储。
* **多用户隔离**:不同用户的对话历史严格隔离,避免数据泄露。
* **高效检索**:快速提取历史信息辅助当前对话生成。
* **动态更新**:支持记忆的增量添加和过期清理。
* 解决思路:
* 持久化存储:将会话历史保存到数据库/缓存,支持跨会话读取。
* 高效检索:通过语义搜索或键值查询快速定位历史信息。
* 动态更新:根据新交互持续补充用户画像。
* LangChain提供的存储方案
* 地址(失效忽略即可):https://python.langchain.com/docs/integrations/memory/
* `RedisChatMessageHistory` 存储介绍

* 内置的 Redis 消息历史存储工具,将会话记录以结构化形式保存至 Redis
| 特性 | 价值 |
| :-------------: | :----------------------------------------------------------: |
| 低延迟(<1ms) | 实时响应交互需求 |
| 丰富数据结构 | 灵活存储消息/元数据/关系, 使用 JSON 格式存储,支持复杂消息类型(如带元数据的消息) |
| 持久化选项 | RDB+AOF保障数据安全 |
| 集群支持 | 横向扩展应对高并发 |
| 自动过期(TTL) | 合规数据自动清理, 通过 `expire` 参数设置历史记录保存时间(如 30 天自动删除 |
* LangChain 的 `RedisChatMessageHistory` 等组件默认依赖 JSON 格式存储对话历史,ReJSON 提供天然的兼容性
* 数据存储结构
* 步骤思路
* 配置SearchAPI的API密钥,
* 实例化`SearchApiAPIWrapper`对象,用于调用搜索API。
* 定义多个工具函数,供系统在回答问题时调用。
- **web_search**: 用于搜索实时信息、最新事件或未知领域知识。
- 输入参数:`query`(字符串类型,搜索关键词)。
- 返回值:搜索结果的标题和摘要。
- **multiply**: 用于计算两个整数的乘积。
- 输入参数:`a`和`b`(均为整数类型)。
- 返回值:两数相乘的结果。
* 初始化大语言模型(LLM),并将其与工具绑定,形成一个智能问答Agent。
- **关键点**
- 使用`ChatOpenAI`类初始化LLM,指定模型名称、API密钥、温度等参数。
- 创建聊天提示模板(`ChatPromptTemplate`),定义系统角色和用户输入格式。
- 将工具列表与LLM绑定,具备工具调用能力的Agent。
* 构建运行链(`chain`),将用户输入传递给提示模板和Agent,生成响应。
- **关键点**
- 用户输入通过`RunnablePassthrough`传递到提示模板。
- 提示模板生成的消息进一步传递给Agent处理。
* 根据据LLM生成的响应,判断是否要调用工具。如果需要调用工具并将结果合并到历史消息中,重新传递给LLM生成最终答案。
- **关键点**
- 通过`resp.tool_calls`判断是否需要调用工具。
- 调用工具后,将结果以`ToolMessage`形式添加到历史消息中。
- 最终结果由LLM根据更新的历史消息生成。
* 案例代码实战
```python
# 基于LangChain 0.3.x的SearchApi工具实战(需安装依赖)
# pip install langchain-core langchain-openai langchain-community
from langchain_community.utilities import SearchApiAPIWrapper
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langchain_core.messages import ToolMessage
from langchain_core.runnables import RunnablePassthrough
from langchain_core.prompts import ChatPromptTemplate
import os
from langchain_core.tools import tool
from pydantic import Field
# ======================
# 第一步:配置搜索工具
# ======================
# 注册SearchAPI获取密钥:https://www.searchapi.io/
# 设置SearchAPI的API密钥
os.environ["SEARCHAPI_API_KEY"] = "qQBHMQo4Rk8SihmpJjCs7fML"
# 实例化SearchApiAPIWrapper对象,用于调用搜索API
search = SearchApiAPIWrapper()
# ======================
# 第二步:定义搜索工具
# ======================
@tool("web_search", return_direct=True)
def web_search(query: str) -> str:
"""
当需要获取实时信息、最新事件或未知领域知识时使用,输入应为搜索关键词
"""
try:
results = search.results(query) # 获取前3条结果
return "\n\n".join([
f"来源:{res['title']}\n内容:{res['snippet']}"
for res in results['organic_results']
])
except Exception as e:
return f"搜索失败:{str(e)}"
@tool("multiply")
def multiply(a: int, b: int) -> int:
"""
把传递的两个参数相乘
"""
return a * b
# ======================
# 第三步:绑定LLM创建Agent
# ======================
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 创建聊天提示模板
prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个AI助手,名称叫老王,请根据用户输入的查询问题,必要时可以调用工具帮用户解答"),
("human", "{query}"),
]
)
# 定义工具字典
tool_dict = {
"web_search": web_search,
"multiply": multiply
}
# 从字典中提取工具列表
tools = [ tool_dict[tool_name] for tool_name in tool_dict ]
# 绑定工具到大模型
llm_with_tools = llm.bind_tools(tools=tools)
# 创建运行链
chain = {"query":RunnablePassthrough()} | prompt | llm_with_tools
# 定义查询
query = "你是谁?"
# 执行链并获取响应
resp = chain.invoke({"query":query})
print(resp)
#判断是否需要调用工具 content=''不一定需要调用,根据tool_calls进行判断
```
* 编码实战
```python
#判断是否需要调用工具 content=''不一定需要调用,根据tool_calls进行判断
# ======================
# 第四步:获取工具调用
# ======================
tool_calls = resp.tool_calls
if len(tool_calls) <= 0:
print(f"不需要调用工具:{resp.content}")
else:
#将历史消息合并,包括用户输入和AI输出
history_messages = prompt.invoke(query).to_messages()
history_messages.append(resp)
print(f"历史消息:{history_messages}")
#循环调用工具
for tool_call in tool_calls:
tool_name = tool_call.get("name")
tool_args = tool_call.get("args")
tool_resp = tool_dict[tool_name].invoke(tool_args)
print(f"一次调用工具:{tool_name},参数:{tool_args},结果:{tool_resp}")
#将工具调用结果添加到历史消息中
history_messages.append(
ToolMessage(
tool_call_id=tool_call.get("id"),
name=tool_name,
content=tool_resp
)
)
print(f"历史消息:{history_messages}")
resp = llm_with_tools.invoke(history_messages)
print(f"最终结果:{resp}")
print(f"调用工具后的结果:{resp.content}")
```
* 案例测试实战
```
#query = "9*3是多少"
#query = "今天是腾讯股价是多少"
```
* 扩展功能建议
- **多语言支持**:增加对多种语言的输入和输出支持。
- **更多工具集成**:集成更多类型的工具,如翻译工具、图像识别工具等。
- **用户反馈机制**:允许用户对系统生成的答案进行评价,优化模型性能。
### 大模型链路调试平台之LangSmith实战
#### 大模型LLM调用链路分析和LangSmith介绍
* 需求背景
* 开发基于大语言模型(LLM)的智能体时,会遇到以下问题:
* 调试困难
* LLM 的输出不可预测,难以追踪中间步骤(如思维链、工具调用)。
* 错误定位耗时(如工具返回异常,但不知道具体哪一步出错)。
* 测试复杂
* 需要验证不同输入场景下的输出稳定性。
* 手动测试效率低,缺乏自动化验证。
* 监控缺失
* 生产环境中的智能体行为难以追踪(如 API 调用延迟、错误率)。
* 无法分析用户高频问题或模型性能瓶颈。
* **LangSmith 是什么**
* **LangChain官方出品**的LLM应用开发调试与监控平台
* 地址:https://smith.langchain.com/
* 解决大模型应用开发中的**调试困难**、**效果追踪**、**生产监控**三大痛点
* 类似:Java中的Spring Boot Actuator(监控)、ELK Stack(日志分析)
* 核心功能说明
* 调试与追踪
- 记录智能体完整执行链路(LLM 调用、工具调用、中间结果)。
- 可视化展示每一步的输入输出和耗时。
- 统计成功率、延迟等关键指标。
* 生产监控
- 实时监控 API 调用异常(如超时、错误响应)。
- 分析用户高频请求和模型性能趋势
* 功能矩阵
| 功能模块 | 作用描述 | 典型应用场景 |
| :----------: | :---------------------------------------: | :---------------------: |
| 运行追踪 | 记录LLM调用链的完整执行过程 | 调试复杂Chain/Agent逻辑 |
| 提示工程分析 | 对比不同Prompt模板的实际效果 | 优化系统提示词 |
| 版本对比 | 比对不同模型版本或参数的表现 | 模型升级效果验证 |
| 生产监控 | 实时监控API调用指标(延迟、成本、错误率) | 服务健康状态跟踪 |
| 团队协作 | 共享调试结果和监控仪表盘 | 多人协作开发LLM应用 |
* LangSmith 系统架构
* SDK捕获所有LLM相关操作
* 加密传输到LangSmith服务端
* 数据存储与索引
* 可视化界面动态查询
```
[Your Application]
│
▼
[LangChain SDK] → [LangSmith API]
│ │
▼ ▼
[LLM Providers] [Trace Storage]
│ │
▼ ▼
[External Tools] [Analytics Engine]
```
* 相关环境实战
* 注册地址:https://smith.langchain.com/

* 配置项目前准备
* 项目安装依赖
```
pip install langsmith==0.3.19
```
* 生成密钥,记得保存
* 配置项目名称(不存在的话会自动新建)

#### 大模型调用接入LangSmith分析实战
**简介: 大模型调用接入LangSmith分析实战**
* LangChain接入调用链路分析实战
* 项目配置
```
#示例配置
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "ls_xxxxx" # 替换为实际Key
os.environ["LANGCHAIN_PROJECT"] = "My_Project" # 自定义项目名
os.environ["LANGSMITH_ENDPOINT"] = "https://api.smith.langchain.com" #后端接口路径
```
```python
#真正配置
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "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"
os.environ["LANGSMITH_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGSMITH_PROJECT"] = "agent_v1"
```
* 如果需要本地私有化部署 langfuse
* 案例实战分析
* 单独案例测试
```python
import os
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "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"
os.environ["LANGSMITH_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGSMITH_PROJECT"] = "xdclass_test_v1"
from langchain_openai import ChatOpenAI
import logging
logging.basicConfig(level=logging.DEBUG)
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
resp = llm.invoke("什么是智能体")
print(resp.content)
```

* 进阶案例测试【选择之前的案例代码-43.2】

### 模型Agent智能体进阶开发实战
#### 大模型智能体之CoT思维链和ReAct推理行动
* 需求背景:为什么需要CoT/ReAct?
* 问题场景:传统大模型直接输出结果,但复杂任务(数学推理/多步骤决策)易出错
* 核心需求:让模型展示思考过程 + 动态调整策略
* 类比理解:
* 普通模型 → 考试直接写答案
* CoT → 在试卷上写解题步骤
* ReAct → 边查公式手册边解题
* 什么是CoT(思维链,Chain of Thought)
* **核心机制**:通过显式生成推理步骤得出最终答案
```python
"""
问题:...[输入问题]...
思考步骤:
1. 第一步分析(如提取关键数据)
2. 第二步计算(如公式应用)
3. ...(更多步骤)
最终答案:...[结论]...
"""
比如问题:A超市苹果每斤5元,买3斤送1斤;B超市同品质苹果每斤6元但买二送一。买8斤哪家更划算?
CoT推理:
1. A超市实际获得:3+1=4斤,花费3×5=15元 → 单价15/4=3.75元/斤
2. 买8斤需要购买两次活动:4×2=8斤 → 总价15×2=30元
3. B超市每3斤花费6×2=12元 → 单价12/3=4元/斤
4. 买8斤需购买3次活动(3×3=9斤)花费12×3=36元 → 实际单价36/9=4元/斤
5. 结论:A超市更优惠
```
* 是一种促使大语言模型产生一系列中间推理步骤,进而得出最终答案的技术。
* 以往的大模型通常直接给出问题的答案,而 CoT 鼓励模型展示其思考过程,就像人类在解决复杂问题时逐步推导一样。
* 这种方法能增强模型在处理复杂推理任务时的性能,尤其是涉及算术、常识推理和符号操作的任务。
* 局限性
* **依赖模型知识**:若模型内部知识错误,推理链条也可能错误(如“太阳绕地球转”)。
* **不适用于动态信息**:无法处理需要实时数据的问题(如“今天天气如何”)。
* **步骤冗余**:简单问题可能因分步反而降低效率。
* 案例说明:算术问题
* 问题:小明有 5 个苹果,小红给他 3 个,然后他吃了 2 个,还剩下多少个苹果?
* 无 CoT 回答:“6 个”。
* CoT 回答:
* 首先,小明原本有 5 个苹果,小红又给了他 3 个,那么此时他拥有的苹果数为 5 + 3 = 8 个。
* 接着,他吃了 2 个苹果,所以剩下的苹果数是 8 - 2 = 6 个。
* 因此,小明最后还剩下 6 个苹果。
* 应用场景
* 教育领域
* 用于辅导学生学习数学、科学等学科的推理问题。
* 通过展示推理过程,学生能更好地理解解题思路,提高学习效果。
* 智能客服
* 在回答客户复杂问题时,展示推理过程能让客户更清楚解决方案的由来,增强客户对服务的信任。
* 什么是ReAct(推理与行动,Reasoning and Acting)
* **交互逻辑**:循环执行"思考-行动-观察"步骤
```python
"""
问题:...[输入问题]...
思考:当前需要解决的问题是...
行动:调用__工具名称__(参数)
观察:工具返回结果...
思考:根据结果分析...
(循环直至得出结论)
答案:...[最终结果]...
"""
比如问题:2027年诺贝尔文学奖得主的代表作是什么?
ReAct流程:
[思考] 需要先确定最新获奖者 → 调用搜索工具
[行动] 使用DuckDuckGo搜索"2027诺贝尔文学奖获得者"
[观察] 结果显示:法国作家安妮·艾诺
[思考] 需要确认其代表作品 → 调用维基百科工具
[行动] 查询维基百科"安妮·艾诺"
[观察] 主要作品:《悠悠岁月》《位置》等
[结论] 代表作是《悠悠岁月》
```
* ReAct 是一种让大模型结合推理和行动的范式,不是前端框架React
* 模型不仅要进行推理,还能根据推理结果调用外部工具(如搜索引擎、数据库等)来获取额外信息,从而更有效地解决问题。
* 它使模型能够与外部环境交互,拓展了模型的能力边界。
* ReAct的优势
* 减少幻觉:通过实时调用外部工具验证信息,降低模型编造错误答案的概率。
* 处理复杂任务:适合多步骤问题(如数学计算、事实核查),传统单次生成容易出错。
* 透明可解释:模型的推理过程以自然语言呈现,便于人类理解其决策逻辑。
* 案例说明:
* 问题:2027 年 NBA 总冠军是哪个队伍?
* 无 ReAct 处理:由于模型训练数据可能存在时效性问题,可能无法给出准确答案或给出过时的信息。
* ReAct 处理:
* 推理:模型意识到自己可能没有最新的 2026 年 NBA 总冠军信息,需要调用外部资源获取。
* 行动:调用体育新闻网站的 API 或搜索引擎查询相关信息。
* 结果:获取到最新信息后,给出准确回答,如 “2026年 NBA 总冠军是 [具体队伍名称]。
* 应用场景
* 知识问答系统
* 处理需要实时信息或特定领域最新数据的问题,如财经数据、体育赛事结果、科技动态等。
* 任务自动化
* 在自动化流程中,根据任务需求调用不同的工具和服务,如预订机票、查询物流信息、控制智能家居设备等。
* 技术框架对比
| 维度 | CoT | ReAct |
| :---------------: | :-------------------------------: | :---------------------------------: |
| **核心组件** | 纯提示工程,依赖模型知识 | 代理(Agent)+ 工具调用 |
| **数据依赖** | 仅依赖内部知识 | 可接入外部数据源/API |
| **错误修复** | 单次推理完成 | 可通过多次行动修正结果 |
| **适用场景** | 理论推导/数学计算 | 实时信息查询/复杂任务分解 |
| **计算开销** | 低 | 中高(涉及外部调用) |
| **LangChain组件** | `ChatPromptTemplate` + `LLMChain` | `Agent` + `Tools` + `AgentExecutor` |
| **优势** | 简单、透明 | 实时交互,扩展性强 |
| **缺点** | 无法获取最新信息 | 依赖工具API的稳定性 |
* 应用场景指南
| 场景类型 | 推荐方法 | 原因说明 |
| :--------------: | :------: | :------------------------: |
| 数学/逻辑推理 | CoT | 无需外部数据,单步推理高效 |
| 实时数据获取 | ReAct | 需要调用搜索/API工具 |
| 多步骤决策任务 | ReAct | 支持动态调整执行路径 |
| 知识密集型问答 | CoT | 依赖模型内部知识库 |
| 复杂问题分解执行 | 混合架构 | 兼顾推理与执行效率 |
* **开发建议**:
* **方法选择原则**:
- 纯推理 → CoT
- 需实时数据 → ReAct
* **提示工程技巧**:
- CoT需明确定义步骤格式
- ReAct要严格规范行动命名(如`调用API名称_参数`)
* **常见陷阱**:
- CoT可能产生错误中间步骤
- ReAct需处理API调用失败情况
* 通过`verbose=True`参数观察两种方法的执行过程差异
* LangChain框架的模块化设计,可以灵活组合这两种技术,适应不同场景需求
#### 大模型的Zero-Shot和Few-Shot案例实战
**简介: 大模型的Zero-Shot和Few-Shot案例讲解**
* **零样本(Zero-Shot)学习**
* 模型在**没有特定任务训练数据**的情况下,直接通过预训练知识和自然语言理解能力完成任务。
* 例如,直接要求模型生成从未见过的任务结果(如翻译、分类)。
* **核心原理**:依赖大模型在预训练阶段学习到的通用知识泛化能力
* 示例
- 用户输入:“将这句话翻译成中文:Hello, how are you?”
- 模型输出:“你好”
* **少量样本(Few-Shot)学习【照猫画虎】**
- 模型通过**少量示例(通常3-5个)** 快速理解任务格式和需求,提升任务表现。
- 例如,提供几个问答示例后,模型能模仿格式回答新问题。
- **核心原理**:通过示例激发模型的上下文学习(In-Context Learning)能力,提升输出准确性和一致性。
- 示例
```
输入:“苹果 -> 水果”,输出:“香蕉 -> 水果”
输入:“汽车 -> 交通工具”,输出:“飞机 -> 交通工具”
输入:“猫 ->”,输出:“动物”
```
* 应用场景对比
| **场景** | **零样本(Zero-Shot)** | **少量样本(Few-Shot)** |
| :----------------: | :------------------------: | :------------------------------------------: |
| **适用任务复杂度** | 简单任务(如翻译、分类) | 复杂任务(如逻辑推理、特定格式生成) |
| **数据依赖** | 无需示例 | 需要少量高质量示例 |
| **输出可控性** | 较低(依赖模型预训练知识) | 较高(通过示例明确格式和规则) |
| **典型用例** | 快速原型开发、通用问答 | 领域特定任务(如法律文档解析、医疗术语抽取) |
* 案例实战
* 零样本学习案例:直接通过指令调用大模型生成答案
```python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# 零样本提示模板
zero_shot_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业翻译,将文本从{source_lang}翻译到{target_lang}"),
("human", "{text}")
])
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 链式调用
chain = zero_shot_prompt | llm
# 执行翻译(中文→英文)
response = chain.invoke({
"source_lang": "中文",
"target_lang": "英文",
"text": "今天天气不错,我要学习AI大模型开发"
})
print(response.content)
```
* 少量样本学习案例: 通过示例指导模型理解任务格式
```python
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
from langchain_openai import ChatOpenAI
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 示例数据
examples = [
{
"input": "苹果公司的总部在哪里?",
"output": "根据我的大量思考:苹果公司的总部位于美国加利福尼亚州的库比蒂诺(Cupertino)。"
},
{
"input": "OpenAI的CEO是谁?",
"output": "根据我的大量思考:OpenAI的现任CEO是萨姆·阿尔特曼(Sam Altman)。"
}
]
# 定义单条示例模板
example_template = """
输入:{input}
输出:{output}
"""
example_prompt = PromptTemplate(
template=example_template
input_variables=["input", "output"],
)
# 构建Few-Shot提示模板
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
suffix="输入:{question}\n输出:",
input_variables=["question"]
)
# 创建Chain并调用
few_shot_chain = few_shot_prompt | llm
response = few_shot_chain.invoke({"question": "亚马逊的创始人是谁?"})
print(response.content) # 输出:根据我的大量思考:亚马逊的创始人是杰夫·贝索斯(Jeff Bezos)。
```
* 总结
* **零样本 vs 少量样本**:
- 零样本依赖模型预训练知识,适合通用任务。
- 少量样本通过示例提升任务适配性,适合专业场景。
* **LangChain 实现要点**:
- **零样本**:使用 `AgentType.ZERO_SHOT_REACT_DESCRIPTION` 初始化智能体。
- **少量样本**:通过 `PromptTemplate` 设计含示例的提示词。
* **设计原则**:
- **清晰指令**:明确任务目标和输出格式。
- **示例质量**:少量样本的示例需覆盖典型场景。
#### LangChain智能体执行引擎AgentExecutor
* 需求背景:为什么需要 AgentExecutor?
* 问题:当智能体(Agent)需要执行多步操作(如多次调用工具、循环推理)时,开发者需手动处理:
* 执行循环:根据模型输出决定是否继续调用工具。
* 错误处理:捕获工具调用或模型解析中的异常。
* 流程控制:限制最大迭代次数,防止无限循环。
* 日志记录:追踪每一步的输入、输出和中间状态。
* 痛点:
* 代码冗余:重复编写循环和错误处理逻辑。
* 维护成本高:复杂任务中难以保证流程稳定性。
* 可观测性差:难以调试多步骤执行过程。
* `AgentExecutor` 介绍
* LangChain 提供的智能体执行引擎,封装了执行循环、错误处理和日志追踪,让开发者聚焦业务逻辑。
* 核心功能
| **功能** | **说明** |
| :--------------: | :----------------------------------------------------------: |
| **执行循环控制** | 自动迭代执行智能体的 `思考 -> 行动 -> 观察` 流程,直到满足终止条件。 |
| **错误处理** | 捕获工具调用异常、模型解析错误,支持自定义重试或回退逻辑。 |
| **迭代限制** | 通过 `max_iterations` 防止无限循环(如模型陷入死循环)。 |
| **日志与追踪** | 记录每一步的详细执行过程(需设置 `verbose=True`),支持集成 LangSmith。 |
| **输入输出处理** | 统一格式化最终结果,隐藏中间步骤细节(除非显式要求输出)。 |
* 关键参数
| **参数** | **作用** |
| :-------------------------: | :----------------------------------------------------------: |
| `agent` | 绑定的智能体实例(如 `create_react_agent` 的返回值)。 |
| `tools` | 智能体可调用的工具列表。 |
| `verbose` | 是否打印详细执行日志(调试时建议开启)。 |
| `max_iterations` | 最大迭代次数,防止死循环。 |
| `handle_parsing_errors` | 自动处理模型输出解析错误(如返回无效工具名),可设置为 `True` 或自定义函数。 |
| `return_intermediate_steps` | 是否返回中间步骤结果(用于调试或展示完整链路)。 |
* 使用场景:何时需要 `AgentExecutor`
* **多步骤任务**:
- 例如:先调用搜索工具获取数据,再调用计算工具处理结果
```python
# 示例:计算商品折扣价
"思考:需要先获取商品价格,再计算折扣。"
"行动1:调用 get_price(商品A)"
"观察1:价格=100元"
"行动2:调用 calculate_discount(100, 20%)"
"观察2:折扣价=80元"
```
* **工具依赖场景**:
- 例如:预订航班需要先查询航班号,再调用支付接口。
* **复杂推理任务**:
- 例如:解决数学问题需多次尝试不同公式。
* **生产环境部署**:
- 需保证服务稳定性(自动处理超时、限流等异常)
* 伪代码参考
```python
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
max_iterations=3,
handle_parsing_errors=True
)
# 执行查询(自动处理循环和错误)
response = agent_executor.invoke({"input": "北京的气温是多少华氏度?"})
print(response["output"]) # 输出:25℃ = 77℉
```
#### LangChain智能体之initialize_agent开发实战
* 需求背景
| 手工调用工具的问题 | `initialize_agent`解决方案 |
| :----------------------: | :--------------------------: |
| 需要手动编写工具选择逻辑 | 自动根据输入选择最合适的工具 |
| 缺乏错误重试机制 | 内置异常处理和重试策略 |
| 输出格式不统一 | 标准化响应格式 |
| 难以处理多工具协作场景 | 自动编排工具调用顺序 |
* 手动执行需要开发者自己处理任务分解、工具选择、参数生成、结果整合等步骤
* Agent利用大模型的推理能力自动完成这些步骤,提高了开发效率和系统的灵活性。
* 解决方案:
* langchain内置多个方法快速创建智能体,能减少手动编码的复杂性,提升系统的智能性和适应性。
* 包括自动化任务分解、动态工具选择、错误处理、结果整合等
* 主要包含以下核心方法:
* `initialize_agent`:通用初始化方法,快速构建智能体(兼容旧版)返回AgentExecutor。
* `create_react_agent`:基于 ReAct 框架的智能体,支持多步推理。
* `create_tool_calling_agent`:专为工具调用优化的智能体,支持结构化输出。
* 其他方法:如 `create_json_agent`(处理 JSON )、`create_openai_tools_agent`(适配 OpenAI 工具调用格式)

* `initialize_agent` 方法介绍
* 通过封装智能体的决策逻辑和工具调度,旧版方法,未来可能被弃用
* **适用场景**:快速原型开发、简单任务处理
* 实现
* 自动化工具选择:根据输入动态调用合适的工具。
* 流程标准化:统一处理错误、重试、结果格式化。
* 简化开发:一行代码完成智能体初始化。
* 语法与参数详解
```python
from langchain.agents import initialize_agent
def initialize_agent(
tools: Sequence[BaseTool], # 可用工具列表
llm: BaseLanguageModel, # 大模型实例
agent: Optional[AgentType] = None, # Agent类型
verbose: bool = False, # 是否显示详细过程
) -> AgentExecutor:
```
* **关键参数说明**:`agent_type`
| AgentType | 适用场景 | 特点 |
| :-----------------------------------------: | :------------------------------------: | :-----------------------: |
| ZERO_SHOT_REACT_DESCRIPTION | 通用任务处理 | 基于ReAct框架,零样本学习 |
| STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION | 结构化输入输出 | 支持复杂参数类型 |
| CONVERSATIONAL_REACT_DESCRIPTION | 多轮对话场景 | 保留对话历史上下文 |
| SELF_ASK_WITH_SEARCH | 结合自问自答和搜索工具,适合问答场景。 | 自动生成中间问题并验证 |
* 案例实战
```python
from langchain.agents import initialize_agent, AgentType
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langchain.agents import initialize_agent
from langchain_community.utilities import SearchApiAPIWrapper
import os
# 设置SearchAPI的API密钥
os.environ["SEARCHAPI_API_KEY"] = "qQBHMQo4Rk8SihmpJjCs7fML"
# 实例化SearchApiAPIWrapper对象,用于调用搜索API
search = SearchApiAPIWrapper()
#定义搜索工具
@tool("web_search", return_direct=True)
def web_search(query: str) -> str:
"""
当需要获取实时信息、最新事件或未知领域知识时使用,输入应为搜索关键词
"""
try:
results = search.results(query) # 获取前3条结果
return "\n\n".join([
f"来源:{res['title']}\n内容:{res['snippet']}"
for res in results['organic_results']
])
except Exception as e:
return f"搜索失败:{str(e)}"
# 使用 @tool 定义进行数学计算的工具
@tool("math_calculator", return_direct=True)
def math_calculator(expression: str) -> str:
"""用于进行数学计算,输入应该是一个有效的数学表达式,如 '2 + 3' 或 '5 * 4'"""
try:
result = eval(expression)
return str(result)
except Exception as e:
return f"计算出错: {str(e)}"
#不同大模型效果不一样,有些会报错,不支持多个输入参数的工具
@tool("multiply")
def multiply(a: int, b: int) -> int:
"""
把传递的两个参数相乘
"""
return a * b
# 创建工具列表
tools = [math_calculator,web_search]
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 使用 initialize_agent 创建代理
agent_chain = initialize_agent(
tools=tools, # 使用的工具列表
llm=llm, # 使用的语言模型
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, # 指定代理类型
verbose=True, # 打开详细日志,便于查看代理的思考过程
handle_parsing_errors=True #自动处理解析错误,提高Agent的稳定性。
)
#打印对应的智能体,更清晰底层逻辑
print(agent_chain.agent.llm_chain)
print(agent_chain.agent.llm_chain.prompt.template)
print(agent_chain.agent.llm_chain.prompt.input_variables)
# 测试代理
# 需求 1: 计算 5 乘以 6 的结果
result1 = agent_chain.invoke({"input":"计算 5 乘以 6 的结果"})
print("计算 5 乘以 6 的结果:", result1)
# 需求 2: 获取当前日期
#result2 = agent_chain.run("腾讯最新的股价")
#result2 = agent_chain.invoke({"input":"腾讯最新的股价"})
#print("腾讯最新的股价:", result2
```
#### 个人AI助理智能体之tool_calling_agent实战
* `create_tool_calling_agent `方法介绍
* 是 LangChain 0.3 新增的智能体创建方法, 要求模型直接返回工具调用参数(如 JSON 格式),减少中间解析错误。
* **结构化工具调用**:显式调用工具并传递结构化参数(支持复杂数据类型)
* **多步骤任务处理**:适合需要按顺序调用多个工具的场景
* **精准控制**:通过自定义 Prompt 模板指导 Agent 行为
* 方法参数
```python
from langchain.agents import create_tool_calling_agent
agent = create_tool_calling_agent(
llm: BaseLanguageModel, # 语言模型实例(需支持结构化输出)
tools: List[BaseTool], # 工具列表
prompt: ChatPromptTemplate # 提示模板(需明确工具调用规则)
)
```
| 参数 | 类型 | 必填 | 说明 |
| :----: | :----------------: | :--: | :----------------------------------------------------------: |
| llm | BaseLanguageModel | 是 | 支持工具调用的模型(如 `ChatOpenAI`) |
| tools | Sequence[BaseTool] | 是 | 工具列表,每个工具需用 `@tool` 装饰器定义 |
| prompt | ChatPromptTemplate | 是 | 控制 Agent 行为的提示模板,需包含 `tools` 和 `tool_names` 的占位符 |
* 适用场景
* API 集成:如调用天气查询、支付接口等需要严格参数格式的场景。
* 多工具协作:模型需根据输入动态选择多个工具并传递参数。
* 高精度任务:如金融计算、医疗诊断等容错率低的场景。
* 案例实战: 个人AI助理智能体
```python
from langchain_openai import ChatOpenAI
from langchain.agents import create_tool_calling_agent, Tool, AgentExecutor
from langchain.tools import tool
from datetime import datetime
from langchain_core.prompts import ChatPromptTemplate
# 定义获取当前日期的工具函数
@tool
def get_current_date() -> str:
"""获取当前日期"""
formatted_date = datetime.now().strftime("%Y-%m-%d")
return f"The current date is {formatted_date}"
# 定义搜索航班的工具函数
@tool
def search_flights(from_city: str, to_city: str, date: str) -> str:
"""根据城市和日期搜索可用航班"""
return f"找到航班:{from_city} -> {to_city},日期:{date},价格:¥1200"
# 定义预订航班的工具函数
@tool
def book_flight(flight_id: str, user: str) -> str:
"""预订指定航班"""
return f"用户 {user} 成功预订航班 {flight_id}"
# 定义获取股票价格的函数
def get_stock_price(symbol) -> str:
return f"The price of {symbol} is $100."
# 创建工具列表,包括获取股票价格、搜索航班、预订航班和获取当前日期的工具
tools = [
Tool(
name="get_stock_price",
func=get_stock_price,
description="获取指定的股票价格"
),
search_flights,
book_flight,
get_current_date
]
# 初始化大模型
llm = ChatOpenAI(
model_name="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 定义聊天提示模板
prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个AI助手,必要时可以调用工具回复问题"),
("human", "我叫老王,经常出差,身份证号是 4414231993210223213332"),
#("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
]
)
# 创建代理
agent = create_tool_calling_agent(llm, tools, prompt)
# 初始化代理执行器 , verbose=True可以看到思考明细, return_intermediate_steps返回中间结果
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True,return_intermediate_steps=True)
# 运行代理并获取结果
result = agent_executor.invoke({"input": "苹果股票是多少?根据我的行程,帮我查询下明天的航班,从广州去北京,并定机票"})
print(f"最终结果:{result}"
```
#### 旅游规划智能体之react_agent实战
* **ReAct 框架**:
* **Re**asoning + **Act**ing 是一种结合推理和行动的智能体设计模式
* 由以下步骤循环组成:
* **推理(Reason)**:分析当前状态,决定下一步行动(如调用工具或直接回答)。
* **行动(Act)**:执行选定的操作(如调用工具、查询数据)。
* **观察(Observe)**:获取行动结果,更新状态,进入下一轮循环。
```
[Thought] <-- 推理阶段(分析当前状况)
[Action] <-- 行动阶段(调用工具)
[Observation] <-- 环境反馈(工具返回结果)
```
* **`create_react_agent`**
* LangChain 提供的专用方法,用于创建基于 ReAct 框架的智能体
* 适合需要**多步动态决策**的任务(如复杂问答、数学问题求解)。
* 方法参数与语法
```python
from langchain.agents import create_react_agent
agent = create_react_agent(
llm: BaseLanguageModel, # 必须支持 ReAct 格式
tools: Sequence[BaseTool],# 工具集(需详细文档)
prompt: ChatPromptTemplate # 必须包含 ReAct 特殊标记
) -> Runnable
```
* 参考使用的提示模板结构
```python
# 官方推荐模板(从 hub 获取)
prompt = hub.pull("hwchase17/react")
# 模板核心内容示例:
"""
Answer the following questions using the following tools:
{tools}
Use the following format:
Question: the input question
Thought: 需要始终进行的思考过程
Action: 要执行的动作,必须是 [{tool_names}] 之一
Action Input: 动作的输入
Observation: 动作的结果
...(重复思考/行动循环)
Final Answer: 最终答案
"""
```
* 与其它方法的对比选型
| 场景特征 | 推荐方法 | 原因说明 |
| :--------------: | :-----------------------: | :--------------------: |
| 需要逐步推理 | create_react_agent | 显式思考链支持复杂逻辑 |
| **严格参数传递** | create_tool_calling_agent | 结构化输入更可靠 |
| 快速简单任务 | initialize_agent | 开箱即用最简配置 |
| 需要自我修正 | create_react_agent | 错误后可重新推理 |
| 与人类协作调试 | create_react_agent | 完整思考链易读性好 |
* 适用场景
* 多步骤任务:例如:“查询北京的气温,并计算对应的华氏度。”
* 动态工具选择:根据中间结果决定下一步调用哪个工具。
* 复杂推理任务:例如:“如果明天下雨,推荐室内活动;否则推荐户外活动。
* 案例实战:智能推荐助手
```python
from langchain_openai import ChatOpenAI
from langchain.tools import tool
from langchain_community.utilities import SearchApiAPIWrapper
import os
from langchain_core.prompts import PromptTemplate
from langchain.agents import create_react_agent, AgentExecutor
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气"""
# 模拟数据
weather_data = {
"北京": "晴,25℃",
"上海": "雨,20℃",
"广州": "多云,28℃"
}
return weather_data.get(city, "暂不支持该城市")
@tool
def recommend_activity(weather: str) -> str:
"""根据天气推荐活动"""
if "雨" in weather:
return "推荐室内活动:博物馆参观。"
elif "晴" in weather:
return "推荐户外活动:公园骑行。"
else:
return "推荐一般活动:城市观光。"
# 定义搜索工具
os.environ["SEARCHAPI_API_KEY"] = "qQBHMQo4Rk8SihmpJjCs7fML"
@tool("web_search", return_direct=True)
def web_search(query: str) -> str:
"""
当需要获取实时信息、最新事件或未知领域知识时使用,输入应为搜索关键词
"""
try:
search = SearchApiAPIWrapper()
results = search.results(query) # 获取前3条结果
return "\n\n".join([
f"来源:{res['title']}\n内容:{res['snippet']}"
for res in results['organic_results']
])
except Exception as e:
return f"搜索失败:{str(e)}"
tools = [get_weather, recommend_activity, web_search]
# 初始化大模型
llm = ChatOpenAI(
model_name="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 使用 LangChain 预定义的 ReAct 提示模板,https://smith.langchain.com/hub/hwchase17/react
#from langchain import hub
#prompt = hub.pull("hwchase17/react")
# 模板内容示例:
template = """
Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}
"""
prompt = PromptTemplate.from_template(template)
# 创建 ReAct 智能体
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True, # 打印详细执行过程
max_iterations=3, # 限制最大迭代次数,
handle_parsing_errors=lambda _: "请检查输入格式", # 错误处理
return_intermediate_steps=True # 保留中间步骤
)
# 执行查询
response = agent_executor.invoke({
"input": "我在北京玩3天,根据天气推荐活动, 顺便查询腾讯的股价是多少"
})
print(response)
```
#### LLM综合实战-文档网络智能问答助手开发
* 需求说明
* 智能体核心功能
* **多模态知识整合**
* 深度结合 **Milvus 向量数据库** 的本地文档知识与 **实时网络搜索能力**,实现对复杂问题的分步解析与回答。
* 支持同时处理 **结构化文档问答**(如技术框架详解)和 **实时信息查询**(如股价、日期等动态数据)。
* **智能工具决策**
- 自动判断问题类型:
- **文档相关问题**(如 "什么是Milvus?")调用 **Milvus 向量检索工具**,精准匹配本地知识库内容。
- **实时信息需求**(如 "腾讯股价")触发 **Web 搜索工具**,获取最新数据。
- 支持 **多问题串联回答**,例如一次性处理包含技术解释、时间查询、股价查询的复合任务。
* **交互式回答增强**
- 通过 **LangChain Agent 框架** 的动态决策流程,展示问题拆解与工具调用的全过程(如中间思考步骤)。
- 提供 **结构化输出**,清晰标注每个答案的来源(如 "来自 Milvus 文档" 或 "来自实时搜索")。
* 技术亮点:
* 工具链集成:无缝融合 Milvus 向量检索 + 网络搜索API + 大模型推理(如 Qwen-Plus)。
* 可视化流程:通过 LangSmith 追踪 Agent 的决策路径
* 自定义提示模板:支持灵活调整 Agent 的行为逻辑(如切换 create_tool_calling_agent 或 create_react_agent 模式)。
* 应用场景
* 技术文档问答:快速解析 Milvus 版本、功能、与 LangChain 的集成方法。
* 实时数据查询:动态获取股票价格、当前日期等时效性信息。
* 多步骤问题处理:如 "解释Milvus的工作原理,同时比较其与Faiss的优劣,最后给出GitHub最新教程链接"。
* 功能效果演示

* 编码实战
```python
from langchain_community.utilities import SearchApiAPIWrapper
from langchain_core.tools import tool
from langchain.agents import AgentExecutor, create_tool_calling_agent,create_react_agent
from langchain.tools.retriever import create_retriever_tool
from langchain_milvus import Milvus
from langchain.prompts import PromptTemplate,ChatPromptTemplate
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_openai import ChatOpenAI
import os
from pydantic import Field
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "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"
os.environ["LANGSMITH_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGSMITH_PROJECT"] = "agent_v1"
# 配置搜索工具
os.environ["SEARCHAPI_API_KEY"] = "qQBHMQo4Rk8SihmpJjCs7fML"
search = SearchApiAPIWrapper()
@tool("web_search")
def web_search(query: str) -> str:
"""当需要获取实时信息、最新事件或未知领域知识时使用,输入应为搜索关键词"""
try:
results = search.results(query) # 获取前3条结果
return "\n\n".join([
f"来源:{res['title']}\n内容:{res['snippet']}"
for res in results['organic_results']
])
except Exception as e:
return f"搜索失败:{str(e)}"
#初始化嵌入模型
embeddings = DashScopeEmbeddings(
model="text-embedding-v2", # 第二代通用模型
max_retries=3,
dashscope_api_key="sk-005c3c25f6d042848b29d75f2f020f08"
)
vector_store = Milvus(
embeddings,
connection_args={"uri": "http://47.119.128.20:19530"},
collection_name='doc_qa_db',
)
#获取检索器
retriever = vector_store.as_retriever()
retriever_tool = create_retriever_tool(
retriever,
"milvus_retriever",
"搜索有关 Milvus 的信息。对于任何有关 Milvus 的问题,你必须使用这个工具!",
)
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
tools = [web_search, retriever_tool]
# #构建提示模板 ,采用create_tool_calling_agent的提示词模版
```
* 编码实战
```python
# #构建提示模板 ,采用create_tool_calling_agent的提示词模版
# prompt = ChatPromptTemplate.from_messages([
# ("system", "你是一个AI文档助手,拥有多个工具,必要时可以利用工具来回答问题。"),
# ("user", "{input}"),
# ("placeholder", "{agent_scratchpad}")
# ])
# # 创建Agent执行器
# agent = create_tool_calling_agent(llm, tools,prompt)
#构建提示模板 ,采用create_react_agent的提示词模版
prompt = PromptTemplate.from_template('''Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}''')
agent = create_react_agent(llm, tools,prompt)
#创建Agent执行器
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True,handle_parsing_errors=True,return_intermediate_steps=True)
def run_question(question: str):
print(f"\n问题:{question}")
result = agent_executor.invoke({"input": question})
print(f"\nllm-result:{result}")
print(f"\n答案:{result['output']}\n{'='*50}")
```
* 案例测试
* 提问输入问题
```
run_question("中文回答下面3个问题:第一个:什么是Milvus,最新的版本是多少,如何整合LangChain框架,其与Faiss的优劣,最后给出GitHub最新教程链接; 第二个:现在的日期是几号;第三个:腾讯的股价是多少")
```
* LangSmith调用链路分析

* 切换不同创建agent方法和提示词进行测试
* 打印输出中间思考步骤
* 使用 AgentExecutor 的 `return_intermediate_steps` 参数
```python
#print("最终结果:", result["output"])
#print("中间步骤:", result["intermediate_steps"])
def run_question(question: str):
print(f"\n问题:{question}")
result = agent_executor.invoke({"input": question})
print(f"\nllm-result:{result}")
print(f"\n答案:{result['output']}\n{'='*50}")
# 输出完整执行轨迹
print("=== 完整执行链 ===")
for step in result["intermediate_steps"]:
print(f"Action: {step[0].tool}")
print(f"Input: {step[0].tool_input}")
print(f"Observation: {step[1]}\n")
```
* 总结说明
* 在AI智能体开发中,不同的任务需要不同的交互逻辑,因此需要不同类型的智能体来高效处理不同任务。
* 例如:
- 有些任务需要智能体先“思考”再行动(如解数学题)。
- 有些任务需要直接调用工具完成(如查天气、调用计算器)
* **关键选择点**:
* 任务是否需要分解步骤 → 选`create_react_agent`;
* 任务是否单一明确 → 选`create_tool_calling_agent`。
* **进阶技巧**:
* 混合使用两种智能体(如先用React分解任务,再调用Tool-Calling执行子任务)
* 共同点
- 均基于大模型(如LLM大模型)驱动。
- 依赖预定义的工具集(Tools)。
* **底层关系**:
* `create_tool_calling_agent` 可视为 `create_react_agent` 的简化版(跳过显式推理步骤)。
### 老王忘不了的痛-大模型存储记忆实战
#### LLM大模型存储记忆功能介绍和应用场景
* 需求背景:为什么需要存储记忆功能?
* 长对话上下文遗忘问题
```
# 示例:第二次提问时模型已“失忆”
user_input1 = "我叫张三"
ai_response1 = "你好张三!"
user_input2 = "我叫什么名字?"
ai_response2 = "抱歉,我不知道您的名字。" # 期望回答“张三”
```
* 大模型(如 GPT-4)单次对话的上下文窗口有限(通常为 4k-128k tokens),导致多轮对话中容易丢失早期信息。
* 例如,用户询问 “如何制作蛋糕” 后接着问 “需要烤箱吗”
* 模型若无法记住前一轮对话,可能回答 “需要烤箱” 但忘记蛋糕配方的关键步骤。
* 个性化服务与用户偏好记忆
* 在客服、教育、医疗等场景中,用户需要模型记住个人信息(如姓名、病史)或历史行为(如订单记录、学习进度)。
* 例如,医疗助手需根据患者的历史诊断结果提供建议。
* 复杂任务的状态管理
* 涉及多步骤的任务(如旅行规划、代码调试)需要模型跟踪中间状态。
* 例如,用户要求 “规划上海到北京的三天行程”,模型需记住已推荐的景点、交通方式等。
* LangChain方法
* 短期记忆:通过 Memory 模块存储对话历史,确保模型在多轮交互中保持连贯
* 长期记忆:将用户数据存储在外部数据库或向量数据库(如 Milvus、Pinecone),实现跨会话的长期记忆
* 记忆功能的核心设计
* 两种类型
| 维度 | 短期记忆 | 长期记忆 |
| :------------: | :----------------------------------: | :-----------------------------------------: |
| **存储方式** | 内存缓存, 模型输入中的历史消息 | 数据库持久化存储, 向量库/文件 |
| **容量限制** | 受上下文窗口限制(如4k-128k tokens) | 理论上无上限 |
| **访问速度** | 毫秒级 | 百毫秒级(依赖检索算法) |
| **典型应用** | 对话连贯性保持, 即时对话、单次任务 | 个性化服务、用户画像构建,跨会话记忆、知识库 |
| **实现复杂度** | 低 | 高 |
| **成本** | 低(无额外存储开销) | 中高(需维护存储系统) |
| **示例** | 聊天中记住前3轮对话 | 用户资料、项目历史记录 |
* 记忆的实现方式
* **短期记忆**:通过拼接历史消息实现(`[用户: 你好][AI: 你好!]`)。
* 长期记忆
- **结构化存储**:用数据库记录关键信息(如用户喜好)。
- **向量化存储**:将文本转为向量存入向量库(如Milvus)。
- **混合模式**:短期记忆 + 长期检索增强(RAG)
* 应用场景与案例
* 个性化教育助手 (伪代码)
```python
from langchain.memory import VectorStoreRetrieverMemory
# 初始化记忆系统
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
memory = VectorStoreRetrieverMemory(retriever=retriever)
# 运行示例
memory.save_context(
{"input": "我的学习目标是掌握微积分"},
{"output": "目标已记录,将推荐相关资源"}
)
memory.save_context(
{"input": "请解释洛必达法则"},
{"output": f"{explanation} 已添加到你的学习清单"}
)
# 后续对话
query = "根据我的目标推荐学习资料"
relevant_memories = memory.load_memory_variables({"query": query})
# 返回微积分相关记忆
```
* 电商推荐引擎
```python
from langchain.retrievers import TimeWeightedVectorStoreRetriever
# 带时间权重的记忆系统
retriever = TimeWeightedVectorStoreRetriever(
vectorstore=vectorstore,
decay_rate=0.95, # 记忆衰减系数
k=5
)
# 记忆示例数据
retriever.add_documents([
Document(page_content="用户2026-12-01购买手机", metadata={"type": "purchase"}),
Document(page_content="用户2027-03-15浏览笔记本电脑", metadata={"type": "browse"}),
Document(page_content="用户2027-06-20退货耳机", metadata={"type": "return"})
])
# 获取最新加权记忆
relevant_memories = retriever.get_relevant_documents("用户兴趣分析")
```
* 大模型长短期记忆选择决策树
* 基础用法:短期对话记忆
* 进阶用法:长期记忆 + 向量数据库
* 高级用法:多用户隔离记忆(会话级)

#### LLM存储记忆功能之BaseChatMemory实战
* `BaseChatMemory` 介绍
* 是 LangChain 中所有**聊天型记忆模块的基类**,定义了记忆存储和检索的通用接口。
```
from langchain.memory.chat_memory import BaseChatMemory
```
* 可通过继承此类实现自定义记忆逻辑(如过滤敏感信息、动态清理策略)
* 注意:部分API虽然过期,但也需要知道核心思想, 新旧我们都有讲
* 核心作用
* **标准化接口**:统一 `save_context()`(保存上下文)和 `load_memory_variables()`(加载记忆)方法。
* **状态管理**:维护对话历史(`chat_memory` 属性),支持消息的增删改查。
* **扩展性**:允许开发者覆盖默认行为(如自定义存储格式、加密数据)
* 关键属性
* `chat_memory`
* 存储对话消息的容器,类型为 ChatMessageHistory,包含 messages 列表
* 每条消息为 BaseMessage 对象,如 HumanMessage、AIMessage
* 核心方法
* `save_context` 保存用户输入和模型输出到 chat_memory。
```
memory.save_context({"input": "你好"}, {"output": "你好!有什么可以帮您?"})
# 等价于:
memory.chat_memory.add_user_message("你好")
memory.chat_memory.add_ai_message("你好!有什么可以帮您?")
```
* `load_memory_variables` 返回当前记忆内容(通常为 {"history": "对话历史字符串"}
```
variables = memory.load_memory_variables({})
print(variables["history"]) # 输出:Human: 你好\nAI: 你好!有什么可以帮您?
```
* `clear()` 清空所有记忆
```
#调用
chat_memory.clear()
```
* `BaseChatMemory`的子类
| **类名** | **说明** |
| :------------------------------: | :----------------------------------------------------------: |
| `ConversationBufferMemory` | 直接存储原始对话历史(继承 `BaseChatMemory`)。 |
| `ConversationBufferWindowMemory` | 仅保留最近 N 轮对话(通过 `k` 参数控制,覆盖消息存储逻辑)。 |
| `ConversationSummaryMemory` | 存储模型生成的对话摘要(覆盖 `load_memory_variables` 生成摘要)。 |
| 自定义类 | 继承 `BaseChatMemory`,按需重写 `save_context` 或 `load_memory_variables` |
* 案例实战
* `ConversationBufferMemory`
```python
from langchain.memory import ConversationBufferMemory
# 初始化对话缓冲记忆
memory = ConversationBufferMemory(
memory_key="chat_history", #存储进去的Key,和获取的时候需要保持一致
return_messages=True,
)
# 添加用户消息和 AI 消息
memory.chat_memory.add_user_message("你的名字是什么")
memory.chat_memory.add_ai_message("二当家")
# 加载记忆内容
memory_variables = memory.load_memory_variables({})
print("记忆内容:", memory_variables)
```
* `ConversationBufferWindowMemory `
* 滑动窗口式对话记忆, 此类在对话记录中引入窗口机制,仅保存最近的 `k` 条对话历史。
* **k 参数**:定义窗口大小,表示最多保留的对话记录条数, 适合长对话或对历史要求不高的应用。
```python
from langchain.memory import ConversationBufferWindowMemory
# 初始化窗口记忆,设置窗口大小为 2
memory = ConversationBufferWindowMemory(k=2, memory_key="chat_history")
# 保存一些消息
memory.save_context({"input": "你叫什么名字"}, {"output": "你好,我是三当家"})
memory.save_context({"input": "小滴课堂怎么样"}, {"output": "小滴课堂是适合初学者的计算机学习平台"})
memory.save_context({"input": "好的,我去了解下"}, {"output": "希望对你有帮助!"})
# 获取窗口内的对话历史
window_history = memory.load_memory_variables({})
print("当前窗口内的对话历史:", window_history)
```
#### 【面试题】LLM存储优化-大量长对话如何解决
* 面试官
* 传统对话系统每次交互独立,模型无法感知历史对话内容,如何解决?
* 长对话超出模型的Token处理能力,导致信息截断或性能下降,如何解决?
* **大模型场景题目的需求背景【重要】**
* **大模型的上下文限制**
* 大语言模型(如GPT-4、DeepSeek等虽然能处理复杂的对话任务
* 但其输入长度存在限制(如Token上限),无法直接存储长期对话历史
* **对话连贯性需求**
* 实际应用中(如客服系统、智能助手),用户问题常依赖上下文。
* 例如,用户先问“人工智能的定义”,再要求“详细说明”,模型需基于历史回答才能生成合理响应
* 资源优化需求
* 直接存储完整对话历史会占用大量内存或数据库资源,且频繁传递完整上下文会增加计算成本。
| 问题类型 | 具体表现 | 后果 |
| :------: | :----------------------------: | :------------------------: |
| 技术限制 | 长对话超出模型上下文窗口 | 关键信息丢失,回答质量下降 |
| 效率瓶颈 | 全量历史数据检索耗时(>500ms) | 响应延迟影响用户体验 |
| 业务需求 | 需快速定位历史问题关键点 | 客服质检、争议溯源效率低 |
| 合规风险 | 存储用户敏感对话原文 | 数据泄露风险增加 |
* 面试回答要点
* **核心目标**
* 通过摘要存储实现对话上下文的长期维护,解决大模型Token限制与对话连贯性问题。
* 技术实现
* 记忆模块:LangChain提供ConversationBufferMemory(完整历史)和ConversationSummaryMemory(摘要存储)等
* 摘要生成:调用LLM对历史对话生成摘要,后续交互仅传递摘要而非完整历史
* **优势**
- 减少Token消耗,适配模型输入限制。
- 提升对话系统的长期记忆能力。
- 支持分布式存储(如MongoDB、Milvus),扩展性强
* `ConversationSummaryMemory`
* 通过模型生成对话的摘要,帮助保留重要信息,而不保存完整历史,适合需要长期记忆的场景。
* 原理就是提示词,让AI帮出来摘要,而且可以定制
```python
请将以下对话压缩为简短摘要,保留用户需求和关键结果:
对话历史:
{history}
当前对话:
Human: {input}
AI: {output}
摘要:
"""
```
* **load_memory_variables**:返回当前会话的摘要信息。
```python
from langchain.memory import ConversationSummaryMemory
from langchain_openai import ChatOpenAI
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 初始化摘要记忆
memory = ConversationSummaryMemory(llm=llm)
# 模拟对话
memory.save_context({"input": "你叫什么名字?"}, {"output": "你好,我是三当家。"})
memory.save_context({"input": "你能告诉我机器学习吗?"}, {"output": "机器学习是人工智能的一个分支。"})
# 获取摘要
summary = memory.load_memory_variables({})
print("当前对话摘要:", summary)
```
#### 基于LangChain的带摘要存储对话系统实战
* 实战案例
* 基于LangChain的带摘要存储对话系统
```python
from langchain.memory import ConversationSummaryMemory
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 初始化模型和记忆模块
memory = ConversationSummaryMemory(
llm=llm,
memory_key="chat_history", # 与prompt中的变量名一致
return_messages=True
)
# 定义提示模板(必须包含chat_history占位符)
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个助手,需基于对话历史回答问题。当前摘要:{chat_history}"),
("human", "{input}")
])
# # 创建链并绑定记忆模块
# chain = LLMChain(
# llm=llm,
# prompt=prompt,
# memory=memory,
# verbose=True # 调试时查看详细流程
# )
# 定义LCEL链式流程
chain = (
# 注入输入和记忆
RunnablePassthrough.assign(
chat_history=lambda _: memory.load_memory_variables({})["chat_history"]
)
| prompt # 将输入传递给提示模板
| llm # 调用模型
| StrOutputParser() # 解析模型输出为字符串
)
# 模拟多轮对话
user_inputs = [
"人工智能的定义是什么?",
"小滴课堂上面有什么课程可以学习",
"人工智能它在医疗领域有哪些应用?"
]
for query in user_inputs:
# 执行对话
response = chain.invoke({"input": query})
# 打印结果
print(f"\n用户:{query}")
print(f"AI:{response}")
#使用 LLMChain 而非原始LCEL链时,每次 invoke() 会自动调用 memory.save_context()。
#手动调用场景需显式保存:
memory.save_context({"input": query}, {"output": response})
print("当前记忆摘要:", memory.load_memory_variables({})["chat_history"])
```
* 示例输出
```markdown
用户:人工智能的定义是什么?
AI:人工智能是模拟人类智能的计算机系统...
当前记忆摘要: 用户询问人工智能的定义,助手解释了其核心是通过算法模拟人类认知能力。
用户:小滴课堂上面有什么课程可以学习
AI:如果“小滴课堂”是一个特定的学习平台,建议直接查询该平台提供的课程列表以获取最新信息
当前记忆摘要: 首先询问了人工智能的定义,AI解释了人工智能是计算机科学的一个分支,随后,人类问到“小滴课堂”上有什么课程可以学习
用户:它在医疗领域有哪些应用?
AI:在医疗影像分析、药物研发...
当前记忆摘要: 用户问及医疗应用,助手提到影像分析、药物研发和个性化诊疗是主要方向。
```
* 关键步骤讲解
* **链式组合 (`|` 操作符)**
通过管道符连接多个组件:
- `RunnablePassthrough`:传递原始输入
- `prompt`:格式化提示词
- `llm`:调用大模型
- `StrOutputParser`:解析输出为字符串
* **记忆管理**
- `memory.load_memory_variables()`:加载当前摘要到提示词
- `memory.save_context()`:手动保存对话记录(LCEL需要显式保存)
* **变量绑定**
使用 `RunnablePassthrough.assign` 动态注入 `chat_history` 变量,确保与提示模板匹配
* 注意: 变量名一致性
- `memory_key` 必须与提示模板中的变量名一致(示例中均为 `chat_history`)。
- 错误示例:如果模板用 `{summary}` 但 `memory_key` 设为 `history`,会导致变量未注入
* LCEL与 LLMChain 的核心区别
| 特性 | LCEL 实现 | LLMChain 实现 |
| :------------- | :--------------------------- | :------------------ |
| **记忆管理** | 需手动调用 `save_context` | 自动保存上下文 |
| **链式组合** | 支持任意步骤组合 | 固定结构 |
| **调试灵活性** | 可插入日志中间件 | 依赖 `verbose=True` |
| **扩展性** | 容易添加路由、分支等复杂逻辑 | 适合简单线性流程 |
#### MessagesPlaceholder和多轮AI翻译助手实战
* `MessagesPlaceholder `介绍
* 是 LangChain 中用于在 **聊天型提示模板(ChatPromptTemplate)** 中动态插入消息列表的占位符。
* 允许开发者将历史对话记录、系统消息等结构化地嵌入到 Prompt 中,从而支持多轮对话场景的上下文管理
* 适用场景
* 多角色对话:在聊天机器人中,区分系统指令、用户输入和AI响应。
* 历史对话注入:将历史消息作为上下文传递给模型,确保对话连贯性。
* 模块化Prompt设计:灵活组合不同来源的消息(如系统消息、检索结果等)
* 与普通PromptTemplate的区别
* PromptTemplate:用于单字符串模板,适合简单问答。
* ChatPromptTemplate:专为多角色消息设计,必须使用 MessagesPlaceholder 处理消息列表
* 例如
```python
ChatPromptTemplate.from_messages([
("system", "你是一个助手"),
MessagesPlaceholder(variable_name="history"),
("human", "{input}")
])
```
* 核心功能对比
| 功能特性 | MessagesPlaceholder | 传统列表存储 |
| :--------------: | :--------------------------: | :----------------: |
| **动态插入** | ✅ 支持运行时动态调整消息顺序 | ❌ 固定顺序 |
| **消息类型感知** | ✅ 区分 system/human/AI | ❌ 统一存储为字符串 |
| **内存集成** | ✅ 自动与Memory组件同步 | ❌ 需手动管理 |
| **结构化操作** | ✅ 支持消息元数据 | ❌ 纯文本存储 |
* 使用步骤
* 定义模板与占位符
* 在 ChatPromptTemplate 中通过 MessagesPlaceholder 声明占位位置
* **并指定变量名(需与 Memory 模块的 memory_key 一致)**
```python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个翻译助手"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}")
])
```
* 绑定记忆模块
* 使用 ConversationBufferMemory 或 ConversationSummaryMemory 存储对话历史,
* 并确保 memory_key 与占位符变量名匹配
```python
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
memory_key="chat_history", # 必须与MessagesPlaceholder的variable_name一致
return_messages=True # 返回消息对象而非字符串
)
```
* 链式调用与历史管理
* 在链式调用中自动注入历史消息,需使用 LLMChain 或 `RunnableWithMessageHistory`
```python
from langchain.chains import LLMChain
from langchain_community.chat_models import ChatOpenAI
llm = ChatOpenAI()
chain = LLMChain(llm=llm, prompt=prompt, memory=memory)
```
* 案例测试
```python
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_models import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains import LLMChain
from langchain_openai import ChatOpenAI
# 1. 初始化模型与记忆模块
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# 2. 定义包含MessagesPlaceholder的Prompt模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个翻译助手,需参考历史对话优化翻译结果。"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "请翻译以下内容:{input}")
])
# 3. 创建链并绑定记忆
chain = LLMChain(llm=llm, prompt=prompt, memory=memory)
# 4. 模拟多轮对话
user_inputs = [
"Translate 'Hello' to Chinese",
"Use the translation in a sentence",
"Now translate 'Goodbye'"
]
for query in user_inputs:
response = chain.invoke({"input": query})
print(f"用户:{query}")
print(f"AI:{response['text']}\n")
print("当前对话历史:", memory.load_memory_variables({})["chat_history"], "\n")
```
* LCEL表达式案例
```python
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_models import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains import LLMChain
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# 1. 初始化模型与记忆模块
# 初始化大模型
llm = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# 2. 定义包含MessagesPlaceholder的Prompt模板
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个翻译助手,需参考历史对话优化翻译结果。"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "请翻译以下内容:{input}")
])
# 3. 创建链并绑定记忆
#chain = LLMChain(llm=llm, prompt=prompt, memory=memory)
#定义LECL表达式,构建chain
chain = (
RunnablePassthrough.assign(
chat_history = lambda _ : memory.load_memory_variables({})['chat_history']
)
| prompt
| llm
| StrOutputParser()
)
# 4. 模拟多轮对话
user_inputs = [
"Translate 'Hello' to Chinese",
"Use the translation in a sentence",
"Now translate 'Goodbye'"
]
for query in user_inputs:
response = chain.invoke({"input": query})
print(f"用户:{query}")
print(f"AI:{response}\n")
memory.save_context({"input": query}, {"output": response})
print("当前对话历史:", memory.load_memory_variables({})["chat_history"], "\n")
```
#### LLM复杂记忆存储-多会话隔离案例实战
* 背景与需求
* 当多个会话同时与对话系统交互时,需确保每个会话的对话历史独立存储,避免以下问题:
- **数据混淆**:会话A的对话内容泄露给会话B。
- **上下文丢失**:不同会话的对话历史互相覆盖。
- **隐私安全**:敏感信息因隔离不当导致泄露。
* **典型场景**
- **客服系统**:不同会话咨询需独立记录。
- **教育应用**:每个学生与AI助教的对话需单独存档。
- **医疗助手**:患者健康信息需严格隔离。
* **解决方案:为每个会话分配唯一ID,通过ID隔离的对话历史。**
* `RunnableWithMessageHistory` 介绍
* 是 LangChain 中用于**动态管理多用户对话历史**的高级封装类,主要解决以下问题
* **会话隔离**:为不同用户/会话(通过 `session_id`)独立存储对话历史。
* **记忆注入**:自动将历史消息注入到链的每次执行中,无需手动传递。
* **灵活存储**:支持自定义历史存储后端(内存、数据库、Redis 等)。
* 核心参数
```
from langchain_core.runnables.history import RunnableWithMessageHistory
```
| 参数 | 类型 | 必填 | 说明 |
| :--------------------: | :-------------------------------------: | :--: | :-------------------------------------: |
| `runnable` | Runnable | 是 | 基础处理链(需支持消息历史输入) |
| `get_session_history` | Callable[[str], BaseChatMessageHistory] | 是 | 根据session_id获取历史存储实例的函数 |
| `input_messages_key` | str | 否 | 输入消息在字典中的键名(默认"input") |
| `history_messages_key` | str | 否 | 历史消息在字典中的键名(默认"history") |
* 使用场景
* **多用户对话系统**:为每个用户维护独立的对话历史(如客服系统)。
* **长期会话管理**:结合数据库存储历史,支持跨设备会话恢复。
* 案例实战
```python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai.chat_models import ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
# 存储会话历史的字典,可以改其他存储结构
store = {}
# 获取会话历史的函数 如果给定的session_id不在store中,则为其创建一个新的ChatMessageHistory实例
def get_session_history(session_id):
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
# 初始化大模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 构建聊天提示模板,包含系统消息、历史消息占位符和人类消息
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是一个小滴课堂AI助手,擅长能力{ability}。用30个字以内回答",
),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
# 创建Runnable管道,将提示模板和模型结合在一起
runnable = prompt | model
# 创建带有会话历史的Runnable ,使用get_session_history函数来管理会话历史
with_message_history = RunnableWithMessageHistory(
runnable,
get_session_history,
input_messages_key="input", #输入消息在字典中的键名(默认"input")
history_messages_key="history", #历史消息在字典中的键名(默认"history")
)
# 第一次调用带有会话历史的Runnable,提供用户输入和会话ID
response1=with_message_history.invoke(
{"ability": "Java开发", "input": HumanMessage("什么是jvm")},
config={"configurable": {"session_id": "user_123"}},#历史信息存入session_id
)
print(f"response1:{response1.content}",end="\n\n")
# 第二次调用带有会话历史的Runnable,用户请求重新回答上一个问题
response2=with_message_history.invoke(
{"ability": "Java开发", "input": HumanMessage("重新回答一次")},
config={"configurable": {"session_id": "user_123"}},#历史信息存入session_id,如果改为其他session_id,则不会关联到之前的会话历史
)
print(f"response2:{response2.content}",end="\n\n")
# 打印存储的会话历史
print(f"存储内容:{store}")
```
#### 再进阶复杂存储-多租户多会话隔离案例实战
* 需求背景
* 系统需要支持多个用户访问,每个用户拥有唯一的标识符(`user_id`)。
* 用户之间的会话历史完全隔离,避免数据混淆。
* 业务场景中,存在一个用户多个会话的场景
* 存储里面需要支持多用户,多会话的方案, 支持不同用户在多个会话中与AI助手交互。
* 目标:
* **多租户支持**:每个用户拥有独立的标识符(`user_id`),确保不同用户之间的数据隔离。
* **多会话支持**:每个用户可以同时维护多个会话(`session_id`),每个会话的历史记录相互独立。
* **灵活扩展性**:支持自定义存储结构和参数配置,便于未来扩展到分布式存储或其他存储介质
* 知识点
* `history_factory_config`
- 是一个配置列表,用于定义额外的可配置字段,(如 `user_id` 和 `session_id`),这些字段可以影响会话历史的生成逻辑。
- 通过自定义参数来增强系统的灵活性,例如指定用户标识符或对话标识符,从而实现多租户或多会话的支持
* `ConfigurableFieldSpec`
* 是一个类,用于定义一个可配置字段的元信息,包括字段的 ID、类型、名称、描述、默认值等。
```
from langchain_core.runnables import ConfigurableFieldSpec
```
* 为 `RunnableWithMessageHistory` 提供灵活的参数支持,使得开发者可以通过配置动态调整行为。
| 参数名 | 类型 | 描述 | 示例值 |
| :------------ | :----- | :----------------------------------------------------------- | :--------------------- |
| `id` | `str` | 字段的唯一标识符,用于在配置中引用该字段。 | `"user_id"` |
| `annotation` | `type` | 字段的数据类型,用于类型检查和验证。 | `str` |
| `name` | `str` | 字段的名称,通常用于UI展示或调试信息。 | `"用户ID"` |
| `description` | `str` | 字段的描述信息,用于说明该字段的用途。 | `"用户的唯一标识符。"` |
| `default` | `any` | 字段的默认值,如果未提供值时使用。 | `""` |
| `is_shared` | `bool` | 是否为共享字段。如果为 `True`,则该字段在整个运行过程中保持不变。 | `True` |
* 解决方案
* 使用 `user_id` 和 `session_id` 组合作为键值,存储在全局字典 `store` 中。
* 在调用 `get_session_history` 函数时,传入 `user_id` 和 `session_id`,确保获取正确的会话历史。
* 案例实战
```python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai.chat_models import ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables import ConfigurableFieldSpec
# 存储会话历史的字典,可以改其他存储结构
store = {}
# 获取会话历史的函数 如果给定的session_id不在store中,则为其创建一个新的ChatMessageHistory实例
def get_session_history(user_id: str,session_id: str):
if (user_id, session_id) not in store:
store[(user_id, session_id)] = ChatMessageHistory()
return store[(user_id, session_id)]
# 初始化大模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 构建聊天提示模板,包含系统消息、历史消息占位符和人类消息
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是一个小滴课堂AI助手,擅长能力{ability}。用30个字以内回答",
),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
# 创建Runnable管道,将提示模板和模型结合在一起
runnable = prompt | model
# 创建带有会话历史的Runnable ,使用get_session_history函数来管理会话历史
with_message_history = RunnableWithMessageHistory(
runnable,
get_session_history,
input_messages_key="input", #输入消息在字典中的键名(默认"input")
history_messages_key="history", #历史消息在字典中的键名(默认"history")
# 定义一些自定义的参数
history_factory_config=[
ConfigurableFieldSpec(
id="user_id",
annotation=str,
name="用户ID",
description="用户的唯一标识符。",
default="",
is_shared=True,
),
ConfigurableFieldSpec(
id="session_id",
annotation=str,
name="对话 ID",
description="对话的唯一标识符。",
default="",
is_shared=True,
),
]
)
# 第一次调用带有会话历史的Runnable,提供用户输入和会话ID
response1=with_message_history.invoke(
{"ability": "Java开发", "input": HumanMessage("什么是jvm")},
config={'configurable' : { "user_id" : "1" , "session_id" : "1" }}
)
print(f"response1:{response1.content}",end="\n\n")
# 第二次调用带有会话历史的Runnable,用户请求重新回答上一个问题
response2=with_message_history.invoke(
{"ability": "Java开发", "input": HumanMessage("重新回答一次")},
#历史信息存入session_id,如果改为其他session_id,则不会关联到之前的会话历史
config={'configurable' : { "user_id" : "1" , "session_id" : "2" }},
)
print(f"response2:{response2.content}",end="\n\n")
# 打印存储的会话历史
print(f"存储内容:{store}")
```
#### 大模型长期记忆解决方案和案例实战
* 长期记忆的核心需求
* 大模型(LLM)本身不具备长期记忆能力,需通过外部系统实现以下目标:
* **跨会话记忆持久化**:用户多次对话中产生的关键信息需永久存储。
* **多用户隔离**:不同用户的对话历史严格隔离,避免数据泄露。
* **高效检索**:快速提取历史信息辅助当前对话生成。
* **动态更新**:支持记忆的增量添加和过期清理。
* 解决思路:
* 持久化存储:将会话历史保存到数据库/缓存,支持跨会话读取。
* 高效检索:通过语义搜索或键值查询快速定位历史信息。
* 动态更新:根据新交互持续补充用户画像。
* LangChain提供的存储方案
* 地址(失效忽略即可):https://python.langchain.com/docs/integrations/memory/
* `RedisChatMessageHistory` 存储介绍

* 内置的 Redis 消息历史存储工具,将会话记录以结构化形式保存至 Redis
| 特性 | 价值 |
| :-------------: | :----------------------------------------------------------: |
| 低延迟(<1ms) | 实时响应交互需求 |
| 丰富数据结构 | 灵活存储消息/元数据/关系, 使用 JSON 格式存储,支持复杂消息类型(如带元数据的消息) |
| 持久化选项 | RDB+AOF保障数据安全 |
| 集群支持 | 横向扩展应对高并发 |
| 自动过期(TTL) | 合规数据自动清理, 通过 `expire` 参数设置历史记录保存时间(如 30 天自动删除 |
* LangChain 的 `RedisChatMessageHistory` 等组件默认依赖 JSON 格式存储对话历史,ReJSON 提供天然的兼容性
* 数据存储结构
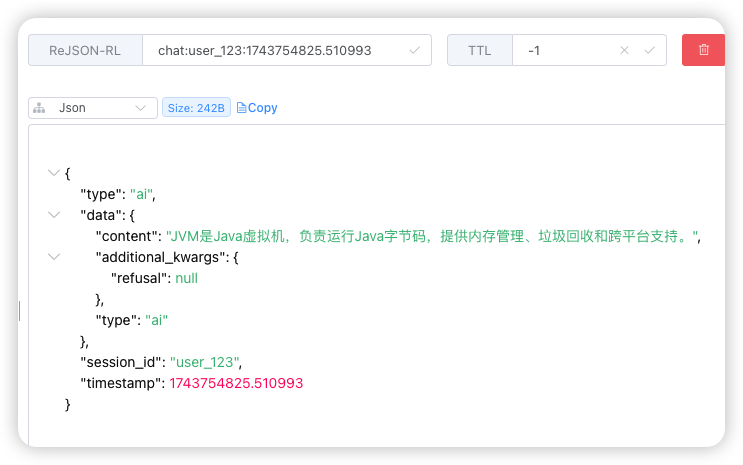
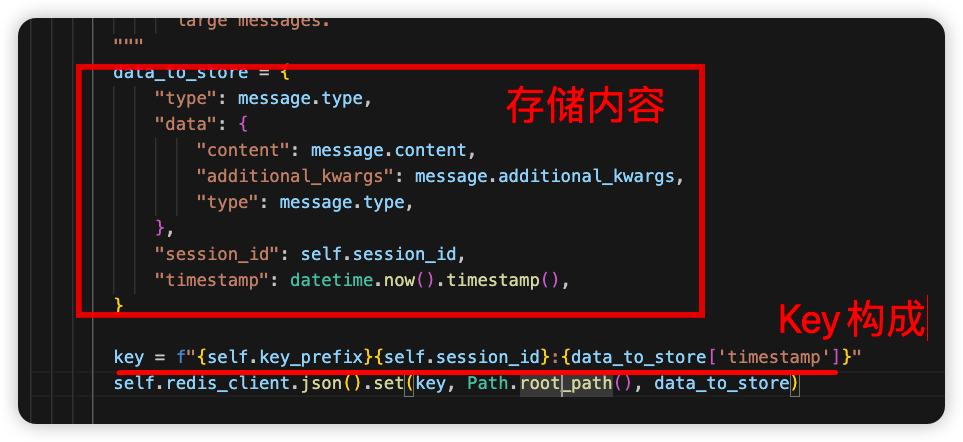 * 什么是Redis-Stack
* 是Redis 官方推出的 集成化发行版,预装了多个高性能模块和工具,专为现代应用设计。
* **开箱即用**:无需手动安装模块,直接支持搜索、JSON、图数据库等高级功能。
* **开发友好**:更适合需要复杂查询、实时分析、AI 应用的场景(如大模型上下文管理、聊天记录检索)。
* **统一体验**:通过 Redis Stack 命令行或客户端库统一访问所有功能。
| 模块/工具 | 功能 |
| :------------------ | :----------------------------------- |
| **RediSearch** | 全文搜索、二级索引 |
| **RedisJSON** | 原生 JSON 数据支持 |
| **RedisGraph** | 图数据库(基于属性图模型) |
| **RedisTimeSeries** | 时间序列数据处理 |
| **RedisBloom** | 概率数据结构(布隆过滤器、基数估算) |
| **RedisInsight** | 图形化管理工具 |
* 何时选择 Redis Stack?
* 全文检索(如聊天记录搜索)。
* 直接操作 JSON 数据(如存储大模型的对话上下文)。
* 时间序列分析(如监控聊天频率)。
* 图关系查询(如社交网络分析)。
* 简化开发流程:避免手动配置多个模块的兼容性和依赖。
* LLM整合如果直接使用之前的Redis服务端会报错,新版单独安装 RedisStack 服务端,才支持相关Redis搜索
* 之前部署的Redis可以卸载,或者更改端口,也可以配置密码,使用方式一样,redis-stack 7.X版本都可以
```dockerfile
docker run -d \
--name redis-stack \
-p 6379:6379 \
-p 8001:8001 \
redis/redis-stack:latest
```
* 案例实战
* 安装依赖
```
pip install langchain-redis==0.2.0 redis==5.2.1
```
* 案例测试
```python
from langchain_redis import RedisChatMessageHistory
import os
REDIS_URL = os.getenv("REDIS_URL", "redis://47.119.128.20:6379")
#配置了密码 REDIS_URL = "redis://:your_password@your_ip:6379"
#REDIS_URL = os.getenv("REDIS_URL", "redis://:abc123456@39.108.115.28:6379")
# 初始化 RedisChatMessageHistory
history = RedisChatMessageHistory(session_id="user_123", redis_url=REDIS_URL)
# 新增消息
history.add_user_message("Hello, AI assistant!")
history.add_ai_message("Hello! How can I assist you today?")
# 检索消息
print("Chat History:")
for message in history.messages:
print(f"{type(message).__name__}: {message.content}")
```
* 编码实战
```python
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI
from langchain_redis import RedisChatMessageHistory
#存储历史会话的字典
REDIS_URL="redis://47.119.128.20:6379"
#定义函数,用于获取会话历史
def get_redis_history(session_id: str):
return RedisChatMessageHistory(session_id, redis_url=REDIS_URL)
# 初始化大模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 构建聊天提示模板,包含系统消息、历史消息占位符和人类消息
prompt = ChatPromptTemplate.from_messages(
[
("system","你是一个小滴课堂AI助手,擅长能力{ability}。用30个字以内回答",),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
#创建基础链
chain = prompt | model
with_message_history = RunnableWithMessageHistory(
chain, get_redis_history, input_messages_key="input", history_messages_key="history"
)
#第一次调用,提供用户输入和会话ID
resp1 = with_message_history.invoke(
{"ability":"Java开发", "input":HumanMessage("什么是JVM")}, #替换提示词
config={"configurable":{"session_id":"user_123"} }) #会话唯一ID
print(f"resp1={resp1.content}",end="\n\n")
resp2 = with_message_history.invoke(
{"ability":"Java开发", "input":HumanMessage("重新回答一次")}, #替换提示词
config={"configurable":{"session_id":"user_123"} }) #会话唯一ID
print(f"resp2={resp2.content}",end="\n\n")
```
* 注意: 安全起见,RedisStack还是需要配置密码,避免入侵挖矿
```dockerfile
docker run -d \
--name redis-stack \
-p 6379:6379 \
-p 8001:8001 \
-e REDIS_ARGS="--requirepass abc123456" \
redis/redis-stack:latest
```
* 多租户多会话方案
```python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai.chat_models import ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables import ConfigurableFieldSpec
from langchain_redis import RedisChatMessageHistory
#存储历史会话的字典
REDIS_URL="redis://:abc123456@47.119.128.20:6379"
# 获取会话历史的函数 如果给定的session_id不在store中,则为其创建一个新的ChatMessageHistory实例
def get_session_history(user_id: str,session_id: str):
uni_key = user_id+"_"+session_id
return RedisChatMessageHistory(
session_id=uni_key,
redis_url=REDIS_URL)
# 初始化大模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 构建聊天提示模板,包含系统消息、历史消息占位符和人类消息
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是一个小滴课堂AI助手,擅长能力{ability}。用30个字以内回答",
),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
# 创建Runnable管道,将提示模板和模型结合在一起
runnable = prompt | model
# 创建带有会话历史的Runnable ,使用get_session_history函数来管理会话历史
with_message_history = RunnableWithMessageHistory(
runnable,
get_session_history,
input_messages_key="input", #输入消息在字典中的键名(默认"input")
history_messages_key="history", #历史消息在字典中的键名(默认"history")
# 定义一些自定义的参数
history_factory_config=[
ConfigurableFieldSpec(
id="user_id",
annotation=str,
name="用户ID",
description="用户的唯一标识符。",
default="",
is_shared=True,
),
ConfigurableFieldSpec(
id="session_id",
annotation=str,
name="对话 ID",
description="对话的唯一标识符。",
default="",
is_shared=True,
),
]
)
# 第一次调用带有会话历史的Runnable,提供用户输入和会话ID
response1=with_message_history.invoke(
{"ability": "Java开发", "input": HumanMessage("什么是jvm")},
config={'configurable' : { "user_id" : "user_1" , "session_id" : "session_1" }}
)
print(f"response1:{response1.content}",end="\n\n")
# 打印存储的会话历史
print(get_session_history("user_1","session_1").messages)
# 第二次调用带有会话历史的Runnable,用户请求重新回答上一个问题
response2=with_message_history.invoke(
{"ability": "Java开发", "input": HumanMessage("重新回答一次")},
config={'configurable' : { "user_id" : "user_2" , "session_id" : "session_1" }},
)
print(f"response2:{response2.content}",end="\n\n")
# 打印存储的会话历史
print(get_session_history("user_2","session_1").messages)
```
### 大模型服务必备FastAPI Web框架
#### Python Web框架Fast API技术介绍
* 需求背景:现代Web开发痛点
* 传统框架(如Flask、Django)对异步支持弱,性能受限。
* 手动编写API文档耗时且易过时、缺乏自动化数据验证,易出现安全漏洞。
* FastAPI是什么?
- 一个基于 Python 3.8+ 的现代 Web 框架,专为构建高性能 API 设计。
- 官方地址:
- https://github.com/fastapi/fastapi
- https://fastapi.tiangolo.com/
- 关键特性:
- ⚡ 高性能:基于Starlette(异步)和Pydantic(数据验证)
- 📚 自动文档:集成Swagger UI和Redoc,代码即文档。
- ✅ 强类型安全:Python类型提示 + Pydantic模型,减少Bug。
- 🚀 易学易用:代码简洁,适合快速开发API。
- 适用场景
* 构建 RESTful API 或 大模型服务,微服务架构中的独立服务模块。
* 需要自动生成 API 文档的项目。
* **核心价值**:FastAPI = 高性能 + 强类型 + 自动文档。
- **优点**:
- 开发效率高(代码量减少 40%+)
- 严格的类型提示减少运行时错误。
- **缺点**:
- 生态相对较新(插件和社区资源少于 Django/Flask)。
- 学习曲线略高(需熟悉 异步编程)。
* 什么是 Uvicorn(类似Java 生态的Tomcat)
* 是一个轻量级、高性能的 **ASGI(Asynchronous Server Gateway Interface)服务器**
* 专门运行异步 Python Web 应用(如 FastAPI、Starlette 或 Django Channels)。
* 类似传统 WSGI 服务器 的异步升级版,支持 HTTP/1.1、WebSockets 和 ASGI 标准。
* **核心功能**
* **异步处理**:基于 `asyncio` 库,原生支持 `async/await`,适合高并发场景(如实时通信、高频 API 调用)。
* **高性能**:使用 C 语言编写的 `uvloop` 和 `httptools` 加速网络请求处理。
* **自动重载**:开发时通过 `--reload` 参数监听代码变动,自动重启服务。
* **协议支持**: HTTP/1.1 、WebSocket、实验性 HTTP/2(需额外配置)
* 与 FastAPI 的关系
* 依赖关系:FastAPI 本身不包含服务器,需通过 Uvicorn(或其他 ASGI 服务器)启动。
* 协同工作流程:
* 用户通过 Uvicorn 启动 FastAPI 应用。
* Uvicorn 监听 HTTP 请求,将请求转发给 FastAPI 处理。
* FastAPI 处理请求并返回响应,由 Uvicorn 发送给客户端
* 类似产品对比
| 框架 | 语言 | 特点 | 适用场景 |
| :-------------- | :------ | :----------------------------------- | :---------------------- |
| **Flask** | Python | 轻量级、灵活,但同步且无内置数据验证 | 小型应用、快速原型开发 |
| **Django** | Python | 全功能(ORM、Admin),但重量级、同步 | 复杂 Web 应用(如 CMS) |
| **Express** | Node.js | 高并发,但动态类型易出错 | JS 生态的 API 开发 |
| **Spring Boot** | Java | 企业级功能,但配置复杂、启动慢 | 大型分布式系统 |
| **FastAPI** | Python | 高性能、异步、类型安全、自动文档 | 高并发 API、微服务 |
#### FastAPI环境安装和基础案例实战
* 环境安装
* FastAPI 依赖 Python 3.8 及更高版本, 安装fastapi版本 `0.115.12`
* 安装命令
* 安装依赖库. `pip install "fastapi[standard]"`
* 安装uvicorn服务器 `pip install "uvicorn[standard]"`
* 案例实战
* 创建第一个Fast API应用
```python
from typing import Union
from fastapi import FastAPI
# 创建FastAPI实例
app = FastAPI()
#http请求方式类型:get、post、put、update、delete
#不带参数访问路由
@app.get("/")
def read_root():
return {"Hello": "World11"}
# 带参数访问,比如 http://127.0.0.1:8000/items/5?q=xd
# q参数通过 Union[str, None] 表示可以是字符串类型或空,这样就允许在请求中不提供 q 参数。
@app.get("/items/{item_id}")
def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
```
* 启动服务
```python
# 语法:uvicorn 文件的相对路径:实例名 --reload
# 多级目录使用.,例如: uvicorn xx.xx.main:app -- reload
#--reload:代码修改后自动重启(仅开发环境)
# main:当前目录下的main.py文件,app:文件下的app实例变量
uvicorn main:app --reload
#指定程序监听端口
uvicorn main:app --port 8002 --reload
#下面这个方式也可以
fastapi dev main.py
```
* 访问API与文档
* API地址:`http://localhost:8000`
* 交互文档:`http://localhost:8000/docs`
* 备用文档( 另一种交互式文档界面,具有清晰简洁的外观 ):`http://localhost:8000/redoc`
#### 进阶FastAPI Web多案例参数请求实战
* 路由与 HTTP 方法
```python
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/{item_id}")
def read_item(item_id: int): # 自动类型转换和验证
return {"item_id": item_id}
@app.post("/items/")
def create_item(item: dict):
return {"item": item}
@app.put("/items/{item_id}")
def update_item(item_id: int, item: dict):
return {"item_id": item_id, "updated_item": item}
@app.delete("/items/{item_id}")
def delete_item(item_id: int):
return {"status": "deleted", "item_id": item_id}
```
* 请求头Header操作
```python
from fastapi import Header
@app.get("/header")
def read_item(item_id: int, token: str = Header("token")):
return {"token": token,"item_id": item_id}
```
* 获取多个请求头
```python
from fastapi import Request
@app.get("/all-headers/")
def get_all_headers(request: Request):
return dict(request.headers)
```
* 自定义响应头
```python
from fastapi.responses import JSONResponse
@app.get("/custom-header/")
def set_custom_header():
content = {"message": "Hello World"}
headers = {
"X-Custom-Header": "my_value xdclass.net",
"Cache-Control": "max-age=3600"
}
return JSONResponse(content=content, headers=headers)
```
* 自定义响应码
```python
from fastapi import FastAPI, status,Response
@app.get("/status_code", status_code=200)
def create_item(name: str):
if name == "Foo":
return Response(status_code=status.HTTP_404_NOT_FOUND)
return {"name": name}
```
#### FastAPI异步编程async-await多案例实战
* 需求背景
* 什么是同步和异步? 用一个奶茶店买饮料的场景帮理解同步和异步的区别
* 🧋 **同步(Synchronous)就像传统奶茶店**
```markdown
你: 老板,我要一杯珍珠奶茶
店员: 开始制作(5分钟)
你: 干站着等,不能做其他事
店员: 做好了!请取餐
下一位顾客: 必须等前一个人完成才能点单
特点: 必须按顺序处理,前一个任务没完成,后面全卡住
```
* 🚀 异步(Asynchronous)像智能奶茶店
```markdown
你: 扫码下单珍珠奶茶
系统: 收到订单(生成取餐号)
你: 去旁边座位玩手机(不用干等)
店员: 同时处理多个订单
系统: 奶茶做好后叫号通知你
特点: 下单后可以继续做其他事,系统并行处理多个任务
```
* 对应到代码中
```markdown
# 同步代码(传统奶茶店模式)
def make_tea():
print("开始煮茶") # 👨🍳 店员开始工作
time.sleep(3) # ⏳ 你干等着
print("加珍珠")
return "奶茶好了"
# 异步代码(智能奶茶店模式)
async def async_make_tea():
print("开始煮茶")
await asyncio.sleep(3) # 🚶♂️ 你可以去做其他事
print("加珍珠")
return "奶茶好了"
```
* 同步和异步关键区别总结【伪代码】
* 同步版本(存在性能瓶颈)
```python
import requests
@app.get("/sync-news")
def get_news_sync():
# 顺序执行(总耗时=各请求之和)
news1 = requests.get("https://api1.com").json() # 2秒
news2 = requests.get("https://api2.com").json() # 2秒
return {"total_time": 4}
```
* 异步版本(高效并发)
```python
import httpx
@app.get("/async-news")
async def get_news_async():
async with httpx.AsyncClient() as client:
# 并行执行(总耗时≈最慢的请求)
start = time.time()
task1 = client.get("https://api1.com")
task2 = client.get("https://api2.com")
res1, res2 = await asyncio.gather(task1, task2)
return {
"total_time": time.time() - start # ≈2秒
}
```
* 异步编程常见类库介绍
* * `asyncio` 类库
* Python 中用于编写**单线程并发代码**的库,基于**协程(Coroutine)**和**事件循环(Event Loop)**实现异步编程。
* 专为处理 I/O 密集型任务(如网络请求、文件读写、数据库操作)设计,提高程序的吞吐量和资源利用率
* **协程(Coroutine)**
- 使用 `async def` 定义的函数称为协程,返回一个协程对象,不会立即执行。
- 协程通过 `await` 关键字挂起自身,将控制权交还给事件循环,直到异步操作完成
```
async def my_coroutine():
await asyncio.sleep(1)
print("Done!")
```
* **事件循环(Event Loop)**
- 事件循环是异步程序的核心,负责调度和执行协程、处理 I/O 事件、管理回调等。
- 通过 `asyncio.run()` 或手动创建事件循环来启动。
```python
# 启动事件循环并运行协程
asyncio.run(my_coroutine())
```
* **任务(Task)**
- 任务是对协程的封装,用于在事件循环中并发执行多个协程。
- 通过 `asyncio.create_task()` 创建任务
```python
async def main():
task = asyncio.create_task(my_coroutine())
await task
```
* **Future**
- `Future` 是一个底层对象,表示异步操作的最终结果。通常开发者直接使用 `Task`(它是 `Future` 的子类)。
* `httpx` 类库
* Python 中一个现代化、功能丰富的 HTTP 客户端库,支持同步和异步请求
* `httpx` 是 `requests` 的现代替代品,结合了易用性与强大功能,尤其适合需要异步或 HTTP/2 支持的场景。
* 同步请求案例
```python
import httpx
# GET 请求
response = httpx.get("https://httpbin.org/get")
print(response.status_code)
print(response.json())
```
* 异步请求案例
```python
import httpx
import asyncio
async def fetch_data():
async with httpx.AsyncClient() as client:
response = await client.get("https://httpbin.org/get")
print(response.json())
asyncio.run(fetch_data())
```
* 使用客户端实例(推荐)
```python
# 同步客户端
with httpx.Client() as client:
response = client.get("https://httpbin.org/get")
# 异步客户端
async with httpx.AsyncClient() as client:
response = await client.get("https://httpbin.org/get")
```
* 案例实战
* 基础同步和异步编程
```python
from fastapi import FastAPI
import asyncio
import time
app = FastAPI()
# 同步路由执行(顺序阻塞)
@app.get("/sync_func")
def sync_endpoint():
# 模拟耗时操作
print("开始任务1") # 立即执行
time.sleep(3) # 阻塞3秒
print("开始任务2") # 3秒后执行
return {"status": "done"}
# 异步异步执行(非阻塞切换)
@app.get("/async_func")
async def async_endpoint(): # 异步接口
# 必须使用异步库
print("开始任务A") # 立即执行
await asyncio.sleep(3) # 释放控制权,异步等待
print("开始任务B") # 3秒后恢复执行
return {"status": "done"}
```
* 综合案例实战:并发调用外部API
```python
import asyncio
import httpx
from fastapi import FastAPI
app = FastAPI()
"""
异步函数:fetch_data
功能:通过HTTP GET请求从指定URL获取数据并返回JSON格式的响应。
参数:
url (str): 目标API的URL地址。
返回值:
dict: 从目标URL获取的JSON格式数据。
"""
async def fetch_data(url: str):
async with httpx.AsyncClient() as client:
response = await client.get(url)
return response.json()
"""
路由处理函数:get_news
功能:定义一个FastAPI的GET路由,用于并发获取多个API的数据并返回整合后的结果。
"""
@app.get("/xdclass")
async def get_news():
start = time.time()
# 定义需要请求的API URL列表
urls = [
"https://api-v2.xdclass.net/api/funny/v1/get_funny",
"https://api-v2.xdclass.net/api/banner/v1/list?location=home_top_ad",
"https://api-v2.xdclass.net/api/rank/v1/hot_product",
"http://localhost:8000/sync1",
"http://localhost:8000/sync2",
]
# 创建并发任务列表,每个任务调用fetch_data函数获取对应URL的数据
tasks = [fetch_data(url) for url in urls]
# 使用asyncio.gather并发执行所有任务,并等待所有任务完成
results = await asyncio.gather(*tasks)
print(f"共耗时 {time.time() - start} 秒")
# 返回整合后的结果
return results
```
* 常见错误模式演示
```python
# 错误示例:在async函数中使用同步阻塞
@app.get("/wrong")
async def bad_example():
time.sleep(5) # 会阻塞整个事件循环!
# 正确方案1:改用异步等待
@app.get("/right1")
async def good_example():
await asyncio.sleep(5)
```
* 最佳实践指南
* **必须使用async的三种场景**
* 需要await调用的异步库操作
* WebSocket通信端点
* 需要后台任务处理的接口
* **以下情况适合同步路由**
- 纯CPU计算(如数学运算)
- 使用同步数据库驱动
- 快速返回的简单端点
* **路由声明规范**
* 所有路由优先使用`async def`
* 仅在必须使用同步操作时用普通 `def`
* **性能优化建议**
- 保持async函数轻量化
- 长时间CPU密集型任务使用后台线程
- 使用连接池管理数据库/HTTP连接
#### 进阶FastAPI模型Pydantic 案例实战
* 什么是数据模型
* 客户端能发送什么数据
* 服务端会返回什么数据
* 数据验证规则
* 基础模型定义
```python
from pydantic import BaseModel
# 用户注册模型
class UserRegister(BaseModel):
username: str # 必填字段
email: str | None = None # 可选字段
age: int = Field(18, gt=0) # 带默认值和验证
```
* 案例实战
* 请求体(POST/PUT数据)
```python
from pydantic import BaseModel,Field
class Product(BaseModel):
name: str
price: float = Field(..., gt=0)
tags: list[str] = []
@app.post("/products")
async def create_product(product: Product):
return product.model_dump()
#测试数据
{
"name":"小滴",
"price":111,
"tags":["java","vue"]
}
```
* 返回 Pydantic 模型
```python
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: str = None
price: float
tax: float = None
@app.post("/items")
async def create_item(item: Item):
return item
#测试数据
{
"name":"小滴",
"price":111,
"description":"小滴课堂是在线充电平台"
}
```
* 密码强度验证
```python
from pydantic import BaseModel, field_validator
class UserRegistration(BaseModel):
username: str
password: str
@field_validator('password')
def validate_password(cls, v):
if len(v) < 8:
raise ValueError('密码至少8位')
if not any(c.isupper() for c in v):
raise ValueError('必须包含大写字母')
if not any(c.isdigit() for c in v):
raise ValueError('必须包含数字')
return v
@app.post("/register/")
async def register(user: UserRegistration):
return {"username": user.username}
#测试数据
{
"username":"小滴",
"password":"123"
}
```
### FastAPI框架高级技能和综合项目实战
#### FastAPI路由管理APIRouter案例实战
* 需求背景
* 代码混乱问题, 未使用路由管理(所有接口堆在main.py中)
* 所有接口混杂在一个文件中,随着功能增加,文件会变得臃肿难维护。
```python
# main.py
from fastapi import FastAPI
app = FastAPI()
# 用户相关接口
@app.get("/users")
def get_users(): ...
# 商品相关接口
@app.get("/items")
def get_items(): ...
# 订单相关接口
@app.get("/orders")
def get_orders(): ...
```
* 重复配置问题, 未使用路由管理(重复写前缀和标签)
* 每个接口都要重复写`/api/v1`前缀和`tags`,容易出错且难以统一修改
```python
# 用户接口
@app.get("/api/v1/users", tags=["用户管理"])
def get_users_v1(): ...
# 商品接口
@app.get("/api/v1/items", tags=["商品管理"])
def get_items_v1(): ...
```
* 权限控制问题, 未使用路由管理(每个接口单独添加认证)
* 需要在每个管理员接口重复添加认证依赖。
```python
@app.get("/admin/stats", dependencies=[Depends(admin_auth)])
def get_stats(): ...
@app.post("/admin/users", dependencies=[Depends(admin_auth)])
def create_user(): ...
```
* **使用路由管理(模块化拆分)**
* 按业务模块拆分,每个文件职责单一。
```python
# 文件结构
routers/
├── users.py # 用户路由
├── items.py # 商品路由
└── orders.py # 订单路由
# main.py
from routers import users, items, orders
app.include_router(users.router)
app.include_router(items.router)
app.include_router(orders.router)
```
* 使用路由管理
```python
# 创建管理员专属路由组
admin_router = APIRouter(
prefix="/admin",
dependencies=[Depends(admin_auth)], # 👈 统一认证
tags=["管理员"]
)
@admin_router.get("/stats")
def get_stats(): ...
@admin_router.post("/users")
def create_user(): ...
```
* `APIRouter`核心概念
* 基础使用模板
```python
from fastapi import APIRouter
router = APIRouter(
prefix="/users", # 路由前缀
tags=["用户管理"], # OpenAPI分组
responses={404: {"description": "资源未找到"}} # 默认响应
)
@router.get("/", summary="获取用户列表")
async def list_users():
return [{"id": 1, "name": "张三"}]
```
* 核心配置参数
| 参数 | 作用 | 示例值 |
| :----------: | :--------------: | :---------------------: |
| prefix | 路由统一前缀 | "/api/v1" |
| tags | OpenAPI文档分组 | ["认证相关"] |
| dependencies | 路由组公共依赖项 | [Depends(verify_token)] |
| responses | 统一响应定义 | {400: {"model": Error}} |
* 案例实战
* 创建文件` app/users.py`
```python
from fastapi import APIRouter, HTTPException
from pydantic import BaseModel
router = APIRouter(
prefix="/users", # 路由前缀
tags=["用户管理"], # OpenAPI文档分组
dependencies=[] # 模块级依赖
)
@router.get("/", summary="获取用户列表")
async def list_users():
return [{"id": 1, "name": "Alice"}]
@router.post("/", summary="创建新用户")
async def create_user():
return {"id": 2, "name": "Bob"}
class UserCreate(BaseModel):
username: str
password: str
@router.post("/register", status_code=201)
async def register(user: UserCreate):
"""用户注册接口"""
# 实际应保存到数据库
return {"message": "用户创建成功", "username": user.username}
@router.get("/{user_id}")
async def get_user(user_id: int):
if user_id > 100:
raise HTTPException(404, "用户不存在")
return {"user_id": user_id, "name": "虚拟用户"}
```
* 创建文件 `app/products.py`
```python
# app/api/v1/products.py
from fastapi import APIRouter
router = APIRouter(
prefix="/products",
tags=["商品管理"],
dependencies=[]
)
@router.get("/search", summary="商品搜索")
async def search_products(
q: str,
min_price: float = None,
max_price: float = None
):
# 实现搜索逻辑
return {"message": "搜索成功"}
@router.get("/{product_id}", summary="获取商品详情")
async def get_product_details(product_id: int):
return {"id": product_id}
```
* 创建入口文件 `main.py`
```python
from fastapi import FastAPI
from app import users, products
import uvicorn
# 创建FastAPI应用实例
app = FastAPI()
# 注册用户模块的路由
app.include_router(users.router)
# 注册产品模块的路由
app.include_router(products.router)
# 访问路径:
# GET /users/ → 用户列表
# POST /users/ → 创建用户
#...
# 打印所有注册的路由信息,便于开发者查看和调试
for route in app.routes:
print(f"{route.path} → {route.methods}")
# 定义根路径的GET请求处理函数
"""
处理根路径的GET请求。
返回值:
dict: 返回一个JSON对象,包含欢迎消息。
"""
@app.get("/")
async def root():
return {"message": "Hello 小滴课堂"}
# 主程序入口,用于启动FastAPI应用
if __name__ == '__main__':
# 使用uvicorn运行FastAPI应用,默认监听本地地址和端口
uvicorn.run(app,port=8001)
```
* 模块化结构参考
```python
#整体项目结构
project/
├── main.py
└── routers/
├── __init__.py
├── users.py
├── items.py
├── admin/
│ ├── dashboard.py
│ └── audit.py
└── v2/
└── users.py
```
* 总结
| 实践要点 | 说明 |
| :----------: | :------------------------------------: |
| 模块化组织 | 按业务功能拆分路由模块 |
| 统一前缀管理 | 使用`prefix`参数避免路径重复 |
| 文档友好 | 合理使用`tags`和`summary`优化API文档 |
| 依赖分层 | 模块级依赖处理认证,路由级处理业务逻辑 |
#### FastAPI依赖注入和常见项目结构设计
* 什么是依赖注入
* 用于将重复逻辑(如鉴权、数据库连接、参数校验)抽象为可复用的组件,
* 通过依赖注入(Dependency Injection)自动注入到路由处理函数中,让代码更简洁、模块化且易于测试
* 核心
* **代码复用**:避免在多个路由中重复相同逻辑(如权限检查)。
* **解耦**:将业务逻辑与基础设施(如数据库、认证)分离。
* **层级化**:支持嵌套依赖,构建多层逻辑(如先验证用户,再验证权限)
* 与 Java Spring 对比
| **功能** | **FastAPI** | **Spring (Java)** |
| :----------- | :-------------------- | :----------------------------- |
| **依赖注入** | 函数/类 + `Depends()` | `@Autowired` + 容器管理 |
| **作用域** | 默认每次请求 | Singleton/Prototype/Request 等 |
* 语法案例
* **定义依赖项函数**
* 依赖项可以是任何可调用对象(如函数、类),通过 `Depends()` 声明依赖关系
```python
from fastapi import Depends, FastAPI
app = FastAPI()
# 定义一个依赖项(函数)
def common_params(query: str = None, page: int = 1):
return {"query": query, "page": page}
# 在路由中使用依赖项
@app.get("/read_items")
async def read_items(params: dict = Depends(common_params)):
return params
#说明:common_params 会被自动调用,结果注入到 params 参数。
#访问结果:read_items 中可直接使用 params["query"] 和 params["page"]。
```
* 类作为依赖项
* 依赖项也可以是类,适合需要初始化或状态管理的场景, 通过依赖注入机制,将复杂逻辑解耦为可复用的模块
```python
#案例一
class DatabaseSession:
def __init__(self):
self.session = "模拟数据库连接"
def close(self):
print("关闭数据库连接")
def get_db():
db = DatabaseSession()
try:
yield db
finally:
db.close()
@app.get("/users/")
async def get_users(db: DatabaseSession = Depends(get_db)):
return {"db_session": db.session}
#案例二
class Pagination:
def __init__(self, page: int = 1, size: int = 10):
self.page = page
self.size = size
@app.get("/articles/")
async def get_articles(pagination: Pagination = Depends()):
return {"page": pagination.page, "size": pagination.size}
```
* 全局依赖项
* 为所有路由添加公共依赖项(如统一认证)
```python
app = FastAPI(dependencies=[Depends(verify_token)])
# 或针对特定路由组:
router = APIRouter(dependencies=[Depends(log_request)])
#在部分管理员接口添加认证依赖。
@app.get("/admin/stats", dependencies=[Depends(admin_auth)])
def get_stats(): ...
@app.post("/admin/users", dependencies=[Depends(admin_auth)])
def create_user(): ...
```
* FastAPI 项目结构设计原则
* 基础分层结构(适合小型项目)
```python
myproject/
├── main.py
├── routers/
│ ├── users.py
│ └── items.py
├── models/
│ └── schemas.py
└── dependencies.py
```
* 模块化拆分结构一(推荐中型项目)
```python
src/
├── app/
│ ├── core/ # 核心配置
│ │ ├── config.py
│ │ └── security.py
│ ├── api/ # 路由入口
│ │ ├── v1/ # 版本控制
│ │ │ ├── users/
│ │ │ │ ├── endpoints.py
│ │ │ │ └── schemas.py
│ │ │ └── items/
│ ├── models/ # 数据模型
│ ├── services/ # 业务逻辑
│ └── utils/ # 工具类
├── tests/ # 测试目录
└── requirements.txt
```
* 模块化拆分结构二(推荐中型项目)
```python
myproject/
├── app/ # 应用核心目录
│ ├── core/ # 全局配置和工具
│ │ ├── config.py # 配置管理
│ │ └── security.py # 安全相关工具
│ ├── api/ # 路由端点
│ │ ├── v1/ # API版本目录
│ │ │ ├── users.py
│ │ │ ├── items.py
│ │ │ └── ai.py
│ │ └── deps.py # 公共依赖项
│ ├── models/ # Pydantic模型
│ │ ├── user.py
│ │ └── item.py
│ ├── services/ # 业务逻辑层
│ │ ├── user_service.py
│ │ └── ai_service.py
│ ├── db/ # 数据库相关
│ │ ├── session.py # 数据库会话
│ │ └── models.py # SQLAlchemy模型
│ └── utils/ # 工具函数
│ └── logger.py
├── tests/ # 测试目录
│ ├── test_users.py
│ └── conftest.py
├── static/ # 静态文件
├── main.py # 应用入口
├── requirements.txt
└── .env # 环境变量
```
* 推荐原则【遵循团队规范即可】
| 原则 | 实施方法 |
| :------: | :--------------------------------: |
| 单一职责 | 每个文件/类只做一件事 |
| 依赖倒置 | 通过依赖注入解耦组件 |
| 分层清晰 | 严格区分路由层、服务层、数据访问层 |
| 版本控制 | 通过URL路径实现API版本管理 |
| 文档友好 | 为每个路由添加summary和description |
#### FastAPI+大模型流式AI问答助手实战
* 需求
* 开发一个基于AI的问答工具,能够根据用户提供的知识点或主题生成简洁的介绍或解释。
* 使用了大语言模型(LLM)来实现流式生成文本的功能,适用于教育、内容创作等场景
* FastAPI框架整合LLM大模型,提供HTTP服务
* `StreamingResponse` 介绍
* FastAPI 的提供了 `StreamingResponse` 是一个用于处理流式传输数据的工具,适用于需要逐步发送大量数据或实时内容的场景。
* 允许通过生成器逐块发送数据,避免一次性加载全部内容到内存,提升性能和资源利用率。
```
from fastapi.responses import StreamingResponse
```
* 核心功能
* 流式传输:逐步发送数据块,适用于大文件(如视频、日志)、大模型实时生成内容(如LLM响应、服务器推送事件)或长时间运行的任务。
* 内存高效:无需将完整数据加载到内存,减少服务器负载。
* 异步支持:兼容同步和异步生成器,灵活适配不同场景。
* 基本用法
* 在路由中返回 `StreamingResponse` 实例,并传入生成器作为数据源
* 参数说明
* `content`: 生成器函数,产生字节或字符串数据块。
* `media_type`: 指定 MIME 类型(如 `"text/event-stream"`、`"application/json"`)。
* `headers`: 自定义响应头(如 `{"Content-Disposition": "attachment; filename=data.csv"}`)。
* `status_code`: 设置 HTTP 状态码(默认为 `200`)。
* 案例实操
```python
async def ai_qa_stream_generator(query: str):
"""生成A回答的流式响应"""
try:
async for chunk in ai_writer.run_stream(query):
json_data = json.dumps({"text": chunk})
yield f"data: {json_data}\n\n"
except Exception as e:
error_msg = json.dumps({"error": str(e)})
yield f"data: {error_msg}\n\n"
@app.get("/ai_write")
async def ai_writer_endpoint(query: str):
"""AI写作接口,返回流式响应"""
return StreamingResponse(
ai_qa_stream_generator(query),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive"
}
)
```
* 编码实战 `app/ai_writer.py`
```python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from typing import AsyncGenerator
# 封装AI问答的类
class AIWriter:
def __init__(self):
# 初始化语言模型
self.llm = self.llm_model()
# 定义一个返回自定义语言模型的方法
def llm_model(self):
#创建模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7,
streaming=True
)
return model
async def run_stream(self, query: str) -> AsyncGenerator[str, None]:
"""运行AI问答并返回流式响应"""
try:
# 定义提示模板,要求对文档进行摘要总结
prompt_template = "用100个字解释下面的知识点或者介绍:{concept}"
# 使用提示模板类创建模板
prompt = ChatPromptTemplate.from_template(prompt_template)
# 定义LLM链,将自定义语言模型和提示模板结合
chain = prompt | self.llm | StrOutputParser()
# 使用流式输出
async for chunk in chain.astream({"concept": query}):
if isinstance(chunk, str):
yield chunk
elif isinstance(chunk, dict) and "content" in chunk:
yield chunk["content"]
else:
yield str(chunk)
except Exception as e:
yield f"发生错误: {str(e)}"
async def chat(self, query: str):
"""处理用户消息并返回流式响应"""
try:
async for chunk in self.run_stream(query):
yield chunk
except Exception as e:
yield f"发生错误: {str(e)}"
```
* 编码实战 `writer_app.py`
```python
import uvicorn
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from app.ai_writer import AIWriter
import json
app = FastAPI()
# 初始化智能体
ai_writer = AIWriter()
async def ai_qa_stream_generator(query: str):
"""生成A回答的流式响应"""
try:
async for chunk in ai_writer.run_stream(query):
json_data = json.dumps({"text": chunk}, ensure_ascii=False)
yield f"data: {json_data}\n\n"
except Exception as e:
error_msg = json.dumps({"error": str(e)})
yield f"data: {error_msg}\n\n"
@app.get("/ai_write")
async def ai_writer_endpoint(query: str):
"""AI写作接口,返回流式响应"""
return StreamingResponse(
ai_qa_stream_generator(query),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive"
}
)
# 启动服务器的命令
if __name__ == "__main__":
uvicorn.run(app, port=8003)
```
* 如何调试
* Apifox 提供了专门的 SSE(Server-Sent Events)调试功能,适合处理 AI 大模型的流式响应场景
* 配置 SSE,选择接口的请求方法,在请求头中添加 `Accept: text/event-stream` 来启用 SSE。
### LLM大模型Web服务智能体中心开发实战
#### AI智能体中心Web服务架构和相关环境创建
* 需求说明
* 基于前面学的`langchain+fastapi`+多个知识点,综合开发大模型Web服务,包括多个智能体
* 部分智能体可以结合网盘业务进行,部分智能体可以独立运行
* 注意
* **智能体中心包括多个应用,非强行绑定,可以结合自己公司业务灵活切换包装简历**
* **要学会举一反三,结合前面的内容进行拓展更多,比如AI医生、AI律师、AI政务等**
* 智能体业务架构图
* 什么是Redis-Stack
* 是Redis 官方推出的 集成化发行版,预装了多个高性能模块和工具,专为现代应用设计。
* **开箱即用**:无需手动安装模块,直接支持搜索、JSON、图数据库等高级功能。
* **开发友好**:更适合需要复杂查询、实时分析、AI 应用的场景(如大模型上下文管理、聊天记录检索)。
* **统一体验**:通过 Redis Stack 命令行或客户端库统一访问所有功能。
| 模块/工具 | 功能 |
| :------------------ | :----------------------------------- |
| **RediSearch** | 全文搜索、二级索引 |
| **RedisJSON** | 原生 JSON 数据支持 |
| **RedisGraph** | 图数据库(基于属性图模型) |
| **RedisTimeSeries** | 时间序列数据处理 |
| **RedisBloom** | 概率数据结构(布隆过滤器、基数估算) |
| **RedisInsight** | 图形化管理工具 |
* 何时选择 Redis Stack?
* 全文检索(如聊天记录搜索)。
* 直接操作 JSON 数据(如存储大模型的对话上下文)。
* 时间序列分析(如监控聊天频率)。
* 图关系查询(如社交网络分析)。
* 简化开发流程:避免手动配置多个模块的兼容性和依赖。
* LLM整合如果直接使用之前的Redis服务端会报错,新版单独安装 RedisStack 服务端,才支持相关Redis搜索
* 之前部署的Redis可以卸载,或者更改端口,也可以配置密码,使用方式一样,redis-stack 7.X版本都可以
```dockerfile
docker run -d \
--name redis-stack \
-p 6379:6379 \
-p 8001:8001 \
redis/redis-stack:latest
```
* 案例实战
* 安装依赖
```
pip install langchain-redis==0.2.0 redis==5.2.1
```
* 案例测试
```python
from langchain_redis import RedisChatMessageHistory
import os
REDIS_URL = os.getenv("REDIS_URL", "redis://47.119.128.20:6379")
#配置了密码 REDIS_URL = "redis://:your_password@your_ip:6379"
#REDIS_URL = os.getenv("REDIS_URL", "redis://:abc123456@39.108.115.28:6379")
# 初始化 RedisChatMessageHistory
history = RedisChatMessageHistory(session_id="user_123", redis_url=REDIS_URL)
# 新增消息
history.add_user_message("Hello, AI assistant!")
history.add_ai_message("Hello! How can I assist you today?")
# 检索消息
print("Chat History:")
for message in history.messages:
print(f"{type(message).__name__}: {message.content}")
```
* 编码实战
```python
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_openai import ChatOpenAI
from langchain_redis import RedisChatMessageHistory
#存储历史会话的字典
REDIS_URL="redis://47.119.128.20:6379"
#定义函数,用于获取会话历史
def get_redis_history(session_id: str):
return RedisChatMessageHistory(session_id, redis_url=REDIS_URL)
# 初始化大模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 构建聊天提示模板,包含系统消息、历史消息占位符和人类消息
prompt = ChatPromptTemplate.from_messages(
[
("system","你是一个小滴课堂AI助手,擅长能力{ability}。用30个字以内回答",),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
#创建基础链
chain = prompt | model
with_message_history = RunnableWithMessageHistory(
chain, get_redis_history, input_messages_key="input", history_messages_key="history"
)
#第一次调用,提供用户输入和会话ID
resp1 = with_message_history.invoke(
{"ability":"Java开发", "input":HumanMessage("什么是JVM")}, #替换提示词
config={"configurable":{"session_id":"user_123"} }) #会话唯一ID
print(f"resp1={resp1.content}",end="\n\n")
resp2 = with_message_history.invoke(
{"ability":"Java开发", "input":HumanMessage("重新回答一次")}, #替换提示词
config={"configurable":{"session_id":"user_123"} }) #会话唯一ID
print(f"resp2={resp2.content}",end="\n\n")
```
* 注意: 安全起见,RedisStack还是需要配置密码,避免入侵挖矿
```dockerfile
docker run -d \
--name redis-stack \
-p 6379:6379 \
-p 8001:8001 \
-e REDIS_ARGS="--requirepass abc123456" \
redis/redis-stack:latest
```
* 多租户多会话方案
```python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai.chat_models import ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables import ConfigurableFieldSpec
from langchain_redis import RedisChatMessageHistory
#存储历史会话的字典
REDIS_URL="redis://:abc123456@47.119.128.20:6379"
# 获取会话历史的函数 如果给定的session_id不在store中,则为其创建一个新的ChatMessageHistory实例
def get_session_history(user_id: str,session_id: str):
uni_key = user_id+"_"+session_id
return RedisChatMessageHistory(
session_id=uni_key,
redis_url=REDIS_URL)
# 初始化大模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7
)
# 构建聊天提示模板,包含系统消息、历史消息占位符和人类消息
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"你是一个小滴课堂AI助手,擅长能力{ability}。用30个字以内回答",
),
MessagesPlaceholder(variable_name="history"),
("human", "{input}"),
]
)
# 创建Runnable管道,将提示模板和模型结合在一起
runnable = prompt | model
# 创建带有会话历史的Runnable ,使用get_session_history函数来管理会话历史
with_message_history = RunnableWithMessageHistory(
runnable,
get_session_history,
input_messages_key="input", #输入消息在字典中的键名(默认"input")
history_messages_key="history", #历史消息在字典中的键名(默认"history")
# 定义一些自定义的参数
history_factory_config=[
ConfigurableFieldSpec(
id="user_id",
annotation=str,
name="用户ID",
description="用户的唯一标识符。",
default="",
is_shared=True,
),
ConfigurableFieldSpec(
id="session_id",
annotation=str,
name="对话 ID",
description="对话的唯一标识符。",
default="",
is_shared=True,
),
]
)
# 第一次调用带有会话历史的Runnable,提供用户输入和会话ID
response1=with_message_history.invoke(
{"ability": "Java开发", "input": HumanMessage("什么是jvm")},
config={'configurable' : { "user_id" : "user_1" , "session_id" : "session_1" }}
)
print(f"response1:{response1.content}",end="\n\n")
# 打印存储的会话历史
print(get_session_history("user_1","session_1").messages)
# 第二次调用带有会话历史的Runnable,用户请求重新回答上一个问题
response2=with_message_history.invoke(
{"ability": "Java开发", "input": HumanMessage("重新回答一次")},
config={'configurable' : { "user_id" : "user_2" , "session_id" : "session_1" }},
)
print(f"response2:{response2.content}",end="\n\n")
# 打印存储的会话历史
print(get_session_history("user_2","session_1").messages)
```
### 大模型服务必备FastAPI Web框架
#### Python Web框架Fast API技术介绍
* 需求背景:现代Web开发痛点
* 传统框架(如Flask、Django)对异步支持弱,性能受限。
* 手动编写API文档耗时且易过时、缺乏自动化数据验证,易出现安全漏洞。
* FastAPI是什么?
- 一个基于 Python 3.8+ 的现代 Web 框架,专为构建高性能 API 设计。
- 官方地址:
- https://github.com/fastapi/fastapi
- https://fastapi.tiangolo.com/
- 关键特性:
- ⚡ 高性能:基于Starlette(异步)和Pydantic(数据验证)
- 📚 自动文档:集成Swagger UI和Redoc,代码即文档。
- ✅ 强类型安全:Python类型提示 + Pydantic模型,减少Bug。
- 🚀 易学易用:代码简洁,适合快速开发API。
- 适用场景
* 构建 RESTful API 或 大模型服务,微服务架构中的独立服务模块。
* 需要自动生成 API 文档的项目。
* **核心价值**:FastAPI = 高性能 + 强类型 + 自动文档。
- **优点**:
- 开发效率高(代码量减少 40%+)
- 严格的类型提示减少运行时错误。
- **缺点**:
- 生态相对较新(插件和社区资源少于 Django/Flask)。
- 学习曲线略高(需熟悉 异步编程)。
* 什么是 Uvicorn(类似Java 生态的Tomcat)
* 是一个轻量级、高性能的 **ASGI(Asynchronous Server Gateway Interface)服务器**
* 专门运行异步 Python Web 应用(如 FastAPI、Starlette 或 Django Channels)。
* 类似传统 WSGI 服务器 的异步升级版,支持 HTTP/1.1、WebSockets 和 ASGI 标准。
* **核心功能**
* **异步处理**:基于 `asyncio` 库,原生支持 `async/await`,适合高并发场景(如实时通信、高频 API 调用)。
* **高性能**:使用 C 语言编写的 `uvloop` 和 `httptools` 加速网络请求处理。
* **自动重载**:开发时通过 `--reload` 参数监听代码变动,自动重启服务。
* **协议支持**: HTTP/1.1 、WebSocket、实验性 HTTP/2(需额外配置)
* 与 FastAPI 的关系
* 依赖关系:FastAPI 本身不包含服务器,需通过 Uvicorn(或其他 ASGI 服务器)启动。
* 协同工作流程:
* 用户通过 Uvicorn 启动 FastAPI 应用。
* Uvicorn 监听 HTTP 请求,将请求转发给 FastAPI 处理。
* FastAPI 处理请求并返回响应,由 Uvicorn 发送给客户端
* 类似产品对比
| 框架 | 语言 | 特点 | 适用场景 |
| :-------------- | :------ | :----------------------------------- | :---------------------- |
| **Flask** | Python | 轻量级、灵活,但同步且无内置数据验证 | 小型应用、快速原型开发 |
| **Django** | Python | 全功能(ORM、Admin),但重量级、同步 | 复杂 Web 应用(如 CMS) |
| **Express** | Node.js | 高并发,但动态类型易出错 | JS 生态的 API 开发 |
| **Spring Boot** | Java | 企业级功能,但配置复杂、启动慢 | 大型分布式系统 |
| **FastAPI** | Python | 高性能、异步、类型安全、自动文档 | 高并发 API、微服务 |
#### FastAPI环境安装和基础案例实战
* 环境安装
* FastAPI 依赖 Python 3.8 及更高版本, 安装fastapi版本 `0.115.12`
* 安装命令
* 安装依赖库. `pip install "fastapi[standard]"`
* 安装uvicorn服务器 `pip install "uvicorn[standard]"`
* 案例实战
* 创建第一个Fast API应用
```python
from typing import Union
from fastapi import FastAPI
# 创建FastAPI实例
app = FastAPI()
#http请求方式类型:get、post、put、update、delete
#不带参数访问路由
@app.get("/")
def read_root():
return {"Hello": "World11"}
# 带参数访问,比如 http://127.0.0.1:8000/items/5?q=xd
# q参数通过 Union[str, None] 表示可以是字符串类型或空,这样就允许在请求中不提供 q 参数。
@app.get("/items/{item_id}")
def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
```
* 启动服务
```python
# 语法:uvicorn 文件的相对路径:实例名 --reload
# 多级目录使用.,例如: uvicorn xx.xx.main:app -- reload
#--reload:代码修改后自动重启(仅开发环境)
# main:当前目录下的main.py文件,app:文件下的app实例变量
uvicorn main:app --reload
#指定程序监听端口
uvicorn main:app --port 8002 --reload
#下面这个方式也可以
fastapi dev main.py
```
* 访问API与文档
* API地址:`http://localhost:8000`
* 交互文档:`http://localhost:8000/docs`
* 备用文档( 另一种交互式文档界面,具有清晰简洁的外观 ):`http://localhost:8000/redoc`
#### 进阶FastAPI Web多案例参数请求实战
* 路由与 HTTP 方法
```python
from fastapi import FastAPI
app = FastAPI()
@app.get("/items/{item_id}")
def read_item(item_id: int): # 自动类型转换和验证
return {"item_id": item_id}
@app.post("/items/")
def create_item(item: dict):
return {"item": item}
@app.put("/items/{item_id}")
def update_item(item_id: int, item: dict):
return {"item_id": item_id, "updated_item": item}
@app.delete("/items/{item_id}")
def delete_item(item_id: int):
return {"status": "deleted", "item_id": item_id}
```
* 请求头Header操作
```python
from fastapi import Header
@app.get("/header")
def read_item(item_id: int, token: str = Header("token")):
return {"token": token,"item_id": item_id}
```
* 获取多个请求头
```python
from fastapi import Request
@app.get("/all-headers/")
def get_all_headers(request: Request):
return dict(request.headers)
```
* 自定义响应头
```python
from fastapi.responses import JSONResponse
@app.get("/custom-header/")
def set_custom_header():
content = {"message": "Hello World"}
headers = {
"X-Custom-Header": "my_value xdclass.net",
"Cache-Control": "max-age=3600"
}
return JSONResponse(content=content, headers=headers)
```
* 自定义响应码
```python
from fastapi import FastAPI, status,Response
@app.get("/status_code", status_code=200)
def create_item(name: str):
if name == "Foo":
return Response(status_code=status.HTTP_404_NOT_FOUND)
return {"name": name}
```
#### FastAPI异步编程async-await多案例实战
* 需求背景
* 什么是同步和异步? 用一个奶茶店买饮料的场景帮理解同步和异步的区别
* 🧋 **同步(Synchronous)就像传统奶茶店**
```markdown
你: 老板,我要一杯珍珠奶茶
店员: 开始制作(5分钟)
你: 干站着等,不能做其他事
店员: 做好了!请取餐
下一位顾客: 必须等前一个人完成才能点单
特点: 必须按顺序处理,前一个任务没完成,后面全卡住
```
* 🚀 异步(Asynchronous)像智能奶茶店
```markdown
你: 扫码下单珍珠奶茶
系统: 收到订单(生成取餐号)
你: 去旁边座位玩手机(不用干等)
店员: 同时处理多个订单
系统: 奶茶做好后叫号通知你
特点: 下单后可以继续做其他事,系统并行处理多个任务
```
* 对应到代码中
```markdown
# 同步代码(传统奶茶店模式)
def make_tea():
print("开始煮茶") # 👨🍳 店员开始工作
time.sleep(3) # ⏳ 你干等着
print("加珍珠")
return "奶茶好了"
# 异步代码(智能奶茶店模式)
async def async_make_tea():
print("开始煮茶")
await asyncio.sleep(3) # 🚶♂️ 你可以去做其他事
print("加珍珠")
return "奶茶好了"
```
* 同步和异步关键区别总结【伪代码】
* 同步版本(存在性能瓶颈)
```python
import requests
@app.get("/sync-news")
def get_news_sync():
# 顺序执行(总耗时=各请求之和)
news1 = requests.get("https://api1.com").json() # 2秒
news2 = requests.get("https://api2.com").json() # 2秒
return {"total_time": 4}
```
* 异步版本(高效并发)
```python
import httpx
@app.get("/async-news")
async def get_news_async():
async with httpx.AsyncClient() as client:
# 并行执行(总耗时≈最慢的请求)
start = time.time()
task1 = client.get("https://api1.com")
task2 = client.get("https://api2.com")
res1, res2 = await asyncio.gather(task1, task2)
return {
"total_time": time.time() - start # ≈2秒
}
```
* 异步编程常见类库介绍
* * `asyncio` 类库
* Python 中用于编写**单线程并发代码**的库,基于**协程(Coroutine)**和**事件循环(Event Loop)**实现异步编程。
* 专为处理 I/O 密集型任务(如网络请求、文件读写、数据库操作)设计,提高程序的吞吐量和资源利用率
* **协程(Coroutine)**
- 使用 `async def` 定义的函数称为协程,返回一个协程对象,不会立即执行。
- 协程通过 `await` 关键字挂起自身,将控制权交还给事件循环,直到异步操作完成
```
async def my_coroutine():
await asyncio.sleep(1)
print("Done!")
```
* **事件循环(Event Loop)**
- 事件循环是异步程序的核心,负责调度和执行协程、处理 I/O 事件、管理回调等。
- 通过 `asyncio.run()` 或手动创建事件循环来启动。
```python
# 启动事件循环并运行协程
asyncio.run(my_coroutine())
```
* **任务(Task)**
- 任务是对协程的封装,用于在事件循环中并发执行多个协程。
- 通过 `asyncio.create_task()` 创建任务
```python
async def main():
task = asyncio.create_task(my_coroutine())
await task
```
* **Future**
- `Future` 是一个底层对象,表示异步操作的最终结果。通常开发者直接使用 `Task`(它是 `Future` 的子类)。
* `httpx` 类库
* Python 中一个现代化、功能丰富的 HTTP 客户端库,支持同步和异步请求
* `httpx` 是 `requests` 的现代替代品,结合了易用性与强大功能,尤其适合需要异步或 HTTP/2 支持的场景。
* 同步请求案例
```python
import httpx
# GET 请求
response = httpx.get("https://httpbin.org/get")
print(response.status_code)
print(response.json())
```
* 异步请求案例
```python
import httpx
import asyncio
async def fetch_data():
async with httpx.AsyncClient() as client:
response = await client.get("https://httpbin.org/get")
print(response.json())
asyncio.run(fetch_data())
```
* 使用客户端实例(推荐)
```python
# 同步客户端
with httpx.Client() as client:
response = client.get("https://httpbin.org/get")
# 异步客户端
async with httpx.AsyncClient() as client:
response = await client.get("https://httpbin.org/get")
```
* 案例实战
* 基础同步和异步编程
```python
from fastapi import FastAPI
import asyncio
import time
app = FastAPI()
# 同步路由执行(顺序阻塞)
@app.get("/sync_func")
def sync_endpoint():
# 模拟耗时操作
print("开始任务1") # 立即执行
time.sleep(3) # 阻塞3秒
print("开始任务2") # 3秒后执行
return {"status": "done"}
# 异步异步执行(非阻塞切换)
@app.get("/async_func")
async def async_endpoint(): # 异步接口
# 必须使用异步库
print("开始任务A") # 立即执行
await asyncio.sleep(3) # 释放控制权,异步等待
print("开始任务B") # 3秒后恢复执行
return {"status": "done"}
```
* 综合案例实战:并发调用外部API
```python
import asyncio
import httpx
from fastapi import FastAPI
app = FastAPI()
"""
异步函数:fetch_data
功能:通过HTTP GET请求从指定URL获取数据并返回JSON格式的响应。
参数:
url (str): 目标API的URL地址。
返回值:
dict: 从目标URL获取的JSON格式数据。
"""
async def fetch_data(url: str):
async with httpx.AsyncClient() as client:
response = await client.get(url)
return response.json()
"""
路由处理函数:get_news
功能:定义一个FastAPI的GET路由,用于并发获取多个API的数据并返回整合后的结果。
"""
@app.get("/xdclass")
async def get_news():
start = time.time()
# 定义需要请求的API URL列表
urls = [
"https://api-v2.xdclass.net/api/funny/v1/get_funny",
"https://api-v2.xdclass.net/api/banner/v1/list?location=home_top_ad",
"https://api-v2.xdclass.net/api/rank/v1/hot_product",
"http://localhost:8000/sync1",
"http://localhost:8000/sync2",
]
# 创建并发任务列表,每个任务调用fetch_data函数获取对应URL的数据
tasks = [fetch_data(url) for url in urls]
# 使用asyncio.gather并发执行所有任务,并等待所有任务完成
results = await asyncio.gather(*tasks)
print(f"共耗时 {time.time() - start} 秒")
# 返回整合后的结果
return results
```
* 常见错误模式演示
```python
# 错误示例:在async函数中使用同步阻塞
@app.get("/wrong")
async def bad_example():
time.sleep(5) # 会阻塞整个事件循环!
# 正确方案1:改用异步等待
@app.get("/right1")
async def good_example():
await asyncio.sleep(5)
```
* 最佳实践指南
* **必须使用async的三种场景**
* 需要await调用的异步库操作
* WebSocket通信端点
* 需要后台任务处理的接口
* **以下情况适合同步路由**
- 纯CPU计算(如数学运算)
- 使用同步数据库驱动
- 快速返回的简单端点
* **路由声明规范**
* 所有路由优先使用`async def`
* 仅在必须使用同步操作时用普通 `def`
* **性能优化建议**
- 保持async函数轻量化
- 长时间CPU密集型任务使用后台线程
- 使用连接池管理数据库/HTTP连接
#### 进阶FastAPI模型Pydantic 案例实战
* 什么是数据模型
* 客户端能发送什么数据
* 服务端会返回什么数据
* 数据验证规则
* 基础模型定义
```python
from pydantic import BaseModel
# 用户注册模型
class UserRegister(BaseModel):
username: str # 必填字段
email: str | None = None # 可选字段
age: int = Field(18, gt=0) # 带默认值和验证
```
* 案例实战
* 请求体(POST/PUT数据)
```python
from pydantic import BaseModel,Field
class Product(BaseModel):
name: str
price: float = Field(..., gt=0)
tags: list[str] = []
@app.post("/products")
async def create_product(product: Product):
return product.model_dump()
#测试数据
{
"name":"小滴",
"price":111,
"tags":["java","vue"]
}
```
* 返回 Pydantic 模型
```python
from pydantic import BaseModel
class Item(BaseModel):
name: str
description: str = None
price: float
tax: float = None
@app.post("/items")
async def create_item(item: Item):
return item
#测试数据
{
"name":"小滴",
"price":111,
"description":"小滴课堂是在线充电平台"
}
```
* 密码强度验证
```python
from pydantic import BaseModel, field_validator
class UserRegistration(BaseModel):
username: str
password: str
@field_validator('password')
def validate_password(cls, v):
if len(v) < 8:
raise ValueError('密码至少8位')
if not any(c.isupper() for c in v):
raise ValueError('必须包含大写字母')
if not any(c.isdigit() for c in v):
raise ValueError('必须包含数字')
return v
@app.post("/register/")
async def register(user: UserRegistration):
return {"username": user.username}
#测试数据
{
"username":"小滴",
"password":"123"
}
```
### FastAPI框架高级技能和综合项目实战
#### FastAPI路由管理APIRouter案例实战
* 需求背景
* 代码混乱问题, 未使用路由管理(所有接口堆在main.py中)
* 所有接口混杂在一个文件中,随着功能增加,文件会变得臃肿难维护。
```python
# main.py
from fastapi import FastAPI
app = FastAPI()
# 用户相关接口
@app.get("/users")
def get_users(): ...
# 商品相关接口
@app.get("/items")
def get_items(): ...
# 订单相关接口
@app.get("/orders")
def get_orders(): ...
```
* 重复配置问题, 未使用路由管理(重复写前缀和标签)
* 每个接口都要重复写`/api/v1`前缀和`tags`,容易出错且难以统一修改
```python
# 用户接口
@app.get("/api/v1/users", tags=["用户管理"])
def get_users_v1(): ...
# 商品接口
@app.get("/api/v1/items", tags=["商品管理"])
def get_items_v1(): ...
```
* 权限控制问题, 未使用路由管理(每个接口单独添加认证)
* 需要在每个管理员接口重复添加认证依赖。
```python
@app.get("/admin/stats", dependencies=[Depends(admin_auth)])
def get_stats(): ...
@app.post("/admin/users", dependencies=[Depends(admin_auth)])
def create_user(): ...
```
* **使用路由管理(模块化拆分)**
* 按业务模块拆分,每个文件职责单一。
```python
# 文件结构
routers/
├── users.py # 用户路由
├── items.py # 商品路由
└── orders.py # 订单路由
# main.py
from routers import users, items, orders
app.include_router(users.router)
app.include_router(items.router)
app.include_router(orders.router)
```
* 使用路由管理
```python
# 创建管理员专属路由组
admin_router = APIRouter(
prefix="/admin",
dependencies=[Depends(admin_auth)], # 👈 统一认证
tags=["管理员"]
)
@admin_router.get("/stats")
def get_stats(): ...
@admin_router.post("/users")
def create_user(): ...
```
* `APIRouter`核心概念
* 基础使用模板
```python
from fastapi import APIRouter
router = APIRouter(
prefix="/users", # 路由前缀
tags=["用户管理"], # OpenAPI分组
responses={404: {"description": "资源未找到"}} # 默认响应
)
@router.get("/", summary="获取用户列表")
async def list_users():
return [{"id": 1, "name": "张三"}]
```
* 核心配置参数
| 参数 | 作用 | 示例值 |
| :----------: | :--------------: | :---------------------: |
| prefix | 路由统一前缀 | "/api/v1" |
| tags | OpenAPI文档分组 | ["认证相关"] |
| dependencies | 路由组公共依赖项 | [Depends(verify_token)] |
| responses | 统一响应定义 | {400: {"model": Error}} |
* 案例实战
* 创建文件` app/users.py`
```python
from fastapi import APIRouter, HTTPException
from pydantic import BaseModel
router = APIRouter(
prefix="/users", # 路由前缀
tags=["用户管理"], # OpenAPI文档分组
dependencies=[] # 模块级依赖
)
@router.get("/", summary="获取用户列表")
async def list_users():
return [{"id": 1, "name": "Alice"}]
@router.post("/", summary="创建新用户")
async def create_user():
return {"id": 2, "name": "Bob"}
class UserCreate(BaseModel):
username: str
password: str
@router.post("/register", status_code=201)
async def register(user: UserCreate):
"""用户注册接口"""
# 实际应保存到数据库
return {"message": "用户创建成功", "username": user.username}
@router.get("/{user_id}")
async def get_user(user_id: int):
if user_id > 100:
raise HTTPException(404, "用户不存在")
return {"user_id": user_id, "name": "虚拟用户"}
```
* 创建文件 `app/products.py`
```python
# app/api/v1/products.py
from fastapi import APIRouter
router = APIRouter(
prefix="/products",
tags=["商品管理"],
dependencies=[]
)
@router.get("/search", summary="商品搜索")
async def search_products(
q: str,
min_price: float = None,
max_price: float = None
):
# 实现搜索逻辑
return {"message": "搜索成功"}
@router.get("/{product_id}", summary="获取商品详情")
async def get_product_details(product_id: int):
return {"id": product_id}
```
* 创建入口文件 `main.py`
```python
from fastapi import FastAPI
from app import users, products
import uvicorn
# 创建FastAPI应用实例
app = FastAPI()
# 注册用户模块的路由
app.include_router(users.router)
# 注册产品模块的路由
app.include_router(products.router)
# 访问路径:
# GET /users/ → 用户列表
# POST /users/ → 创建用户
#...
# 打印所有注册的路由信息,便于开发者查看和调试
for route in app.routes:
print(f"{route.path} → {route.methods}")
# 定义根路径的GET请求处理函数
"""
处理根路径的GET请求。
返回值:
dict: 返回一个JSON对象,包含欢迎消息。
"""
@app.get("/")
async def root():
return {"message": "Hello 小滴课堂"}
# 主程序入口,用于启动FastAPI应用
if __name__ == '__main__':
# 使用uvicorn运行FastAPI应用,默认监听本地地址和端口
uvicorn.run(app,port=8001)
```
* 模块化结构参考
```python
#整体项目结构
project/
├── main.py
└── routers/
├── __init__.py
├── users.py
├── items.py
├── admin/
│ ├── dashboard.py
│ └── audit.py
└── v2/
└── users.py
```
* 总结
| 实践要点 | 说明 |
| :----------: | :------------------------------------: |
| 模块化组织 | 按业务功能拆分路由模块 |
| 统一前缀管理 | 使用`prefix`参数避免路径重复 |
| 文档友好 | 合理使用`tags`和`summary`优化API文档 |
| 依赖分层 | 模块级依赖处理认证,路由级处理业务逻辑 |
#### FastAPI依赖注入和常见项目结构设计
* 什么是依赖注入
* 用于将重复逻辑(如鉴权、数据库连接、参数校验)抽象为可复用的组件,
* 通过依赖注入(Dependency Injection)自动注入到路由处理函数中,让代码更简洁、模块化且易于测试
* 核心
* **代码复用**:避免在多个路由中重复相同逻辑(如权限检查)。
* **解耦**:将业务逻辑与基础设施(如数据库、认证)分离。
* **层级化**:支持嵌套依赖,构建多层逻辑(如先验证用户,再验证权限)
* 与 Java Spring 对比
| **功能** | **FastAPI** | **Spring (Java)** |
| :----------- | :-------------------- | :----------------------------- |
| **依赖注入** | 函数/类 + `Depends()` | `@Autowired` + 容器管理 |
| **作用域** | 默认每次请求 | Singleton/Prototype/Request 等 |
* 语法案例
* **定义依赖项函数**
* 依赖项可以是任何可调用对象(如函数、类),通过 `Depends()` 声明依赖关系
```python
from fastapi import Depends, FastAPI
app = FastAPI()
# 定义一个依赖项(函数)
def common_params(query: str = None, page: int = 1):
return {"query": query, "page": page}
# 在路由中使用依赖项
@app.get("/read_items")
async def read_items(params: dict = Depends(common_params)):
return params
#说明:common_params 会被自动调用,结果注入到 params 参数。
#访问结果:read_items 中可直接使用 params["query"] 和 params["page"]。
```
* 类作为依赖项
* 依赖项也可以是类,适合需要初始化或状态管理的场景, 通过依赖注入机制,将复杂逻辑解耦为可复用的模块
```python
#案例一
class DatabaseSession:
def __init__(self):
self.session = "模拟数据库连接"
def close(self):
print("关闭数据库连接")
def get_db():
db = DatabaseSession()
try:
yield db
finally:
db.close()
@app.get("/users/")
async def get_users(db: DatabaseSession = Depends(get_db)):
return {"db_session": db.session}
#案例二
class Pagination:
def __init__(self, page: int = 1, size: int = 10):
self.page = page
self.size = size
@app.get("/articles/")
async def get_articles(pagination: Pagination = Depends()):
return {"page": pagination.page, "size": pagination.size}
```
* 全局依赖项
* 为所有路由添加公共依赖项(如统一认证)
```python
app = FastAPI(dependencies=[Depends(verify_token)])
# 或针对特定路由组:
router = APIRouter(dependencies=[Depends(log_request)])
#在部分管理员接口添加认证依赖。
@app.get("/admin/stats", dependencies=[Depends(admin_auth)])
def get_stats(): ...
@app.post("/admin/users", dependencies=[Depends(admin_auth)])
def create_user(): ...
```
* FastAPI 项目结构设计原则
* 基础分层结构(适合小型项目)
```python
myproject/
├── main.py
├── routers/
│ ├── users.py
│ └── items.py
├── models/
│ └── schemas.py
└── dependencies.py
```
* 模块化拆分结构一(推荐中型项目)
```python
src/
├── app/
│ ├── core/ # 核心配置
│ │ ├── config.py
│ │ └── security.py
│ ├── api/ # 路由入口
│ │ ├── v1/ # 版本控制
│ │ │ ├── users/
│ │ │ │ ├── endpoints.py
│ │ │ │ └── schemas.py
│ │ │ └── items/
│ ├── models/ # 数据模型
│ ├── services/ # 业务逻辑
│ └── utils/ # 工具类
├── tests/ # 测试目录
└── requirements.txt
```
* 模块化拆分结构二(推荐中型项目)
```python
myproject/
├── app/ # 应用核心目录
│ ├── core/ # 全局配置和工具
│ │ ├── config.py # 配置管理
│ │ └── security.py # 安全相关工具
│ ├── api/ # 路由端点
│ │ ├── v1/ # API版本目录
│ │ │ ├── users.py
│ │ │ ├── items.py
│ │ │ └── ai.py
│ │ └── deps.py # 公共依赖项
│ ├── models/ # Pydantic模型
│ │ ├── user.py
│ │ └── item.py
│ ├── services/ # 业务逻辑层
│ │ ├── user_service.py
│ │ └── ai_service.py
│ ├── db/ # 数据库相关
│ │ ├── session.py # 数据库会话
│ │ └── models.py # SQLAlchemy模型
│ └── utils/ # 工具函数
│ └── logger.py
├── tests/ # 测试目录
│ ├── test_users.py
│ └── conftest.py
├── static/ # 静态文件
├── main.py # 应用入口
├── requirements.txt
└── .env # 环境变量
```
* 推荐原则【遵循团队规范即可】
| 原则 | 实施方法 |
| :------: | :--------------------------------: |
| 单一职责 | 每个文件/类只做一件事 |
| 依赖倒置 | 通过依赖注入解耦组件 |
| 分层清晰 | 严格区分路由层、服务层、数据访问层 |
| 版本控制 | 通过URL路径实现API版本管理 |
| 文档友好 | 为每个路由添加summary和description |
#### FastAPI+大模型流式AI问答助手实战
* 需求
* 开发一个基于AI的问答工具,能够根据用户提供的知识点或主题生成简洁的介绍或解释。
* 使用了大语言模型(LLM)来实现流式生成文本的功能,适用于教育、内容创作等场景
* FastAPI框架整合LLM大模型,提供HTTP服务
* `StreamingResponse` 介绍
* FastAPI 的提供了 `StreamingResponse` 是一个用于处理流式传输数据的工具,适用于需要逐步发送大量数据或实时内容的场景。
* 允许通过生成器逐块发送数据,避免一次性加载全部内容到内存,提升性能和资源利用率。
```
from fastapi.responses import StreamingResponse
```
* 核心功能
* 流式传输:逐步发送数据块,适用于大文件(如视频、日志)、大模型实时生成内容(如LLM响应、服务器推送事件)或长时间运行的任务。
* 内存高效:无需将完整数据加载到内存,减少服务器负载。
* 异步支持:兼容同步和异步生成器,灵活适配不同场景。
* 基本用法
* 在路由中返回 `StreamingResponse` 实例,并传入生成器作为数据源
* 参数说明
* `content`: 生成器函数,产生字节或字符串数据块。
* `media_type`: 指定 MIME 类型(如 `"text/event-stream"`、`"application/json"`)。
* `headers`: 自定义响应头(如 `{"Content-Disposition": "attachment; filename=data.csv"}`)。
* `status_code`: 设置 HTTP 状态码(默认为 `200`)。
* 案例实操
```python
async def ai_qa_stream_generator(query: str):
"""生成A回答的流式响应"""
try:
async for chunk in ai_writer.run_stream(query):
json_data = json.dumps({"text": chunk})
yield f"data: {json_data}\n\n"
except Exception as e:
error_msg = json.dumps({"error": str(e)})
yield f"data: {error_msg}\n\n"
@app.get("/ai_write")
async def ai_writer_endpoint(query: str):
"""AI写作接口,返回流式响应"""
return StreamingResponse(
ai_qa_stream_generator(query),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive"
}
)
```
* 编码实战 `app/ai_writer.py`
```python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from typing import AsyncGenerator
# 封装AI问答的类
class AIWriter:
def __init__(self):
# 初始化语言模型
self.llm = self.llm_model()
# 定义一个返回自定义语言模型的方法
def llm_model(self):
#创建模型
model = ChatOpenAI(
model_name = "qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key="sk-005c3c25f6d042848b29d75f2f020f08",
temperature=0.7,
streaming=True
)
return model
async def run_stream(self, query: str) -> AsyncGenerator[str, None]:
"""运行AI问答并返回流式响应"""
try:
# 定义提示模板,要求对文档进行摘要总结
prompt_template = "用100个字解释下面的知识点或者介绍:{concept}"
# 使用提示模板类创建模板
prompt = ChatPromptTemplate.from_template(prompt_template)
# 定义LLM链,将自定义语言模型和提示模板结合
chain = prompt | self.llm | StrOutputParser()
# 使用流式输出
async for chunk in chain.astream({"concept": query}):
if isinstance(chunk, str):
yield chunk
elif isinstance(chunk, dict) and "content" in chunk:
yield chunk["content"]
else:
yield str(chunk)
except Exception as e:
yield f"发生错误: {str(e)}"
async def chat(self, query: str):
"""处理用户消息并返回流式响应"""
try:
async for chunk in self.run_stream(query):
yield chunk
except Exception as e:
yield f"发生错误: {str(e)}"
```
* 编码实战 `writer_app.py`
```python
import uvicorn
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
from app.ai_writer import AIWriter
import json
app = FastAPI()
# 初始化智能体
ai_writer = AIWriter()
async def ai_qa_stream_generator(query: str):
"""生成A回答的流式响应"""
try:
async for chunk in ai_writer.run_stream(query):
json_data = json.dumps({"text": chunk}, ensure_ascii=False)
yield f"data: {json_data}\n\n"
except Exception as e:
error_msg = json.dumps({"error": str(e)})
yield f"data: {error_msg}\n\n"
@app.get("/ai_write")
async def ai_writer_endpoint(query: str):
"""AI写作接口,返回流式响应"""
return StreamingResponse(
ai_qa_stream_generator(query),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive"
}
)
# 启动服务器的命令
if __name__ == "__main__":
uvicorn.run(app, port=8003)
```
* 如何调试
* Apifox 提供了专门的 SSE(Server-Sent Events)调试功能,适合处理 AI 大模型的流式响应场景
* 配置 SSE,选择接口的请求方法,在请求头中添加 `Accept: text/event-stream` 来启用 SSE。
### LLM大模型Web服务智能体中心开发实战
#### AI智能体中心Web服务架构和相关环境创建
* 需求说明
* 基于前面学的`langchain+fastapi`+多个知识点,综合开发大模型Web服务,包括多个智能体
* 部分智能体可以结合网盘业务进行,部分智能体可以独立运行
* 注意
* **智能体中心包括多个应用,非强行绑定,可以结合自己公司业务灵活切换包装简历**
* **要学会举一反三,结合前面的内容进行拓展更多,比如AI医生、AI律师、AI政务等**
* 智能体业务架构图
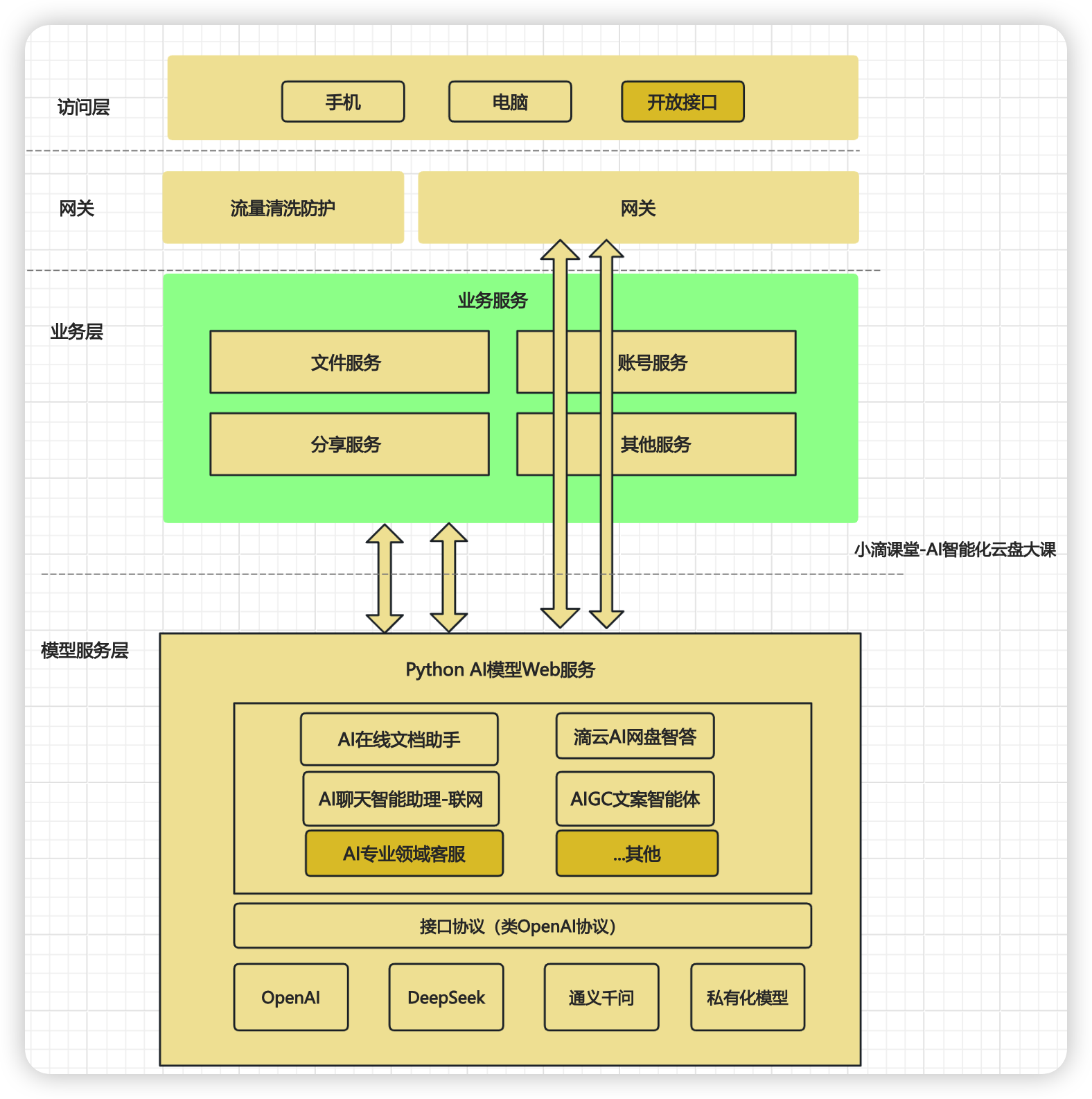 * 项目依赖环境创建
* 项目名称:`dcloud-ai-agent`
* 创建虚拟环境
```
# 语法:python -m venv <环境目录名>
python -m venv myenv
```
* 激活虚拟环境
```
source myenv/bin/activate
```
* 安装核心依赖包 (**版本和课程保持一致,不然很多不兼容!!!**)
* 下载相关资料 ,使用**【wget】或者【浏览器】远程下载相关依赖包(需要替换群里最新的)**
```
原生资料下载方式(账号 - 密码 - ip地址 - 端口 需要替换群里最新的,【其他路径不变】)
wget --http-user=用户名 --http-password=密码 http://ip:端口/dcloud_pan/aipan_agent_1.zip
#比如 命令行下
wget --http-user=admin --http-password=xdclass.net888 http://47.115.31.28:9088/dcloud_pan/aipan_agent_1.zip
# 比如 浏览器直接访问
http://47.115.31.28:9088/dcloud_pan/aipan_agent_1.zip
```
* 解压后执行【**依赖很多,版本差异大,务必按照下面执行,否则课程无法进行下去,加我微信 xdclass6**】
```
# 安装依赖
pip install -r requirements.txt
```
#### AI智能体中心Web项目搭建和基础配置
* 项目基本目录结构-创建对应的目录
```python
dcloud-agent/
├── agents/ # 智能代理相关代码
├── app/ # 应用主目录
│ └── main.py # 应用入口文件
├── core/ # 核心功能模块
├── models/ # 数据模型定义
├── routers/ # API路由定义
├── services/ # 业务服务层
├── tests/ # 测试代码
├── tools/ # 工具函数和辅助类
├── myenv/ # Python虚拟环境
├── Dockerfile # Docker容器配置
├── README.md # 项目说明文档
└── requirements.txt # 项目依赖包列表【不提供,参考上集,进大课群下载】
```
* 编写主入口文件
```python
import uvicorn
from fastapi import FastAPI
from core.config import settings
from routers import chat
app = FastAPI(
title=settings.APP_NAME,
description="AI智能体中心API服务",
version="1.0.0"
)
# 注册路由
app.include_router(chat.router)
@app.get("/")
async def root():
return {
"message": "欢迎使用AI智能体中心API",
"version": "1.0.0",
"available_agents": ["chat"] # 列出可用的智能体
}
# 启动服务器的命令 uvicorn app.main:app --reload
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
```
* 隐藏pychche文件
* 打开 首选项 --> 设置 --> 搜索框中 搜索 files.exclude --> 点击 "添加模式" 按钮
* 输入想要隐藏的文件夹, 如python经常生成的缓存文件夹, 输入 `**/__pycache`__ 即可隐藏 `__pycache__` 文件夹.
#### AI智能体中心FastAPI自定义异常+统一响应
**简介: AI智能体中心FastAPI自定义异常+统一响应**
* 需求
* Web响应一般都会进行自定义异常+统一响应
* 前端方便对接和记录相关业务操作日志
* 编码实战
* 自定义异常,创建一个 `exceptions.py` 文件
* 定义一个继承自 `Exception` 的自定义异常类,可以添加额外的字段(如错误码、错误信息等)
* 定义一个接收 `Request` 和 `Exception` 参数的函数,返回标准的 `JSONResponse`
```python
from fastapi import HTTPException, status
from fastapi.responses import JSONResponse
from typing import Any
from models.json_response import JsonData
class ApiException(Exception):
"""API异常基类"""
def __init__(
self,
msg: str = "操作失败",
code: int = -1,
data: Any = None
):
self.msg = msg
self.code = code
self.data = data
super().__init__(msg)
async def api_exception_handler(request, exc: Exception) -> JSONResponse:
"""统一异常处理器"""
print(f"❌ API异常: {str(exc)}")
if isinstance(exc, ApiException):
response = JsonData.error(msg=exc.msg, code=exc.code)
elif isinstance(exc, HTTPException):
response = JsonData.error(msg=str(exc.detail), code=exc.status_code)
else:
# 处理其他所有异常,包括验证错误
response = JsonData.error(msg=str(exc), code=-1)
return JSONResponse(
status_code=status.HTTP_200_OK,
content=response.model_dump()
)
# main.py文件注册统一异常处理器
app.add_exception_handler(ApiException, api_exception_handler)
```
* 统一响应JsonData,创建`json_response.py`文件
```python
from pydantic import BaseModel
from typing import Any, Optional, Literal
class JsonData(BaseModel):
"""通用响应数据模型"""
code: int = 0 # 状态码
data: Optional[Any] = None # 响应数据
msg: str = "" # 响应消息
type: Literal["stream", "text"] = "text" # 响应类型
@classmethod
def success(cls, data: Any = None) -> "JsonData":
"""创建成功响应"""
return cls(code=0, data=data, type="text")
@classmethod
def error(cls, msg: str = "error", code: int = -1) -> "JsonData":
"""创建错误响应"""
return cls(code=code, msg=msg, type="text")
@classmethod
def stream_data(cls, data: Any, msg: str = "") -> "JsonData":
"""创建流式数据响应"""
return cls(code=0, data=data, msg=msg, type="stream")
```
#### AI智能体中心配置文件和模型方法开发实战
* 需求
* 统一管理配置文件,包括JWT配置、数据库、分布式缓存、大模型参数
* 封装LLM方法,方便切换模型
* 编码实战
* 配置文件 `core/config.py`
```python
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
# Redis配置
REDIS_HOST: str = "47.119.128.20"
REDIS_PORT: int = 6379
REDIS_DB: int = 0
REDIS_PASSWORD: str = "abc123456"
REDIS_MAX_CONNECTIONS: int = 10
# MySQL配置
MYSQL_HOST: str = "39.108.115.28"
MYSQL_PORT: int = 3306
MYSQL_USER: str = "root"
MYSQL_PASSWORD: str = "xdclass.net168"
MYSQL_DATABASE: str = "dcloud_aipan"
MYSQL_CHARSET: str = "utf8mb4"
# 应用配置
APP_NAME: str = "AI智能体中心API服务"
DEBUG: bool = False
# JWT配置
JWT_SECRET_KEY: str = "xdclass.net168xdclass.net168xdclass.net168xdclass.net168"
JWT_ALGORITHM: str = "HS256"
JWT_ACCESS_TOKEN_EXPIRE_MINUTES: int = 30
JWT_LOGIN_SUBJECT: str = "XDCLASS"
# LLM配置
LLM_MODEL_NAME: str = "qwen-plus"
LLM_BASE_URL: str = "https://dashscope.aliyuncs.com/compatible-mode/v1"
LLM_API_KEY: str = "sk-005c3c25f6d042848b29d75f2f020f08"
LLM_TEMPERATURE: float = 0.7
LLM_STREAMING: bool = True
class Config:
env_file = ".env"
case_sensitive = True
settings = Settings()
```
* 注意:也可以创建一个 .env 文件来存储敏感信息(如 API_KEY),并将其添加到 .gitignore 中,避免敏感信息泄露。
* 大模型方法获取 `core/llm.py`
```python
from langchain_openai import ChatOpenAI
from core.config import settings
def get_default_llm():
"""获取LLM模型"""
return ChatOpenAI(
name = settings.LLM_MODEL_NAME,
base_url = settings.LLM_BASE_URL,
api_key = settings.LLM_API_KEY,
temperature = settings.LLM_TEMPERATURE,
streaming = settings.LLM_STREAMING
)
```
#### AI智能体中心登录JWT和日志处理实战
**简介: AI智能体中心登录JWT和日志处理实战**
* 需求
* 部分智能体需要登录才可以进行使用,因此需要加入JWT解析的逻辑
* 和Java采用一样的JWT方式进行,封装相关方法和密钥
* 链路一:前端传递token->后端Java透传->fastapi处理
* 链路二:前端传递token->fastapi处理
* 快速掌握logging模块使用,替代print
* 编码实战
* logging介绍
* 是 Python 标准库中用于记录日志的模块,提供了灵活的日志记录机制,支持多级别日志
* 替代 `print` 调试的工业级解决方案
```
import logging
# 默认使用 WARNING 级别,输出到控制台
logging.warning("This is a warning message") # 输出
logging.info("This is an info message") # 不输出
```
* 通过 logging.basicConfig 配置
```python
import logging
logging.basicConfig(
filename="app.log", # 输出到文件
level=logging.INFO, # 记录器级别
format="%(asctime)s [%(levelname)s] %(message)s",
datefmt="%Y-%m-%d %H:%M:%S"
)
logging.info("Program started") # 写入 app.log
```
* 推荐方案,为模块或组件创建独立的记录器
```python
logger = logging.getLogger(__name__) # 推荐方式
```
* 创建 `auth.py`文件
```python
from fastapi import Depends, Header
from jose import JWTError, jwt
from typing import Dict, Any, Optional
import logging
from datetime import datetime, timedelta, UTC
import os
import sys
from core.config import settings
from core.exceptions import ApiException
logger = logging.getLogger(__name__)
def remove_prefix(token: str) -> str:
"""移除token的前缀"""
return token.replace(settings.JWT_LOGIN_SUBJECT, "").strip() if token.startswith(settings.JWT_LOGIN_SUBJECT) else token
async def get_current_user(token: Optional[str] = Header(None)) -> Dict[str, Any]:
"""
获取当前用户信息
Args:
token: JWT token字符串,从请求头中获取
Returns:
Dict[str, Any]: 包含用户信息的字典,格式为 {"account_id": int, "username": str}
Raises:
ApiException: 当token无效、过期或解析失败时抛出异常
"""
try:
# 验证token是否存在
if not token or not token.strip():
raise ApiException(msg="Token不能为空", code=-1)
# 移除前缀并解析token
token = remove_prefix(token.strip())
payload = jwt.decode(token, settings.JWT_SECRET_KEY, algorithms=[settings.JWT_ALGORITHM])
# 验证token内容
if payload.get("sub") != settings.JWT_LOGIN_SUBJECT or not payload.get("accountId"):
raise ApiException(msg="无效的认证凭据", code=-1)
# 记录日志并返回用户信息
logger.info(f"JWT解密成功,accountId: {payload.get('accountId')}, username: {payload.get('username')}")
return {"account_id": payload.get("accountId"), "username": payload.get("username")}
except Exception as e:
logger.error(f"JWT处理失败: {str(e)}")
raise ApiException(msg="无效的认证凭据", code=-1)
```
### AI智能体中心实战之聊天智能助理-可联网
#### AI聊天智能助理需求讲解和路由开发实战
* 需求
* 开发AI聊天智能助理, 基于 Redis 实现聊天历史存储,支持流式响应(Streaming Response)
- 技术亮点:
- 智能对话能力:
- 支持多轮对话,保持上下文连贯性
- 可以理解用户意图并调用合适的工具
- 能够生成对话摘要,帮助理解对话历史
- 实时信息获取:
- 可以回答需要实时数据的问题
- 通过搜索工具获取最新信息,搜索结果会被智能整合到回答中
- 高性能设计:
- 支持流式响应,提升用户体验
- 使用 Redis 缓存,提高响应速度,异步处理,提高并发能力
- 可扩展性:
- 模块化设计,易于添加新功能
- 工具系统可扩展,支持添加新工具
* AI智能体业务使用场景(包装简历和项目):
- 日常对话和问答、实时信息查询
- 多轮对话交互、知识获取和分享
* 编码实战
* 创建模型类 `chat_schemas.py`
```python
from pydantic import BaseModel
from typing import List
class ChatMessage(BaseModel):
role: str
content: str
timestamp: str
class ChatHistoryResponse(BaseModel):
messages: List[ChatMessage]
class ChatRequest(BaseModel):
message: str
```
* 创建 `chat_service.py`
```python
import json
from typing import List, Dict
import redis
from datetime import datetime
from core.config import settings
from core.llm import get_default_llm
from models.json_response import JsonData
import logging
logger = logging.getLogger(__name__)
class ChatService:
def __init__(self):
self.redis_client = redis.Redis(
host=settings.REDIS_HOST,
port=settings.REDIS_PORT,
db=settings.REDIS_DB,
password=settings.REDIS_PASSWORD,
decode_responses=True
)
self.llm = get_default_llm()
```
* 开发路由`chat.py`
```python
from fastapi import APIRouter, Depends
from fastapi.responses import StreamingResponse
from services.chat_service import ChatService
from models.chat_schemas import ChatRequest, ChatHistoryResponse
from models.json_response import JsonData
from core.auth import get_current_user
from core.exceptions import ApiException
from typing import Dict, Any
router = APIRouter(prefix="/api/chat", tags=["聊天助手"])
@router.post("/stream")
async def chat_stream(
request: ChatRequest,
chat_service: ChatService = Depends(ChatService),
current_user: Dict[str, Any] = Depends(get_current_user)
):
"""聊天接口(流式响应)"""
# 使用当前用户的 account_id
account_id = current_user["account_id"]
```
#### AI聊天智能助理之聊天会话持久化设计
* 需求说明
* 采用Redis进行持久化用户的聊天记录
* 项目依赖环境创建
* 项目名称:`dcloud-ai-agent`
* 创建虚拟环境
```
# 语法:python -m venv <环境目录名>
python -m venv myenv
```
* 激活虚拟环境
```
source myenv/bin/activate
```
* 安装核心依赖包 (**版本和课程保持一致,不然很多不兼容!!!**)
* 下载相关资料 ,使用**【wget】或者【浏览器】远程下载相关依赖包(需要替换群里最新的)**
```
原生资料下载方式(账号 - 密码 - ip地址 - 端口 需要替换群里最新的,【其他路径不变】)
wget --http-user=用户名 --http-password=密码 http://ip:端口/dcloud_pan/aipan_agent_1.zip
#比如 命令行下
wget --http-user=admin --http-password=xdclass.net888 http://47.115.31.28:9088/dcloud_pan/aipan_agent_1.zip
# 比如 浏览器直接访问
http://47.115.31.28:9088/dcloud_pan/aipan_agent_1.zip
```
* 解压后执行【**依赖很多,版本差异大,务必按照下面执行,否则课程无法进行下去,加我微信 xdclass6**】
```
# 安装依赖
pip install -r requirements.txt
```
#### AI智能体中心Web项目搭建和基础配置
* 项目基本目录结构-创建对应的目录
```python
dcloud-agent/
├── agents/ # 智能代理相关代码
├── app/ # 应用主目录
│ └── main.py # 应用入口文件
├── core/ # 核心功能模块
├── models/ # 数据模型定义
├── routers/ # API路由定义
├── services/ # 业务服务层
├── tests/ # 测试代码
├── tools/ # 工具函数和辅助类
├── myenv/ # Python虚拟环境
├── Dockerfile # Docker容器配置
├── README.md # 项目说明文档
└── requirements.txt # 项目依赖包列表【不提供,参考上集,进大课群下载】
```
* 编写主入口文件
```python
import uvicorn
from fastapi import FastAPI
from core.config import settings
from routers import chat
app = FastAPI(
title=settings.APP_NAME,
description="AI智能体中心API服务",
version="1.0.0"
)
# 注册路由
app.include_router(chat.router)
@app.get("/")
async def root():
return {
"message": "欢迎使用AI智能体中心API",
"version": "1.0.0",
"available_agents": ["chat"] # 列出可用的智能体
}
# 启动服务器的命令 uvicorn app.main:app --reload
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
```
* 隐藏pychche文件
* 打开 首选项 --> 设置 --> 搜索框中 搜索 files.exclude --> 点击 "添加模式" 按钮
* 输入想要隐藏的文件夹, 如python经常生成的缓存文件夹, 输入 `**/__pycache`__ 即可隐藏 `__pycache__` 文件夹.

#### AI智能体中心FastAPI自定义异常+统一响应
**简介: AI智能体中心FastAPI自定义异常+统一响应**
* 需求
* Web响应一般都会进行自定义异常+统一响应
* 前端方便对接和记录相关业务操作日志
* 编码实战
* 自定义异常,创建一个 `exceptions.py` 文件
* 定义一个继承自 `Exception` 的自定义异常类,可以添加额外的字段(如错误码、错误信息等)
* 定义一个接收 `Request` 和 `Exception` 参数的函数,返回标准的 `JSONResponse`
```python
from fastapi import HTTPException, status
from fastapi.responses import JSONResponse
from typing import Any
from models.json_response import JsonData
class ApiException(Exception):
"""API异常基类"""
def __init__(
self,
msg: str = "操作失败",
code: int = -1,
data: Any = None
):
self.msg = msg
self.code = code
self.data = data
super().__init__(msg)
async def api_exception_handler(request, exc: Exception) -> JSONResponse:
"""统一异常处理器"""
print(f"❌ API异常: {str(exc)}")
if isinstance(exc, ApiException):
response = JsonData.error(msg=exc.msg, code=exc.code)
elif isinstance(exc, HTTPException):
response = JsonData.error(msg=str(exc.detail), code=exc.status_code)
else:
# 处理其他所有异常,包括验证错误
response = JsonData.error(msg=str(exc), code=-1)
return JSONResponse(
status_code=status.HTTP_200_OK,
content=response.model_dump()
)
# main.py文件注册统一异常处理器
app.add_exception_handler(ApiException, api_exception_handler)
```
* 统一响应JsonData,创建`json_response.py`文件
```python
from pydantic import BaseModel
from typing import Any, Optional, Literal
class JsonData(BaseModel):
"""通用响应数据模型"""
code: int = 0 # 状态码
data: Optional[Any] = None # 响应数据
msg: str = "" # 响应消息
type: Literal["stream", "text"] = "text" # 响应类型
@classmethod
def success(cls, data: Any = None) -> "JsonData":
"""创建成功响应"""
return cls(code=0, data=data, type="text")
@classmethod
def error(cls, msg: str = "error", code: int = -1) -> "JsonData":
"""创建错误响应"""
return cls(code=code, msg=msg, type="text")
@classmethod
def stream_data(cls, data: Any, msg: str = "") -> "JsonData":
"""创建流式数据响应"""
return cls(code=0, data=data, msg=msg, type="stream")
```
#### AI智能体中心配置文件和模型方法开发实战
* 需求
* 统一管理配置文件,包括JWT配置、数据库、分布式缓存、大模型参数
* 封装LLM方法,方便切换模型
* 编码实战
* 配置文件 `core/config.py`
```python
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
# Redis配置
REDIS_HOST: str = "47.119.128.20"
REDIS_PORT: int = 6379
REDIS_DB: int = 0
REDIS_PASSWORD: str = "abc123456"
REDIS_MAX_CONNECTIONS: int = 10
# MySQL配置
MYSQL_HOST: str = "39.108.115.28"
MYSQL_PORT: int = 3306
MYSQL_USER: str = "root"
MYSQL_PASSWORD: str = "xdclass.net168"
MYSQL_DATABASE: str = "dcloud_aipan"
MYSQL_CHARSET: str = "utf8mb4"
# 应用配置
APP_NAME: str = "AI智能体中心API服务"
DEBUG: bool = False
# JWT配置
JWT_SECRET_KEY: str = "xdclass.net168xdclass.net168xdclass.net168xdclass.net168"
JWT_ALGORITHM: str = "HS256"
JWT_ACCESS_TOKEN_EXPIRE_MINUTES: int = 30
JWT_LOGIN_SUBJECT: str = "XDCLASS"
# LLM配置
LLM_MODEL_NAME: str = "qwen-plus"
LLM_BASE_URL: str = "https://dashscope.aliyuncs.com/compatible-mode/v1"
LLM_API_KEY: str = "sk-005c3c25f6d042848b29d75f2f020f08"
LLM_TEMPERATURE: float = 0.7
LLM_STREAMING: bool = True
class Config:
env_file = ".env"
case_sensitive = True
settings = Settings()
```
* 注意:也可以创建一个 .env 文件来存储敏感信息(如 API_KEY),并将其添加到 .gitignore 中,避免敏感信息泄露。
* 大模型方法获取 `core/llm.py`
```python
from langchain_openai import ChatOpenAI
from core.config import settings
def get_default_llm():
"""获取LLM模型"""
return ChatOpenAI(
name = settings.LLM_MODEL_NAME,
base_url = settings.LLM_BASE_URL,
api_key = settings.LLM_API_KEY,
temperature = settings.LLM_TEMPERATURE,
streaming = settings.LLM_STREAMING
)
```
#### AI智能体中心登录JWT和日志处理实战
**简介: AI智能体中心登录JWT和日志处理实战**
* 需求
* 部分智能体需要登录才可以进行使用,因此需要加入JWT解析的逻辑
* 和Java采用一样的JWT方式进行,封装相关方法和密钥
* 链路一:前端传递token->后端Java透传->fastapi处理
* 链路二:前端传递token->fastapi处理
* 快速掌握logging模块使用,替代print
* 编码实战
* logging介绍
* 是 Python 标准库中用于记录日志的模块,提供了灵活的日志记录机制,支持多级别日志
* 替代 `print` 调试的工业级解决方案
```
import logging
# 默认使用 WARNING 级别,输出到控制台
logging.warning("This is a warning message") # 输出
logging.info("This is an info message") # 不输出
```
* 通过 logging.basicConfig 配置
```python
import logging
logging.basicConfig(
filename="app.log", # 输出到文件
level=logging.INFO, # 记录器级别
format="%(asctime)s [%(levelname)s] %(message)s",
datefmt="%Y-%m-%d %H:%M:%S"
)
logging.info("Program started") # 写入 app.log
```
* 推荐方案,为模块或组件创建独立的记录器
```python
logger = logging.getLogger(__name__) # 推荐方式
```
* 创建 `auth.py`文件
```python
from fastapi import Depends, Header
from jose import JWTError, jwt
from typing import Dict, Any, Optional
import logging
from datetime import datetime, timedelta, UTC
import os
import sys
from core.config import settings
from core.exceptions import ApiException
logger = logging.getLogger(__name__)
def remove_prefix(token: str) -> str:
"""移除token的前缀"""
return token.replace(settings.JWT_LOGIN_SUBJECT, "").strip() if token.startswith(settings.JWT_LOGIN_SUBJECT) else token
async def get_current_user(token: Optional[str] = Header(None)) -> Dict[str, Any]:
"""
获取当前用户信息
Args:
token: JWT token字符串,从请求头中获取
Returns:
Dict[str, Any]: 包含用户信息的字典,格式为 {"account_id": int, "username": str}
Raises:
ApiException: 当token无效、过期或解析失败时抛出异常
"""
try:
# 验证token是否存在
if not token or not token.strip():
raise ApiException(msg="Token不能为空", code=-1)
# 移除前缀并解析token
token = remove_prefix(token.strip())
payload = jwt.decode(token, settings.JWT_SECRET_KEY, algorithms=[settings.JWT_ALGORITHM])
# 验证token内容
if payload.get("sub") != settings.JWT_LOGIN_SUBJECT or not payload.get("accountId"):
raise ApiException(msg="无效的认证凭据", code=-1)
# 记录日志并返回用户信息
logger.info(f"JWT解密成功,accountId: {payload.get('accountId')}, username: {payload.get('username')}")
return {"account_id": payload.get("accountId"), "username": payload.get("username")}
except Exception as e:
logger.error(f"JWT处理失败: {str(e)}")
raise ApiException(msg="无效的认证凭据", code=-1)
```
### AI智能体中心实战之聊天智能助理-可联网
#### AI聊天智能助理需求讲解和路由开发实战
* 需求
* 开发AI聊天智能助理, 基于 Redis 实现聊天历史存储,支持流式响应(Streaming Response)
- 技术亮点:
- 智能对话能力:
- 支持多轮对话,保持上下文连贯性
- 可以理解用户意图并调用合适的工具
- 能够生成对话摘要,帮助理解对话历史
- 实时信息获取:
- 可以回答需要实时数据的问题
- 通过搜索工具获取最新信息,搜索结果会被智能整合到回答中
- 高性能设计:
- 支持流式响应,提升用户体验
- 使用 Redis 缓存,提高响应速度,异步处理,提高并发能力
- 可扩展性:
- 模块化设计,易于添加新功能
- 工具系统可扩展,支持添加新工具
* AI智能体业务使用场景(包装简历和项目):
- 日常对话和问答、实时信息查询
- 多轮对话交互、知识获取和分享
* 编码实战
* 创建模型类 `chat_schemas.py`
```python
from pydantic import BaseModel
from typing import List
class ChatMessage(BaseModel):
role: str
content: str
timestamp: str
class ChatHistoryResponse(BaseModel):
messages: List[ChatMessage]
class ChatRequest(BaseModel):
message: str
```
* 创建 `chat_service.py`
```python
import json
from typing import List, Dict
import redis
from datetime import datetime
from core.config import settings
from core.llm import get_default_llm
from models.json_response import JsonData
import logging
logger = logging.getLogger(__name__)
class ChatService:
def __init__(self):
self.redis_client = redis.Redis(
host=settings.REDIS_HOST,
port=settings.REDIS_PORT,
db=settings.REDIS_DB,
password=settings.REDIS_PASSWORD,
decode_responses=True
)
self.llm = get_default_llm()
```
* 开发路由`chat.py`
```python
from fastapi import APIRouter, Depends
from fastapi.responses import StreamingResponse
from services.chat_service import ChatService
from models.chat_schemas import ChatRequest, ChatHistoryResponse
from models.json_response import JsonData
from core.auth import get_current_user
from core.exceptions import ApiException
from typing import Dict, Any
router = APIRouter(prefix="/api/chat", tags=["聊天助手"])
@router.post("/stream")
async def chat_stream(
request: ChatRequest,
chat_service: ChatService = Depends(ChatService),
current_user: Dict[str, Any] = Depends(get_current_user)
):
"""聊天接口(流式响应)"""
# 使用当前用户的 account_id
account_id = current_user["account_id"]
```
#### AI聊天智能助理之聊天会话持久化设计
* 需求说明
* 采用Redis进行持久化用户的聊天记录
 * **数据结构**聊天历史:JSON数组,每个元素为一条消息,包含以下字段
```json
{
"role": "user/assistant",
"content": "消息内容",
"timestamp": "ISO时间戳"
}
```
* 设计相关方法
* **保存聊天历史**
* 将用户的聊天记录以JSON格式存储到Redis中。
* Redis键格式:`chat_history:{account_id}`。
* **获取聊天历史**
* 从Redis中读取指定用户的聊天记录, 如果Redis中无记录,则返回空列表。
* **添加消息**
* 支持向用户的聊天历史中追加新的消息, 消息包含以下字段:
* `role`: 消息角色(如`user`或`assistant`)。
* `content`: 消息内容。
* `timestamp`: 消息时间戳(ISO格式)。
* **清空聊天历史**
* 清除指定用户的聊天历史及相关摘要信息。
* 编码实战 `chat_service.py`
```python
def _get_chat_key(self, account_id: str) -> str:
"""获取用户聊天记录的Redis key"""
return f"chat_history:{account_id}"
def save_chat_history(self, account_id: str, messages: List[Dict]):
"""保存聊天历史到Redis"""
chat_key = self._get_chat_key(account_id)
self.redis_client.set(chat_key, json.dumps(messages))
def get_chat_history(self, account_id: str) -> List[Dict]:
"""从Redis获取聊天历史"""
chat_key = self._get_chat_key(account_id)
history = self.redis_client.get(chat_key)
return json.loads(history) if history else []
def add_message(self, account_id: str, role: str, content: str):
"""添加一条消息到聊天历史"""
messages = self.get_chat_history(account_id)
messages.append({
"role": role,
"content": content,
"timestamp": datetime.now().isoformat()
})
self.save_chat_history(account_id, messages)
def clear_chat_history(self, account_id: str):
"""清空用户的聊天历史"""
chat_key = self._get_chat_key(account_id)
summary_key = self._get_summary_key(account_id)
self.redis_client.delete(chat_key)
self.redis_client.delete(summary_key)
def save_chat_messages(
self,
account_id: str,
user_message: str,
assistant_message: str
):
"""保存对话消息"""
self.add_message(account_id, "user", user_message)
self.add_message(account_id, "assistant", assistant_message)
```
#### AI聊天智能助理之多轮长对话摘要生成
* 背景:为啥多轮对话要生成摘要
- 技术必要性:突破大模型token长度限制
- 信息保留率:需保持85%以上的关键信息完整度
- 推理成本控制:减少30-50%的重复计算
- 延迟优化:缩短响应时间200-500ms
- 注意:摘要生成核心还是提示词工程
* 业务逻辑设计
* 基于用户的聊天历史,通过调用LLM(大语言模型)生成简洁的核心摘要。
* 摘要要求:
* 突出对话的主要话题和关键信息。
* 使用第三人称描述,提取重要数据、时间节点、待办事项等。
* 保留原始对话中的重要细节。
* 包含最新的对话内容。
* **摘要合并**
- 如果用户已有旧摘要,需将新生成的摘要与旧摘要合并。
- 合并要求:
- 保留两个摘要中的重要信息。
- 突出对话的主要话题和关键信息。
- 使用第三人称描述,提取重要数据、时间节点、待办事项等。
- 保留原始对话中的重要细节。
- 包含最新的对话内容。
* **摘要存储**
- 将生成的摘要存储到Redis中。
- Redis键格式:`chat_summary:{account_id}`。
* 编码实战 `chat_service.py`
```python
def _get_summary_key(self, account_id: str) -> str:
"""获取聊天摘要的Redis key"""
return f"chat_summary:{account_id}"
async def generate_summary(self, account_id: str) -> str:
"""生成聊天历史的核心摘要"""
try:
# 获取最新的聊天历史
messages = self.get_chat_history(account_id)
if not messages:
return ""
# 构建提示词
prompt = f"""请根据以下对话历史生成一个简洁的核心摘要,突出主要话题和关键信息:
{json.dumps(messages, ensure_ascii=False, indent=2)}
摘要要求:
1. 突出对话的主要话题和关键信息
2. 使用第三人称描述,提取重要数据/时间节点/待办事项
3. 保留原始对话中的重要细节
4. 确保包含最新的对话内容
"""
# 生成新的摘要
response = await self.llm.ainvoke(prompt)
new_summary = response.content
# 获取旧的摘要(如果有)
summary_key = self._get_summary_key(account_id)
old_summary = self.redis_client.get(summary_key)
if old_summary:
# 如果存在旧摘要,生成一个合并的提示词
merge_prompt = f"""请将以下两个摘要合并成一个新的摘要:
旧摘要:
{old_summary}
新摘要:
{new_summary}
合并要求:
1. 保留两个摘要中的重要信息
2. 突出对话的主要话题和关键信息
3. 使用第三人称描述,提取重要数据/时间节点/待办事项
4. 保留原始对话中的重要细节
5. 确保包含最新的对话内容
"""
# 生成合并后的摘要
merge_response = await self.llm.ainvoke(merge_prompt)
final_summary = merge_response.content
else:
final_summary = new_summary
# 更新缓存中的摘要
self.redis_client.set(summary_key, final_summary)
return final_summary
except Exception as e:
logger.error(f"生成摘要失败: {str(e)}")
return ""
```
#### AI聊天智能助理之联网搜索工具开发
* 需求
* 聊天助理可以根据用户需求,实时查询最新信息
* 封装搜索工具,参考前面的代码即可
* 而且支持拓展更多工具,让AI聊天助理更加智能
* 注意工具的参数 `return_direct=True`
* 当return_direct设置为True时,工具执行完毕后会直接将结果返回给用户,而不会经过Agent的后续处理。
* Agent不会对工具的输出进行分析或生成进一步的响应,而是立即将结果呈现给用户。
* 在需要快速返回简单结果或者不希望模型介入后续处理的情况下推荐使用
| 参数状态 | 数据流向 | 典型响应示例 |
| :--------------------------- | :-------------------------------------- | :----------------------------- |
| `return_direct=False` (默认) | 工具结果 → Agent → 模型生成自然语言响应 | "查询完成,当前北京气温是25℃" |
| `return_direct=True` | 工具结果 → 直接返回用户 | `{"city": "北京", "temp": 25}` |
* 编码实战 `chat_tools.py`
```python
from langchain_core.tools import tool
from langchain_community.utilities import SearchApiAPIWrapper
import os
os.environ["SEARCHAPI_API_KEY"] = "qQBHMQo4Rk8SihmpJjCs7fML"
@tool("web_search", return_direct=False)
def web_search(query: str) -> str:
"""
使用此工具搜索最新的互联网信息。当你需要获取实时信息或不确定某个事实时使用
"""
try:
search = SearchApiAPIWrapper()
results = search.results(query)
return "\n\n".join([
f"来源:{res['title']}\n内容:{res['snippet']}"
for res in results['organic_results']
])
except Exception as e:
return f"搜索失败:{str(e)}"
def get_chat_tools():
"""获取聊天助手可用的工具集"""
tools = [
web_search
]
return tools
```
#### AI聊天智能助理之Agent智能体开发实战
* 需求背景
* 创建聊天智能体,与智能体进行对话
* 支持工具调用(如搜索工具)
* 对话历史摘要生成
* 知识点:`create_openai_functions_agent`
* 专门适配 OpenAI 函数调用功能的代理生成器 , 将自然语言指令自动映射到预定义工具函数
* 实现结构化数据输出与动态行为决策 , 构建符合 ReAct 模式的智能体架构
* 创建聊天智能体开发
* **功能描述**
- 创建一个具备对话能力的智能体,支持日常对话、问答以及工具调用。
- 智能体能够记住用户的对话历史,并在对话中使用摘要信息。
* **输入参数**
- `tools`: 工具列表,用于扩展智能体的功能。
* **输出结果**
- 返回一个`AgentExecutor`实例,代表创建好的聊天智能体。
* **实现细节**
- 使用`create_openai_functions_agent`创建智能体。
- 定义系统提示词,包含智能体的能力说明和对话摘要占位符。
- 启用流式响应功能
* 编码实现 `chat_agent.py`
```python
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.tools import Tool
from core.llm import get_default_llm
from typing import List, AsyncIterator, Dict, AsyncGenerator
import asyncio
from services.chat_service import ChatService
from tools.chat_tools import get_chat_tools
from models.json_response import JsonData
def create_chat_agent(tools: List[Tool]):
"""创建聊天智能体"""
system_prompt = """你是一个智能聊天助手。你可以:
1. 进行日常对话和问答
2. 使用搜索工具获取最新信息
3. 记住与用户的对话历史
请保持回答专业、友好且准确。如果用户的问题需要最新信息,请使用搜索工具。"""
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("system", "以下是之前的对话摘要: {summary}"),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
])
llm = get_default_llm()
llm.streaming = True
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
handle_parsing_errors=True
)
return agent_executo
```
#### AI聊天智能助理之对话和流式响应开发
* 知识点:`AsyncIterator `异步迭代器
* Python异步编程中的核心模块,用于在异步环境中逐项处理数据流。
* 与普通迭代器不同,它能在迭代过程中暂停并执行其他异步操作,特别适合处理I/O密集型任务
* 比如处理WebSocket连接、批量处理数据库查询结果等异步数据流
* 注意: 比如忘记使用await 或在错误的地方调用异步迭代器,导致程序阻塞或错误
| 特性 | 普通Iterator | AsyncIterator |
| :----------- | :------------------ | :------------------------- |
| **迭代方法** | `__next__()` | `__anext__()` |
| **循环语法** | `for item in iter:` | `async for item in aiter:` |
| **执行模式** | 同步阻塞 | 异步非阻塞 |
| **适用场景** | 内存数据遍历 | 网络流/数据库等异步数据源 |
| **暂停机制** | 无 | 可await其他协程 |
* **与智能体进行对话业务逻辑开发**
- **功能描述**
- 用户通过输入文本与智能体进行对话。
- 智能体根据对话历史摘要生成回复,并保存对话记录。
- **输出结果**
- 流式返回智能体的回复内容。
- **实现细节**
- 获取用户的对话历史摘要。
- 调用智能体的`astream`方法生成流式响应。
- 保存用户输入和智能体回复到对话历史中。
- 异常处理:如果发生错误,返回错误信息
- 编码实战
```python
async def chat_with_agent(
agent_executor: AgentExecutor,
chat_service: ChatService,
account_id: str,
input_text: str
) -> AsyncIterator[str]:
"""与智能体进行对话"""
try:
# 获取最新的历史摘要
summary = await chat_service.generate_summary(account_id)
# 执行对话
async for chunk in agent_executor.astream({
"input": input_text,
"summary": summary
}):
if "output" in chunk:
response = chunk["output"]
# 保存对话消息(用户输入和助手回复)
await chat_service.save_chat_messages(account_id, input_text, response)
# 流式返回响应
for token in response:
yield token
await asyncio.sleep(0.01)
except Exception as e:
yield f"抱歉,处理您的请求时出现错误: {str(e)}"
```
* 流式生成响应
- **功能描述**
- 将智能体的回复内容以流式方式发送给用户。
- 支持按标点符号或固定长度分割响应内容。
- **输入参数**
- `agent`: 聊天智能体实例。
- `chat_service`: 聊天服务实例。
- `account_id`: 用户标识。
- `message`: 用户输入的文本。
- **输出结果**
- 以SSE(Server-Sent Events)格式返回流式响应。
- **实现细节**
- 逐字符接收智能体的回复内容。
- 当遇到标点符号或字符长度达到20时,发送当前分块内容。
- 发送剩余内容后,添加结束标记`[DONE]`。
- 编码实战
```
async def generate_stream_response(
agent: AgentExecutor,
chat_service: ChatService,
account_id: str,
message: str
) -> AsyncGenerator[str, None]:
"""生成流式响应"""
current_chunk = ""
async for token in chat_with_agent(agent, chat_service, account_id, message):
current_chunk += token
# 当遇到标点符号或空格时,发送当前chunk
if token in "。,!?、;:,.!?;: " or len(current_chunk) >= 20:
response = JsonData.stream_data(data=current_chunk)
yield f"data: {response.model_dump_json()}\n\n"
current_chunk = ""
await asyncio.sleep(0.01)
# 发送剩余的chunk
if current_chunk:
response = JsonData.stream_data(data=current_chunk)
yield f"data: {response.model_dump_json()}\n\n"
# 发送结束标记
yield "data: [DONE]\n\n"
```
* 路由层面处理 `chat.py`
```python
@router.post("/stream")
async def chat_stream(
request: ChatRequest,
chat_service: ChatService = Depends(ChatService),
current_user: Dict[str, Any] = Depends(get_current_user)
):
"""聊天接口(流式响应)"""
# 使用当前用户的 account_id
account_id = current_user["account_id"]
# 获取智能体
agent = await get_chat_agent(chat_service)
return StreamingResponse(
generate_stream_response(agent, chat_service, account_id, request.message),
media_type="text/event-stream"
)
```
#### AI聊天智能助理之全链路测试综合实战
**简介: AI聊天智能助理之全链路测试综合实战**
* 回顾需求
* 开发AI聊天智能助理, 基于 Redis 实现聊天历史存储,支持流式响应(Streaming Response)
- 智能对话能力:
- 支持多轮对话,保持上下文连贯性
- 可以理解用户意图并调用合适的工具
- 能够生成对话摘要,帮助理解对话历史
- 实时信息获取:
- 可以回答需要实时数据的问题,
- 通过搜索工具获取最新信息,搜索结果会被智能整合到回答中
* 全链路测试实战
* 启动项目 `uvicorn app.main:app --reload`
* 准备token ,并且配置到HTTP请求头里面
* APIFOX增加请求头 `Accept : text/event-stream `
* 测试案例一
* 告诉基本当前人员信息(进阶也可以初始化导入用户的历史画像数据)
* 进行基本信息问答,看智能体助理是否有记忆功能
* 测试案例二
* 询问当前当前需要联网信息内容,看大模型是否有调用工具进行处理
* 查看Redis的数据存储:聊天记录和摘要
* 拓展:不用每次都生成摘要,可以配置进阶策略,比如对话轮次阈值(默认5轮)、关键决策点标记、上下文长度超过XXX
* **数据结构**聊天历史:JSON数组,每个元素为一条消息,包含以下字段
```json
{
"role": "user/assistant",
"content": "消息内容",
"timestamp": "ISO时间戳"
}
```
* 设计相关方法
* **保存聊天历史**
* 将用户的聊天记录以JSON格式存储到Redis中。
* Redis键格式:`chat_history:{account_id}`。
* **获取聊天历史**
* 从Redis中读取指定用户的聊天记录, 如果Redis中无记录,则返回空列表。
* **添加消息**
* 支持向用户的聊天历史中追加新的消息, 消息包含以下字段:
* `role`: 消息角色(如`user`或`assistant`)。
* `content`: 消息内容。
* `timestamp`: 消息时间戳(ISO格式)。
* **清空聊天历史**
* 清除指定用户的聊天历史及相关摘要信息。
* 编码实战 `chat_service.py`
```python
def _get_chat_key(self, account_id: str) -> str:
"""获取用户聊天记录的Redis key"""
return f"chat_history:{account_id}"
def save_chat_history(self, account_id: str, messages: List[Dict]):
"""保存聊天历史到Redis"""
chat_key = self._get_chat_key(account_id)
self.redis_client.set(chat_key, json.dumps(messages))
def get_chat_history(self, account_id: str) -> List[Dict]:
"""从Redis获取聊天历史"""
chat_key = self._get_chat_key(account_id)
history = self.redis_client.get(chat_key)
return json.loads(history) if history else []
def add_message(self, account_id: str, role: str, content: str):
"""添加一条消息到聊天历史"""
messages = self.get_chat_history(account_id)
messages.append({
"role": role,
"content": content,
"timestamp": datetime.now().isoformat()
})
self.save_chat_history(account_id, messages)
def clear_chat_history(self, account_id: str):
"""清空用户的聊天历史"""
chat_key = self._get_chat_key(account_id)
summary_key = self._get_summary_key(account_id)
self.redis_client.delete(chat_key)
self.redis_client.delete(summary_key)
def save_chat_messages(
self,
account_id: str,
user_message: str,
assistant_message: str
):
"""保存对话消息"""
self.add_message(account_id, "user", user_message)
self.add_message(account_id, "assistant", assistant_message)
```
#### AI聊天智能助理之多轮长对话摘要生成
* 背景:为啥多轮对话要生成摘要
- 技术必要性:突破大模型token长度限制
- 信息保留率:需保持85%以上的关键信息完整度
- 推理成本控制:减少30-50%的重复计算
- 延迟优化:缩短响应时间200-500ms
- 注意:摘要生成核心还是提示词工程
* 业务逻辑设计
* 基于用户的聊天历史,通过调用LLM(大语言模型)生成简洁的核心摘要。
* 摘要要求:
* 突出对话的主要话题和关键信息。
* 使用第三人称描述,提取重要数据、时间节点、待办事项等。
* 保留原始对话中的重要细节。
* 包含最新的对话内容。
* **摘要合并**
- 如果用户已有旧摘要,需将新生成的摘要与旧摘要合并。
- 合并要求:
- 保留两个摘要中的重要信息。
- 突出对话的主要话题和关键信息。
- 使用第三人称描述,提取重要数据、时间节点、待办事项等。
- 保留原始对话中的重要细节。
- 包含最新的对话内容。
* **摘要存储**
- 将生成的摘要存储到Redis中。
- Redis键格式:`chat_summary:{account_id}`。
* 编码实战 `chat_service.py`
```python
def _get_summary_key(self, account_id: str) -> str:
"""获取聊天摘要的Redis key"""
return f"chat_summary:{account_id}"
async def generate_summary(self, account_id: str) -> str:
"""生成聊天历史的核心摘要"""
try:
# 获取最新的聊天历史
messages = self.get_chat_history(account_id)
if not messages:
return ""
# 构建提示词
prompt = f"""请根据以下对话历史生成一个简洁的核心摘要,突出主要话题和关键信息:
{json.dumps(messages, ensure_ascii=False, indent=2)}
摘要要求:
1. 突出对话的主要话题和关键信息
2. 使用第三人称描述,提取重要数据/时间节点/待办事项
3. 保留原始对话中的重要细节
4. 确保包含最新的对话内容
"""
# 生成新的摘要
response = await self.llm.ainvoke(prompt)
new_summary = response.content
# 获取旧的摘要(如果有)
summary_key = self._get_summary_key(account_id)
old_summary = self.redis_client.get(summary_key)
if old_summary:
# 如果存在旧摘要,生成一个合并的提示词
merge_prompt = f"""请将以下两个摘要合并成一个新的摘要:
旧摘要:
{old_summary}
新摘要:
{new_summary}
合并要求:
1. 保留两个摘要中的重要信息
2. 突出对话的主要话题和关键信息
3. 使用第三人称描述,提取重要数据/时间节点/待办事项
4. 保留原始对话中的重要细节
5. 确保包含最新的对话内容
"""
# 生成合并后的摘要
merge_response = await self.llm.ainvoke(merge_prompt)
final_summary = merge_response.content
else:
final_summary = new_summary
# 更新缓存中的摘要
self.redis_client.set(summary_key, final_summary)
return final_summary
except Exception as e:
logger.error(f"生成摘要失败: {str(e)}")
return ""
```
#### AI聊天智能助理之联网搜索工具开发
* 需求
* 聊天助理可以根据用户需求,实时查询最新信息
* 封装搜索工具,参考前面的代码即可
* 而且支持拓展更多工具,让AI聊天助理更加智能
* 注意工具的参数 `return_direct=True`
* 当return_direct设置为True时,工具执行完毕后会直接将结果返回给用户,而不会经过Agent的后续处理。
* Agent不会对工具的输出进行分析或生成进一步的响应,而是立即将结果呈现给用户。
* 在需要快速返回简单结果或者不希望模型介入后续处理的情况下推荐使用
| 参数状态 | 数据流向 | 典型响应示例 |
| :--------------------------- | :-------------------------------------- | :----------------------------- |
| `return_direct=False` (默认) | 工具结果 → Agent → 模型生成自然语言响应 | "查询完成,当前北京气温是25℃" |
| `return_direct=True` | 工具结果 → 直接返回用户 | `{"city": "北京", "temp": 25}` |
* 编码实战 `chat_tools.py`
```python
from langchain_core.tools import tool
from langchain_community.utilities import SearchApiAPIWrapper
import os
os.environ["SEARCHAPI_API_KEY"] = "qQBHMQo4Rk8SihmpJjCs7fML"
@tool("web_search", return_direct=False)
def web_search(query: str) -> str:
"""
使用此工具搜索最新的互联网信息。当你需要获取实时信息或不确定某个事实时使用
"""
try:
search = SearchApiAPIWrapper()
results = search.results(query)
return "\n\n".join([
f"来源:{res['title']}\n内容:{res['snippet']}"
for res in results['organic_results']
])
except Exception as e:
return f"搜索失败:{str(e)}"
def get_chat_tools():
"""获取聊天助手可用的工具集"""
tools = [
web_search
]
return tools
```
#### AI聊天智能助理之Agent智能体开发实战
* 需求背景
* 创建聊天智能体,与智能体进行对话
* 支持工具调用(如搜索工具)
* 对话历史摘要生成
* 知识点:`create_openai_functions_agent`
* 专门适配 OpenAI 函数调用功能的代理生成器 , 将自然语言指令自动映射到预定义工具函数
* 实现结构化数据输出与动态行为决策 , 构建符合 ReAct 模式的智能体架构
* 创建聊天智能体开发
* **功能描述**
- 创建一个具备对话能力的智能体,支持日常对话、问答以及工具调用。
- 智能体能够记住用户的对话历史,并在对话中使用摘要信息。
* **输入参数**
- `tools`: 工具列表,用于扩展智能体的功能。
* **输出结果**
- 返回一个`AgentExecutor`实例,代表创建好的聊天智能体。
* **实现细节**
- 使用`create_openai_functions_agent`创建智能体。
- 定义系统提示词,包含智能体的能力说明和对话摘要占位符。
- 启用流式响应功能
* 编码实现 `chat_agent.py`
```python
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.tools import Tool
from core.llm import get_default_llm
from typing import List, AsyncIterator, Dict, AsyncGenerator
import asyncio
from services.chat_service import ChatService
from tools.chat_tools import get_chat_tools
from models.json_response import JsonData
def create_chat_agent(tools: List[Tool]):
"""创建聊天智能体"""
system_prompt = """你是一个智能聊天助手。你可以:
1. 进行日常对话和问答
2. 使用搜索工具获取最新信息
3. 记住与用户的对话历史
请保持回答专业、友好且准确。如果用户的问题需要最新信息,请使用搜索工具。"""
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("system", "以下是之前的对话摘要: {summary}"),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
])
llm = get_default_llm()
llm.streaming = True
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
handle_parsing_errors=True
)
return agent_executo
```
#### AI聊天智能助理之对话和流式响应开发
* 知识点:`AsyncIterator `异步迭代器
* Python异步编程中的核心模块,用于在异步环境中逐项处理数据流。
* 与普通迭代器不同,它能在迭代过程中暂停并执行其他异步操作,特别适合处理I/O密集型任务
* 比如处理WebSocket连接、批量处理数据库查询结果等异步数据流
* 注意: 比如忘记使用await 或在错误的地方调用异步迭代器,导致程序阻塞或错误
| 特性 | 普通Iterator | AsyncIterator |
| :----------- | :------------------ | :------------------------- |
| **迭代方法** | `__next__()` | `__anext__()` |
| **循环语法** | `for item in iter:` | `async for item in aiter:` |
| **执行模式** | 同步阻塞 | 异步非阻塞 |
| **适用场景** | 内存数据遍历 | 网络流/数据库等异步数据源 |
| **暂停机制** | 无 | 可await其他协程 |
* **与智能体进行对话业务逻辑开发**
- **功能描述**
- 用户通过输入文本与智能体进行对话。
- 智能体根据对话历史摘要生成回复,并保存对话记录。
- **输出结果**
- 流式返回智能体的回复内容。
- **实现细节**
- 获取用户的对话历史摘要。
- 调用智能体的`astream`方法生成流式响应。
- 保存用户输入和智能体回复到对话历史中。
- 异常处理:如果发生错误,返回错误信息
- 编码实战
```python
async def chat_with_agent(
agent_executor: AgentExecutor,
chat_service: ChatService,
account_id: str,
input_text: str
) -> AsyncIterator[str]:
"""与智能体进行对话"""
try:
# 获取最新的历史摘要
summary = await chat_service.generate_summary(account_id)
# 执行对话
async for chunk in agent_executor.astream({
"input": input_text,
"summary": summary
}):
if "output" in chunk:
response = chunk["output"]
# 保存对话消息(用户输入和助手回复)
await chat_service.save_chat_messages(account_id, input_text, response)
# 流式返回响应
for token in response:
yield token
await asyncio.sleep(0.01)
except Exception as e:
yield f"抱歉,处理您的请求时出现错误: {str(e)}"
```
* 流式生成响应
- **功能描述**
- 将智能体的回复内容以流式方式发送给用户。
- 支持按标点符号或固定长度分割响应内容。
- **输入参数**
- `agent`: 聊天智能体实例。
- `chat_service`: 聊天服务实例。
- `account_id`: 用户标识。
- `message`: 用户输入的文本。
- **输出结果**
- 以SSE(Server-Sent Events)格式返回流式响应。
- **实现细节**
- 逐字符接收智能体的回复内容。
- 当遇到标点符号或字符长度达到20时,发送当前分块内容。
- 发送剩余内容后,添加结束标记`[DONE]`。
- 编码实战
```
async def generate_stream_response(
agent: AgentExecutor,
chat_service: ChatService,
account_id: str,
message: str
) -> AsyncGenerator[str, None]:
"""生成流式响应"""
current_chunk = ""
async for token in chat_with_agent(agent, chat_service, account_id, message):
current_chunk += token
# 当遇到标点符号或空格时,发送当前chunk
if token in "。,!?、;:,.!?;: " or len(current_chunk) >= 20:
response = JsonData.stream_data(data=current_chunk)
yield f"data: {response.model_dump_json()}\n\n"
current_chunk = ""
await asyncio.sleep(0.01)
# 发送剩余的chunk
if current_chunk:
response = JsonData.stream_data(data=current_chunk)
yield f"data: {response.model_dump_json()}\n\n"
# 发送结束标记
yield "data: [DONE]\n\n"
```
* 路由层面处理 `chat.py`
```python
@router.post("/stream")
async def chat_stream(
request: ChatRequest,
chat_service: ChatService = Depends(ChatService),
current_user: Dict[str, Any] = Depends(get_current_user)
):
"""聊天接口(流式响应)"""
# 使用当前用户的 account_id
account_id = current_user["account_id"]
# 获取智能体
agent = await get_chat_agent(chat_service)
return StreamingResponse(
generate_stream_response(agent, chat_service, account_id, request.message),
media_type="text/event-stream"
)
```
#### AI聊天智能助理之全链路测试综合实战
**简介: AI聊天智能助理之全链路测试综合实战**
* 回顾需求
* 开发AI聊天智能助理, 基于 Redis 实现聊天历史存储,支持流式响应(Streaming Response)
- 智能对话能力:
- 支持多轮对话,保持上下文连贯性
- 可以理解用户意图并调用合适的工具
- 能够生成对话摘要,帮助理解对话历史
- 实时信息获取:
- 可以回答需要实时数据的问题,
- 通过搜索工具获取最新信息,搜索结果会被智能整合到回答中
* 全链路测试实战
* 启动项目 `uvicorn app.main:app --reload`
* 准备token ,并且配置到HTTP请求头里面
* APIFOX增加请求头 `Accept : text/event-stream `
* 测试案例一
* 告诉基本当前人员信息(进阶也可以初始化导入用户的历史画像数据)
* 进行基本信息问答,看智能体助理是否有记忆功能
* 测试案例二
* 询问当前当前需要联网信息内容,看大模型是否有调用工具进行处理
* 查看Redis的数据存储:聊天记录和摘要
* 拓展:不用每次都生成摘要,可以配置进阶策略,比如对话轮次阈值(默认5轮)、关键决策点标记、上下文长度超过XXX
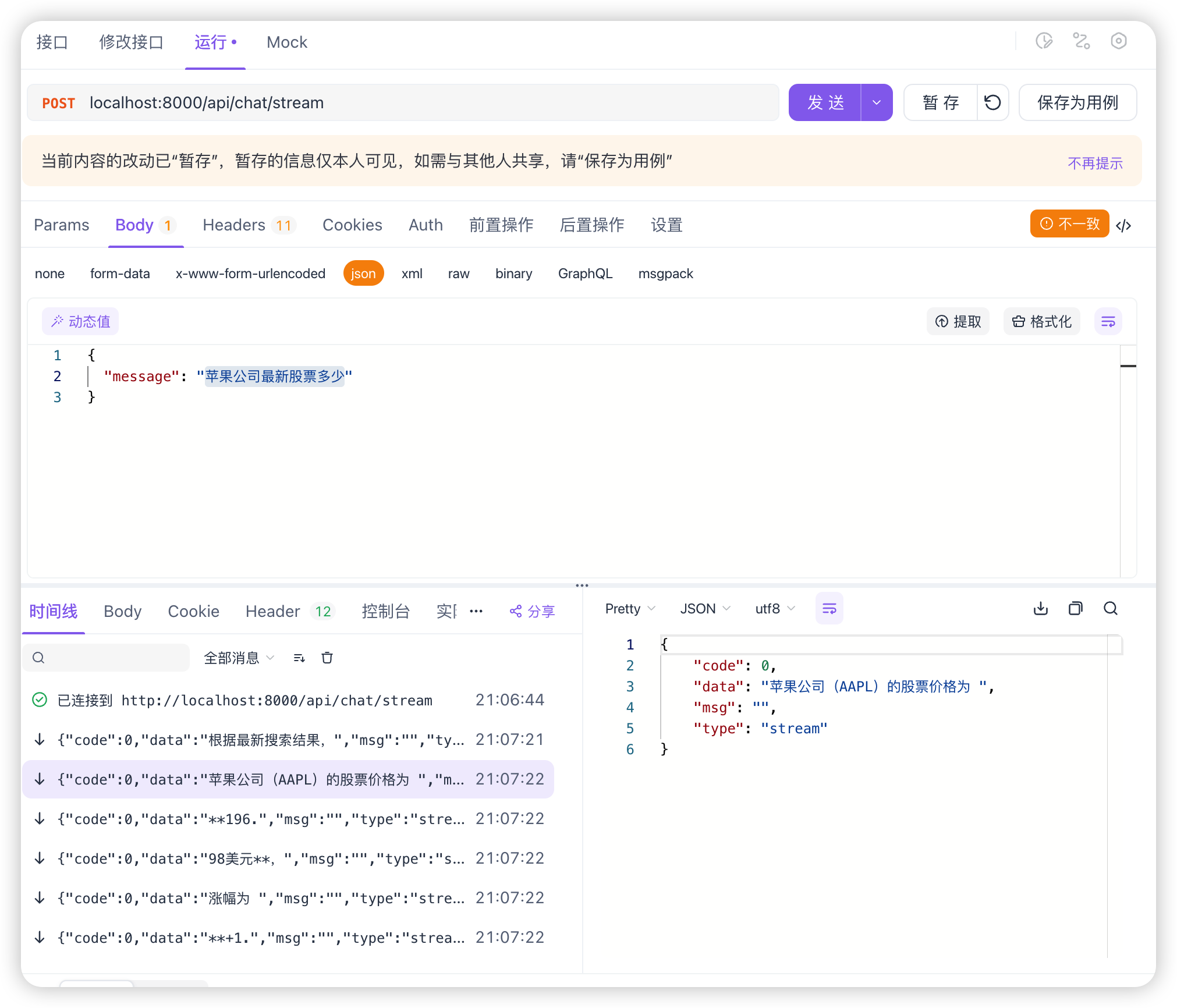 ### AI智能体心实战之AI在线文档助手
#### AI在线文档助手需求文档和路由开发实战
* 需求
* AI在线文档助手,提供文档内容获取、解析和智能总结功能
* 支持多种文档格式(HTML、PDF等),并能够根据用户需求生成不同形式的文档总结。
* 大体流程和聊天助理类似,接下去就会加快速度了哈
* 技术亮点
* 多格式文档支持:HTML、PDF、纯文本等
- 智能文档处理:基于LLM的智能总结和关键点提取
- 流式处理:支持大文件分块处理和流式响应
- 多语言支持:支持多种语言的文档处理和总结
* 备注
* 是否需要鉴权登录,取决文档的来源类型
* 选择网盘里面的相关资源,则需要登录;选择好文件后调用存储接口获取临时访问地址
* 智能体接受的是在线可以访问的地址,即可实现对应的在线文档解析
### AI智能体心实战之AI在线文档助手
#### AI在线文档助手需求文档和路由开发实战
* 需求
* AI在线文档助手,提供文档内容获取、解析和智能总结功能
* 支持多种文档格式(HTML、PDF等),并能够根据用户需求生成不同形式的文档总结。
* 大体流程和聊天助理类似,接下去就会加快速度了哈
* 技术亮点
* 多格式文档支持:HTML、PDF、纯文本等
- 智能文档处理:基于LLM的智能总结和关键点提取
- 流式处理:支持大文件分块处理和流式响应
- 多语言支持:支持多种语言的文档处理和总结
* 备注
* 是否需要鉴权登录,取决文档的来源类型
* 选择网盘里面的相关资源,则需要登录;选择好文件后调用存储接口获取临时访问地址
* 智能体接受的是在线可以访问的地址,即可实现对应的在线文档解析
 * 编码实战
* 创建 请求文件 `doc_schemas.py`
```python
from pydantic import BaseModel, HttpUrl
from typing import Optional
class DocumentRequest(BaseModel):
"""文档处理请求"""
url: HttpUrl # 文档URL
summary_type: str = "brief" # 总结类型:brief(简要), detailed(详细), key_points(要点)
language: str = "zh" # 输出语言
length: Optional[str] = None # 长度限制
additional_instructions: Optional[str] = None # 额外要求
```
* 创建业务逻辑处理文件 `doc_service.py`
```python
from typing import Any, AsyncIterator
from agents.doc_agent import create_document_agent, process_document
from models.doc_schemas import DocumentRequest
from tools.document_tools import DocumentTools
import gc
class DocumentService:
```
* 创建路由文件`doc.py`
```python
from fastapi import APIRouter, Depends
from models.doc_schemas import DocumentRequest
from models.json_response import JsonData
from services.doc_service import DocumentService
from fastapi.responses import StreamingResponse
import asyncio
router = APIRouter(prefix="/api/document", tags=["文档助手"])
#可以放到service层,也可以放到路由层,或者抽取统一方法
async def generate_stream_response(request: DocumentRequest, doc_service: DocumentService):
"""生成流式响应数据"""
async for chunk in doc_service.process_document_stream(request):
response = JsonData.stream_data(data=chunk)
yield f"data: {response.model_dump_json()}\n\n"
await asyncio.sleep(0.01)
yield "data: [DONE]\n\n"
@router.post("/stream")
async def process_document_stream(
request: DocumentRequest,
doc_service: DocumentService = Depends(DocumentService)
):
"""处理文档请求(流式响应)"""
return StreamingResponse(
generate_stream_response(request, doc_service),
media_type="text/event-stream"
)
```
#### AI在线文档助手之文档处理工具集开发
* 需求背景
* 根据用户的需求,智能体提取的文档类型,选择合适的工具进行提取
* 实现文档处理服务,支持多种文档格式的处理(HTML、PDF、文本),提供高效的文档内容提取和清理功能
* 目前开发PDF和HTML类型,可以根据业务需求自己拓展更多
* 编码实战
* 创建 请求文件 `doc_schemas.py`
```python
from pydantic import BaseModel, HttpUrl
from typing import Optional
class DocumentRequest(BaseModel):
"""文档处理请求"""
url: HttpUrl # 文档URL
summary_type: str = "brief" # 总结类型:brief(简要), detailed(详细), key_points(要点)
language: str = "zh" # 输出语言
length: Optional[str] = None # 长度限制
additional_instructions: Optional[str] = None # 额外要求
```
* 创建业务逻辑处理文件 `doc_service.py`
```python
from typing import Any, AsyncIterator
from agents.doc_agent import create_document_agent, process_document
from models.doc_schemas import DocumentRequest
from tools.document_tools import DocumentTools
import gc
class DocumentService:
```
* 创建路由文件`doc.py`
```python
from fastapi import APIRouter, Depends
from models.doc_schemas import DocumentRequest
from models.json_response import JsonData
from services.doc_service import DocumentService
from fastapi.responses import StreamingResponse
import asyncio
router = APIRouter(prefix="/api/document", tags=["文档助手"])
#可以放到service层,也可以放到路由层,或者抽取统一方法
async def generate_stream_response(request: DocumentRequest, doc_service: DocumentService):
"""生成流式响应数据"""
async for chunk in doc_service.process_document_stream(request):
response = JsonData.stream_data(data=chunk)
yield f"data: {response.model_dump_json()}\n\n"
await asyncio.sleep(0.01)
yield "data: [DONE]\n\n"
@router.post("/stream")
async def process_document_stream(
request: DocumentRequest,
doc_service: DocumentService = Depends(DocumentService)
):
"""处理文档请求(流式响应)"""
return StreamingResponse(
generate_stream_response(request, doc_service),
media_type="text/event-stream"
)
```
#### AI在线文档助手之文档处理工具集开发
* 需求背景
* 根据用户的需求,智能体提取的文档类型,选择合适的工具进行提取
* 实现文档处理服务,支持多种文档格式的处理(HTML、PDF、文本),提供高效的文档内容提取和清理功能
* 目前开发PDF和HTML类型,可以根据业务需求自己拓展更多
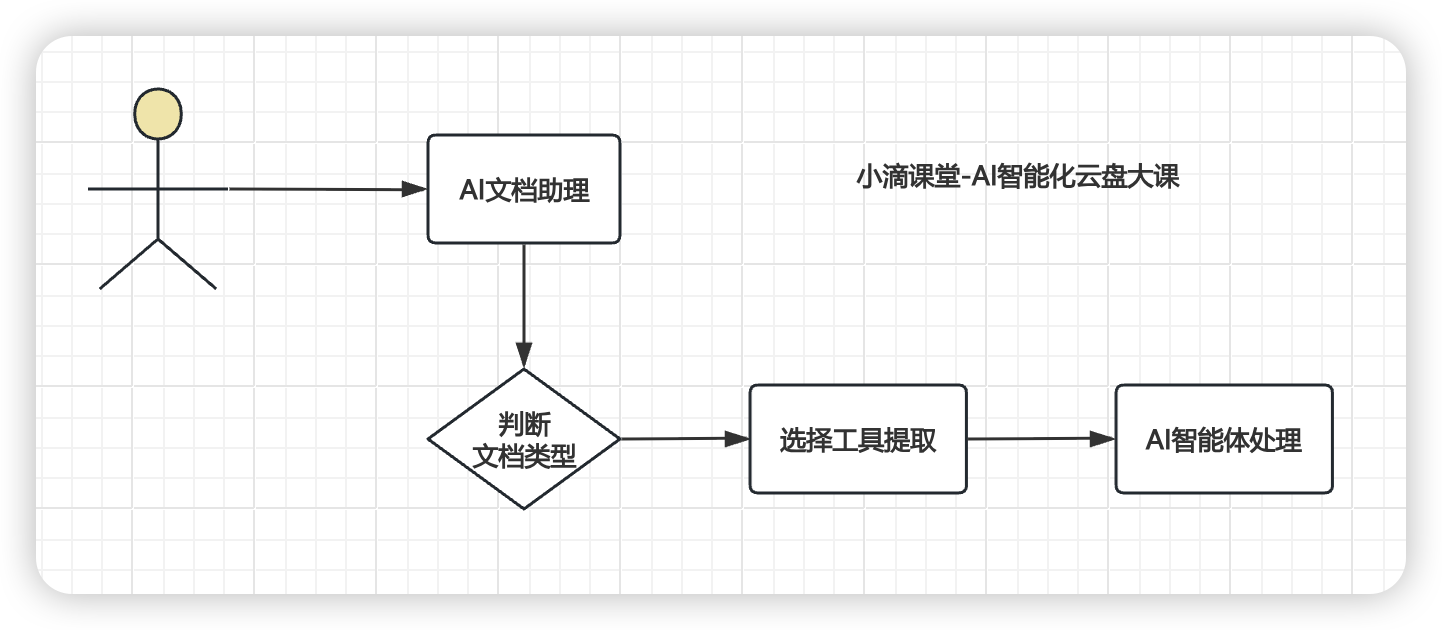 * 拓展知识点
* `BeautifulSoup`库
* 主要是解析 HTML/XML 内容(`html_content`),生成一个结构化的 `BeautifulSoup 对象`
* 解析器 `html.parser`
* 是 Python 自带的 HTML 解析器,轻量、无需依赖第三方库。
* 方便地提取和操作 HTML 中的元素
```python
from bs4 import BeautifulSoup
# 假设有一段 HTML 内容
html_content = "
* 拓展知识点
* `BeautifulSoup`库
* 主要是解析 HTML/XML 内容(`html_content`),生成一个结构化的 `BeautifulSoup 对象`
* 解析器 `html.parser`
* 是 Python 自带的 HTML 解析器,轻量、无需依赖第三方库。
* 方便地提取和操作 HTML 中的元素
```python
from bs4 import BeautifulSoup
# 假设有一段 HTML 内容
html_content = "你好,小滴课堂老王
"
# 解析 HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 提取数据
title = soup.h1.text # 输出:"你好,小滴课堂老王"
```
* 编码实战 `document_tools.py`
```python
from typing import Optional, Dict, Any, Generator
import requests
from bs4 import BeautifulSoup
from langchain.tools import Tool
import re
from urllib.parse import urlparse
import time
import io
from PyPDF2 import PdfReader
from tqdm import tqdm
import gc
class DocumentTools:
"""文档处理工具集"""
@staticmethod
def fetch_document(url: str) -> Dict[str, Any]:
"""获取文档内容"""
try:
# 使用流式下载
response = requests.get(url, stream=True, timeout=30)
response.raise_for_status()
# 解析文档类型
content_type = response.headers.get('content-type', '')
print(f"---Content-Type---: {content_type}")
if 'text/html' in content_type:
return DocumentTools._parse_html(response.text)
elif 'application/pdf' in content_type:
return DocumentTools._parse_pdf_stream(response)
else:
return {
"title": urlparse(url).path.split('/')[-1],
"content": response.text,
"type": "text"
}
except Exception as e:
raise Exception(f"获取文档失败: {str(e)}")
@staticmethod
def _parse_html(html_content: str) -> Dict[str, Any]:
"""解析HTML文档"""
soup = BeautifulSoup(html_content, 'html.parser')
# 提取标题
title = soup.title.string if soup.title else "未命名文档"
# 提取正文内容
content = ""
for p in soup.find_all(['p', 'h1', 'h2', 'h3', 'h4', 'h5', 'h6']):
content += p.get_text() + "\n"
return {
"title": title,
"content": content.strip(),
"type": "html"
}
@staticmethod
def _parse_pdf_stream(response: requests.Response) -> Dict[str, Any]:
"""流式解析PDF文档"""
pass
```
* 知识点拓展
* `tqdm`
* 是 Python 中用于在循环或长时间运行的任务中显示进度条的库
* 主要功能
* 实时进度条:显示当前进度百分比、已用时间、剩余时间、迭代速度等。
* 低开销:对代码性能影响极小。
* 使用
```python
#前面一开始创建项目的时候已经安装了这个依赖
from tqdm import tqdm
import time
# 在 for 循环外包裹 tqdm()
for i in tqdm(range(100)):
time.sleep(0.1) # 模拟耗时操作
```
* `PyPDF2`
* 是 Python 中一个专门用于处理 PDF 文件的第三方库,支持 PDF 文件的读取、写入、合并、拆分、加密、解密等操作。
* 功能相对基础,但在处理简单 PDF 任务时非常高效。
* 建议
* 对于复杂需求(如表格提取、内容编辑),可以结合其他库(如 `pdfplumber` + `PyPDF2`)等进行选择
* **`pdfplumber`**: 更适合提取文本、表格和可视化元素。
* **`PyMuPDF` **: 高性能,支持复杂操作(如 OCR 集成)。
* 编码实战
```python
@staticmethod
def _parse_pdf_stream(response: requests.Response) -> Dict[str, Any]:
"""流式解析PDF文档
Args:
response (requests.Response): 包含PDF文档的响应对象
Returns:
Dict[str, Any]: 包含文档标题、内容和类型的字典
"""
# 创建内存缓冲区
buffer = io.BytesIO()
# 获取文件大小
total_size = int(response.headers.get('content-length', 0))
# 使用tqdm显示下载进度
with tqdm(total=total_size, unit='B', unit_scale=True, desc="下载PDF") as pbar:
for chunk in response.iter_content(chunk_size=8192):
if chunk:
buffer.write(chunk)
pbar.update(len(chunk))
# 重置缓冲区位置
buffer.seek(0)
# 分块读取PDF内容
content = ""
try:
# 使用PdfReader替代PdfFileReader
pdf_reader = PdfReader(buffer)
# 获取文档信息
info = pdf_reader.metadata
title = info.title if info and info.title else "PDF文档"
# 分块处理PDF页面
total_pages = len(pdf_reader.pages)
with tqdm(total=total_pages, desc="处理PDF页面") as pbar:
for page_num in range(total_pages):
page = pdf_reader.pages[page_num]
content += page.extract_text() + "\n"
# 每处理10页就清理一次内存
if (page_num + 1) % 10 == 0:
content = DocumentTools._clean_text(content)
gc.collect()
pbar.update(1)
except Exception as e:
raise ApiException(f"解析PDF失败: {str(e)}")
finally:
buffer.close()
return {
"title": title,
"content": DocumentTools._clean_text(content),
"type": "pdf"
}
@staticmethod
def _clean_text(text: str) -> str:
"""清理文本内容
Args:
text (str): 待清理的文本内容
Returns:
str: 清理后的文本内容
"""
# 移除多余的空行
text = re.sub(r'\n\s*\n', '\n\n', text)
# 移除多余的空格
text = re.sub(r' +', ' ', text)
return text.strip()
@staticmethod
def create_tools() -> list[Tool]:
"""创建文档处理工具集
Returns:
list[Tool]: 文档处理工具列表
"""
return [
Tool(
name="fetch_document",
func=DocumentTools.fetch_document,
description="获取并解析在线文档内容"
)
]
```
#### AI在线文档助手之文档Agent智能体开发实战
* 业务需求
* 智能体能够分析用户提供的文档,并根据用户需求生成高质量的总结。
* 核心功能:
- 分析文档内容并提取关键要点,根据用户指定的总结类型(简要、详细或要点)生成相应的总结。
- 支持流式输出,确保每个 token 实时返回给用户。
- 也支持处理用户提出的额外要求。
* 编码实战
```python
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.tools import Tool
from core.llm import get_default_llm
from typing import List, AsyncIterator
import asyncio
from datetime import datetime
def create_document_agent(tools: List[Tool]):
"""创建文档处理智能体"""
# 定义系统提示词
system_prompt = """你是一个专业的文档处理助手。你的任务是分析用户提供的文档,生成高质量的总结。
你需要:
1. 仔细阅读并理解文档内容
2. 根据用户要求的总结类型(简要/详细/要点)生成相应的总结
3. 提取文档的关键要点
4. 确保总结准确、全面、易读
如果用户提供了额外的要求,请尽量满足这些要求。"""
# 创建提示词模板
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
])
# 获取LLM实例,并配置流式输出
llm = get_default_llm()
# 创建智能体
agent = create_openai_functions_agent(llm, tools, prompt)
# 创建执行器
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True,
handle_parsing_errors=True
)
return agent_executor
async def process_document(agent_executor: AgentExecutor, input_text: str) -> AsyncIterator[str]:
"""处理文档并生成总结"""
print(f"正在处理 input_text: {input_text}")
async for chunk in agent_executor.astream({"input": input_text}):
if "output" in chunk:
# 确保每个token都能实时返回
for token in chunk["output"]:
yield token
await asyncio.sleep(0.01) # 控制输出速度
```
#### AI在线文档助手之文档Service层处理实战
* 需求
* 文档处理服务,能够接收用户请求并调用智能体对文档进行分析和总结。
* 核心功能:
- 接收文档请求并获取文档内容。
- 根据文档大小决定是否进行分块处理。
- 使用智能体生成高质量的文档总结,并支持流式输出。
- 处理大文本时,通过内存管理优化性能。
* 编码实战 `doc_service.py`
```python
from typing import Any, AsyncIterator
from agents.doc_agent import create_document_agent, process_document
from models.doc_schemas import DocumentRequest
from tools.document_tools import DocumentTools
import gc
class DocumentService:
"""
文档处理服务类,负责初始化文档处理所需的工具和智能体,并提供文档处理的接口
"""
def __init__(self):
# 初始化工具
self.tools = DocumentTools.create_tools()
# 创建智能体
self.agent_excutor = create_document_agent(self.tools)
async def process_document_stream(self, request: DocumentRequest) -> AsyncIterator[str]:
"""流式处理文档请求"""
try:
# 获取文档内容
doc_content = DocumentTools.fetch_document(str(request.url))
# 根据文档内容长度决定是否分割处理
content = doc_content['content']
chunks = []
# 检查内容长度是否超过1,000,000个字符
print(f"--------------len(content): {len(content)}")
if len(content) > 1000:
# 初始化当前块变量,用于累积不足1,000,000字符的内容
current_chunk = ""
# 遍历内容中的每个段落,使用'\n\n'作为分隔符进行分割
for paragraph in content.split('\n\n'):
# 如果当前块加上新段落后超过1,000,000字符,且当前块非空
if len(current_chunk) + len(paragraph) > 1000000 and current_chunk:
# 将当前块添加到块列表中,并开始新的块
chunks.append(current_chunk)
current_chunk = paragraph
else:
# 否则,将当前段落添加到当前块中
current_chunk = f"{current_chunk}\n\n{paragraph}" if current_chunk else paragraph
# 如果循环结束后当前块非空,将其添加到块列表中
if current_chunk:
chunks.append(current_chunk)
else:
# 如果内容长度不超过1,000,000字符,直接将内容作为唯一一个块
chunks = [content]
# 处理每个文档片段
for i, chunk in enumerate(chunks):
# 构建输入文本
input_text = self._build_input_text(
doc_content['title'],
chunk,
request.summary_type,
request.language,
request.length or '无限制',
request.additional_instructions or '无'
)
# 异步处理文档并生成响应
async for response_chunk in process_document(self.agent_excutor, input_text):
yield response_chunk
# 如果不是最后一个片段,插入分隔符
if i < len(chunks) - 1:
yield "\n\n--- 下一部分 ---\n\n"
# 清理内存
gc.collect()
except Exception as e:
# 错误处理
yield f"处理文档时发生错误: {str(e)}"
def _build_input_text(self, title: str, content: str, summary_type: str,
language: str, length: str, additional_instructions: str) -> str:
"""构建输入文本"""
return f"""
文档标题: {title}
文档内容: {content}
总结类型: {summary_type}
输出语言: {language}
最大长度: {length}
额外要求: {additional_instructions}
"""
```
#### AI在线文档助手之全链路测试综合实战
* 全链路测试,回顾需求
* AI在线文档助手,提供文档内容获取、解析和智能总结功能
* 支持多种文档格式(HTML、PDF等),并能够根据用户需求生成不同形式的文档总结。
* 注意
* 不同智能体之间,实现方式也有多样,企业中开发遵循当前团队即可
* 不用局限一定的格式,智能体工程化这个不像传统的后端和前端,新技术刚出来,还在持续发展中
* 代码有一定的优化空间和逻辑修复,大家可以进一步跟进自己的需求进行拓展,比如doc文档、其他类型提取等
* 异常打印堆栈信息:`logger.exception("获取文档失败")`
* 链路测试一
* 选择网盘的文件,可以调用下载接口,拿到临时文件访问地址
* 也可以直接通过minio获取临时的访问地址
* 链路测试二
* 选择在线网站,非动态网站即可,HTML结尾的静态网站才可以提取
* 比如
* 短文本:https://www.runoob.com/python3/python3-tutorial.html
* 长文本: https://file.xdclass.net/video/2024/selenium/biji.html